
模型壓縮 | 知識蒸餾經(jīng)典解讀

極市導(dǎo)讀
?本文基于2015年Hinton發(fā)表的一篇經(jīng)典文章:Distilling the Knowledge in a Neural Network,闡述了知識蒸餾的背景和動機(jī)以及知識蒸餾的兩種具體方法,文章末尾對"溫度“這個名詞進(jìn)行了探討。>>加入極市CV技術(shù)交流群,走在計(jì)算機(jī)視覺的最前沿
寫在前面
知識蒸餾是一種模型壓縮方法,是一種基于“教師-學(xué)生網(wǎng)絡(luò)思想”的訓(xùn)練方法,由于其簡單,有效,在工業(yè)界被廣泛應(yīng)用。這一技術(shù)的理論來自于2015年Hinton發(fā)表的一篇神作:Distilling the Knowledge in a Neural NetworkKnowledge Distillation,簡稱KD,顧名思義,就是將已經(jīng)訓(xùn)練好的模型包含的知識(”Knowledge”),蒸餾(“Distill”)提取到另一個模型里面去。今天,我們就來簡單讀一下這篇論文,力求用簡單的語言描述論文作者的主要思想。在本文中,我們將從背景和動機(jī)講起,然后著重介紹“知識蒸餾”的方法,最后我會討論“溫度“這個名詞:
「溫度」: 我們都知道“蒸餾”需要在高溫下進(jìn)行,那么這個“蒸餾”的溫度代表了什么,又是如何選取合適的溫度?
介紹
論文提出的背景:
雖然在一般情況下,我們不會去區(qū)分訓(xùn)練和部署使用的模型,但是訓(xùn)練和部署之間存在著一定的不一致性:
在訓(xùn)練過程中,我們需要使用復(fù)雜的模型,大量的計(jì)算資源,以便從非常大、高度冗余的數(shù)據(jù)集中提取出信息。在實(shí)驗(yàn)中,效果最好的模型往往規(guī)模很大,甚至由多個模型集成得到。而大模型不方便部署到服務(wù)中去,常見的瓶頸如下:
推斷速度慢 對部署資源要求高(內(nèi)存,顯存等) 在部署時,我們對延遲以及計(jì)算資源都有著嚴(yán)格的限制。
因此,模型壓縮(在保證性能的前提下減少模型的參數(shù)量)成為了一個重要的問題。而「模型蒸餾」屬于模型壓縮的一種方法。插句題外話,我們可以從模型參數(shù)量和訓(xùn)練數(shù)據(jù)量之間的相對關(guān)系來理解underfitting和overfitting。AI領(lǐng)域的從業(yè)者可能對此已經(jīng)習(xí)以為常,但是為了力求讓小白也能讀懂本文,還是引用我同事的解釋(我印象很深)形象地說明一下:
模型就像一個容器,訓(xùn)練數(shù)據(jù)中蘊(yùn)含的知識就像是要裝進(jìn)容器里的水。
當(dāng)數(shù)據(jù)知識量(水量)超過模型所能建模的范圍時(容器的容積),加再多的數(shù)據(jù)也不能提升效果(水再多也裝不進(jìn)容器),因?yàn)槟P偷谋磉_(dá)空間有限(容器容積有限),就會造成underfitting; 而當(dāng)模型的參數(shù)量大于已有知識所需要的表達(dá)空間時(容積大于水量,水裝不滿容器),就會造成overfitting,即模型的bias會增大(想象一下?lián)u晃半滿的容器,里面水的形狀是不穩(wěn)定的)。
“思想歧路”
上面容器和水的比喻非常經(jīng)典和貼切,但是會引起一個誤解: 人們在直覺上會覺得,要保留相近的知識量,必須保留相近規(guī)模的模型。也就是說,一個模型的參數(shù)量基本決定了其所能捕獲到的數(shù)據(jù)內(nèi)蘊(yùn)含的“知識”的量。這樣的想法是基本正確的,但是需要注意的是:
模型的參數(shù)量和其所能捕獲的“知識“量之間并非穩(wěn)定的線性關(guān)系(下圖中的1),而是接近邊際收益逐漸減少的一種增長曲線(下圖中的2和3) 完全相同的模型架構(gòu)和模型參數(shù)量,使用完全相同的訓(xùn)練數(shù)據(jù),能捕獲的“知識”量并不一定完全相同,另一個關(guān)鍵因素是訓(xùn)練的方法。合適的訓(xùn)練方法可以使得在模型參數(shù)總量比較小時,盡可能地獲取到更多的“知識”(下圖中的3與2曲線的對比). 
知識蒸餾的理論依據(jù)
Teacher Model和Student Model
知識蒸餾使用的是Teacher—Student模型,其中teacher是“知識”的輸出者,student是“知識”的接受者。知識蒸餾的過程分為2個階段:
原始模型訓(xùn)練: 訓(xùn)練”Teacher模型”, 簡稱為Net-T,它的特點(diǎn)是模型相對復(fù)雜,也可以由多個分別訓(xùn)練的模型集成而成。我們對”Teacher模型”不作任何關(guān)于模型架構(gòu)、參數(shù)量、是否集成方面的限制,唯一的要求就是,對于輸入X, 其都能輸出Y,其中Y經(jīng)過softmax的映射,輸出值對應(yīng)相應(yīng)類別的概率值。 精簡模型訓(xùn)練: 訓(xùn)練”Student模型”, 簡稱為Net-S,它是參數(shù)量較小、模型結(jié)構(gòu)相對簡單的單模型。同樣的,對于輸入X,其都能輸出Y,Y經(jīng)過softmax映射后同樣能輸出對應(yīng)相應(yīng)類別的概率值。
在本論文中,作者將問題限定在「分類問題」下,或者其他本質(zhì)上屬于分類問題的問題,該類問題的共同點(diǎn)是模型最后會有一個softmax層,其輸出值對應(yīng)了相應(yīng)類別的概率值。
知識蒸餾的關(guān)鍵點(diǎn)
如果回歸機(jī)器學(xué)習(xí)最最基礎(chǔ)的理論,我們可以很清楚地意識到一點(diǎn)(而這一點(diǎn)往往在我們深入研究機(jī)器學(xué)習(xí)之后被忽略): 機(jī)器學(xué)習(xí)「最根本的目的」在于訓(xùn)練出在某個問題上泛化能力強(qiáng)的模型。
泛化能力強(qiáng): 在某問題的所有數(shù)據(jù)上都能很好地反應(yīng)輸入和輸出之間的關(guān)系,無論是訓(xùn)練數(shù)據(jù),還是測試數(shù)據(jù),還是任何屬于該問題的未知數(shù)據(jù)。
而現(xiàn)實(shí)中,由于我們不可能收集到某問題的所有數(shù)據(jù)來作為訓(xùn)練數(shù)據(jù),并且新數(shù)據(jù)總是在源源不斷的產(chǎn)生,因此我們只能退而求其次,訓(xùn)練目標(biāo)變成在已有的訓(xùn)練數(shù)據(jù)集上建模輸入和輸出之間的關(guān)系。由于訓(xùn)練數(shù)據(jù)集是對真實(shí)數(shù)據(jù)分布情況的采樣,訓(xùn)練數(shù)據(jù)集上的最優(yōu)解往往會多少偏離真正的最優(yōu)解(這里的討論不考慮模型容量)。而在知識蒸餾時,由于我們已經(jīng)有了一個泛化能力較強(qiáng)的Net-T,我們在利用Net-T來蒸餾訓(xùn)練Net-S時,可以直接讓Net-S去學(xué)習(xí)Net-T的泛化能力。一個很直白且高效的遷移泛化能力的方法就是使用softmax層輸出的類別的概率來作為“soft target”。
傳統(tǒng)training過程(hard targets): 對ground truth求極大似然 KD的training過程(soft targets): 用large model的class probabilities作為soft targets
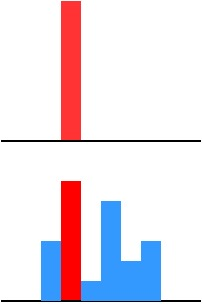
「為什么?」
softmax層的輸出,除了正例之外,負(fù)標(biāo)簽也帶有大量的信息,比如某些負(fù)標(biāo)簽對應(yīng)的概率遠(yuǎn)遠(yuǎn)大于其他負(fù)標(biāo)簽。而在傳統(tǒng)的訓(xùn)練過程(hard target)中,所有負(fù)標(biāo)簽都被統(tǒng)一對待。也就是說,KD的訓(xùn)練方式使得每個樣本給Net-S帶來的信息量大于傳統(tǒng)的訓(xùn)練方式。舉個例子來說明一下: 在手寫體數(shù)字識別任務(wù)MNIST中,輸出類別有10個。假設(shè)某個輸入的“2”更加形似”3”,softmax的輸出值中”3”對應(yīng)的概率為0.1,而其他負(fù)標(biāo)簽對應(yīng)的值都很小,而另一個”2”更加形似”7”,”7”對應(yīng)的概率為0.1。這兩個”2”對應(yīng)的hard target的值是相同的,但是它們的soft target卻是不同的,由此我們可見soft target蘊(yùn)含著比hard target多的信息。并且soft target分布的熵相對高時,其soft target蘊(yùn)含的知識就更豐富。
這就解釋了為什么通過蒸餾的方法訓(xùn)練出的Net-S相比使用完全相同的模型結(jié)構(gòu)和訓(xùn)練數(shù)據(jù)只使用hard target的訓(xùn)練方法得到的模型,擁有更好的泛化能力。
softmax函數(shù)
先回顧一下原始的softmax函數(shù):
但要是直接使用softmax層的輸出值作為soft target, 這又會帶來一個問題: 當(dāng)softmax輸出的概率分布熵相對較小時,負(fù)標(biāo)簽的值都很接近0,對損失函數(shù)的貢獻(xiàn)非常小,小到可以忽略不計(jì)。因此”溫度”這個變量就派上了用場。下面的公式時加了溫度這個變量之后的softmax函數(shù):
這里的T就是「溫度」。 原來的softmax函數(shù)是T = 1的特例。T越高,softmax的output probability distribution越趨于平滑,其分布的熵越大,負(fù)標(biāo)簽攜帶的信息會被相對地放大,模型訓(xùn)練將更加關(guān)注負(fù)標(biāo)簽。
知識蒸餾的具體方法
通用的知識蒸餾方法
第一步是訓(xùn)練Net-T;第二步是在高溫T下,蒸餾Net-T的知識到Net-S 
訓(xùn)練Net-T的過程很簡單,下面詳細(xì)講講第二步:高溫蒸餾的過程。高溫蒸餾過程的目標(biāo)函數(shù)由distill loss(對應(yīng)soft target)和student loss(對應(yīng)hard target)加權(quán)得到。示意圖如上。
: Net-T的logits : Net-S的logits : Net-T的在溫度=T下的softmax輸出在第i類上的值 : Net-S的在溫度=T下的softmax輸出在第i類上的值 : 在第i類上的ground truth值,, 正標(biāo)簽取1,負(fù)標(biāo)簽取0. : 總標(biāo)簽數(shù)量 Net-T 和 Net-S同時輸入 transfer set (這里可以直接復(fù)用訓(xùn)練Net-T用到的training set), 用Net-T產(chǎn)生的softmax distribution (with high temperature) 來作為soft target,Net-S在相同溫度T下的softmax輸出和soft target的cross entropy就是「Loss函數(shù)的第一部分」.
, 其中,
Net-S在溫度=1下的softmax輸出和ground truth的cross entropy就是「Loss函數(shù)的第二部分」.
, 其中.
第二部分Loss 的必要性其實(shí)很好理解: Net-T也有一定的錯誤率,使用ground truth可以有效降低錯誤被傳播給Net-S的可能。打個比方,老師雖然學(xué)識遠(yuǎn)遠(yuǎn)超過學(xué)生,但是他仍然有出錯的可能,而這時候如果學(xué)生在老師的教授之外,可以同時參考到標(biāo)準(zhǔn)答案,就可以有效地降低被老師偶爾的錯誤“帶偏”的可能性。
「討論」
實(shí)驗(yàn)發(fā)現(xiàn)第二部分所占比重比較小的時候,能產(chǎn)生最好的結(jié)果,這是一個經(jīng)驗(yàn)的結(jié)論。一個可能的原因是,由于soft target產(chǎn)生的gradient與hard target產(chǎn)生的gradient之間有與 T 相關(guān)的比值。
另外,。因此在同時使用soft target和hard target的時候,需要在soft target之前乘上 的系數(shù),這樣才能保證soft target和hard target貢獻(xiàn)的梯度量基本一致。
「注意」: 在Net-S訓(xùn)練完畢后,做inference時其softmax的溫度T要恢復(fù)到1.
一種特殊情形: 直接match logits(不經(jīng)過softmax)
直接match logits指的是,直接使用softmax層的輸入logits(而不是輸出)作為soft targets,需要最小化的目標(biāo)函數(shù)是Net-T和Net-S的logits之間的平方差。「直接match logits的做法是」?「的情況下的特殊情形。」由單個case貢獻(xiàn)的loss,推算出對應(yīng)在Net-S每個logit 上的gradient:
當(dāng) 時,我們使用 來近似 ,于是得到
如果再加上logits是零均值的假設(shè)
那么上面的公式可以簡化成
也就是等價于minimise下面的損失函數(shù)
關(guān)于”溫度”的討論
【問題】 我們都知道“蒸餾”需要在高溫下進(jìn)行,那么這個“蒸餾”的溫度代表了什么,又是如何選取合適的溫度?
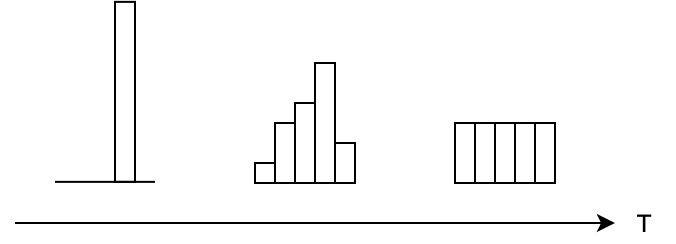
溫度的特點(diǎn)
在回答這個問題之前,先討論一下「溫度T的特點(diǎn)」
原始的softmax函數(shù)是 時的特例, 時,概率分布比原始更“陡峭”, 時,概率分布比原始更“平緩”。 溫度越高,softmax上各個值的分布就越平均(思考極端情況: (i), 此時softmax的值是平均分布的;(ii) ,此時softmax的值就相當(dāng)于,即最大的概率處的值趨近于1,而其他值趨近于0) 不管溫度T怎么取值,Soft target都有忽略小的 攜帶的信息的傾向
溫度代表了什么,如何選取合適的溫度?
溫度的高低改變的是Net-S訓(xùn)練過程中對負(fù)標(biāo)簽的關(guān)注程度: 溫度較低時,對負(fù)標(biāo)簽的關(guān)注,尤其是那些顯著低于平均值的負(fù)標(biāo)簽的關(guān)注較少;而溫度較高時,負(fù)標(biāo)簽相關(guān)的值會相對增大,Net-S會相對多地關(guān)注到負(fù)標(biāo)簽。實(shí)際上,負(fù)標(biāo)簽中包含一定的信息,尤其是那些值顯著「高于」平均值的負(fù)標(biāo)簽。但由于Net-T的訓(xùn)練過程決定了負(fù)標(biāo)簽部分比較noisy,并且負(fù)標(biāo)簽的值越低,其信息就越不可靠。因此溫度的選取比較empirical,本質(zhì)上就是在下面兩件事之中取舍:
從有部分信息量的負(fù)標(biāo)簽中學(xué)習(xí) –> 溫度要高一些 防止受負(fù)標(biāo)簽中噪聲的影響 –>溫度要低一些
總的來說,T的選擇和Net-S的大小有關(guān),Net-S參數(shù)量比較小的時候,相對比較低的溫度就可以了(因?yàn)閰?shù)量小的模型不能capture all knowledge,所以可以適當(dāng)忽略掉一些負(fù)標(biāo)簽的信息)
本文參考資料
推薦閱讀
