
爆火的分布式數(shù)據(jù)庫,到底是個(gè)啥?
免責(zé)聲明~
任何文章不要過度深思!
萬事萬物都經(jīng)不起審視,因?yàn)槭郎蠜]有同樣的成長環(huán)境,也沒有同樣的認(rèn)知水平,更「沒有適用于所有人的解決方案」;
不要急著評(píng)判文章列出的觀點(diǎn),只需代入其中,適度審視一番自己即可,能「跳脫出來從外人的角度看看現(xiàn)在的自己處在什么樣的階段」才不為俗人。
怎么想、怎么做,全在乎自己「不斷實(shí)踐中尋找適合自己的大道」
1 啥是分布式DB?
隨著TiDB等分布式DB的興起,關(guān)系型DB也逐漸增加了分布式特性。在這些分布式DB中,數(shù)據(jù)分片和分布式事務(wù)是內(nèi)置的基礎(chǔ)功能,使業(yè)務(wù)開發(fā)人員能夠像使用傳統(tǒng)關(guān)系型DB一樣簡便地使用JDBC接口。作為一種分布式DB中間件,shardingSphere除了提供標(biāo)準(zhǔn)化的數(shù)據(jù)分片解決方案外,還實(shí)現(xiàn)了分布式事務(wù)和DB治理功能。讓我們一起探索這些強(qiáng)大的工具如何提高數(shù)據(jù)管理和操作的效率!
事實(shí)標(biāo)準(zhǔn)
當(dāng)一款技術(shù)產(chǎn)品占據(jù)市場主導(dǎo)地位時(shí),它就成為同類產(chǎn)品的標(biāo)桿。就像關(guān)系型數(shù)據(jù)庫中,Oracle成為了事實(shí)標(biāo)桿,因?yàn)樗行掳姹镜臄?shù)據(jù)庫產(chǎn)品都要和Oracle進(jìn)行對(duì)比,比較各自的特性。這樣一來,Oracle就擁有更多的用戶和支持,而其他競爭對(duì)手則需要不斷改進(jìn)自己的產(chǎn)品才能與之匹敵。
2 外部視角:外部特性
分布式 DB具備啥特性,能解決啥痛點(diǎn)。
業(yè)務(wù)應(yīng)用系統(tǒng)按交易類型分類:
-
聯(lián)機(jī)交易(OLTP)
面向交易的處理過程,單筆交易的數(shù)據(jù)量小,但是要在很短的時(shí)間內(nèi)給出結(jié)果,典型場景包括購物、繳費(fèi)、轉(zhuǎn)賬等
-
聯(lián)機(jī)分析(OLAP)
通常是基于大數(shù)據(jù)集的運(yùn)算,典型場景包括生成個(gè)人年度賬單和企業(yè)財(cái)務(wù)報(bào)表等。
難有一款產(chǎn)品中完全滿足兩者,因此在單體DB時(shí)代演化出兩個(gè)不同技術(shù)體系,即兩類不同的關(guān)系型DB。向分布式架構(gòu)演進(jìn)后,兩者在架構(gòu)設(shè)計(jì)也采用完全不同策略,很難在一個(gè)框架下說清。
先專注討論OLTP場景下的分布式 DB。本教程所提“ DB”都默認(rèn)“關(guān)系型DB”,分布式DB也都指支持關(guān)系模型的分布式DB。即不討論NoSQL,整體看,關(guān)系型DB由于支持SQL、提供ACID事務(wù),具有更好通用性,在更廣泛場景中無法被NoSQL取代。通過NoSQL十余年來發(fā)展已被證實(shí)。
分布式DB目標(biāo)正是融合傳統(tǒng)關(guān)系型 DB與NoSQL DB的優(yōu)勢(shì),而且已經(jīng)取得不錯(cuò)效果。
3 定義
3.1 OLTP關(guān)系型 DB
僅用“OLTP場景”作為定語顯然不夠精準(zhǔn),我們來進(jìn)一步看看OLTP場景具體的技術(shù)特點(diǎn)。
OLTP場景的通常有三個(gè)特點(diǎn):
- 寫多讀少,指請(qǐng)求數(shù)量。而且讀操作的復(fù)雜度較低,一般不涉及大數(shù)據(jù)集的匯總計(jì)算
- 低延時(shí),用戶對(duì)于延時(shí)的容忍度較低,通常在500毫秒以內(nèi),稍微放大一些也就是秒級(jí),超過5秒的延時(shí)通常是無法接受的;
- 高并發(fā),并發(fā)量隨著業(yè)務(wù)量而增長,沒有理論上限。
我們是不是可以有這樣一個(gè)結(jié)論:分布式 DB是服務(wù)于寫多讀少、低延時(shí)、高并發(fā)的OLTP場景的 DB。
3.2 海量并發(fā)
你可能會(huì)說這個(gè)定義有問題,比如MySQL和Oracle這樣的關(guān)系型 DB也是服務(wù)于OLTP場景的,但它們并不是分布式 DB。
相對(duì)傳統(tǒng)關(guān)系型 DB,分布式 DB最大差異就是分布式 DB遠(yuǎn)高于前者的并發(fā)處理能力。
傳統(tǒng)關(guān)系型 DB往往是單機(jī)模式,主要負(fù)載運(yùn)行在一臺(tái)機(jī)器。DB的并發(fā)處理能力與單機(jī)的資源配置是線性相關(guān)的,所以并發(fā)處理能力的上限也就受限于單機(jī)配置的上限。這種依靠提升單機(jī)資源配置來擴(kuò)展性能的方式,即垂直擴(kuò)展(Scale Up)。
在一臺(tái)機(jī)器中,隨隨便便就能多塞進(jìn)些CPU和內(nèi)存來提升提性能嗎?當(dāng)然沒那么容易。所以,物理機(jī)單機(jī)配置上限的提升是相對(duì)緩慢的。即在一定時(shí)期內(nèi),依賴垂直擴(kuò)展的 DB總會(huì)存在性能的天花板。很多銀行采購小型機(jī)或大型機(jī)的原因之一,就是相比x86服務(wù)器,這些機(jī)器能夠安裝更多的CPU和內(nèi)存,可以把天花板推高一些。
而分布式 DB不同,在維持關(guān)系型 DB特性不變的基礎(chǔ)上,它通過水平擴(kuò)展增加機(jī)器數(shù)量,提供遠(yuǎn)高單體 DB的并發(fā)量。這個(gè)并發(fā)量幾乎不受單機(jī)性能限制,我將這個(gè)級(jí)別的并發(fā)量稱為“海量并發(fā)”。
“海量并發(fā)”到底多大
沒權(quán)威數(shù)字。雖然理論上是可以找一臺(tái)世界上最好的機(jī)器來測(cè)試一下,但考慮到商業(yè)因素,這個(gè)數(shù)字不會(huì)有什么實(shí)際價(jià)值。不過,我可以給出一個(gè)經(jīng)驗(yàn)值,這個(gè)“海量并發(fā)”的下限大致是10,000TPS。
2.0版本的定義:分布式 DB是服務(wù)于寫多讀少、低延時(shí)、海量并發(fā)OLTP場景的關(guān)系型 DB。
3.3 +高可靠
2.0版仍有問題。是不是沒有海量并發(fā)需求,就不需要使用分布式 DB了呢?不是的,你還要考慮 DB的高可靠性。
一般來說,可靠性是與硬件設(shè)備的故障率有關(guān)的。
與銀行不同,很多互聯(lián)網(wǎng)公司和中小企業(yè)通常是采用x86服務(wù)器的。x86服務(wù)器有很多優(yōu)勢(shì),但故障率會(huì)相對(duì)高一些,坊間流傳的年故障率在5%左右。
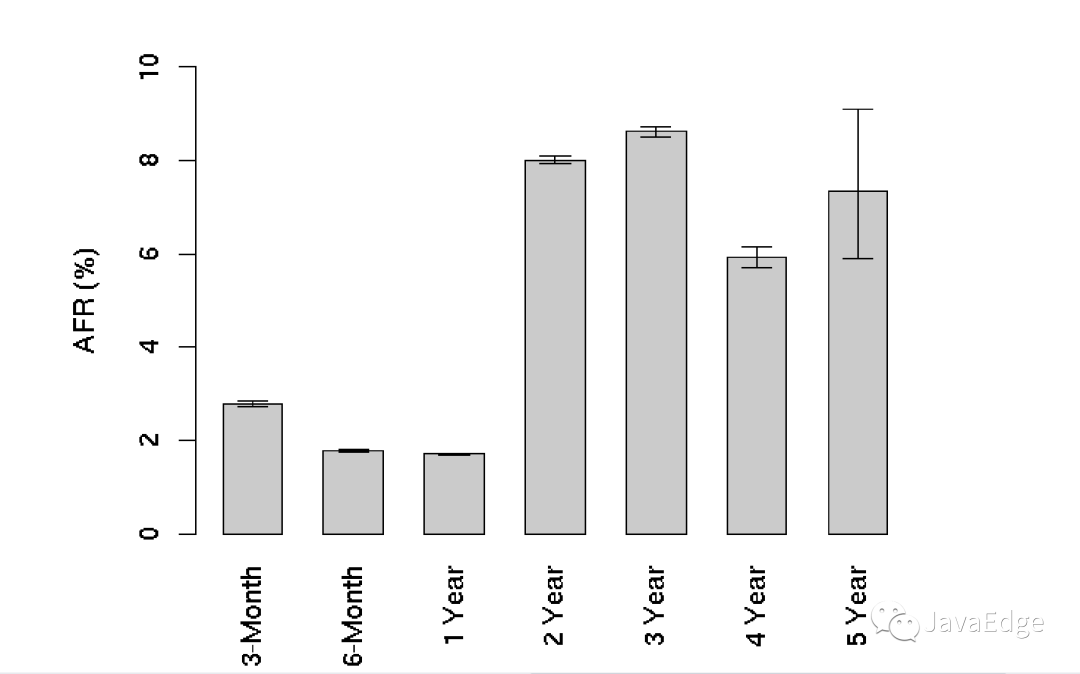
一些更加可靠的數(shù)據(jù)來自Google的論文Failure Trends in a Large Disk Drive Population,文中詳細(xì)探討了通用設(shè)備磁盤的故障情況。它給出的磁盤年度故障率的統(tǒng)計(jì)圖,如下所示:
 img
img
可以看到,前三個(gè)月會(huì)超過2%的磁盤損壞率,到第二年這個(gè)數(shù)字會(huì)上升到8%左右。
你可能會(huì)說,這個(gè)數(shù)字也不是很高啊。
但你要知道,對(duì)金融行業(yè)的關(guān)鍵應(yīng)用系統(tǒng)來說,通常是要求具備5個(gè)9的可靠性(99.999%),也就是說,一年中系統(tǒng)的服務(wù)中斷時(shí)間不能超過5.26分鐘(365*24*60*(1-99.999%) ≈ 5.26 )。
而且,不只是金融行業(yè),隨著人們對(duì)互聯(lián)網(wǎng)的依賴,越來越多的系統(tǒng)都會(huì)有這樣高的可靠性要求。
根據(jù)這兩個(gè)數(shù)字,我們可以設(shè)想一下,如果你所在的公司有四、五個(gè)關(guān)鍵業(yè)務(wù)系統(tǒng),十幾臺(tái) DB服務(wù)器,磁盤數(shù)量一定會(huì)超過100個(gè)吧?那么我們保守估計(jì),按照損壞率2%來算,一年中就會(huì)碰到2次磁盤損壞的情況,要達(dá)到5個(gè)9的可靠性你就只有5.26分鐘,能處理完一次磁盤故障嗎?這幾乎是做不到的,可能你剛沖到機(jī)房,時(shí)間就用完了。
我猜你會(huì)建議用RAID(獨(dú)立冗余磁盤陣列)來提高磁盤的可靠性。這確實(shí)是一個(gè)辦法,但也會(huì)帶來性能上的損耗和存儲(chǔ)空間上的損失。分布式 DB的副本機(jī)制可以比RAID更好地平衡可靠性、性能和空間利用率三者的關(guān)系。副本機(jī)制就是將一份數(shù)據(jù)同時(shí)存儲(chǔ)在多個(gè)機(jī)器上,形成多個(gè)物理副本。
回到 DB的話題上,可靠性還要更復(fù)雜一點(diǎn),包括兩個(gè)度量指標(biāo),恢復(fù)時(shí)間目標(biāo)(Recovery Time Objective, RTO)和恢復(fù)點(diǎn)目標(biāo)(Recovery Point Objective, RPO)。RTO是指故障恢復(fù)所花費(fèi)的時(shí)間,可以等同于可靠性;RPO則是指恢復(fù)服務(wù)后丟失數(shù)據(jù)的數(shù)量。
DB存儲(chǔ)著重要數(shù)據(jù),而金融行業(yè)的 DB更是關(guān)系到客戶資產(chǎn)安全,不能容忍任何數(shù)據(jù)丟失。所以, DB高可靠意味著RPO等于0,RTO小于5分鐘。
傳統(tǒng)上,銀行通過兩種方法配合來實(shí)現(xiàn)這個(gè)目標(biāo)。
第一種還是采購小型機(jī)和大型機(jī),因?yàn)樗鼈兊姆€(wěn)定性優(yōu)于x86服務(wù)器。
第二種是引入專業(yè)存儲(chǔ)方案,例如EMC的Symmetrix遠(yuǎn)程鏡像軟件(Symmetrix Remote Data Facility, SRDF)。DB采用主備模式,在高端共享存儲(chǔ)上保存 DB文件和日志,使 DB近似于無狀態(tài)化。主庫一旦出現(xiàn)問題,備庫啟動(dòng)并加載共享存儲(chǔ)的文件,繼續(xù)提供服務(wù)。這樣就可以做到RPO為零,RTO也比較小。
但是,這套方案依賴專用的軟硬件,不僅價(jià)格昂貴,而且技術(shù)體系封閉。在去IOE(IBM小型機(jī)、Oracle DB和EMC存儲(chǔ)設(shè)備)的大背景下,我們必須另辟蹊徑。分布式 DB則是一個(gè)很好的備選方案,它憑借節(jié)點(diǎn)之間的互為備份、自動(dòng)切換的機(jī)制,降低了x86服務(wù)器的單點(diǎn)故障對(duì)系統(tǒng)整體的影響,提供了高可靠性保障。
令人興奮的是,這種單點(diǎn)故障處理機(jī)制甚至可以延展到機(jī)房層面,通過遠(yuǎn)距離跨機(jī)房部署。如此一來,即使在單機(jī)房整體失效的情況下,系統(tǒng)仍然能夠正常運(yùn)行, DB永不宕機(jī)。
3.0定義,分布式 DB是服務(wù)于寫多讀少、低延時(shí)、海量并發(fā)OLTP場景的,高可靠的關(guān)系型 DB。
3.4 海量存儲(chǔ)
雖然單體 DB依靠外置存儲(chǔ)設(shè)備可以擴(kuò)展存儲(chǔ)能力,但這種方式本質(zhì)上不是 DB的能力。現(xiàn)在,借助分布式的橫向擴(kuò)展架構(gòu),通過物理機(jī)的本地磁盤就可以獲得強(qiáng)大的存儲(chǔ)能力,這讓海量存儲(chǔ)成為分布式 DB的標(biāo)配。
最后,我們終于得到一個(gè)4.0終極版本的定義,分布式 DB是服務(wù)于寫多讀少、低延時(shí)、海量并發(fā)OLTP場景的,具備海量數(shù)據(jù)存儲(chǔ)能力和高可靠性的關(guān)系型 DB。
4 內(nèi)部視角:內(nèi)部構(gòu)成
具有相同的外在特性和功效,未必就是同樣的事物。
“日心說”反駁“地心說”要用到34個(gè)圓周解釋天體運(yùn)動(dòng)軌跡;而100多年后,開普勒只用7個(gè)橢圓就達(dá)到同樣效果,徹底摧毀“地心說”。從哥白尼到開普勒,效果近似,簡潔程度大不一樣,這背后代表的是巨大科學(xué)進(jìn)步。
因此,講完外部特性,還要從內(nèi)部視角觀察。
為應(yīng)對(duì)海量存儲(chǔ)和海量并發(fā),很多解決方案在效果上跟V4定義相似。但它們向用戶暴露了太多的內(nèi)部復(fù)雜性。用戶約束太多、使用過程太復(fù)雜、不夠內(nèi)聚的方案,不能稱為成熟產(chǎn)品。同時(shí),業(yè)界的主流觀點(diǎn)并不認(rèn)為它們是分布式 DB。
來看分類:
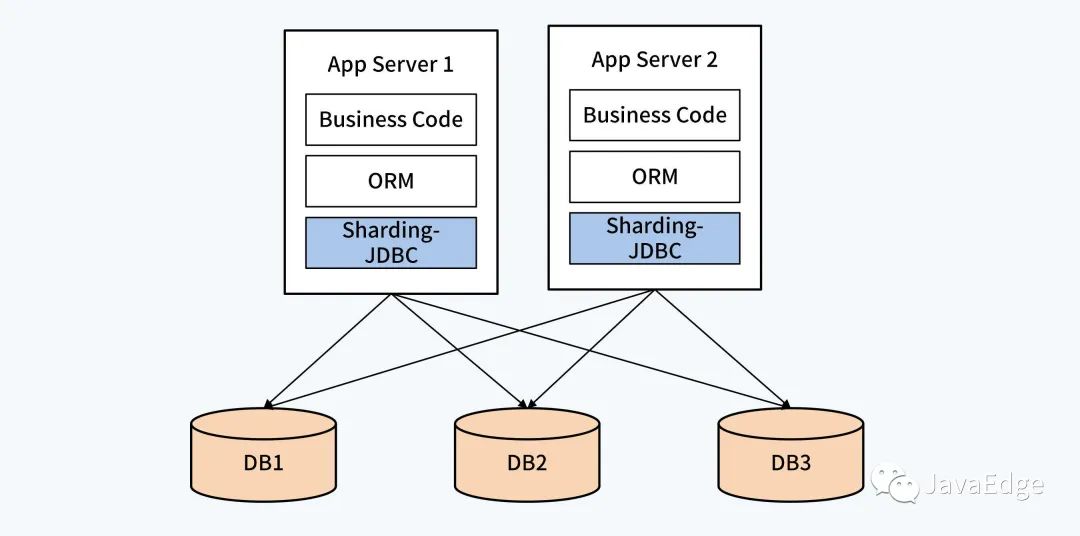
4.1 客戶端組件 + 單體 DB
通過獨(dú)立的邏輯層建立數(shù)據(jù)分片和路由規(guī)則,實(shí)現(xiàn)單體 DB的初步管理,使應(yīng)用能夠?qū)佣鄠€(gè)單體 DB,實(shí)現(xiàn)并發(fā)、存儲(chǔ)能力的擴(kuò)展。其作為應(yīng)用系統(tǒng)的一部分,對(duì)業(yè)務(wù)侵入比較深。
這種客戶端組件的典型產(chǎn)品是Sharding-JDBC。
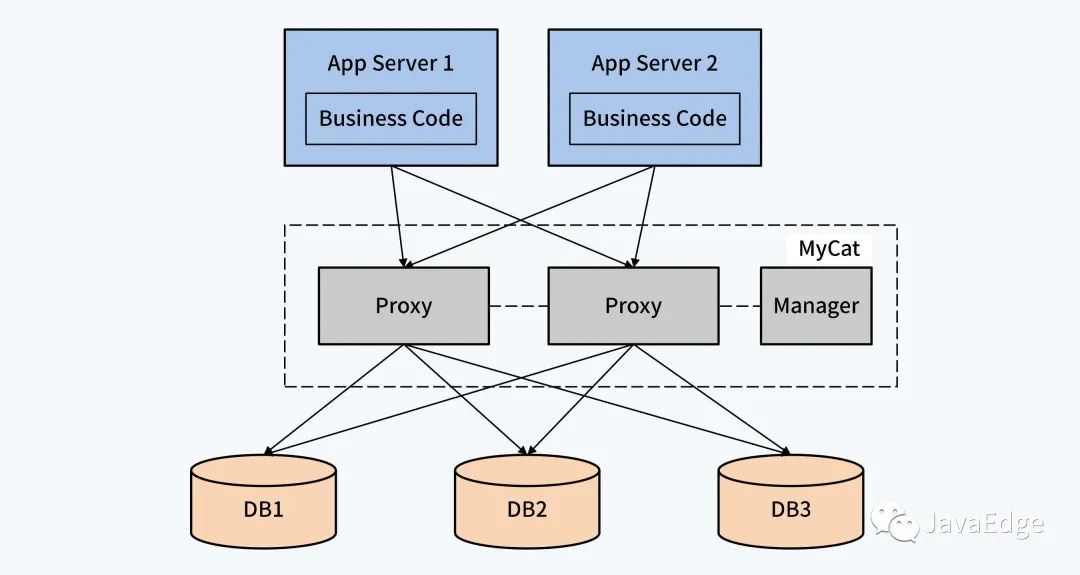
4.2 代理中間件 + 單體 DB
以獨(dú)立中間件的方式,管理數(shù)據(jù)規(guī)則和路由規(guī)則,以獨(dú)立進(jìn)程存在,與業(yè)務(wù)應(yīng)用層和單體 DB相隔離,減少了對(duì)應(yīng)用的影響。隨著代理中間件的發(fā)展,還會(huì)衍生出部分分布式事務(wù)處理能力。
這種中間件的典型產(chǎn)品是MyCat。
 img
img
4.3 單元化架構(gòu) + 單體 DB
單元化架構(gòu)是對(duì)業(yè)務(wù)應(yīng)用系統(tǒng)的徹底重構(gòu),應(yīng)用系統(tǒng)被拆分成若干實(shí)例,配置獨(dú)立的單體 DB,讓每個(gè)實(shí)例管理一定范圍的數(shù)據(jù)。例如對(duì)于銀行貸款系統(tǒng),可以為每個(gè)支行搭建獨(dú)立的應(yīng)用實(shí)例,管理支行各自的用戶,當(dāng)出現(xiàn)跨支行業(yè)務(wù)時(shí),由應(yīng)用層代碼通過分布式事務(wù)組件保證事務(wù)的ACID特性。
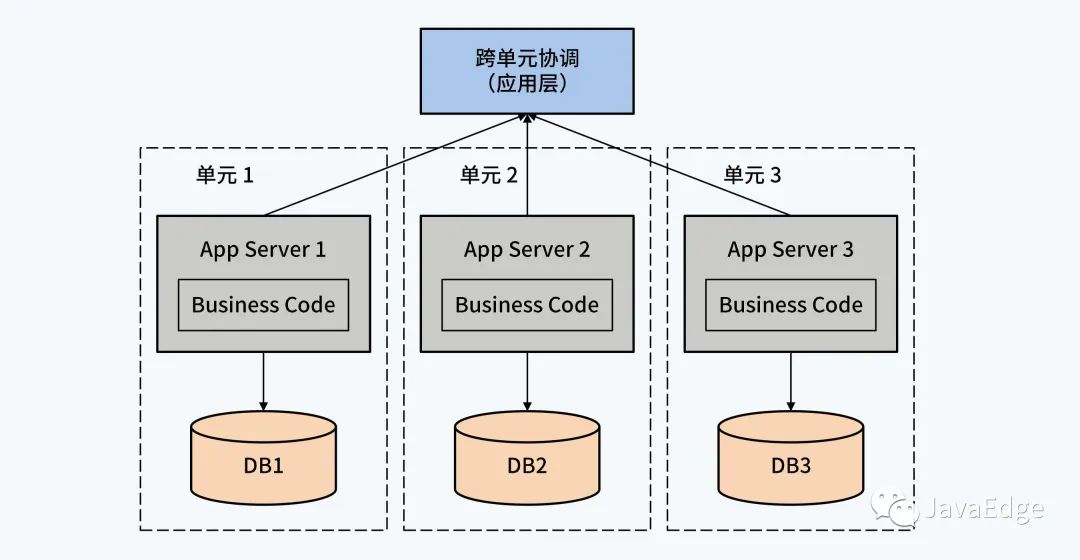
根據(jù)不同的分布式事務(wù)模型,應(yīng)用系統(tǒng)要配合改造,復(fù)雜性也相應(yīng)增加。例如TCC模型下,應(yīng)用必須能夠提供冪等操作。
在分布式 DB出現(xiàn)前,一些頭部互聯(lián)網(wǎng)公司使用過這種架構(gòu)風(fēng)格,該方案的應(yīng)用系統(tǒng)的改造量最大,實(shí)施難度也最高。
共同的特點(diǎn)是單體DB仍能夠被應(yīng)用系統(tǒng)感知到。相反,分布式 DB則是將技術(shù)細(xì)節(jié)收斂到產(chǎn)品內(nèi)部,以一個(gè)整體面對(duì)業(yè)務(wù)應(yīng)用。
分布式 DB的內(nèi)部架構(gòu)到底長什么樣?它跟這三種方案有什么區(qū)別呢?敬請(qǐng)期待系列教程后文。
5 亞馬遜的Aurora
和這里說的分布式DB有明顯差別,了解Aurora或同類產(chǎn)品嗎?和本文分布式DB差異在哪?為啥會(huì)有這種差異?
為啥說Aurora不是分布式DB?Aurora存算分離,使亞馬遜云存儲(chǔ)服務(wù)更高效、易使用。算是NewSQL中比較成功的了。
特點(diǎn)
Aurora是提出一種新的單體架構(gòu)以減少網(wǎng)絡(luò)IO和同步阻塞,邏輯上可以看做一個(gè)龐大的單體 DB,用分布式來支持容錯(cuò)和高吞吐量。:
-
Aurora分片的方式是將 DB的總?cè)萘縿澐譃楣潭ù笮〉臄?shù)據(jù)段,在每一段內(nèi)存儲(chǔ)數(shù)據(jù),每一個(gè)段是一組機(jī)器(六個(gè)),個(gè)人覺得算支持分片
-
寫多讀少、低延時(shí)這就是Aurora所重點(diǎn)的做的事情,通過log is database和支持異步來實(shí)現(xiàn)
-
海量存儲(chǔ)可靠堆機(jī)器(當(dāng)然這些機(jī)器肯定是有一個(gè)控制中心來管理的,論文中沒有提)
-
高可靠則是靠每一個(gè)數(shù)據(jù)段把數(shù)據(jù)冗余到三個(gè)可用區(qū)的六臺(tái)機(jī)器
-
而且它同樣也是關(guān)系型DB
但Aurora特點(diǎn)是Share storage,計(jì)算節(jié)點(diǎn)垂直擴(kuò)展,存儲(chǔ)節(jié)點(diǎn)水平擴(kuò)展,寫入性能收單機(jī)資源的影響。
投票機(jī)制
aurora也用到了,6個(gè)副本,半數(shù)以上就確認(rèn)寫入成功。但無分片,不能多寫,肯定不算分布式。
不能多寫(重點(diǎn)!),適用場景有很大區(qū)別,所以這是個(gè)重要標(biāo)準(zhǔn)。但因?yàn)锳urora是基于共享存儲(chǔ),所以說它是分布式也不是沒道理。定標(biāo)準(zhǔn)只是為讓學(xué)習(xí)思路清晰。
實(shí)際場景Aurora和分布式存儲(chǔ)的應(yīng)用的差別
Aurora還是關(guān)系型 DB,而分布式存儲(chǔ)系統(tǒng)范圍較廣,比如HBase這樣的分布式鍵值系統(tǒng)。兩者在功能上有很大差異。
AWS aurora,阿里polarDB,騰訊CynosDB,華為的Taurus等產(chǎn)品都是類似架構(gòu):計(jì)算存儲(chǔ)分離。所有計(jì)算節(jié)點(diǎn)都訪問存儲(chǔ)節(jié)點(diǎn)上的同一份數(shù)據(jù),也可以說是分布式架構(gòu)。這架構(gòu)的局限是寫入不能橫向擴(kuò)展,對(duì)很多小規(guī)模應(yīng)用夠了,所以不影響它取得商業(yè)成功。
阿里的PolarDB是分布式DB?它采用哪種方案?
PolarDB和Aurora架構(gòu)類似,存算分離,計(jì)算節(jié)點(diǎn)垂直擴(kuò)展,存儲(chǔ)節(jié)點(diǎn)水平擴(kuò)展。代表其寫入能力有上限,但因簡化了日志存儲(chǔ)和其他一些優(yōu)化,單點(diǎn)能力比普通MySQL強(qiáng)很多。
6 總結(jié)
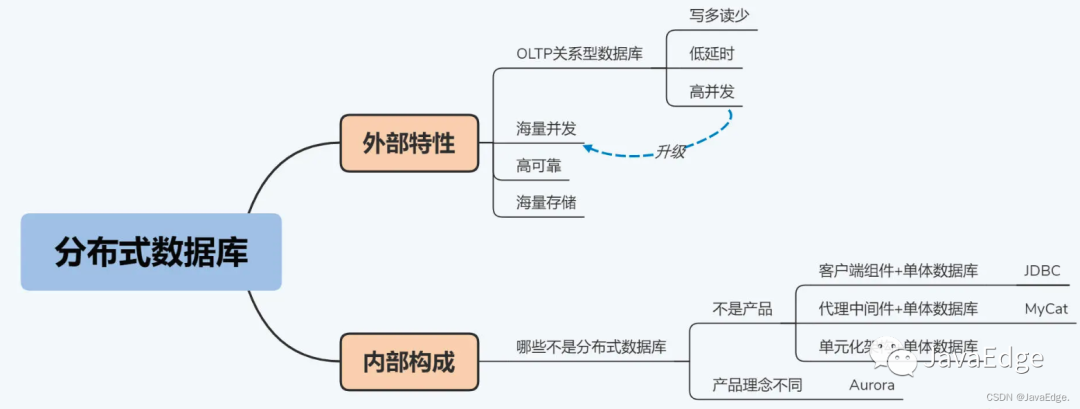
逐層遞進(jìn),勾勒出分布式 DB的六個(gè)外部特性:寫多讀少、低延時(shí)、海量并發(fā)、海量存儲(chǔ)、高可靠性、關(guān)系型 DB。
也存在一些與分布式 DB能力近似解決方案,它們不足之處是都需要對(duì)應(yīng)用系統(tǒng)進(jìn)行一定的改造,對(duì)應(yīng)用的侵入程度更深;其優(yōu)勢(shì)則在于可以最大程度利用單體 DB的穩(wěn)定可靠,畢竟這些特性已經(jīng)歷經(jīng)無數(shù)次的考驗(yàn)。
分布式DB的名稱做一些延伸。
“分布式 DB”在字面上可以分解為“分布式”和“ DB”兩部分,代表了它是跨學(xué)科的產(chǎn)物,它的理論基礎(chǔ)來自兩個(gè)領(lǐng)域。這同時(shí)也呼應(yīng)了產(chǎn)品發(fā)展的兩條不同路徑,一些產(chǎn)品是從分布式存儲(chǔ)系統(tǒng)出發(fā),進(jìn)而增加關(guān)系型 DB的能力;另外一些產(chǎn)品是從單體 DB出發(fā),增加分布式技術(shù)元素。而隨著分布式 DB的走向工業(yè)應(yīng)用,在外部需求的驅(qū)動(dòng)下,這兩種發(fā)展思路又呈現(xiàn)出進(jìn)一步融合的趨勢(shì)。
7 FAQ
① 寫多讀少不應(yīng)加入分布式DB的定義?
分布式DB服務(wù)寫多讀少應(yīng)用,我覺得不管寫多讀多都可應(yīng)用分布式,關(guān)鍵是單體承擔(dān)不了這么多請(qǐng)求了(不論讀寫),所以高并發(fā)就夠了,寫多讀少不應(yīng)加入分布式DB的定義?
強(qiáng)調(diào)寫多讀少,是因?yàn)椋?/p>
- 寫操作的負(fù)載只能是單體DB的主節(jié)點(diǎn),無法轉(zhuǎn)移
- 而讀操作,如對(duì)一致性要求不高,可轉(zhuǎn)移到備節(jié)點(diǎn),甚至在某些條件下還能保證一致性。就是說單體DB可通過一主多備解決讀負(fù)載大問題,而無需引入分布式DB
云dbms在分布式基礎(chǔ)上,更關(guān)注計(jì)算存儲(chǔ)分離后可獨(dú)立擴(kuò)展,甚至動(dòng)態(tài)擴(kuò)縮容,self-driven搞起來,更好賣了。這也引發(fā)不少問題,aurora類 DB提出log is database思想,降低寫壓力,snowflake通過建立中間分布式換存層,降低網(wǎng)絡(luò)瓶頸等。
② 分布式DB V.S 分庫分表
分布式關(guān)系型DB,感覺就是把客戶端或中間件的方案直接作為DB服務(wù)端的特性組件,把分庫分表做得更自動(dòng)化?
最大區(qū)別在于:
- 分布式DB使用體驗(yàn)很接近關(guān)系型DB,無需應(yīng)用進(jìn)行額外控制,大大降低業(yè)務(wù)代碼開發(fā)難度
- 而分庫分表方案在分布式事務(wù)和跨節(jié)點(diǎn)查詢等方面,支持的都不好
③ MyCat這種怎么說?
隨分布式DB發(fā)展,MyCat這類中間件市場會(huì)越來越小。當(dāng)然,它的使用場景也可能轉(zhuǎn)向?qū)Ξ悩?gòu)DB支持,就像Presto。
④ 都說互聯(lián)網(wǎng)應(yīng)用數(shù)據(jù)請(qǐng)求“讀多寫少”
所以有了一主多從讀寫分離、全量數(shù)據(jù)緩存等解決“讀”問題的擴(kuò)容手段。如果說的是同一個(gè)指標(biāo),是否意味著分布式DB不適合互聯(lián)網(wǎng)應(yīng)用?
互聯(lián)網(wǎng)確實(shí)可通過一主多滿足“讀多寫少”,但前提是對(duì)讀對(duì)一致性要求低。而金融場景,很多讀操作依然無法在備庫運(yùn)行,就是一致性不滿足要求。所以,對(duì)互聯(lián)網(wǎng)也不能一概而論,還是區(qū)分場景。
⑤ 交易場景下,交易代碼配合分布式 DB而做出的交易補(bǔ)償或者數(shù)據(jù)回放等
如需要交易代碼配合做出補(bǔ)償和回放,這很可能意味著它不是分布式DB。分布式DB成熟前,確有不少應(yīng)用代碼配合單體 DB。這類應(yīng)用代碼也會(huì)被抽離出來形成獨(dú)立框架,如阿里SOFA。
⑥ Newsql落地如何?
如北京銀行和光大銀行都上線TiDB,Oceanbase也在南京銀行落地。
⑦ BigTable算特殊的(代理中間件 + 單體 DB(分布式文件系統(tǒng)))嗎?
畢竟靠Chubby作為一個(gè)中間層,不過數(shù)據(jù)的獲取是直接與文件系統(tǒng)中交互完成。
BigTable是分布式KV系統(tǒng),不屬于分布式DB。因?yàn)檫@里所說的分布式DB是分布式架構(gòu)實(shí)現(xiàn)的關(guān)系型DB。當(dāng)然它底層依賴一個(gè)分布式文件系統(tǒng),所以看上去也分兩層,但職能和DB差別很大,建議關(guān)注PGXC風(fēng)格分布式DB。
⑧ 基于OLAP使用場景的分布式關(guān)系型DB產(chǎn)品
最典型的MPP架構(gòu)DB,如Greenplum和華為的GaussDB 200,內(nèi)核都使用PostgreSQL。還有Vertica。OLAP不再強(qiáng)調(diào)事務(wù)支持,如果弱化對(duì)數(shù)據(jù)更新要求,很多大數(shù)據(jù)生態(tài)的產(chǎn)品都可納入,如Clickhouse,Hive on spark,甚至Kylin都算是廣義OLAP分布式DB。
end
* 版權(quán)聲明: 轉(zhuǎn)載文章和圖片均來自公開網(wǎng)絡(luò),版權(quán)歸作者本人所有,推送文章除非無法確認(rèn),我們都會(huì)注明作者和來源。如果出處有誤或侵犯到原作者權(quán)益,請(qǐng)與我們聯(lián)系刪除或授權(quán)事宜。
長按識(shí)別圖中二維碼
關(guān)注獲取更多資訊
不點(diǎn)關(guān)注,我們哪來故事?

點(diǎn)個(gè)再看,你最好看