Python爬取東方財富網(wǎng)資金流向數(shù)據(jù)并存入MySQL
第一步:程序及應(yīng)用的準(zhǔn)備
首先我們需要安裝selenium庫,使用命令pip install selenium;然后我們需要下載對應(yīng)的chromedriver,,安裝教程:。我們的chromedriver.exe應(yīng)該是在C:\Program Files\Google\Chrome\Application中(即讓它跟chrome.exe在同一個文件下)。
下載完成后,我們還需要做兩件事:1.配置環(huán)境變量;
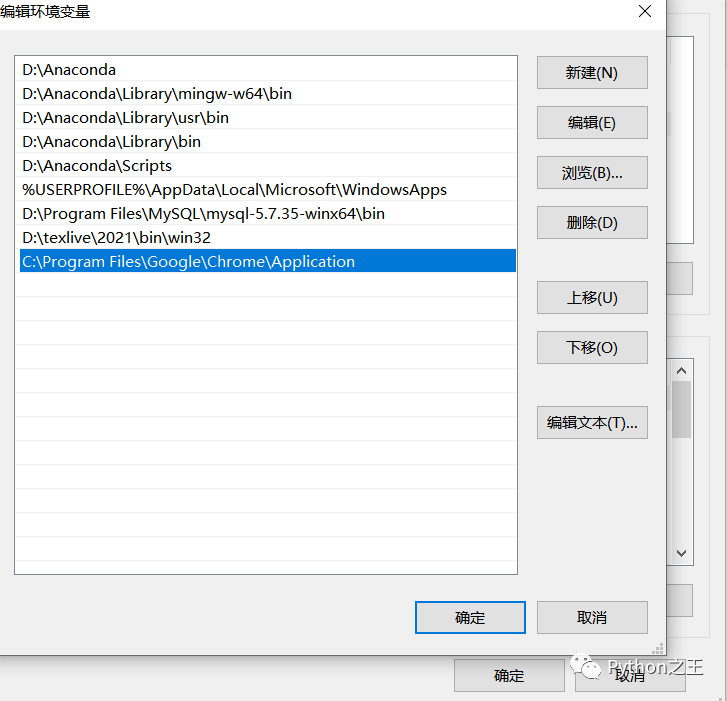
2.將chromedriver.exe拖到python文件夾里,因為我用的是anaconda,所以我直接是放入D:\Anaconda中的。

此時,我們所需的應(yīng)用已經(jīng)準(zhǔn)備好了。
第二步:進入我們要爬取的網(wǎng)頁(),按F12進入調(diào)試模式.
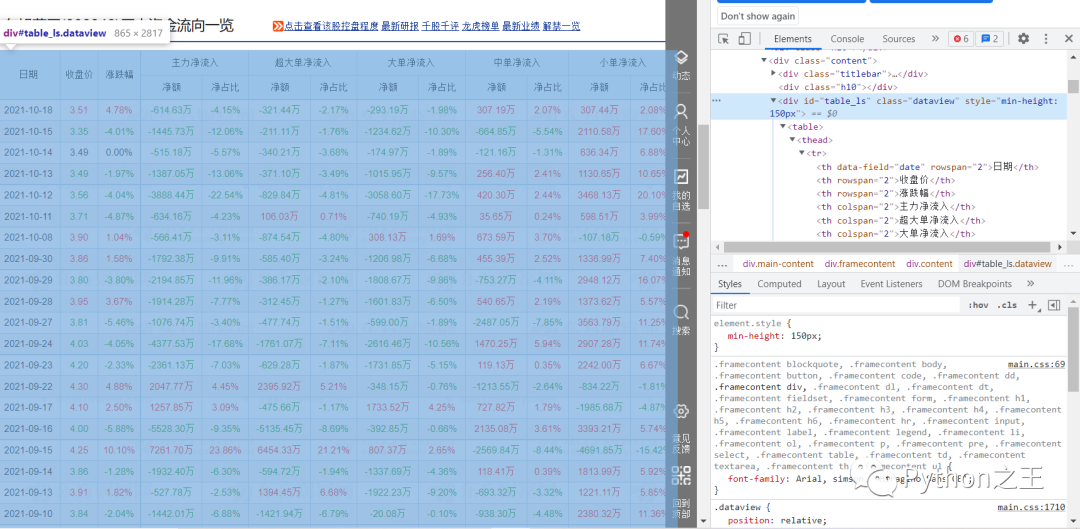
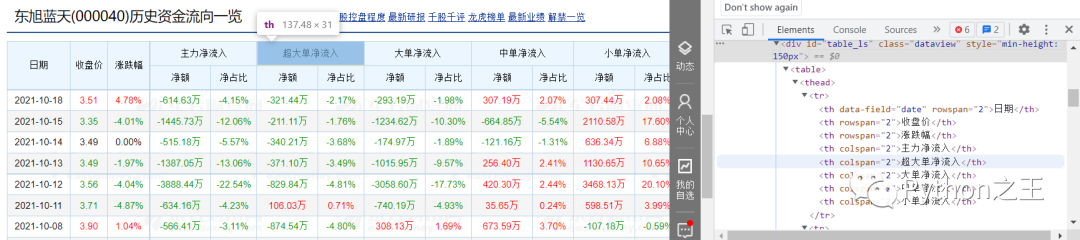
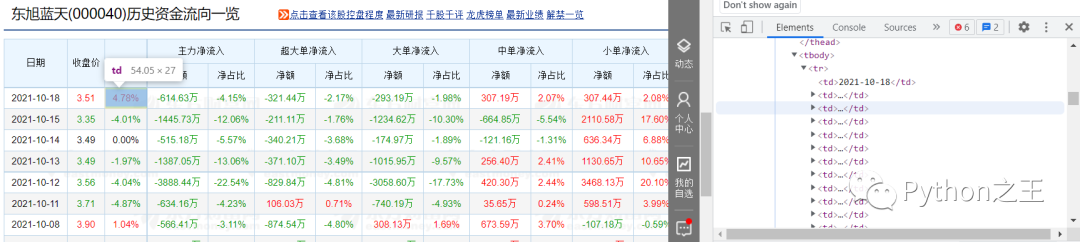
當(dāng)我們依次點擊右側(cè)div時,我們可以發(fā)現(xiàn),我們想要爬取的數(shù)據(jù)對應(yīng)的代碼為右側(cè)藍色部分,而下方的
| 開始,以 | 結(jié)束的;在 | 開始,以 | 結(jié)束的。至此,我們對要爬取的數(shù)據(jù)的構(gòu)成有了一個大概的認(rèn)知。 第三步:編寫程序 etree.HTML()可以用來解析字符串格式的HTML文檔對象,將傳進去的字符串轉(zhuǎn)變成_Element對象。作為_Element對象,可以方便的使用getparent()、remove()、xpath()等方法。 options常用屬性及方法為:
div[@class="dataview"表示我們通過class屬性的值定位到我們要爬取的表格div,‘/table’則是表示 的下一級
|
|---|