
Kafka 中副本機制的設計和原理
在《圖解 Kafka 中的基本概念》中已經(jīng)對副本進行了介紹。我們先回顧下,Kafka中一個分區(qū)可以擁有多個副本,副本可分布于多臺機器上。而在多個副本中,只會有一個Leader副本與客戶端交互,也就是讀寫數(shù)據(jù)。其他則作為Follower副本,負責同步Leader的數(shù)據(jù),當Leader宕機時,從Follower選舉出新的Leader,從而解決分區(qū)單點問題。本文將繼續(xù)深入了解Kafka中副本機制的設計和原理。
好處
副本機制的使用在計算機的世界里是很常見的,比如MySQL、ZooKeeper、CDN等都有使用副本機制。使用副本機制所能帶來的好處有以下幾種:
提供數(shù)據(jù)冗余,提高可用性; 提供擴展性,增加讀操作吞吐量; 改善數(shù)據(jù)局部,降低系統(tǒng)延時。
但并不是每個好處都能獲得,這還是和具體的設計有關(guān),比如本文的主角Kafka,只具有第一個好處,即提高可用性。這是因為副本中只有Leader可以和客戶端交互,進行讀寫,其他副本是只能同步,不能分擔讀寫壓力。為什么這么設計?這和Kafka作為消息系統(tǒng)有關(guān)。比如當我們使用生產(chǎn)者成功寫入消息后,希望消費者能立馬讀取到剛生產(chǎn)的消息,這也被稱作“Read-Your-Writes”一致性,可理解為寫后立即讀,要實現(xiàn)這種一致性,如果是只在Leader上讀寫是很方便實現(xiàn)的。而且也同時保證了“Monotomic Reads”一致性,即單調(diào)讀一致性,不會出現(xiàn)消息一會能讀到,一會讀不到的情況。你可能會問,為什么不讓多個副本都可以讀,來提高讀操作吞吐量,同時加入其它機制來保證這兩個一致性。筆者的理解是在Kafka中已經(jīng)引入了分區(qū)和消費組機制,來提供擴展性,提高讀吞吐量,所以這里沒必要再為了提高讀吞吐量,而讓系統(tǒng)更復雜。
ISR副本
我們已經(jīng)了解到當Leader宕機時,我們要從Follower中選舉出新的Leader,但并不是所有的Follower都有資格參與選舉。因為有的Follower的同步情況滯后,如果讓他成為Leader將會導致消息丟失。而為了避免這個情況,Kafka引入了ISR(In-Sync Replica)副本的概念,這是一個集合,里面存放的是和Leader保持同步的副本并含有Leader。這是一個動態(tài)調(diào)整的集合,當副本由同步變?yōu)闇髸r會從集合中剔除,而當副本由滯后變?yōu)橥綍r又會加入到集合中。
那么如何判斷一個副本是同步還是滯后呢?Kafka在0.9版本之前,是根據(jù)replica.lag.max.messages參數(shù)來判斷,其含義是同步副本所能落后的最大消息數(shù),當Follower上的最大偏移量落后Leader大于replica.lag.max.messages時,就認為該副本是不同步的了,會從ISR中移除。如果ISR的值設置得過小,會導致Follower經(jīng)常被踢出ISR,而如果設置過大,則當Leader宕機時,會造成較多消息的丟失。在實際使用時,很難給出一個合理值,這是因為當生產(chǎn)者為了提高吞吐量而調(diào)大batch.size時,會發(fā)送更多的消息到Leader上,這時候如果不增大replica.lag.max.messages,則會有Follower頻繁被踢出ISR的現(xiàn)象,而當Follower發(fā)生Fetch請求同步后,又被加入到ISR中,ISR將頻繁變動。鑒于該參數(shù)難以設定,Kafka在0.9版本引入了一個新的參數(shù)replica.lag.time.max.ms,默認10s,含義是當Follower超過10s沒發(fā)送Fetch請求同步Leader時,就會認為不同步而被踢出ISR。從時間維度來考量,能夠很好地避免生產(chǎn)者發(fā)送大量消息到Leader副本導致分區(qū)ISR頻繁收縮和擴張的問題。
Unclear Leader選舉
當ISR集合為空時,即沒有同步副本(Leader也掛了),無法選出下一個Leader,Kafka集群將會失效。而為了提高可用性,Kafka提供了unclean.leader.election.enable參數(shù),當設置為true且ISR集合為空時,會進行Unclear Leader選舉,允許在非同步副本中選出新的Leader,從而提高Kafka集群的可用性,但這樣會造成消息丟失。在允許消息丟失的場景中,是可以開啟此參數(shù)來提高可用性的。而其他情況,則不建議開啟,而是通過其他手段來提高可用性。
LEO和HW
下面我們一起了解副本同步的原理。副本的本質(zhì)其實是一個消息日志,為了讓副本正常同步,需要通過一些變量記錄副本的狀態(tài),如下圖所示:
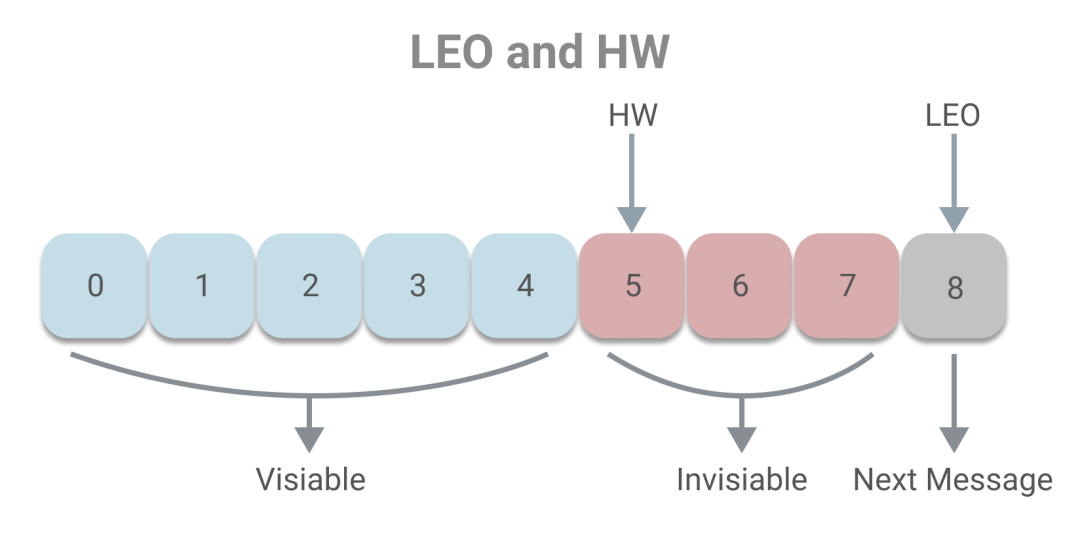
其中LEO(Last End Offset)記錄了日志的下一條消息偏移量,即當前最新消息的偏移量加一。而HW(High Watermark)界定了消費者可見的消息,消費者可以消費小于HW的消息,而大于等于HW的消息將無法消費。HW和LEO的關(guān)系是HW一定小于LEO。下面介紹下HW的概念,其可翻譯為高水位或高水印,這一概念通常用于在流式處理領域(如Flink、Spark等),流式系統(tǒng)將保證在HW為t時刻時,創(chuàng)建時間小于等于t時刻的所有事件都已經(jīng)到達或可被觀測到。而在Kafka中,HW的概念和時間無關(guān),而是和偏移量有關(guān),主要目的是為了保證一致性。試想如果一個消息到達了Leader,而Follower副本還未來得及同步,但該消息能已被消費者消費了,這時候Leader宕機,F(xiàn)ollower副本中選出新的Leader,消息將丟失,出現(xiàn)不一致的現(xiàn)象。所以Kafka引入HW的概念,當消息被同步副本同步完成時,才讓消息可被消費。
上述即是LEO和HW的基本概念,下面我們看下具體是如何工作的。
在每個副本中都存有LEO和HW,而Leader副本中除了存有自身的LEO和HW,還存儲了其他Follower副本的LEO和HW值,為了區(qū)分我們把Leader上存儲的Follower副本的LEO和HW值叫做遠程副本的LEO和HW值,如下圖所示:
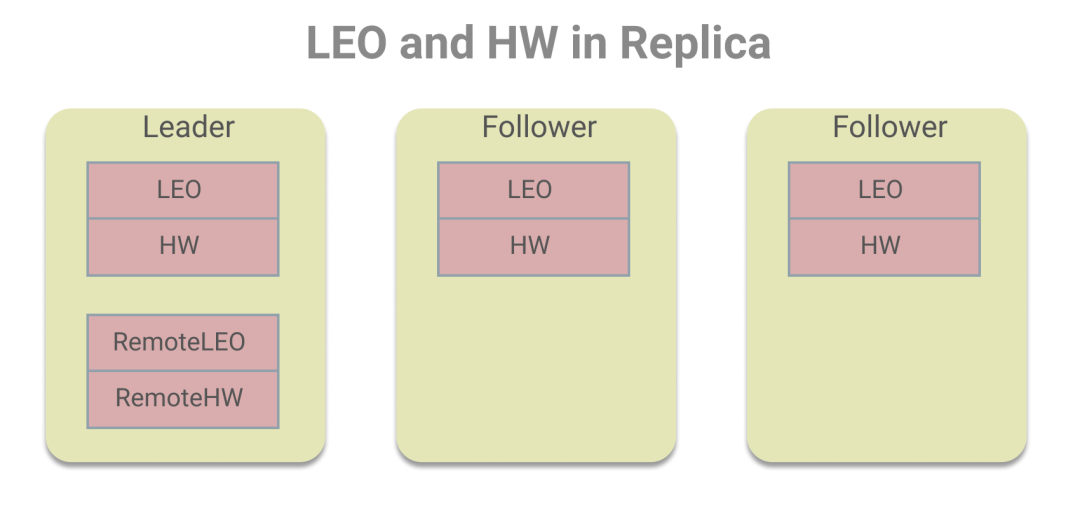
之所以這么設計,是為了HW的更新,Leader需保證HW是ISR副本集合中LEO的最小值。關(guān)于具體的更新,我們分為Follower副本和Leader副本來看。
Follower副本更新LEO和HW的時機只有向Leader拉取了消息之后,會用當前的偏移量加1來更新LEO,并且用Leader的HW值和當前LEO的最小值來更新HW:
CurrentOffset?+?1?->?LEO
min(LEO,?LeaderHW)?->?HW
LEO的更新,很好理解。那為什么HW要取LEO和LeaderHW的最小值,為什么不直接取LeaderHW,LeaderHW不是一定大于LEO嗎?我們在前文簡單的提到了LeaderHW是根據(jù)同步副本來決定,所以LeaderHW一定小于所有同步副本的LEO,而并不一定小于非同步副本的LEO,所以如果一個非同步副本在拉取消息,那LEO是會小于LeaderHW的,則應用當前LEO值來更新HW。
說完了Follower副本上LEO和HW的更新,下面看Leader副本。
正常情況下Leader副本的更新時機有兩個:一、收到生產(chǎn)者的消息;二、被Follower拉取消息。
當收到生產(chǎn)者消息時,會用當前偏移量加1來更新LEO,然后取LEO和遠程ISR副本中LEO的最小值更新HW。
CurrentOffset?+?1?->?LEO
min(LEO,?RemoteIsrLEO)?->?HW
而當Follower拉取消息時,會更新Leader上存儲的Follower副本LEO,然后判斷是否需要更新HW,更新的方式和上述相同。
FollowerLEO?->?RemoteLEO
min(LEO,?RemoteIsrLEO)?->?HW
除了這兩種正常情況,而當發(fā)生故障時,例如Leader宕機,Follower被選為新的Leader,會嘗試更新HW。還有副本被踢出ISR時,也會嘗試更新HW。
下面我們看下更新LEO和HW的示例,假設分區(qū)中有兩個副本,min.insync.replica=1。
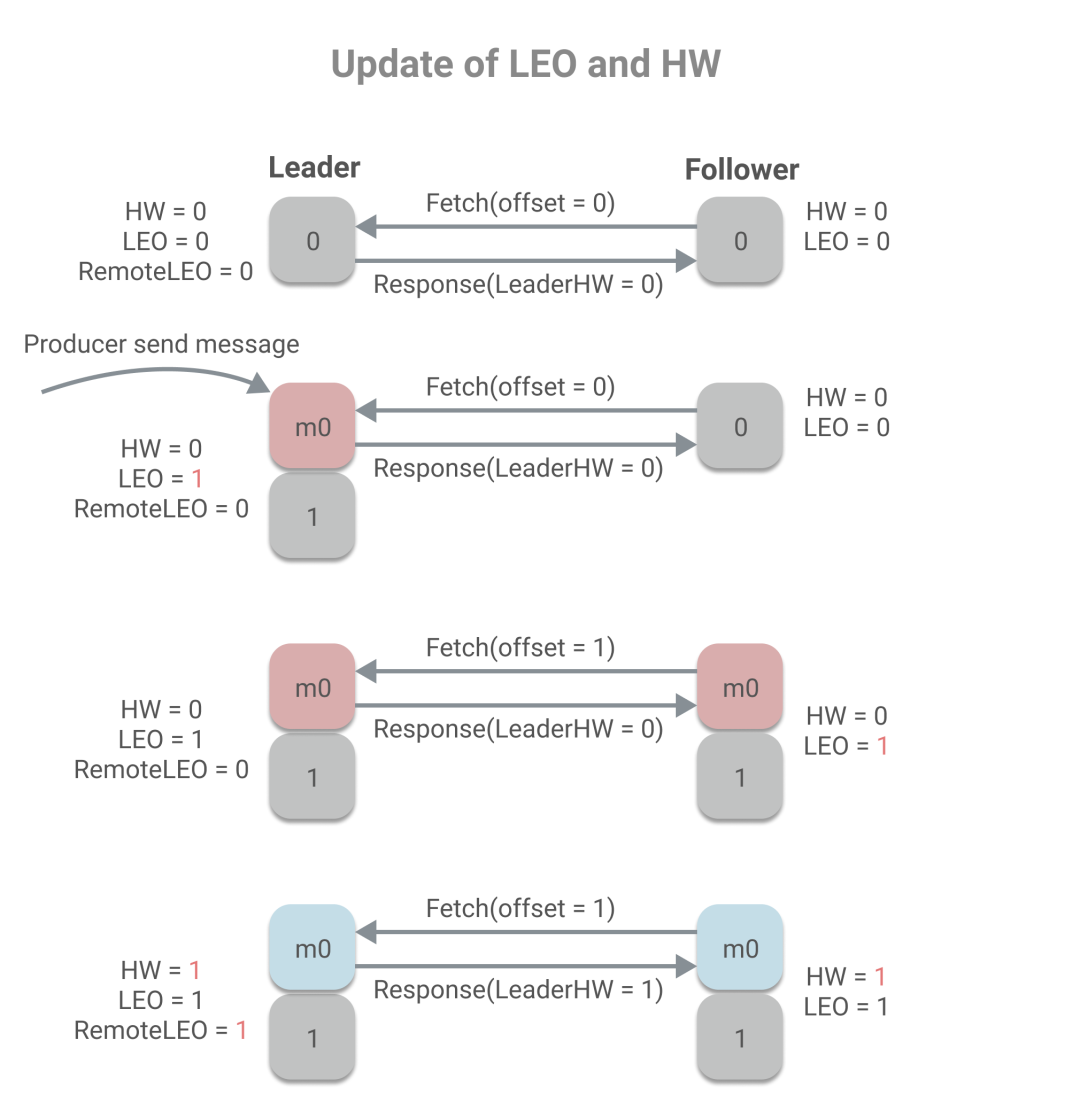
從上述過程中,我們可以看到remoteLEO、LeaderHW和FollowerHW的更新發(fā)生于Follower更新LEO后的第二輪Fetch請求,而這也意味著,更新需要額外一次Fetch請求。而這也將導致在Leader切換時,會存在數(shù)據(jù)丟失和數(shù)據(jù)不一致的問題。下面是數(shù)據(jù)丟失的示例:
當B作為Follower已經(jīng)Fetch了最新的消息,但是在發(fā)送第二輪Fetch時,未來得及處理響應,宕機了。當重啟時,會根據(jù)HW更新LEO,將發(fā)生日志截斷,消息m1被丟棄。這時再發(fā)送Fetch請求給A,A宕機了,則B未能同步到消息m1,同時B被選為Leader,而當A重啟時,作為Follower同步B的消息時,會根據(jù)A的HW值更新HW和LEO,因此由2變成了1,也將發(fā)生日志截斷,而已發(fā)送成功的消息m1將永久丟失。
數(shù)據(jù)不一致的情況如下:
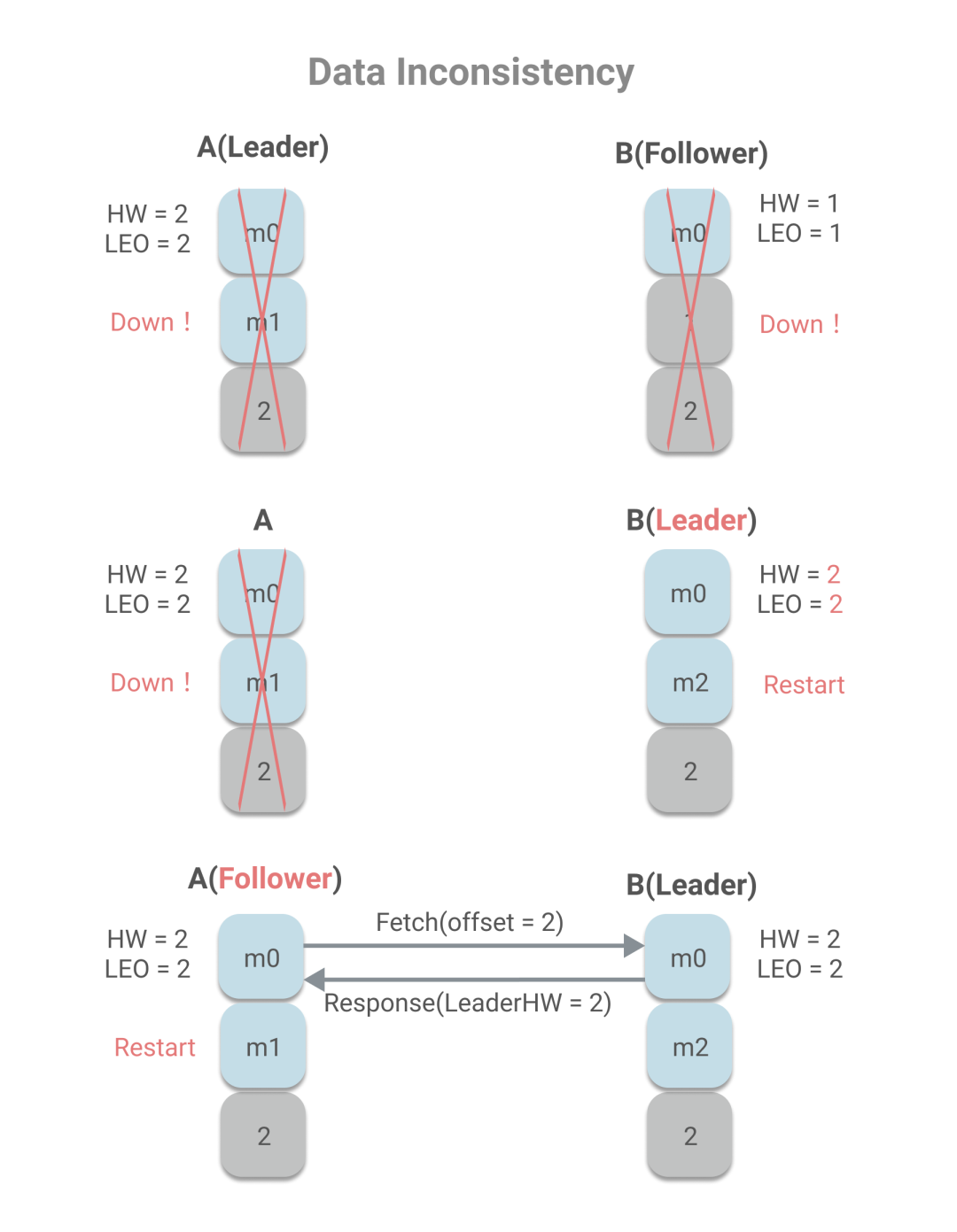
A作為Leader,A已寫入m0、m1兩條消息,且HW為2,而B作為Follower,只有m0消息,且HW為1。若A、B同時宕機,且B重啟時,A還未恢復,則B被選為Leader。
集群處于上述這種狀態(tài)有兩種情況可能導致,一、宕機前,B不在ISR中,因此A未待B同步,即更新了HW,且unclear leader為true,允許B成為Leader;二、宕機前,B同步了消息m1,且發(fā)送了第二輪Fetch請求,Leader更新HW,但B未將消息m1落地到磁盤,宕機了,當再重啟時,消息m1丟失,只剩m0。
在B重啟作為Leader之后,收到消息m2。A宕機重啟后向成為Leader的B發(fā)送Fetch請求,發(fā)現(xiàn)自己的HW和B的HW一致,都是2,因此不會進行消息截斷,而這也造成了數(shù)據(jù)不一致。
Leader Epoch
為了解決HW可能造成的數(shù)據(jù)丟失和數(shù)據(jù)不一致問題,Kafka引入了Leader Epoch機制,在每個副本日志目錄下都有一個leader-epoch-checkpoint文件,用于保存Leader Epoch信息,其內(nèi)容示例如下:
0?0
1?300
2?500
上面每一行為一個Leader Epoch,分為兩部分,前者Epoch,表示Leader版本號,是一個單調(diào)遞增的正整數(shù),每當Leader變更時,都會加1,后者StartOffset,為每一代Leader寫入的第一條消息的位移。例如第0代Leader寫的第一條消息位移為0,而第1代Leader寫的第一條消息位移為300,也意味著第0代Leader在寫了0-299號消息后掛了,重新選出了新的Leader。下面我們看下Leader Epoch如何工作:
當副本成為Leader時:
當收到生產(chǎn)者發(fā)來的第一條消息時,會將新的epoch和當前LEO添加到leader-epoch-checkpoint文件中。
當副本成為Follower時:
向Leader發(fā)送LeaderEpochRequest請求,請求內(nèi)容中含有Follower當前本地的最新Epoch; Leader將返回給Follower的響應中含有一個LastOffset,其取值規(guī)則為: 若FollowerLastEpoch = LeaderLastEpoch,則取Leader LEO; 否則,取大于FollowerLastEpoch的第一個Leader Epoch中的StartOffset。 Follower在拿到LastOffset后,若LastOffset < LEO,將截斷日志; Follower開始正常工作,發(fā)送Fetch請求;
我們再回顧看下數(shù)據(jù)丟失和數(shù)據(jù)不一致的場景,在應用了LeaderEpoch后發(fā)生什么改變:
當B作為Follower已經(jīng)Fetch了最新的消息,但是發(fā)送第二輪Fetch時,未來得及處理響應,宕機了。當重啟時,會向A發(fā)送LeaderEpochRequest請求。如果A沒宕機,由于 FollowerLastEpoch = LeaderLastEpoch,所以將LeaderLEO,即2作為LastOffset給A,又因為LastOffset=LEO,所以不會截斷日志。這種情況比較簡單,而圖中所畫的情況是A宕機的情況,沒返回LeaderEpochRequest的響應的情況。這時候B會被選作Leader,將當前LEO和新的Epoch寫進leader-epoch-checkpoint文件中。當A作為Follower重啟后,發(fā)送LeaderEpochRequest請求,包含最新的epoch值0,當B收到請求后,由于FollowerLastEpoch < LeaderLastEpoch,所以會取大于FollowerLastEpoch的第一個Leader Epoch中的StartOffset,即2。當A收到響應時,由于LEO = LastOffset,所以不會發(fā)生日志截斷,也就不會丟失數(shù)據(jù)。
下面是數(shù)據(jù)不一致情況:
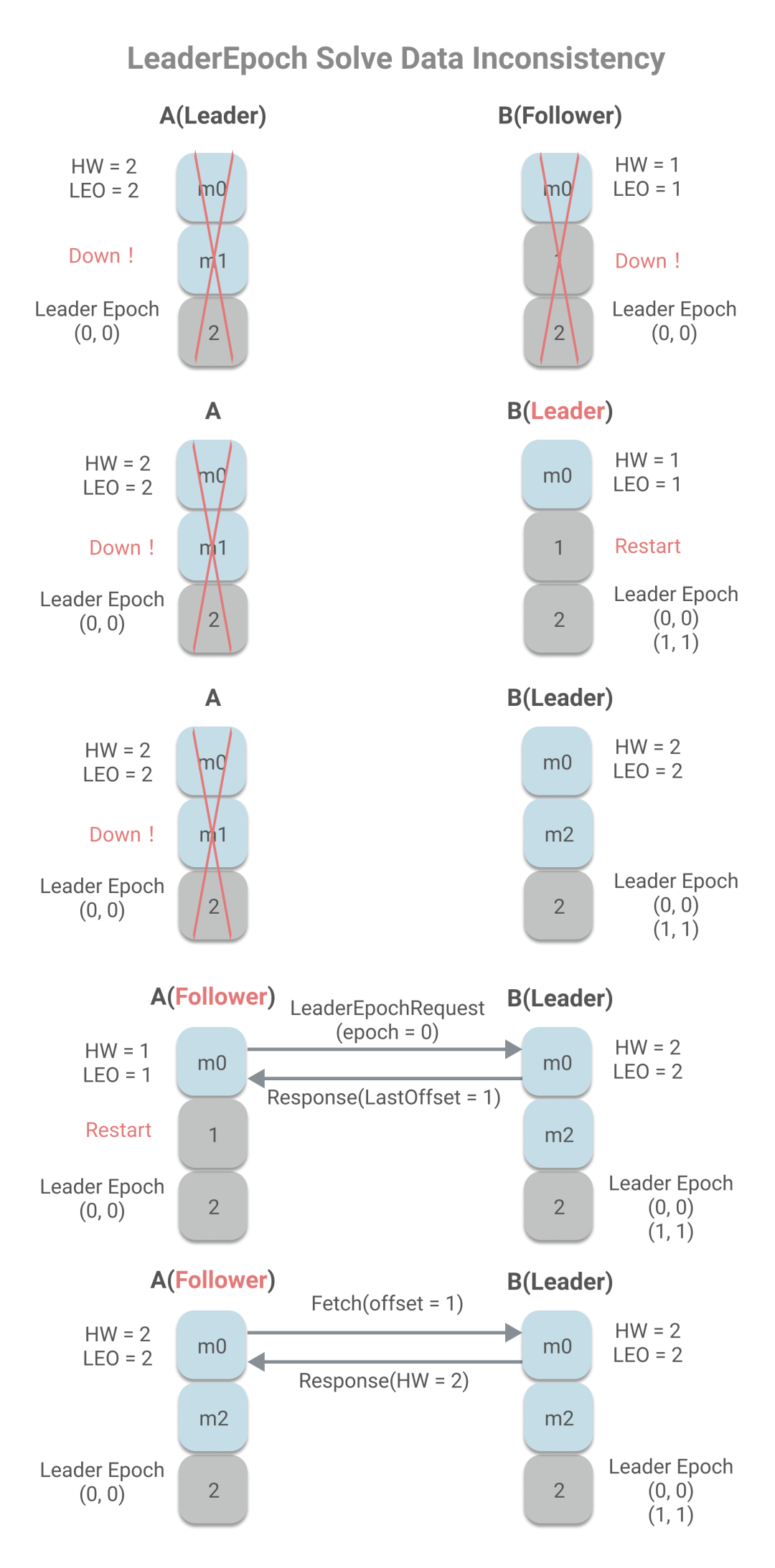
A作為Leader,A已寫入m0、m1兩條消息,且HW為2,而B作為Follower,只有消息m0,且HW為1,A、B同時宕機。B重啟,被選為Leader,將寫入新的LeaderEpoch(1, 1)。B開始工作,收到消息m2時。這是A重啟,將作為Follower將發(fā)送LeaderEpochRequert(FollowerLastEpoch=0),B返回大于FollowerLastEpoch的第一個LeaderEpoch的StartOffset,即1,小于當前LEO值,所以將發(fā)生日志截斷,并發(fā)送Fetch請求,同步消息m2,避免了消息不一致問題。
你可能會問,m2消息那豈不是丟失了?是的,m2消息丟失了,但這種情況的發(fā)送的根本原因在于min.insync.replicas的值設置為1,即沒有任何其他副本同步的情況下,就認為m2消息為已提交狀態(tài)。LeaderEpoch不能解決min.insync.replicas為1帶來的數(shù)據(jù)丟失問題,但是可以解決其所帶來的數(shù)據(jù)不一致問題。而我們之前所說能解決的數(shù)據(jù)丟失問題,是指消息已經(jīng)成功同步到Follower上,但因HW未及時更新引起的數(shù)據(jù)丟失問題。
參考
1. 《Kafka核心技術(shù)與實戰(zhàn)》
2. Kafka ISR副本同步機制:https://objcoding.com/2019/11/05/kafka-isr
3. 圖解Kafka水印備份機制:http://objcoding.com/2019/10/31/kafka-hw
完
? ? ? ?
 ???
???覺得不錯,點個在看~
