
知識蒸餾,中文文本分類,教師模型BERT,學生模型biLSTM

向AI轉型的程序員都關注了這個號??????
機器學習AI算法工程?? 公眾號:datayx
雖然說做文本不像圖像對gpu依賴這么高,但是當需要訓練一個大模型或者拿這個模型做預測的時候,也是耗費相當多資源的,尤其是BERT出來以后,不管做什么用BERT效果都能提高,萬物皆可BERT。
然而想要在線上部署應用,大公司倒還可以燒錢玩,畢竟有錢任性,小公司可玩不起,成本可能都遠大于效益。這時候,模型壓縮的重要性就體現(xiàn)出來了,如果一個小模型能夠替代大模型,而這個小模型的效果又和大模型差不多,何樂而不為。
在講知識蒸餾時一定會提到的Geoffrey Hinton開山之作Distilling the Knowledge in a Neural Network當然也是在圖像中開的山,下面簡單做一個介紹。
知識蒸餾使用的是Teacher—Student模型,其中teacher是“知識”的輸出者,student是“知識”的接受者。知識蒸餾的過程分為2個階段:
1.原始模型訓練: 訓練"Teacher模型", 它的特點是模型相對復雜,可以由多個分別訓練的模型集成而成。
2.精簡模型訓練: 訓練"Student模型", 它是參數(shù)量較小、模型結構相對簡單的單模型。
模型結構
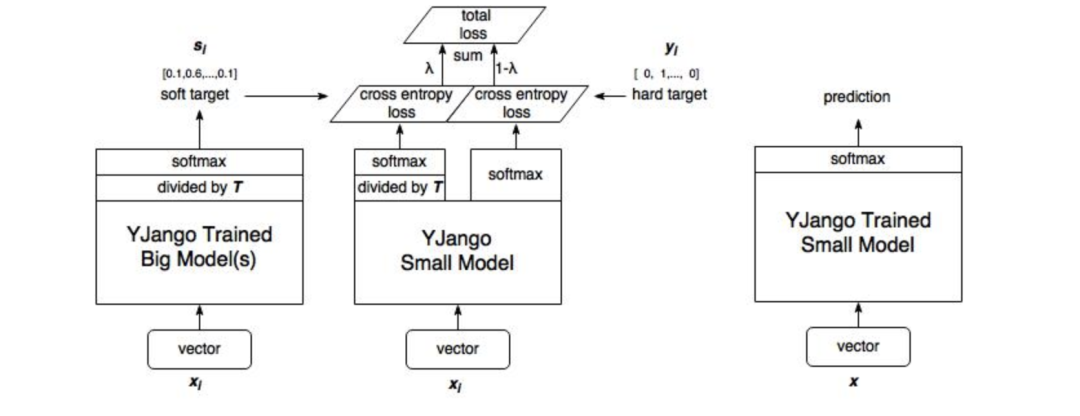
借用YJango大佬的圖,這里我簡單解釋一下我們怎么構建這個模型
1.訓練大模型
首先我們先對大模型進行訓練,得到訓練參數(shù)保存,這一步在上圖中并未體現(xiàn),上圖最左部分是使用第一步訓練大模型得到的參數(shù)。
2. 計算大模型輸出
訓練完大模型之后,我們將計算soft target,不直接計算output的softmax,這一步進行了一個divided by T蒸餾操作。(注:這時候的輸入數(shù)據(jù)可以與訓練大模型時的輸入不一致,但需要保證與訓練小模型時的輸入一致)
3. 訓練小模型
小模型的訓練包含兩部分。
-soft target loss
-h(huán)ard target loss
通過調節(jié)λ的大小來調整兩部分損失函數(shù)的權重。
4. 小模型預測
預測就沒什么不同了,按常規(guī)方式進行預測。
代碼 獲取方式:
關注微信公眾號 datayx ?然后回復?知識蒸餾?即可獲取。
模型實現(xiàn)
模型基本上是對論文Distilling Task-Specific Knowledge from BERT into Simple Neural Networks的復現(xiàn),下面介紹部分代碼實現(xiàn)
代碼結構
Teacher模型:BERT模型
Student模型:一層的biLSTM
LOSS函數(shù):交叉熵 、MSE LOSS
知識函數(shù):用最后一層的softmax前的logits作為知識表示
學生模型輸入
Student模型的輸入句向量由句中每一個詞向量求和取平均得到,詞向量為預訓練好的300維中文向量,訓練數(shù)據(jù)集為Wikipedia_zh中文維基百科。

學生模型結構

教師模型結構

損失函數(shù)

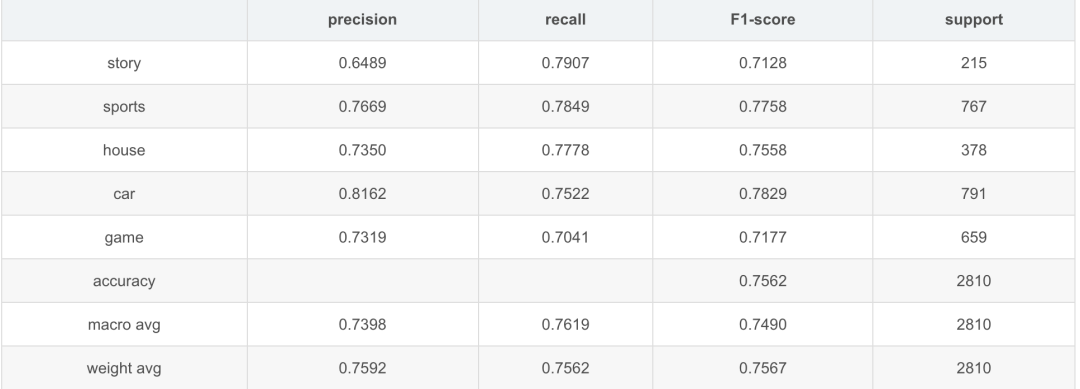
模型效果
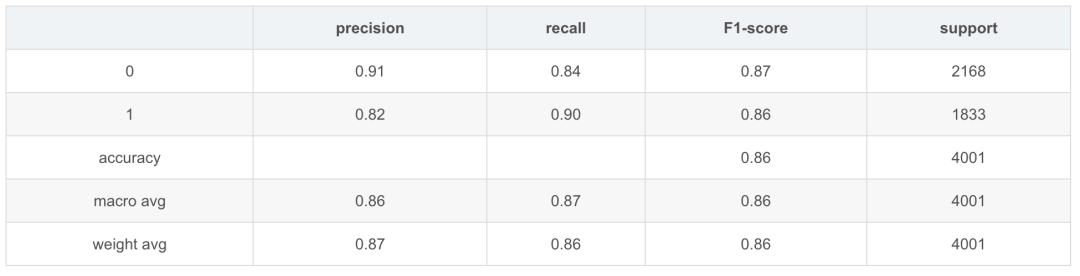
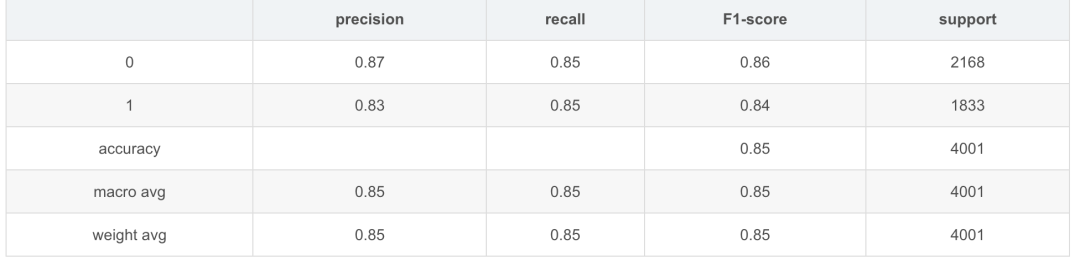
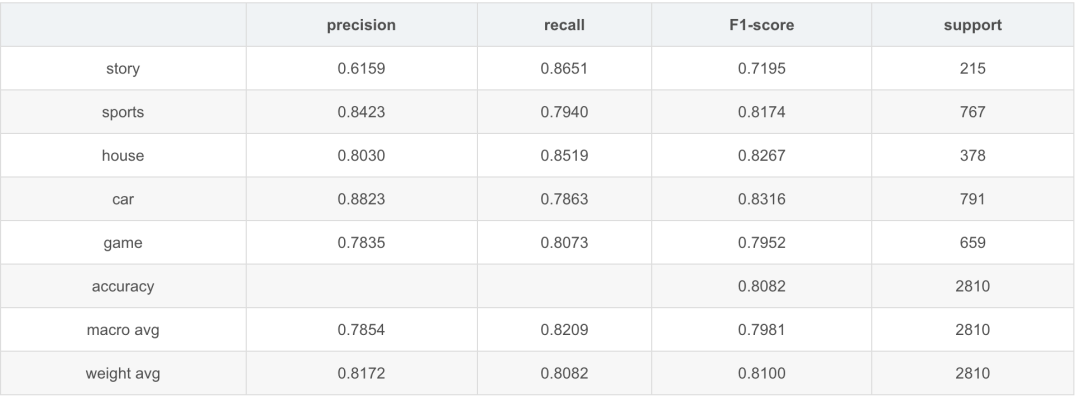
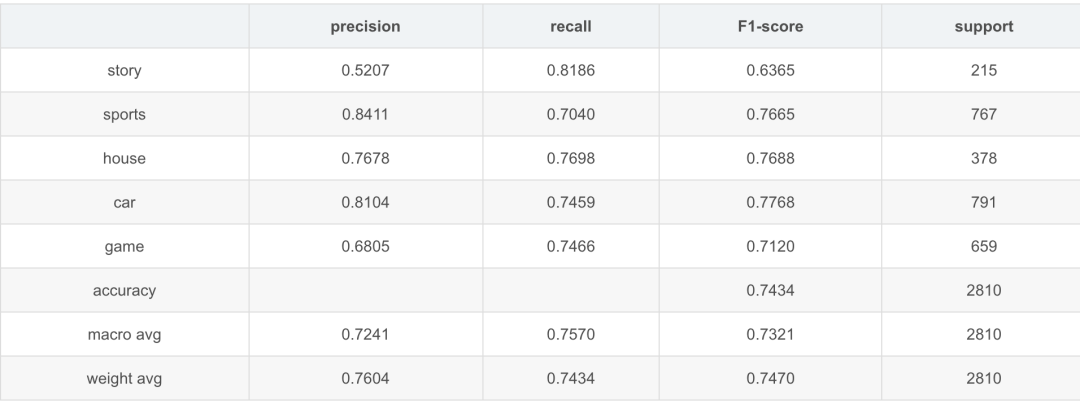
TNEWS測試效果
機器學習算法AI大數(shù)據(jù)技術
?搜索公眾號添加:?datanlp
長按圖片,識別二維碼
閱讀過本文的人還看了以下文章:
基于40萬表格數(shù)據(jù)集TableBank,用MaskRCNN做表格檢測
《深度學習入門:基于Python的理論與實現(xiàn)》高清中文PDF+源碼
python就業(yè)班學習視頻,從入門到實戰(zhàn)項目
2019最新《PyTorch自然語言處理》英、中文版PDF+源碼
《21個項目玩轉深度學習:基于TensorFlow的實踐詳解》完整版PDF+附書代碼
PyTorch深度學習快速實戰(zhàn)入門《pytorch-handbook》
【下載】豆瓣評分8.1,《機器學習實戰(zhàn):基于Scikit-Learn和TensorFlow》
《Python數(shù)據(jù)分析與挖掘實戰(zhàn)》PDF+完整源碼
汽車行業(yè)完整知識圖譜項目實戰(zhàn)視頻(全23課)
李沐大神開源《動手學深度學習》,加州伯克利深度學習(2019春)教材
筆記、代碼清晰易懂!李航《統(tǒng)計學習方法》最新資源全套!
《神經(jīng)網(wǎng)絡與深度學習》最新2018版中英PDF+源碼
重要開源!CNN-RNN-CTC 實現(xiàn)手寫漢字識別
【Keras】完整實現(xiàn)‘交通標志’分類、‘票據(jù)’分類兩個項目,讓你掌握深度學習圖像分類
VGG16遷移學習,實現(xiàn)醫(yī)學圖像識別分類工程項目
特征工程(二) :文本數(shù)據(jù)的展開、過濾和分塊
如何利用全新的決策樹集成級聯(lián)結構gcForest做特征工程并打分?
Machine Learning Yearning 中文翻譯稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
python+flask搭建CNN在線識別手寫中文網(wǎng)站
中科院Kaggle全球文本匹配競賽華人第1名團隊-深度學習與特征工程
不斷更新資源
深度學習、機器學習、數(shù)據(jù)分析、python
?搜索公眾號添加:?datayx??