
MySQL數(shù)據(jù)庫(kù)之互聯(lián)網(wǎng)常用架構(gòu)方案
點(diǎn)擊上方藍(lán)色字體,選擇“標(biāo)星公眾號(hào)”
優(yōu)質(zhì)文章,第一時(shí)間送達(dá)
一、數(shù)據(jù)庫(kù)架構(gòu)原則↑
高可用
高性能
可擴(kuò)展
一致性
二、常見(jiàn)的架構(gòu)方案↑
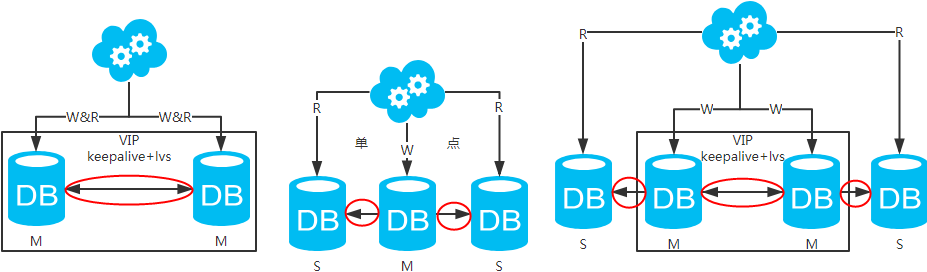
方案一:主備架構(gòu),只有主庫(kù)提供讀寫(xiě)服務(wù),備庫(kù)冗余作故障轉(zhuǎn)移用
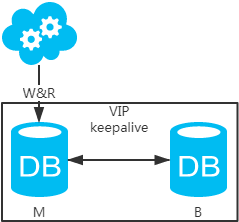
jdbc:mysql://vip:3306/xxdb
高可用分析:高可用,主庫(kù)掛了,keepalive(只是一種工具)會(huì)自動(dòng)切換到備庫(kù)。這個(gè)過(guò)程對(duì)業(yè)務(wù)層是透明的,無(wú)需修改代碼或配置。
高性能分析:讀寫(xiě)都操作主庫(kù),很容易產(chǎn)生瓶頸。大部分互聯(lián)網(wǎng)應(yīng)用讀多寫(xiě)少,讀會(huì)先成為瓶頸,進(jìn)而影響寫(xiě)性能。另外,備庫(kù)只是單純的備份,資源利用率50%,這點(diǎn)方案二可解決。
一致性分析:讀寫(xiě)都操作主庫(kù),不存在數(shù)據(jù)一致性問(wèn)題。
擴(kuò)展性分析:無(wú)法通過(guò)加從庫(kù)來(lái)擴(kuò)展讀性能。
可落地分析:兩點(diǎn)影響落地使用。第一,性能一般,這點(diǎn)可以通過(guò)建立高效的索引和引入緩存來(lái)增加讀性能,進(jìn)而提高性能。這也是通用的方案。第二,擴(kuò)展性差,這點(diǎn)可以通過(guò)分庫(kù)分表來(lái)擴(kuò)展。
方案二:雙主架構(gòu),兩個(gè)主庫(kù)同時(shí)提供服務(wù),負(fù)載均衡
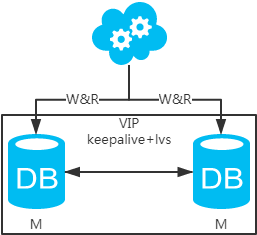
jdbc:mysql://vip:3306/xxdb
高可用分析:高可用,一個(gè)主庫(kù)掛了,不影響另一臺(tái)主庫(kù)提供服務(wù)。這個(gè)過(guò)程對(duì)業(yè)務(wù)層是透明的,無(wú)需修改代碼或配置。
高性能分析:讀寫(xiě)性能相比于方案一都得到提升,提升一倍。
一致性分析:存在數(shù)據(jù)一致性問(wèn)題。請(qǐng)看,一致性解決方案。
擴(kuò)展性分析:當(dāng)然可以擴(kuò)展成三主循環(huán),但不建議(會(huì)多一層數(shù)據(jù)同步,這樣同步的時(shí)間會(huì)更長(zhǎng))。如果非得在數(shù)據(jù)庫(kù)架構(gòu)層面擴(kuò)展的話(huà),擴(kuò)展為方案四。
可落地分析:兩點(diǎn)影響落地使用。第一,數(shù)據(jù)一致性問(wèn)題,一致性解決方案可解決問(wèn)題。第二,主鍵沖突問(wèn)題,ID統(tǒng)一地由分布式ID生成服務(wù)來(lái)生成可解決問(wèn)題。
方案三:主從架構(gòu),一主多從,讀寫(xiě)分離
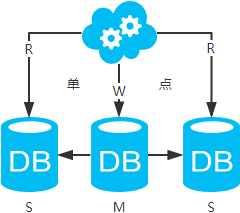
jdbc:mysql://master-ip:3306/xxdb
jdbc:mysql://slave1-ip:3306/xxdb
jdbc:mysql://slave2-ip:3306/xxdb
高可用分析:主庫(kù)單點(diǎn),從庫(kù)高可用。一旦主庫(kù)掛了,寫(xiě)服務(wù)也就無(wú)法提供。
高性能分析:大部分互聯(lián)網(wǎng)應(yīng)用讀多寫(xiě)少,讀會(huì)先成為瓶頸,進(jìn)而影響整體性能。讀的性能提高了,整體性能也提高了。另外,主庫(kù)可以不用索引,線(xiàn)上從庫(kù)和線(xiàn)下從庫(kù)也可以建立不同的索引(線(xiàn)上從庫(kù)如果有多個(gè)還是要建立相同的索引,不然得不償失;線(xiàn)下從庫(kù)是平時(shí)開(kāi)發(fā)人員排查線(xiàn)上問(wèn)題時(shí)查的庫(kù),可以建更多的索引)。
一致性分析:存在數(shù)據(jù)一致性問(wèn)題。請(qǐng)看,一致性解決方案。
擴(kuò)展性分析:可以通過(guò)加從庫(kù)來(lái)擴(kuò)展讀性能,進(jìn)而提高整體性能。(帶來(lái)的問(wèn)題是,從庫(kù)越多需要從主庫(kù)拉取binlog日志的端就越多,進(jìn)而影響主庫(kù)的性能,并且數(shù)據(jù)同步完成的時(shí)間也會(huì)更長(zhǎng)。建議不要分多層,且一臺(tái)主庫(kù)一般掛3-5臺(tái)從庫(kù)吧。一般配置的mysql,并發(fā)最好控制在2000/s,掛5臺(tái)的話(huà),整體基本能支撐1w+/s的并發(fā),再加上緩存和二八定律,基本能支撐小10w/s的并發(fā),很高了。如果還不能滿(mǎn)足需求,那還是選擇去分庫(kù)吧。)
可落地分析:兩點(diǎn)影響落地使用。第一,數(shù)據(jù)一致性問(wèn)題,一致性解決方案可解決問(wèn)題。第二,主庫(kù)單點(diǎn)問(wèn)題,暫時(shí)沒(méi)想到很好的解決方案(這點(diǎn)評(píng)論里給了一種方案,可參考)。
注:思考一個(gè)問(wèn)題,一臺(tái)從庫(kù)掛了會(huì)怎樣?讀寫(xiě)分離之讀的負(fù)載均衡策略怎么容錯(cuò)?
方案四:雙主+主從架構(gòu),看似完美的方案
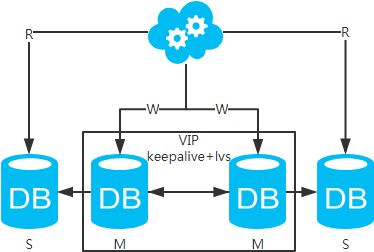
jdbc:mysql://vip:3306/xxdb
jdbc:mysql://slave1-ip:3306/xxdb
jdbc:mysql://slave2-ip:3306/xxdb
高可用分析:高可用。
高性能分析:高性能。
一致性分析:存在數(shù)據(jù)一致性問(wèn)題。請(qǐng)看,一致性解決方案。
擴(kuò)展性分析:可以通過(guò)加從庫(kù)來(lái)擴(kuò)展讀性能,進(jìn)而提高整體性能。(帶來(lái)的問(wèn)題同方案二)
可落地分析:同方案二,但數(shù)據(jù)同步又多了一層,數(shù)據(jù)延遲更嚴(yán)重。
三、一致性解決方案↑
第一類(lèi):主庫(kù)和從庫(kù)一致性解決方案
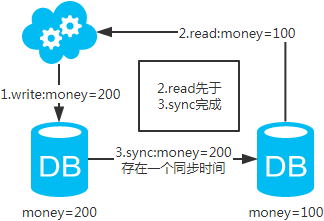
注:圖中圈出的是數(shù)據(jù)同步的地方,數(shù)據(jù)同步(MySQL主從復(fù)制,簡(jiǎn)單來(lái)說(shuō)就是從庫(kù)從主庫(kù)拉取binlog日志,再執(zhí)行一遍,想深入了解可以去查閱“MySQL主從復(fù)制原理”相關(guān)資料)是需要時(shí)間的,這個(gè)同步時(shí)間內(nèi)主庫(kù)和從庫(kù)的數(shù)據(jù)會(huì)存在不一致的情況。如果同步過(guò)程中有讀請(qǐng)求,那么讀到的就是從庫(kù)中的老數(shù)據(jù)。如下圖。
既然知道了數(shù)據(jù)不一致性產(chǎn)生的原因,有下面幾個(gè)解決方案供參考:
直接忽略,如果業(yè)務(wù)允許延時(shí)存在,那么就不去管它。
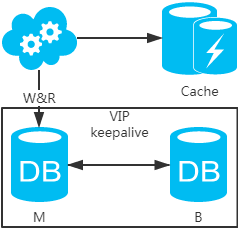
強(qiáng)制讀主,采用主備架構(gòu)方案,或者代碼指定讀主庫(kù)(一般不建議,這樣就失去了讀寫(xiě)分離的意義),讀寫(xiě)都走主庫(kù)。
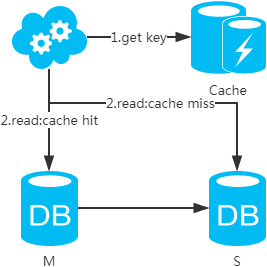
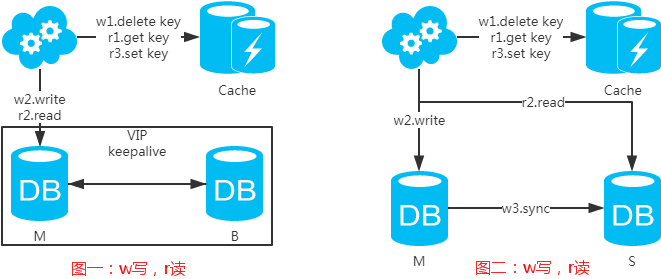
選擇讀主,寫(xiě)操作時(shí)根據(jù)庫(kù)+表+業(yè)務(wù)特征生成一個(gè)key放到Cache里并設(shè)置超時(shí)時(shí)間(大于等于主從數(shù)據(jù)同步時(shí)間)。讀請(qǐng)求時(shí),同樣的方式生成key先去查Cache,再判斷是否命中。若命中,則讀主庫(kù),否則讀從庫(kù)。代價(jià)是多了一次緩存讀寫(xiě),基本可以忽略。
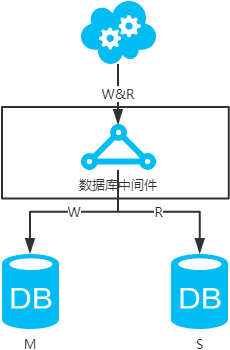
數(shù)據(jù)庫(kù)中間件,引入開(kāi)源(mycat等)或自研的數(shù)據(jù)庫(kù)中間層。個(gè)人理解,思路同選擇讀主。數(shù)據(jù)庫(kù)中間件的成本比較高,并且還多引入了一層。
第二類(lèi):DB和緩存一致性解決方案
先來(lái)看一下常用的緩存使用方式:
第一步:淘汰緩存;
第二步:寫(xiě)入數(shù)據(jù)庫(kù);
第三步:讀取緩存?返回:讀取數(shù)據(jù)庫(kù);
第四步:讀取數(shù)據(jù)庫(kù)后寫(xiě)入緩存。
一般來(lái)說(shuō),并發(fā)量不是特別大的話(huà),上面的方式就可以。但是如果是高并發(fā)量的情況下,當(dāng)寫(xiě)入時(shí),你淘汰了緩存,但是還沒(méi)寫(xiě)入數(shù)據(jù)庫(kù)時(shí)或者主從延時(shí),就有一個(gè)讀請(qǐng)求完成了,此時(shí)緩存中就會(huì)緩存舊的數(shù)據(jù)。此時(shí)可以,寫(xiě)庫(kù)完成時(shí),等一會(huì)(根據(jù)業(yè)務(wù)場(chǎng)景評(píng)估)再刪除一次緩存,這樣緩存舊數(shù)據(jù)的概率又低了,不過(guò)這樣一來(lái)數(shù)據(jù)庫(kù)的壓力就會(huì)有相應(yīng)的增加,并且響應(yīng)時(shí)間會(huì)增加。其實(shí),要想保證數(shù)據(jù)庫(kù)和緩存嚴(yán)格的一致性很難,甚至要付出很高的代價(jià)。網(wǎng)上還個(gè)方案,就是用本地內(nèi)存隊(duì)列來(lái)控制讀請(qǐng)求和寫(xiě)請(qǐng)求串行化,利弊都有,感興趣可深入研究:高并發(fā)場(chǎng)景下,如何保證緩存和數(shù)據(jù)庫(kù)雙寫(xiě)的一致性。另外,思考一下是不是能用基于臨時(shí)順序節(jié)點(diǎn)的Zookeeper分布式鎖(用兩個(gè)鎖,一個(gè)讀鎖,一個(gè)寫(xiě)鎖,當(dāng)排在寫(xiě)鎖后面的第一個(gè)讀鎖被通知時(shí),讀操作完成后,批量刪除后面連續(xù)的讀鎖,注意不要引發(fā)羊群效應(yīng) -> 主備架構(gòu)時(shí))?
注:設(shè)置緩存時(shí),一定要加上失效時(shí)間!
四、個(gè)人的一些見(jiàn)解↑
1、架構(gòu)演變
架構(gòu)演變一:方案一 -> 方案一+分庫(kù)分表;
架構(gòu)演變二:方案一 -> 方案三 -> 方案三+分庫(kù)分表
架構(gòu)演變?nèi)悍桨敢?-> 方案二 -> 方案二+分庫(kù)分表
注:方案四一般不用。
2、個(gè)人見(jiàn)解
加緩存和索引是通用的提升數(shù)據(jù)庫(kù)性能的方式;
分庫(kù)分表帶來(lái)的好處是巨大的,但同樣也會(huì)帶來(lái)一些問(wèn)題,詳見(jiàn)MySQL數(shù)據(jù)庫(kù)之互聯(lián)網(wǎng)常用分庫(kù)分表方案。
不管是主備+分庫(kù)分表還是主從+讀寫(xiě)分離+分庫(kù)分表,都要考慮具體的業(yè)務(wù)場(chǎng)景。一般大部分的數(shù)據(jù)庫(kù)架構(gòu)還是采用方案一和方案一+分庫(kù)分表,典型的讀多寫(xiě)少的場(chǎng)景用方案三+讀寫(xiě)分離+分庫(kù)分表。另外,阿里云提供的數(shù)據(jù)庫(kù)云服務(wù)也都是主備方案,要想主從+讀寫(xiě)分離需要二次架構(gòu)。
記住一句話(huà):不考慮業(yè)務(wù)場(chǎng)景的架構(gòu)都是耍流氓。
作者 | 尜尜人物
來(lái)源 | cnblogs.com/littlecharacter/p/9084291.html
