
Kafka 消費者的使用和原理
繼上周的《Kafka 生產(chǎn)者的使用和原理》,這周我們學(xué)習(xí)下消費者,仍然還是先從一個消費者的Hello World學(xué)起:
public?class?Consumer?{
????public?static?void?main(String[]?args)?{
????????//?1.?配置參數(shù)
????????Properties?properties?=?new?Properties();
????????properties.put("key.deserializer",
????????????????"org.apache.kafka.common.serialization.StringDeserializer");
????????properties.put("value.deserializer",
????????????????"org.apache.kafka.common.serialization.StringDeserializer");
????????properties.put("bootstrap.servers",?"localhost:9092");
????????properties.put("group.id",?"group.demo");
????????//?2.?根據(jù)參數(shù)創(chuàng)建KafkaConsumer實例(消費者)
????????KafkaConsumer?consumer?=?new?KafkaConsumer<>(properties);
????????//?3.?訂閱主題
????????consumer.subscribe(Collections.singletonList("topic-demo"));
????????try?{
????????????// 4. 輪循消費
????????????while?(true)?{
????????????????ConsumerRecords?records?=?consumer.poll(Duration.ofMillis(1000));
????????????????for?(ConsumerRecord?record?:?records)?{
????????????????????System.out.println(record.value());
????????????????}
????????????}
????????}?finally?{
????????????//?5.?關(guān)閉消費者
????????????consumer.close();
????????}
????}
}
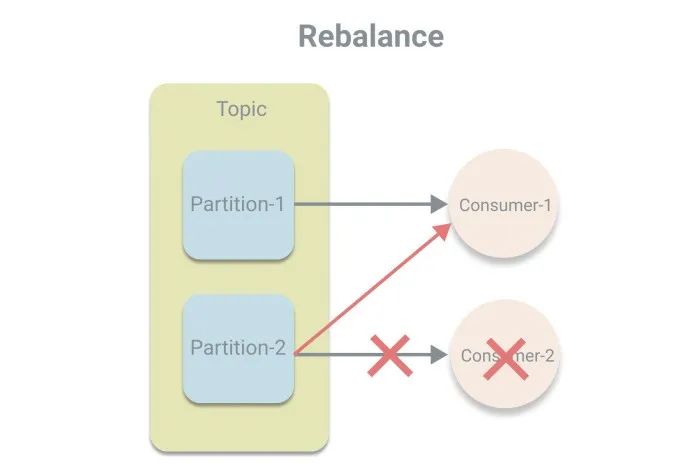
前兩步和生產(chǎn)者類似,配置參數(shù)然后根據(jù)參數(shù)創(chuàng)建實例,區(qū)別在于消費者使用的是反序列化器,以及多了一個必填參數(shù)group.id,用于指定消費者所屬的消費組。關(guān)于消費組的概念在《圖解 Kafka 中的基本概念》中介紹過了,消費組使得消費者的消費能力可橫向擴展,這次再介紹一個新的概念“再均衡”,其意思是將分區(qū)的所屬權(quán)進行重新分配,發(fā)生于消費者中有新的消費者加入或者有消費者宕機的時候。我們先了解再均衡的概念,至于如何再均衡不在此深究。
我們繼續(xù)看上面的代碼,第3步,subscribe訂閱期望消費的主題,然后進入第4步,輪循調(diào)用poll方法從Kafka服務(wù)器拉取消息。給poll方法中傳遞了一個Duration對象,指定poll方法的超時時長,即當(dāng)緩存區(qū)中沒有可消費數(shù)據(jù)時的阻塞時長,避免輪循過于頻繁。poll方法返回的是一個ConsumerRecords對象,其內(nèi)部對多個分區(qū)的ConsumerRecored進行了封裝,其結(jié)構(gòu)如下:
public?class?ConsumerRecords<K,?V>?implements?Iterable<ConsumerRecord<K,?V>>?{
????
????private?final?Map>>?records;
????//?...
????
}
而ConsumerRecord則類似ProducerRecord,封裝了消息的相關(guān)屬性:
public?class?ConsumerRecord<K,?V>?{
????private?final?String?topic;??//?主題
????private?final?int?partition;??//?分區(qū)號
????private?final?long?offset;??//?偏移量
????private?final?long?timestamp;??//?時間戳
????private?final?TimestampType?timestampType;??//?時間戳類型
????private?final?int?serializedKeySize;??//?key序列化后的大小
????private?final?int?serializedValueSize;??//?value序列化后的大小
????private?final?Headers?headers;??//?消息頭部
????private?final?K?key;??//?鍵
????private?final?V?value;??//?值
????private?final?Optional?leaderEpoch;??//?leader的周期號
相比ProdercerRecord的屬性更多,其中重點講下偏移量,偏移量是分區(qū)中一條消息的唯一標識。消費者在每次調(diào)用poll方法時,則是根據(jù)偏移量去分區(qū)拉取相應(yīng)的消息。而當(dāng)一臺消費者宕機時,會發(fā)生再均衡,將其負責(zé)的分區(qū)交給其他消費者處理,這時可以根據(jù)偏移量去繼續(xù)從宕機前消費的位置開始。
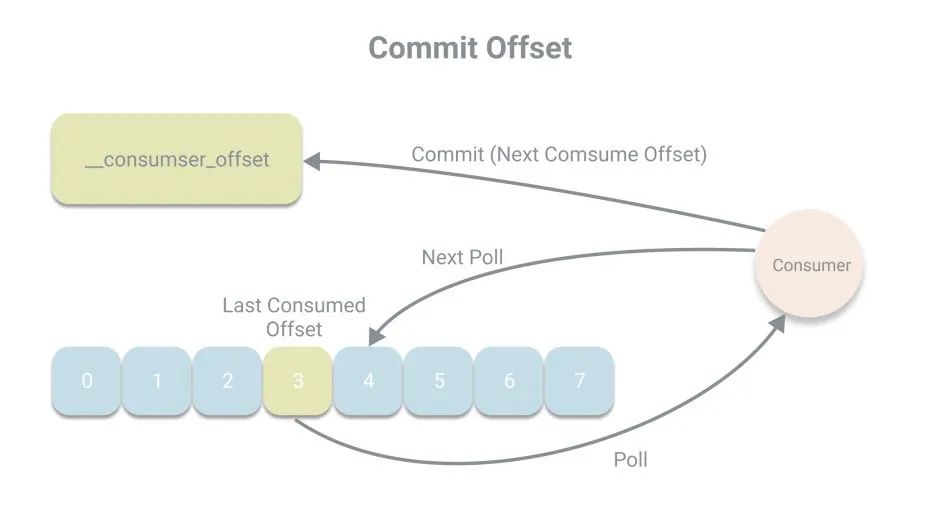
而為了應(yīng)對消費者宕機情況,偏移量被設(shè)計成不存儲在消費者的內(nèi)存中,而是被持久化到一個Kafka的內(nèi)部主題__consumer_offsets中,在Kafka中,將偏移量存儲的操作稱作提交。而消息者在每次消費消息時都將會將偏移量進行提交,提交的偏移量為下次消費的位置,例如本次消費的偏移量為x,則提交的是x+1。
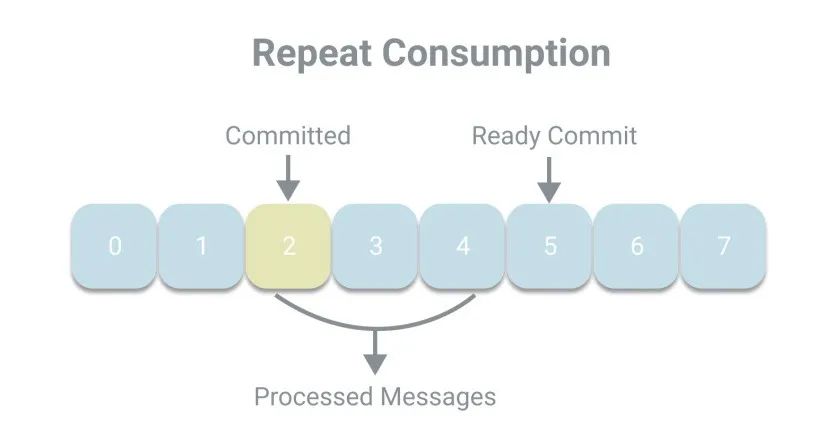
 在代碼中我們并沒有看到顯示的提交代碼,那么Kafka的默認提交方式是什么?默認情況下,消費者會定期以
在代碼中我們并沒有看到顯示的提交代碼,那么Kafka的默認提交方式是什么?默認情況下,消費者會定期以auto_commit_interval_ms(5秒)的頻率進行一次自動提交,而提交的動作發(fā)生于poll方法里,在進行拉取操作前會先檢查是否可以進行偏移量提交,如果可以,則會提交即將拉取的偏移量。下面我們看下這樣一個場景,上次提交的偏移量為2,而當(dāng)前消費者已經(jīng)處理了2、3、4號消息,正準備提交5,但卻宕機了。當(dāng)發(fā)生再均衡時,其他消費者將繼續(xù)從已提交的2開始消費,于是發(fā)生了重復(fù)消費的現(xiàn)象。
我們可以通過減小自動提交的時間間隔來減小重復(fù)消費的窗口大小,但這樣仍然無法避免重復(fù)消費的發(fā)生。
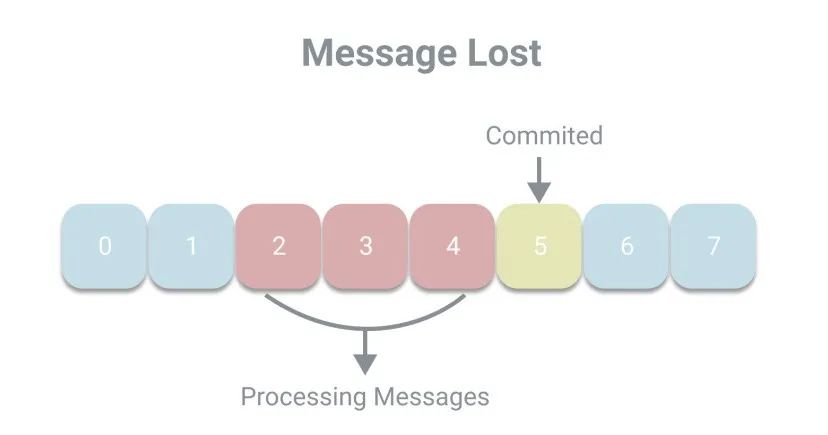
按照線性程序的思維,由于自動提交是延遲提交,即在處理完消息之后進行提交,所以應(yīng)該不會出現(xiàn)消息丟失的現(xiàn)象,也就是已提交的偏移量會大于正在處理的偏移量。但放在多線程環(huán)境中,消息丟失的現(xiàn)象是可能發(fā)生的。例如線程A負責(zé)調(diào)用poll方法拉取消息并放入一個隊列中,由線程B負責(zé)處理消息。如果線程A已經(jīng)提交了偏移量5,而線程B還未處理完2、3、4號消息,這時候發(fā)生宕機,則將丟失消息。
 從上述場景的描述,我們可以知道自動提交是存在風(fēng)險的。所以Kafka除了自動提交,還提供了手動提交的方式,可以細分為同步提交和異步提交,分別對應(yīng)了
從上述場景的描述,我們可以知道自動提交是存在風(fēng)險的。所以Kafka除了自動提交,還提供了手動提交的方式,可以細分為同步提交和異步提交,分別對應(yīng)了KafkaConsumer中的commitSync和commitAsync方法。我們先嘗試使用同步提交修改程序:while?(true)?{
????ConsumerRecords?records?=?consumer.poll(Duration.ofMillis(1000));
????for?(ConsumerRecord?record?:?records)?{
????????System.out.println(record.value());
????}
????consumer.commitSync();;
}
在處理完一批消息后,都會提交偏移量,這樣能減小重復(fù)消費的窗口大小,但是由于是同步提交,所以程序會阻塞等待提交成功后再繼續(xù)處理下一條消息,這樣會限制程序的吞吐量。那我們改為使用異步提交:
while?(true)?{
????ConsumerRecords?records?=?consumer.poll(Duration.ofMillis(1000));
????for?(ConsumerRecord?record?:?records)?{
????????System.out.println(record.value());
????}
????consumer.commitAsync();;
}
異步提交時,程序?qū)⒉粫枞惒教峤辉谔峤皇r也不會進行重試,所以提交是否成功是無法保證的。因此我們可以組合使用兩種提交方式。在輪循中使用異步提交,而當(dāng)關(guān)閉消費者時,再通過同步提交來保證提交成功。
try?{
????while?(true)?{
????????ConsumerRecords?records?=?consumer.poll(Duration.ofMillis(1000));
????????for?(ConsumerRecord?record?:?records)?{
????????????System.out.println(record.value());
????????}
????????consumer.commitAsync();
????}
}?finally?{
????try?{
????????consumer.commitSync();
????}?finally?{
????????consumer.close();
????}
}
上述介紹的兩種無參的提交方式都是提交的poll返回的一個批次的數(shù)據(jù)。若未來得及提交,也會造成重復(fù)消費,如果還想更進一步減少重復(fù)消費,可以在for循環(huán)中為commitAsync和commitSync傳入分區(qū)和偏移量,進行更細粒度的提交,例如每1000條消息我們提交一次:
Map?currentOffsets?=?new?HashMap<>();
int?count?=?0;
while?(true)?{
????ConsumerRecords?records?=?consumer.poll(Duration.ofMillis(1000));
????for?(ConsumerRecord?record?:?records)?{
????????System.out.println(record.value());
????????//?偏移量加1
????????currentOffsets.put(new?TopicPartition(record.topic(),?record.partition()),
???????????????????????????new?OffsetAndMetadata(record.offset()?+?1));
????????if?(count?%?1000?==?0)?{
????????????consumer.commitAsync(currentOffsets,?null);
????????}
????????count++;
????}
}
關(guān)于提交就介紹到這里。在使用消費者的代理中,我們可以看到poll方法是其中最為核心的方法,能夠拉取到我們需要消費的消息。所以接下來,我們一起深入到消費者API的幕后,看看在poll方法中,都發(fā)生了什么,其實現(xiàn)如下:
public?ConsumerRecords?poll(final?Duration?timeout)? {
????return?poll(time.timer(timeout),?true);
}
在我們使用設(shè)置超時時間的poll方法中,會調(diào)用重載方法,第二個參數(shù)includeMetadataInTimeout用于標識是否把元數(shù)據(jù)的獲取算在超時時間內(nèi),這里傳值為true,也就是算入超時時間內(nèi)。下面再看重載的poll方法的實現(xiàn):
private?ConsumerRecords?poll(final?Timer?timer,?final?boolean?includeMetadataInTimeout)? {
????//?1.?獲取鎖并確保消費者沒有關(guān)閉
????acquireAndEnsureOpen();
????try?{
????????//?2.記錄poll開始
????????this.kafkaConsumerMetrics.recordPollStart(timer.currentTimeMs());
????????//?3.檢查是否有訂閱主題
????????if?(this.subscriptions.hasNoSubscriptionOrUserAssignment())?{
????????????throw?new?IllegalStateException("Consumer?is?not?subscribed?to?any?topics?or?assigned?any?partitions");
????????}
????????do?{
????????????//?4.安全的喚醒消費者
????????????client.maybeTriggerWakeup();
????????????//?5.更新偏移量(如果需要的話)
????????????if?(includeMetadataInTimeout)?{
????????????????updateAssignmentMetadataIfNeeded(timer,?false);
????????????}?else?{
????????????????while?(!updateAssignmentMetadataIfNeeded(time.timer(Long.MAX_VALUE),?true))?{
????????????????????log.warn("Still?waiting?for?metadata");
????????????????}
????????????}
????????????// 6.拉取消息
????????????final?Map>>?records?=?pollForFetches(timer);
????????????if?(!records.isEmpty())?{
????????????????//?7.如果拉取到了消息或者有未處理的請求,由于用戶還需要處理未處理的消息
????????????????//?所以會再次發(fā)起拉取消息的請求(異步),提高效率
????????????????if?(fetcher.sendFetches()?>?0?||?client.hasPendingRequests())?{
????????????????????client.transmitSends();
????????????????}
????????????????//?8.調(diào)用消費者攔截器處理
????????????????return?this.interceptors.onConsume(new?ConsumerRecords<>(records));
????????????}
????????}?while?(timer.notExpired());
????????return?ConsumerRecords.empty();
????}?finally?{
????????//?9.釋放鎖
????????release();
????????//?10.記錄poll結(jié)束
????????this.kafkaConsumerMetrics.recordPollEnd(timer.currentTimeMs());
????}
}
我們對上面的代碼逐步分析,首先是第1步acquireAndEnsureOpen方法,獲取鎖并確保消費者沒有關(guān)閉,其實現(xiàn)如下:
private?void?acquireAndEnsureOpen()?{
????acquire();
????if?(this.closed)?{
????????release();
????????throw?new?IllegalStateException("This?consumer?has?already?been?closed.");
????}
}
其中acquire方法用于獲取鎖,為什么這里會要上鎖。這是因為KafkaConsumer是線程不安全的,所以需要上鎖,確保只有一個線程使用KafkaConsumer拉取消息,其實現(xiàn)如下:
private?static?final?long?NO_CURRENT_THREAD?=?-1L;
private?final?AtomicLong?currentThread?=?new?AtomicLong(NO_CURRENT_THREAD);
private?final?AtomicInteger?refcount?=?new?AtomicInteger(0);
private?void?acquire()?{
????long?threadId?=?Thread.currentThread().getId();
????if?(threadId?!=?currentThread.get()?&&?!currentThread.compareAndSet(NO_CURRENT_THREAD,?threadId))
????????throw?new?ConcurrentModificationException("KafkaConsumer?is?not?safe?for?multi-threaded?access");
????refcount.incrementAndGet();
}
用一個原子變量currentThread作為鎖,通過cas操作獲取鎖,如果cas失敗,即獲取鎖失敗,表示發(fā)生了競爭,有多個線程在使用KafkaConsumer,則會拋出ConcurrentModificationException異常,如果cas成功,還會將refcount加一,用于重入。
再看第2、3步,記錄poll的開始以及檢查是否有訂閱主題。然后進入do-while循環(huán),如果沒有拉取到消息,將在不超時的情況下一直輪循。
第4步,安全的喚醒消費者,并不是喚醒,而是檢查是否有喚醒的風(fēng)險,如果程序在執(zhí)行不可中斷的方法或是收到中斷請求,會拋出異常,這里我還不是很明白,先放一下。
第5步,更新偏移量,就是我們在前文說的在進行拉取操作前會先檢查是否可以進行偏移量提交。
第6步,pollForFetches方法拉取消息,其實現(xiàn)如下:
private?Map>>?pollForFetches(Timer?timer)?{
????long?pollTimeout?=?coordinator?==?null???timer.remainingMs()?:
????Math.min(coordinator.timeToNextPoll(timer.currentTimeMs()),?timer.remainingMs());
????//?1.如果消息已經(jīng)有了,則立即返回
????final?Map>>?records?=?fetcher.fetchedRecords();
????if?(!records.isEmpty())?{
????????return?records;
????}
????//?2.準備拉取請求
????fetcher.sendFetches();
????if?(!cachedSubscriptionHashAllFetchPositions?&&?pollTimeout?>?retryBackoffMs)?{
????????pollTimeout?=?retryBackoffMs;
????}
????Timer?pollTimer?=?time.timer(pollTimeout);
????//?3.發(fā)送拉取請求
????client.poll(pollTimer,?()?->?{
????????return?!fetcher.hasAvailableFetches();
????});
????timer.update(pollTimer.currentTimeMs());
????//?3.返回消息
????return?fetcher.fetchedRecords();
}
如果fetcher已經(jīng)有消息了則立即返回,這里和下面將要講的第7步對應(yīng)。如果沒有消息則使用Fetcher準備拉取請求然后再通過ConsumerNetworkClient發(fā)送請求,最后返回消息。
為啥消息會已經(jīng)有了呢,我們回到poll的第7步,如果拉取到了消息或者有未處理的請求,由于用戶還需要處理未處理的消息,這時候可以使用異步的方式發(fā)起下一次的拉取消息的請求,將數(shù)據(jù)提前拉取,減少網(wǎng)絡(luò)IO的等待時間,提高程序的效率。
第8步,調(diào)用消費者攔截器處理,就像KafkaProducer中有ProducerInterceptor,在KafkaConsumer中也有ConsumerInterceptor,用于處理返回的消息,處理完后,再返回給用戶。
第9、10步,釋放鎖和記錄poll結(jié)束,對應(yīng)了第1、2步。
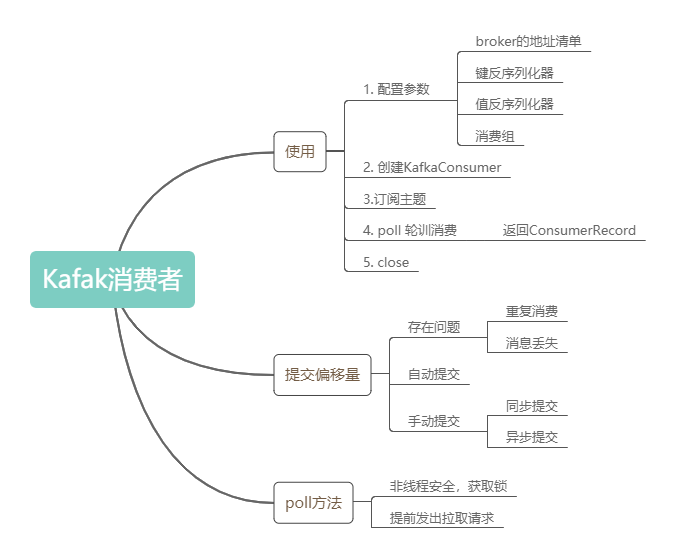
對KafkaConsumer的poll方法就分析到這里。最后用一個思維導(dǎo)圖回顧下文中較為重要的知識點:
參考
- 《Kafka權(quán)威指南》
- 《深入理解Kafka核心設(shè)計和實踐原理》
- 你絕對能看懂的Kafka源代碼分析-KafkaConsumer類代碼分析:?https://blog.csdn.net/liyiming2017/article/details/89187474
- Kafka消費者源碼解析之一KafkaConsumer:?https://blog.csdn.net/lt793843439/article/details/89511405
完
? ? ? ?
 ???●消息系統(tǒng)概述●圖解 Kafka 中的基本概念
???●消息系統(tǒng)概述●圖解 Kafka 中的基本概念●Kafka 生產(chǎn)者的使用和原理
覺得不錯,點個在看~
