
微軟提出的ZeRO到底是個啥?
 點藍色字關注“機器學習算法工程師”
點藍色字關注“機器學習算法工程師”
設為星標,干貨直達!
AI編輯:我是小將
本文作者:OpenMMLab @小P家的 001996,967610
https://zhuanlan.zhihu.com/p/394064174
本文已由原作者授權轉載
0 前言
本次大規(guī)模訓練技術系列分享之 ZeRO,主要對微軟 ZeRO Optimizer 的思路和實現進行介紹,全文包含以下四個部分:
大規(guī)模訓練的技術挑戰(zhàn) & 現有的并行訓練方式
ZeRO Optimizer 的三個不同級別
ZeRO-3 具體實現思路和方式
ZeRO 的局限與大模型訓練的未來
1 訓練大模型的挑戰(zhàn)
隨著人工智能技術在全球的推廣應用,自動駕駛、人臉識別、自然語言處理等越來越多領域通過深度學習大大提升了算法的整體性能和表現,GPU 也成為了訓練模型不可或缺的基礎計算設備。然而,隨著模型規(guī)模的不斷增大,加之模型訓練的數據量也越來越大,單個 GPU 的計算能力完全無法滿足大規(guī)模網絡的訓練需求。在密集型訓練的代表——自然語言處理中,OpenAI 在 2020 年 6 月發(fā)布的第三代語言模型 GPT-3 的參數量達到了 1700 億,相比于之前 GPT-2 的最大版本 15 億個參數增長了百倍以上。2021 年 4 月 25 日,華為云也發(fā)布盤古系列超大預訓練模型,其中包含30億參數的全球最大視覺(CV)預訓練模型,以及與循環(huán)智能、鵬城實驗室聯(lián)合開發(fā)的千億參數、40TB 訓練數據的全球最大中文語言(NLP)預訓練模型。這些龐大的模型訓練背后,必然少不了一套精妙運轉的訓練系統(tǒng)的支持,本次分享將揭秘超大模型訓練系統(tǒng)中必不可少的一項技術——ZeRO。
2 現有并行方法
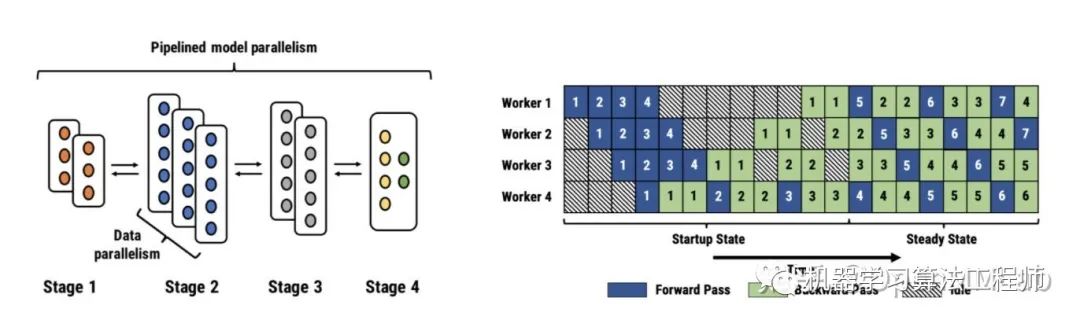
在探索 ZeRO 之前,我們需要先了解一下當前分布式訓練主要的三種并行模式:數據并行、模型并行和流水線并行。
2.1 數據并行
當模型規(guī)模足夠小且單個 GPU 能夠承載得下時,數據并行就是一種有效的分布式訓練方式。因為每個 GPU 都會復制一份模型的參數,我們只需要把訓練數據均分給多個不同的 GPU,然后讓每個 GPU 作為一個計算節(jié)點獨立的完成前向和反向傳播運算。數據并行不僅通信量較小,而且可以很方便的做通信計算重疊,因此可以取得最好的加速比。
2.2 模型并行
如果模型的規(guī)模比較大,單個 GPU 的內存承載不下時,我們可以將模型網絡結構進行拆分,將模型的單層分解成若干份,把每一份分配到不同的 GPU 中,從而在訓練時實現模型并行。訓練過程中,正向和反向傳播計算出的數據通過使用 All gather 或者 All reduce 的方法完成整合。這樣的特性使得模型并行成為處理模型中大 layer 的理想方案之一。然而,深度神經網絡層與層之間的依賴,使得通信成本和模型并行通信群組中的計算節(jié)點 (GPU) 數量正相關。其他條件不變的情況下,模型規(guī)模的增加能夠提供更好的計算通信比。
2.3 流水線并行
流水線并行,可以理解為層與層之間的重疊計算,也可以理解為按照模型的結構和深度,將不同的 layer 分配給指定 GPU 進行計算。相較于數據并行需要 GPU 之間的全局通信,流水線并行只需其之間點對點地通訊傳遞部分 activations,這樣的特性可以使流水并行對通訊帶寬的需求降到更低。然而,流水并行需要相對穩(wěn)定的通訊頻率來確保效率,這導致在應用時需要手動進行網絡分段,并插入繁瑣的通信原語。同時,流水線并行的并行效率也依賴各卡負載的手動調優(yōu)。這些操作都對應用該技術的研究員提出了更高的要求。
3 為什么需要ZeRO?
在三種并行方式中,數據并行因其易用性,得到了最為廣泛的應用。然而,數據并行會產生大量冗余 Model States 的空間占用。ZeRO 的本質,是在數據并行的基礎上,對冗余空間占用進行深度優(yōu)化。
在大規(guī)模訓練系列之技術挑戰(zhàn)一文中,我們介紹了大規(guī)模訓練中的顯存占用可以分為 Model States 與 Activation 兩部分,而 ZeRO 就是為了解決 Model States 而誕生的一項技術。
首先,我們來聊一下模型在訓練過程中 Model States 是由什么組成的:1. Optimizer States: Optimizer States 是 Optimizer 在進行梯度更新時所需要用到的數據,例如 SGD 中的Momentum以及使用混合精度訓練時的Float32 Master Parameters。2. Gradient:在反向傳播后所產生的梯度信息,其決定了參數的更新方向。3. Model Parameter: 模型參數,也就是我們在整個過程中通過數據“學習”的信息。
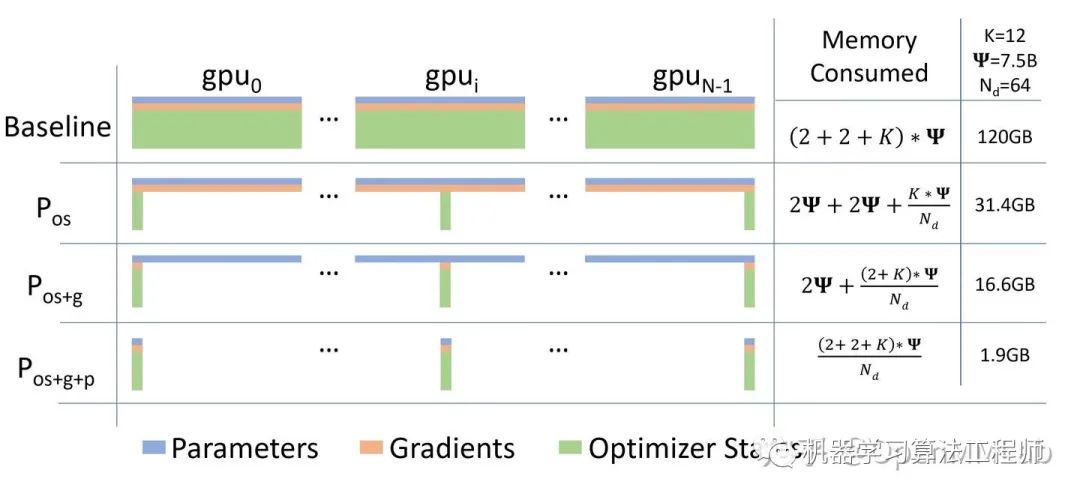
在傳統(tǒng)數據并行下,每個進程都使用同樣參數來進行訓練。每個進程也會持有對Optimizer States的完整拷貝,同樣占用了大量顯存。在混合精度場景下,以參數量為Ψ的模型和Adam optimzier為例,Adam需要保存:- Float16的參數和梯度的備份。這兩項分別消耗了2Ψ和2Ψ Bytes內存;(1 Float16 = 2 Bytes) - Float32的參數,Momentum,Variance備份,對應到 3 份4Ψ的內存占用。(1 Float32 = 4 Bytes)
最終需要2Ψ + 2Ψ + KΨ = 16Ψ bytes的顯存。一個7.5B參數量的模型,就需要至少 120 GB 的顯存空間才能裝下這些Model States。當數據并行時,這些重復的Model States會在N個GPU上復制N份[1]。
ZeRO 則在數據并行的基礎上,引入了對冗余Model States的優(yōu)化。使用 ZeRO 后,各個進程之后只保存完整狀態(tài)的1/GPUs,互不重疊,不再存在冗余。在本文中,我們就以這個 7.5B 參數量的模型為例,量化各個級別的 ZeRO 對于內存的優(yōu)化表現。
3.1 ZeRO 的三個級別
相比傳統(tǒng)數據并行的簡單復制,ZeRO 通過將模型的參數,梯度和Optimizer State劃分到不同進程來消除冗余的內存占用。
ZeRO 有三個不同級別,分別對應對 Model States 不同程度的分割 (Paritition):- ZeRO-1:分割Optimizer States;- ZeRO-2:分割Optimizer States與Gradients;- ZeRO-3:分割Optimizer States、Gradients與Parameters;
3.1.1 ZeRO-1
Optimizer States Partitioning : 4x memory reduction, same communication volume as DP
Optimizer 在進行梯度更新時,會使用參數與Optimizer States計算新的參數。而在正向或反向傳播中,Optimizer States并不會參與其中的計算。因此,我們完全可以讓每個進程只持有一小段Optimizer States,利用這一小段Optimizer States更新完與之對應的一小段參數后,再把各個小段拼起來合為完整的模型參數。ZeRO-1 中正是這么做的:
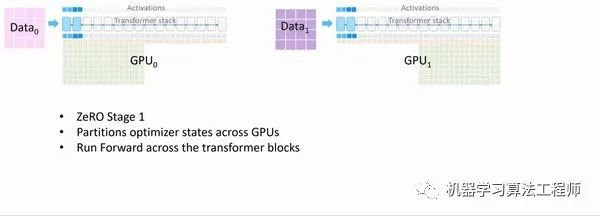 ZeRO Optimizer Stage1 Animation [4]
ZeRO Optimizer Stage1 Animation [4]
假設我們有 Nd 個并行的進程,ZeRO-1 會將完整優(yōu)化器的狀態(tài)等分成 Nd份并儲存在各個進程中。當Backward完成之后,每個進程的Optimizer: - 對自己儲存的Optimizer States(包括Momentum、Variance 與 FP32 Master Parameters)進行計算與更新。- 更新過后的Partitioned FP32 Master Parameters會通過All-gather傳回到各個進程中。- 完成一次完整的參數更新。
通過 ZeRO-1 對Optimizer States的分段化儲存,7.5B 參數量的模型內存占用將由原始數據并行下的 120GB 縮減到 31.4GB。
3.1.2 ZeRO-2
Optimizer States and Gradient Partitioning ($P_{os+g}$): 8x memory reduction, same communication volume as DP
ZeRO-1將Optimizer States分小段儲存在了多個進程中,所以在計算時,這一小段的Optimizer States也只需要得到進程所需的對應一小段Gradient就可以。遵循這種原理,和Optimizer States一樣,ZeRO-2也將Gradient進行了切片:
在一個Layer的Gradient都被計算出來后:- Gradient通過AllReduce進行聚合。(類似于DDP) - 聚合后的梯度只會被某一個進程用來更新參數,因此其它進程上的這段Gradient不再被需要,可以立馬釋放掉。(按需保留)
這樣就在ZeRO-1的基礎上實現了對Gradient的切分。
通過 ZeRO-2 對Gradient和Optimizer States的分段化儲存,7.5B 參數量的模型內存占用將由 ZeRO-1 中 31.4GB 進一步下降到 16.6GB。
3.1.3 ZeRO-3
Optimizer States, Gradient and Parameter Partitioning ($P_{os+g+p}$): Memory reduction is linear with DP degree
當Optimizer States,Gradient都被分布式切割分段儲存和更新之后,剩下的就是Model Parameter了。ZeRO-3 通過對Optimizer States,Gradient和Model Parameter三方面的分割,從而使所有進程共同協(xié)作,只儲存一份完整 Model States。其核心思路就是精細化通訊,按照計算需求做到參數的收集和釋放。
3.2 ZeRO-3 宏觀概覽
ZeRO-3 相對于 ZeRO-1 和 ZeRO-2,實現方式會復雜很多。首先我們站在宏觀的角度,理解ZeRO-3 的算法原理:
3.2.1 初始化
一個模型由多個Submodule組成。在初始化時,ZeRO-3 會將每個Submodule Parameter Tensor下的數據按照 GPU 的數量,分攤切割成多個小ds_tensor儲存在在不同 GPU 進程中。因為ds_tensor可以共同組合出完整數據,所以原始param下的數據變?yōu)槿哂嘈畔ⅲ瑫会尫诺簟?/p>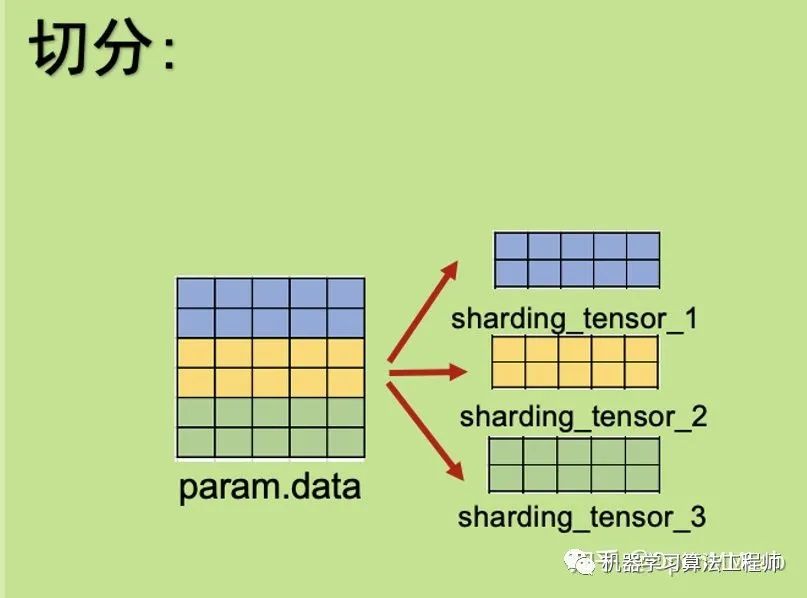
3.2.2 訓練中
在訓練過程中,ZeRO-3 會按照Submodule的計算需求進行參數的收集和釋放:在當前Submodule正向/反向傳播計算前,ZeRO-3 通過All-gather拿到分攤儲存在不同進程中的ds_tensor,重建原始的param。重建之后的參數就可以參與計算。
在當前Submodule正向/反向傳播計算后,param下的數據并沒有發(fā)生變更,與 ds_tensor 相同,造成了冗余。因此,param會再次被釋放。
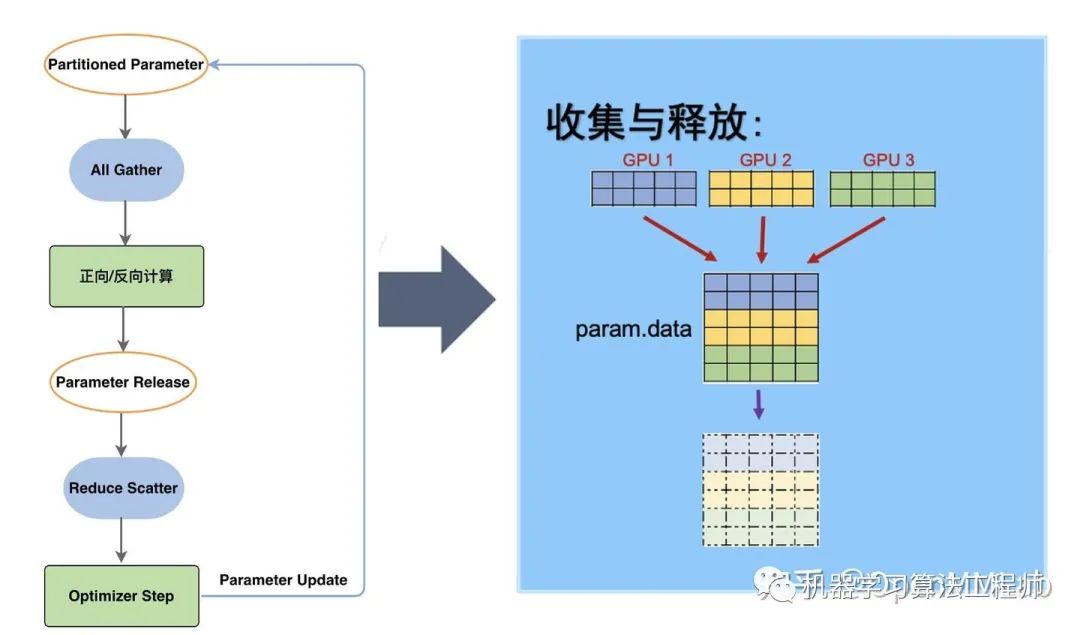
經過 ZeRO-3, 一套完整的 model states 就被分布式儲存在了多個 GPU 進程中。通過按照計算需求的數據收集和釋放,實現儲存空間有限的情況下超大規(guī)模模型的訓練。7.5B 參數量,64 卡并行的模型,內存占用將由 ZeRO-2 的 16.6GB 最終下降到 1.9GB。相較于傳統(tǒng)數據并行下 120GB 的內存空間,ZeRO-3 顯著提升了內存占用效率[1]。
以上就是 ZeRO-3 的宏觀算法原理的概述。在下邊的幾個章節(jié)中,我們將深入源碼,解讀ZeRO-3 代碼的實現方式和邏輯。
3.3 ZeRO-3 在 DeepSpeed 中的具體實現思路和方式
注 : 不想了解具體實現的同學可以略過這一節(jié)
在這里,我們深入代碼,探索一下 ZeRO-3 是如何實現Model Parameter分布式存儲的。
初始化: 分割 & 收集機制 -> submodule 收集 -> submodule 釋放
3.3.1 初始化 - 模型參數的分割
參數的分割遵循著每個進程雨露均沾的原則。
首先,為了防止內存爆炸,巨大的Model Parameters必須在加載之前就被拆分并發(fā)放到各個進程中。ZeRO-3 在模型初始化時就通過class Init對其進行了分攤與切割。
python model = zero.Init(module=model)
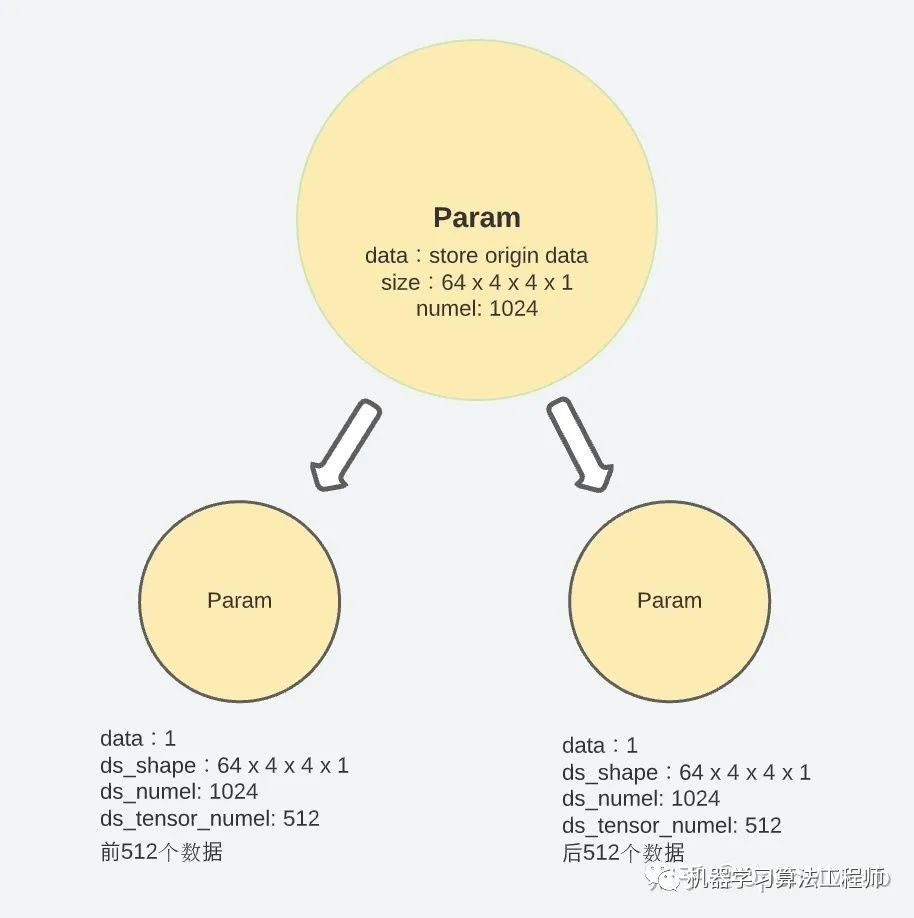
zero.Init初始化過程對傳入的module做了如下的四步:- 判定傳入 ZeRO-3 的module非None - 在一個for loop中,遍歷其下submodule中的所有參數 - 在 tensor 的 data 分割改變之前,對每一個parameter tensor套一層_convert_to_deepspeed_param的馬甲用于記錄tensor的特性(shape, numel, etc),防止后期因為 padding 和 partition 導致原始數據特性的丟失 - 參數完成conver_to_deepspeed_param之后,param.partition()對其進行均分切割并分攤給各個進程。
param.partition()中會按照如下步驟進行參數切分:
1. 根據進程數量(self.world_size)來計算 parameter partition 之后的 size:
partition_size = tensor_size // self.world_size2. 創(chuàng)建一個 partition_size 大小的空白 tensor:
partitioned_tensor = torch.zeros(partition_size, dtype=param.dtype, device=self.remote_device)3. 計算 partition 需要截取和儲存的數據區(qū)間:
start = partition_size * self.rank
end = start + partition_size4. 把原始 param 拉成一維后,按照進程自己的 rank 來決定偏移量的start和end,計算出截取的區(qū)間并放進partitioned_tensor里,把這個新創(chuàng)建的 tensor 掛在原始的param.ds_tensor下:
one_dim_param = param.contiguous().view(-1)
src_tensor = one_dim_param.narrow(0, start, partition_size)
param.ds_tensor.copy_(src_tensor)5. 把原始的param.data減少到1個scalar tensor:
# 因為param.data已經被分散儲存在param.ds_tensor下,
# 所以這一部分會將param.data釋放掉,修改為只儲存一個scalar的形式參數。
# 這也是為什么要通過_convert_to_deepspeed_param的馬甲記錄下原始信息的原因。
param.data = torch.ones(1).half().to(param.device)通過以上五個步驟,每個 module 中的參數就被拆分并儲存到了不同的進程中,當這一步結束時,原始在param.data長度變?yōu)榱?1,分段后的參數則放在param.ds_tensor中。
假設有 Nd 個 GPUs, 某一個model parameter的數據量(numel)為 T, 則其會被para.partition()成 Nd個小數據塊分發(fā)到Nd個進程中,每個進程中保持 T/Nd小段原始數據。在需要重建完整 tensor 進行計算時,ZeRO-3 通過之前記錄下的原始shape, numel等特性對參數進行完整的重構。
3.3.2 初始化 - 模型參數收集初始化
根據每個 submodule 需求做到更精細化的參數收集與釋放。
拆分好了model parameter之后,下一步需要考慮的就是如何在需要時快速的找到這些分攤儲存的參數,并且重新組合成完整的參數進行運算。參數的收集與釋放雖然發(fā)生在每次的 forward 與 backward 中,但是需要在初始化就建立好控制信息,針對這個目的,ZeRO-3 中創(chuàng)建了另外兩個 class:- class PartitionedParameterCoordinator
- class PrefetchCoordinator
這兩個 class 用于負責在forward和backward時協(xié)調module parameters的獲取和釋放。
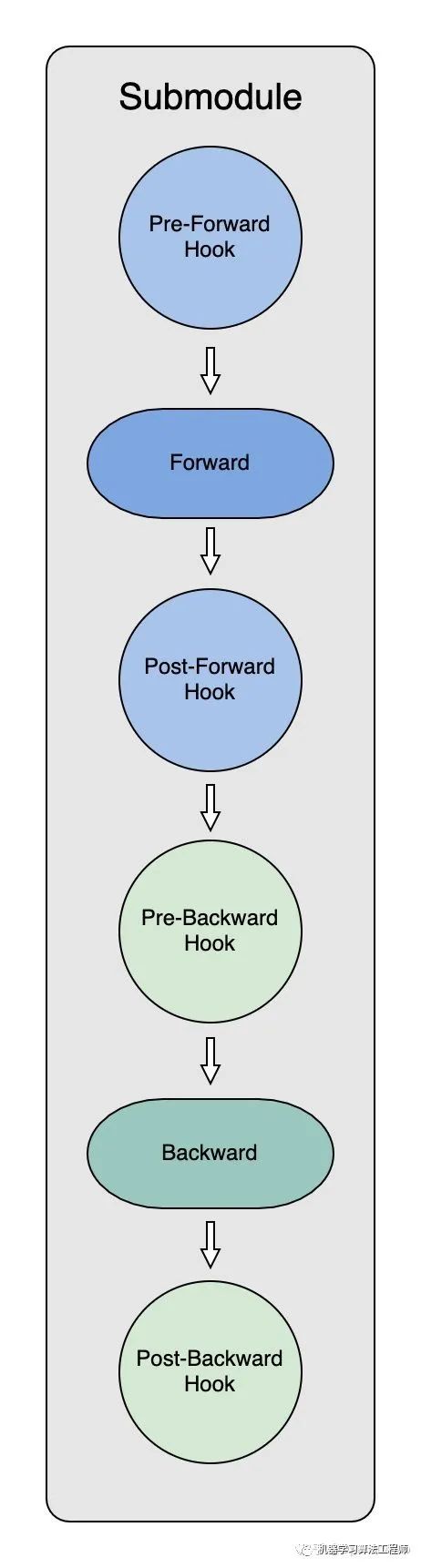
為了能夠在模型forward和backward中及時拿到模型參數,ZeRO初始化過程的一個重要環(huán)節(jié)就是給每個submodule創(chuàng)建 hooks。
首先我們來一起了解一下 PyTorch 中的 hook。根據 PyTorch 的文檔的介紹:
"You can register a function on a Module or Tensor. The hook can be a forward hook or a backward hook. The forward hook will be executed when a forward call is executed. The backward hook will be executed in the backward phase. "
通過使用hook,我們可以在保留網絡輸入輸出結構的同時,方便地獲取、改變網絡中間層變量的值和梯度。ZeRO-3 Optimizer初始化的過程中,代碼通過遞歸的方式,對module下的每個submodule都掛上了四個 hook:
_pre_forward_module_hook,在submodule的forward開始前負責module parameters獲取;_post_forward_module_hook,在submodule的forward結束后負責module parameters釋放;_pre_backward_module_hook,在submodule的backward開始前負責module parameters獲取;_post_backward_module_hook,在submodule的backward結束后負責module parameters釋放;
在每個submodule的forward和backward計算前,hook會調用:- class PartitionedParameterCoordinator 中的fetch_sub_module和all_gather收集重建自己需要的parameter。- class PrefetchCoordinator中的prefetch_next_sub_modules則最大化利用通訊帶寬,提前all_gather收集到未來submodule需要的parameter,為之后的計算做好準備。
計算完成后,hook 則通過:- class PartitionedParameterCoordinator 中的release_sub_module再次釋放當前submodule的parameters。
通過這樣的方式,在每一個iteration中,各個submodule就可以對自己需要的參數做出計算前的獲取和計算后的釋放。
3.3.3 前向傳播中的 ZeRO-3
前向傳播中 Model Parameter 的獲取(Pre-Forward Hook)
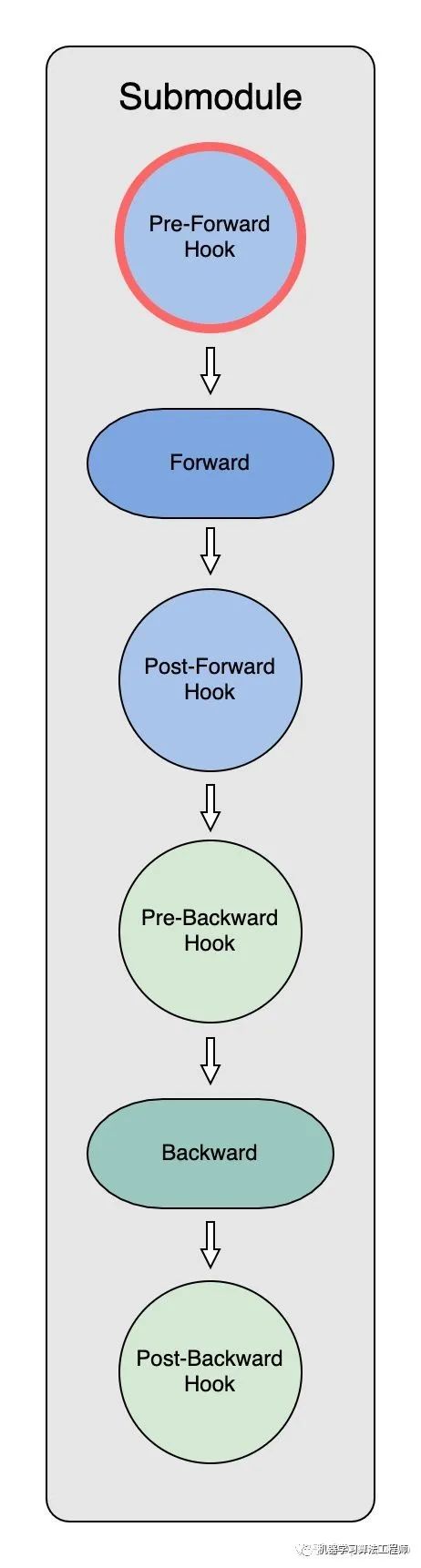
在初始化時,ZeRO-3 Optimizer 把全部module parameter分散partition到了不同的 GPU 上。因此,在每個submodule做forward之前,需要: - 明確submodule所需要的parameter - 通過進程間通訊拿到分散儲存的partitioned parameter - 重新構造出原始parameter進行運算
而整個流程都是通過PartitionedParameterCoordinator和PrefetchCoordinator實現的。每個submodule在Pre-forward hook中進行了四步操作:1. param_coordinator.record_trace 在第一個iteration時,record_trace會通過param_coordinator記錄下一份model的完整運行記錄trace,也就是各nn.module的執(zhí)行順序。在之后的iteration,運行記錄已經創(chuàng)建好了,record_trace就不再發(fā)揮作用。2. param_coordinator.fetch_sub_module 因為module forward會逐層進行,當獲得submodule的信息后:- 通過submodule.named_parameters()收集當前需要的全部partitioned parameters。- 通過all_gather,各個進程中的partitioned parameters會被重新組合構建成原始parameter。- 利用原始parameter進行submodule.forward的計算。3. param_coordinator.prefetch_next_sub_modules 為了節(jié)省通訊時間,提高效率,Pre-Forward Hook中也會提前預取當前submodule后的submodule的參數,并對其標記以便后續(xù)調用。4. param_coordinator.increment_step Step會更新當前Submodule在trace中走到了哪一步,從而確定之后prefetch_next_sub_modules的起點。
在最后,經過以上的三步處理,便實現了:- 完成submodule計算所需的所有parameter重建。- 完成下一個submodule計算的準備。- submodule加入most_recent_sub_module_step字典中并做記錄。
在第一個iteration后,通過之前創(chuàng)建好的trace,在之后計算過程中按照trace中的順序,從當前step進行對參數的fetch和eager prefetch。
通過以上完整的四個步驟,就實現了一個submodule在Pre-forward hook中的操作。在實際過程中,因為module可以逐層分成多個submodule,所以整個module的forward過程中會不斷的對各submodule重復以上操作。
前向傳播中 Model Parameter 的分割釋放(Post-Forward Hook)
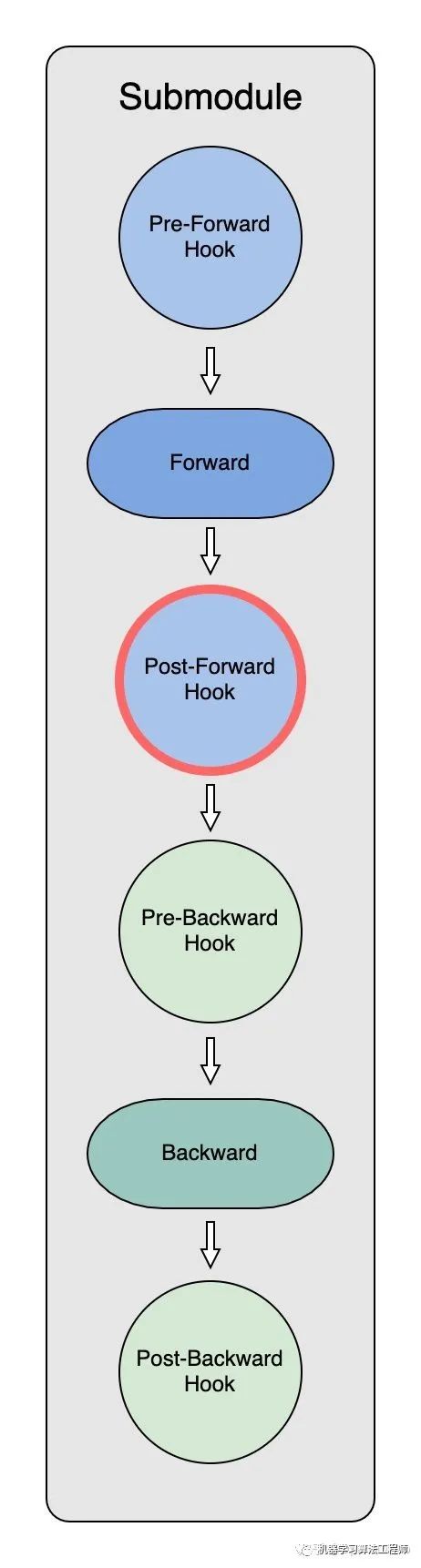
當submodule完成正向傳播計算后,post_forward_hook會釋放掉當前的subomdule,參數也會再次被 partition。但與初始化partition不同的是,此時每個進程中已經有了自己的小段data,所以此時partition只需要把計算前重建的完整大tensor再次釋放掉:
# param.data does not store anything meaningful in partitioned state
param.data = torch.ones(1, dtype=self.dtype).to(param.device)通過這樣的方式,每個進程中 submodule 只需要在計算前收集參數,計算后釋放參數,從而大大減少了冗余空間占用。
當module所有的submodule都完整正向傳播完成后,engine會將記錄submodule執(zhí)行順序的step_id重新歸為0,重新回到整個計算trace最初起點,準備下一次計算流程的開始。
3.3.4 反向傳播中的ZeRO-3
反向傳播中 Model Parameter 的獲取(Pre-Backward Hook)
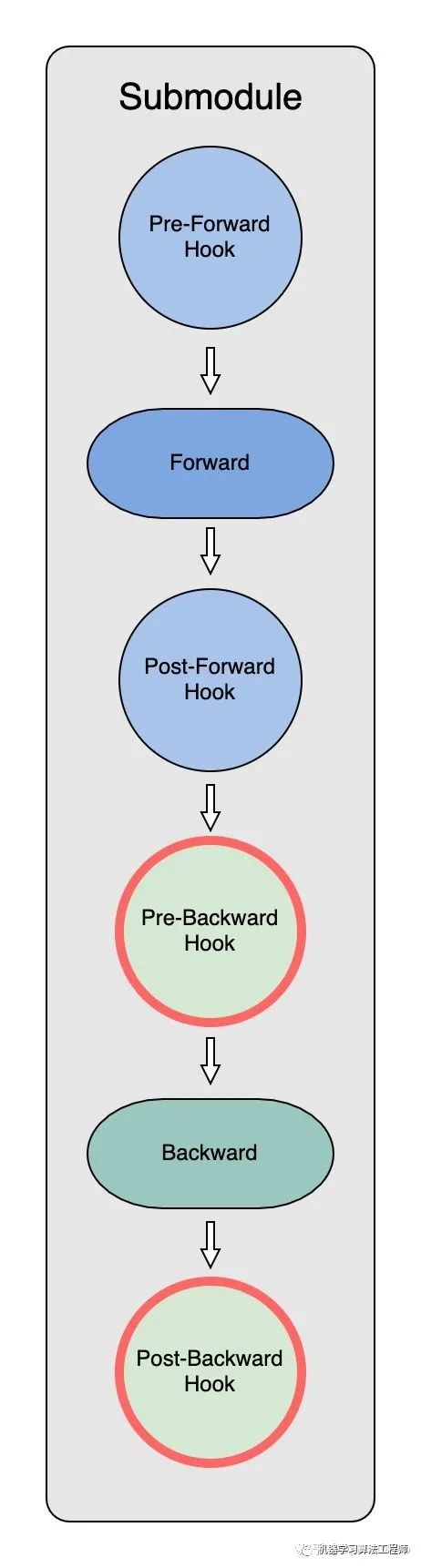
pre-backward_hook也是通過record_trace, fetch_sub_module, prefetch_next_sub_modules和next_step來實現過程的記錄、參數的獲取,并為下一步準備。
但是,由于 PyTorch 不支持Pre Backward Hook,因此這里得曲線救國一下:使用register_forward_hook掛上一個autograd.Function,這樣就可以實現在 module backward 之前執(zhí)行自定義的操作。在backward前,參數收集和分割的操作通過torch.autograd.Function掛在了各個submodule的tensor上。
當該tensor反向傳播計算時,autograd的backward會調用ctx.pre_backward_function(ctx.module)依次完成:1. record_trace 2. fetch_sub_module 3. prefetch_next_sub_modules 4. next_step 這四步操作也與Pre-Forward Hook中的四步操作一致。
反向傳播中 Model Parameter 的分割釋放(Post-Backward Hook)
當backward結束之后,PostBackward hook中的PostBackward Function也會和post_forward_function一樣將parameter釋放,從而減少model parameter的空間占用。[3]
3.3.5 Evaluation
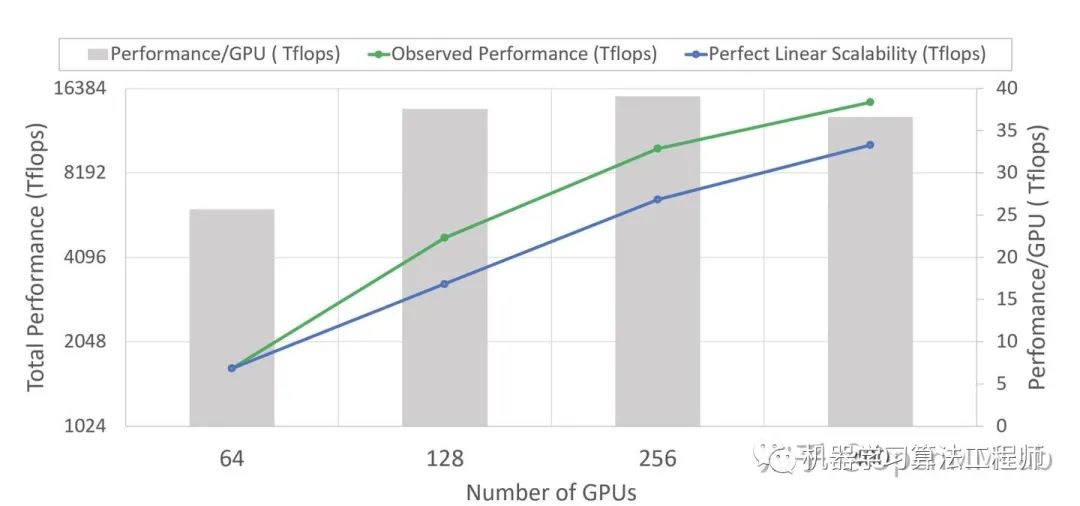
ZeRO 在 stage2 時就可在如下四個方面有杰出的表現。
ZeRO-R optimizes activation memory by identifying and removing activation replication in existing MP approaches through activation partitioning. It also offloads activations to CPU when appropriate.
在 ZeRO-2 和 ZeRO-R 配合可以支持高達170 billion 參數的模型訓練。
模型規(guī)模:相較于 Megatron 局限于 40B parameters,ZeRO-2 和 ZeRO-R 的組合可以支持多達 170 billion 參數的模型訓練,是當前 SOTA 方式的 8 倍。
訓練速度:在 400 張 Nvidia V100 GPU 集群上,ZeRO 可以將 100B 參數量的模型訓練速度提升近 10 倍,達到 38 TFlops/GPU,總體高達 15 Petaflops。
延展性:在 64-400 個 GPUs 區(qū)間,ZeRO 使訓練速度具備超 GPU增量的加速比。
model states內存占用的減少,支持了更大的batch sizes的訓練,從而提升模型的整體表現。易用性:數據和模型開發(fā)人員無需做任何模型并行就可訓練高達 13 billion 參數的模型,從而減少了模型重構帶來的成本開銷。[1]
在 ZeRO-3 的加持下,ZeRO Optimization 性能會得到進一步的提升。
ZeRO-3 可以在單純數據并行的模式下,實現在 1024 個 GPUs 上訓練超過 1 Trillion 的模型。配合模型并行,ZeRO 通過 16 路模型并行和 64 路數據并行,更是支持高達超過 2 Trillion 的模型訓練[1]。
4 What's next ? ZeRO 的局限與大模型訓練的未來
4.1 簡單粗暴的ZeRO也有局限性
ZeRO 在每個 submodule 的前向和反向傳播中進行了參數的collection與partition。在這種策略下:1. 單個 submodule 在前向或反向傳播中所占用的顯存(參數、梯度、Outputs、Workspace)小于單個GPU的容量。2. 頻繁利用通信來傳遞參數、梯度等信息,導致通信成為瓶頸。
4.1.1 大 Layer
例如 Transformer Model 中的一個64K hidden dimension Layer,在 Float16 下也需要超過 64GB 的顯存來儲存模型參數和梯度。在計算正向和反向傳播時,需要至少兩個超過 32GB 的連續(xù) memory buffer。這樣的需求即使在 NVIDIA A100 中也很難滿足。為了解決超大 Layer 這一難題,研究人員在 ZeRO 基礎之上引入了對單層 Layer 的拆分技術,也就是俗稱的模型并行。這里簡單提一下兩個比較有意思的工作:
Megatron-LM [5] 中充分利用了 Transformer 的模型結構,對多個 GEMM 進行了相當高效的拆分。在
MLP中,以縱向并行的方式劃分第一個 GEMM,后續(xù)的GeLU與第二個GEMM只在本地進行,唯一的通信在Dropout前對第二個GEMM的輸出做個加和。通過這樣的方式,GEMM 就可以被分到不同的 GPU 上,并只需在正向和反向傳播時各做一次AllReduce。對于Self-Attention模塊其也用了類似的拆分方法,核心仍是利用了分塊矩陣乘法。
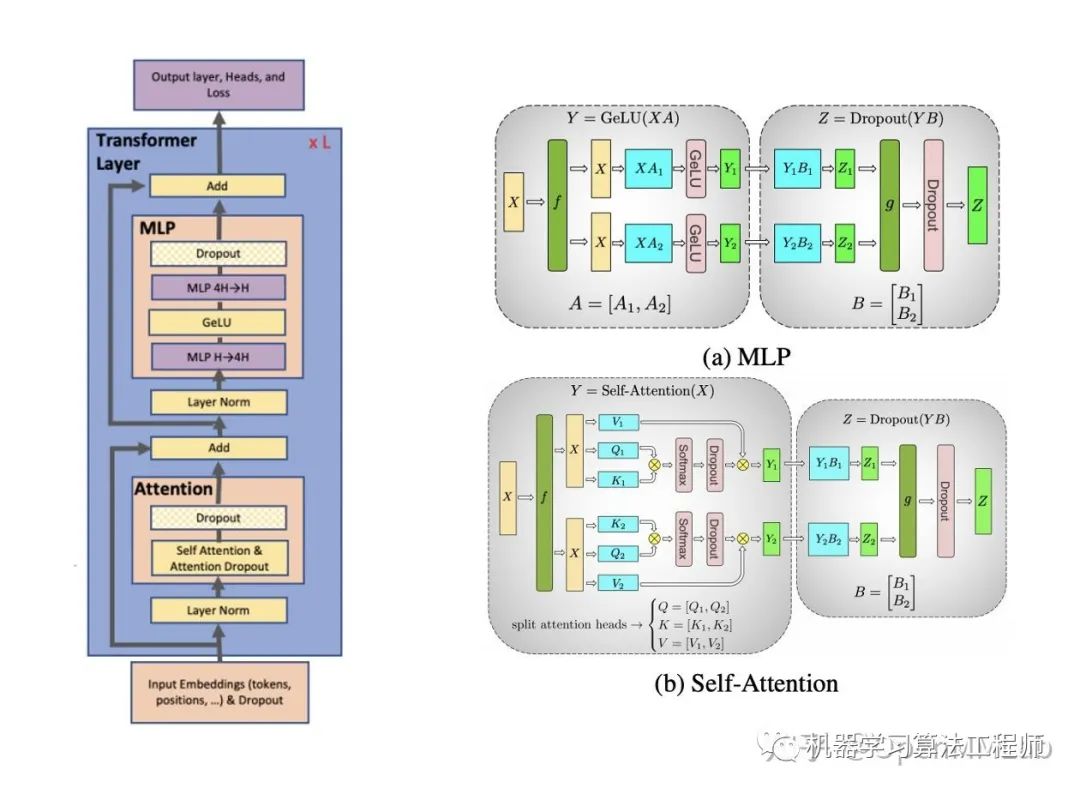
Optimus [7] 同樣利用了 Transformer 模型矩陣乘法的本質,但是不在行列的維度上分割矩陣,而是采用二維矩陣分割,并在理論效率上顯著超過了前者。(PS:這兩個工作的名字真是因吹斯汀
4.1.2 大通信
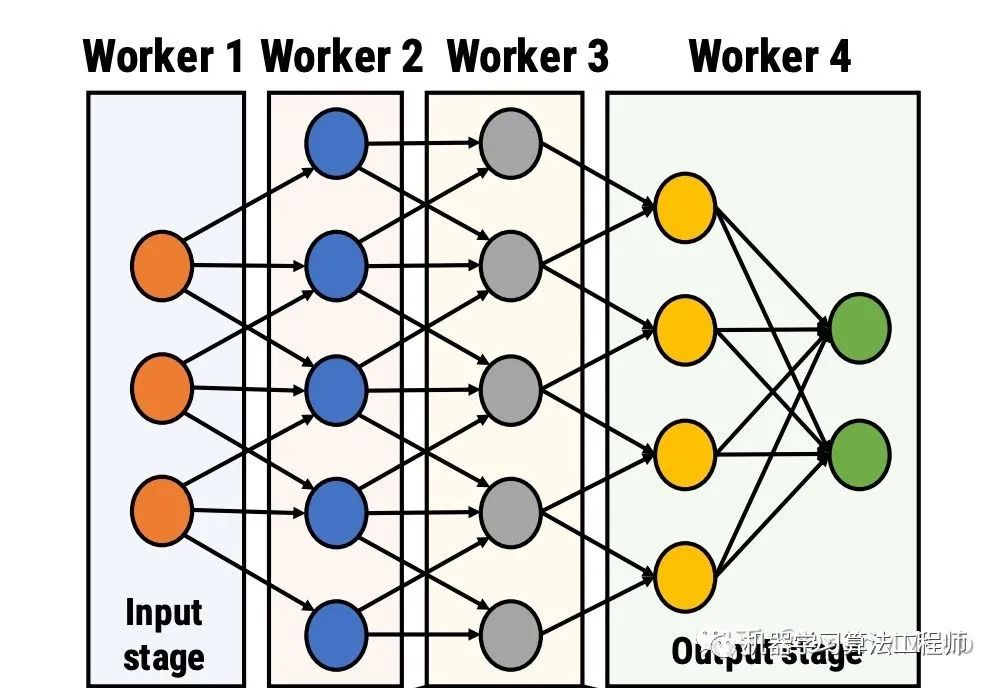
通信問題則主要考慮引入流水線并行來緩解。流水線并行將模型按層切分成了很多個 Stage,每一個 Worker 只持有一部分 Layer。切分后,不但每張卡上的參數和計算量減少了,同時 Worker 和 Worker 之間也只需要通信臨界層的 Activations。
對于 Transformer 模型來說,臨界層的 Activations 大小遠遠小于參數、梯度的大小,因此可以采用在節(jié)點間做流水線并行,節(jié)點內多卡做數據并行的方式來緩解節(jié)點間的通信壓力,同時充分利用節(jié)點內的超高帶寬。也可以將數據并行分為兩級,一級在節(jié)點內做通信量較大的 ZeRO 數據并行,另一級在多個流水線并行間做普通的數據并行。
4.2 最后
細心的朋友可能已經發(fā)現了,將上述的流水線并行、模型并行與數據并行相融合,就成了目前火熱的 3D 混合并行。也正是 3D 混合并行支撐起了 GPT-3、盤古等千億參數 Transformer 模型的訓練,縱然 3D 混合并行恐怖如斯,其仍然有許多局限性,這個就放在之后的系列分享中再展開了。
放眼未來的大模型訓練,同樣也不會是 ZeRO 技術或某項技術獨霸天下,而是在各類技術的更迭與融合中,形成一個愈發(fā)高效、通用、易用的大模型訓練系統(tǒng)。目前我們組也正在朝著視覺大模型這個極具挑戰(zhàn)的方向努力,希望看到這里的你也能加入進來一起搞大新聞,簡歷請發(fā) [email protected] (備注來自知乎,第一時間處理)。
引用
[1] Samyam R, Jeff R, Olatunji R, Yuxiong H. ZeRO: Memory Optimizations Toward Training Trillion Parameter Models. arxiv.org/pdf/1910.02054. 2019.
[2] Turing-NLG: A 17-billion-parameter language model by Microsoft
[3] Rangan M, Junhua W. ZeRO & DeepSpeed: New system optimizations enable training models with over 100 billion parameters. 2020.
[4] KDD 2020: Hands on Tutorials: Deep Speed -System optimizations enable training deep learning models
[5] Mohammad S, Mostofa P, Raul P, et al. Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism arxiv.org/abs/1909.08053 .2019
[6] Rangan M, Andrey P. ZeRO-Infinity and DeepSpeed: Unlocking unprecedented model scale for deep learning training. 2021
[7] Xu Q, Li S, Gong C, et al. An Efficient 2D Method for Training Super-Large Deep Learning Models[J]. arXiv preprint arXiv:2104.05343, 2021.
附錄
PyTorch 的模型必須具有以下的三種特性:1.必須繼承nn.Module這個類,要讓 PyTorch 知道這個類是一個 Module 2.在init(self)中設置好需要的"組件"(如conv,pooling,Linear,BatchNorm等) 3.最后,在forward(self,x)中定義好的“組件”進行組裝,就像搭積木,把網絡結構搭建出來,這樣一個模型就定義好了。
根據 PyTorch 的文檔介紹, nn.Module是所有模型的基礎 class,我們構建的各種模型網絡也是這個nn.Module的subclass,并且每個 Module 也可以包含其他的 Module。
“All network components should inherit from nn.Module and override the forward() method. That is about it, as far as the boilerplate is concerned. Inheriting from nn.Module pro ides functionality to your component. ”
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.conv1 = nn.Conv2d(1, 20, 5)# submodule: Conv2d
self.conv2 = nn.Conv2d(20, 20, 5)
def forward(self, x):
x = F.relu(self.conv1(x))
return F.relu(self.conv2(x))PyTorch 給出的上述例子中,class Model就是繼承了nn.Module,其內部兩個nn.Conv2d各自也繼承了nn.Module,nn.Conv2d就是class Model的submodule了。在 stage3 中,ZeRO 就是利用了 module 的這種嵌套的特性來實現模型參數的記錄和并行。
推薦閱讀
谷歌AI用30億數據訓練了一個20億參數Vision Transformer模型,在ImageNet上達到新的SOTA!
"未來"的經典之作ViT:transformer is all you need!
PVT:可用于密集任務backbone的金字塔視覺transformer!
漲點神器FixRes:兩次超越ImageNet數據集上的SOTA
不妨試試MoCo,來替換ImageNet上pretrain模型!
機器學習算法工程師
一個用心的公眾號
