
Hive SQL到底是個(gè)啥?
1. Hive的能力與應(yīng)用概述
Hadoop實(shí)現(xiàn)了一個(gè)特別的計(jì)算模型,就是MapReduce,可以將我們的計(jì)算任務(wù)分拆成多個(gè)小的計(jì)算單元,然后分配到家用或者服務(wù)器級別的硬件機(jī)器上,從而達(dá)到降低成本以及可擴(kuò)展的問題,在這個(gè)MapReduce計(jì)算模型底下,有一個(gè)分布式文件系統(tǒng)(HDFS),在支持分布式計(jì)算上極其重要。
而Hive就是用來查詢存儲在Hadoop集群上數(shù)據(jù)而存在的,它提供了HiveQL,語法與我們平時(shí)接觸的SQL大同小異,它讓我們不需要去調(diào)用底層的MapReduce Java API,只需要直接寫熟悉的SQL,即可自動進(jìn)行轉(zhuǎn)換。‘
當(dāng)然Hive并不是一個(gè)完整的數(shù)據(jù)庫,Hadoop以及HDFS的設(shè)計(jì),本身就約束和局限了Hive的能力:
1)最大的限制就是不支持?jǐn)?shù)據(jù)行級別的Update、Delete操作;
2)不支持事務(wù),因此不支持OLTP所需要的關(guān)鍵功能,它更接近OLAP,但是查詢效率又十分堪憂;
3)查詢效率堪憂,主要是因?yàn)镠adoop是批處理系統(tǒng),而MapReduce任務(wù)(JOB)的啟動過程需要消耗較長的時(shí)間;
4)如果用戶需要對大規(guī)模數(shù)據(jù)使用OLTP功能的話,可以選擇Hadoop的HBase及Cassandra。
綜上所述,Hive最合適的應(yīng)用場景就是我們當(dāng)前的做數(shù)據(jù)倉庫、數(shù)據(jù)中臺等等的工作,維護(hù)海量數(shù)據(jù),挖掘數(shù)據(jù)中的寶藏,形成報(bào)表、報(bào)告、建議等等。
2. MapReduce綜述
如上,我們知道MapReduce是一種計(jì)算模型,該模型可以將大規(guī)模數(shù)據(jù)處理的任務(wù)拆分成多個(gè)小計(jì)算單元,然后分配到集群中的機(jī)器上去并行計(jì)算,最終合并結(jié)果返回給用戶。MapReduce主要分兩個(gè)數(shù)據(jù)轉(zhuǎn)換操作,map和reduce過程。
Map:map操作將集合中的元素從一種形式轉(zhuǎn)成另外一種形式。
Reduce:將值的集合轉(zhuǎn)換成一個(gè)值。
這些map和reduce任務(wù),就是Hadoop將job拆分后的子任務(wù)(task),然后調(diào)度這些task去完成數(shù)據(jù)的計(jì)算,而計(jì)算的位置一般都是在數(shù)據(jù)所在的位置,從而可以保證最小化網(wǎng)絡(luò)開銷。
3. Hadoop生態(tài)系統(tǒng)中的Hive
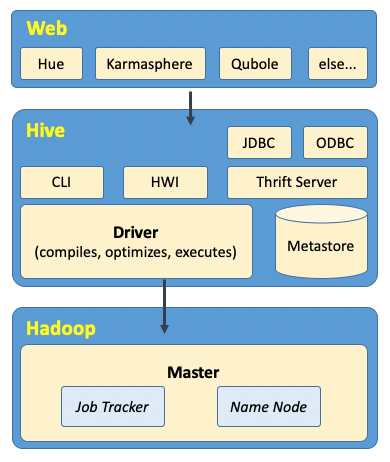
Hive主要由下圖中的模塊組成,主要分3部分(Web+Hive+Hadoop)。直接與我們用戶交互的Web圖形界面,有很多商業(yè)化的、開源的產(chǎn)品,如圖所示;當(dāng)然,發(fā)行版的Hive也自帶有交互界面,如命令行界面(CLI)和簡單的Hive網(wǎng)頁界面(HWI),以及一列JDBC、ODBC、Thrift Server的編程模塊。
我們所有的命令和查詢,都會首先進(jìn)入到Driver(驅(qū)動模塊),通過該模塊進(jìn)行任務(wù)的解析編譯,優(yōu)化任務(wù),生成Job執(zhí)行計(jì)劃,Driver的基礎(chǔ)模塊主要負(fù)責(zé)“語言翻譯”,把job執(zhí)行計(jì)劃的XML文件驅(qū)動執(zhí)行內(nèi)置的、原生的Mapper和Reducer模塊,從而實(shí)現(xiàn)MapReduce任務(wù)執(zhí)行。
Thrift Server提供了可遠(yuǎn)程訪問其他進(jìn)程的功能,也提供使用JDBC和ODBC訪問Hive的功能。另外再介紹一下Metastore,這是專門存儲元數(shù)據(jù)的獨(dú)立關(guān)系型數(shù)據(jù)庫(一般是一個(gè)MySQL實(shí)例),Hive使用它的服務(wù)來存儲表模式信息和其他元數(shù)據(jù)信息,需要使用JDBC來連接。
Hive通過和Job Tracker通信來初始化MapReduce任務(wù)(job),不必要部署在Job Tracker所在的管理節(jié)點(diǎn)上(一般在網(wǎng)關(guān)機(jī)上),之前也提到過,job拆分開的task任務(wù),一般都會在數(shù)據(jù)所在的節(jié)點(diǎn)直接申請機(jī)器資源進(jìn)行計(jì)算,數(shù)據(jù)文件存儲于HDFS中,管理HDFS的是NameNode。
當(dāng)實(shí)際執(zhí)行一個(gè)分布式任務(wù)時(shí)候,集群會啟動多個(gè)服務(wù)。其中,Job Tracker管理著Job,而HDFS則由Name Node管理著,每個(gè)工作節(jié)點(diǎn)上都有job task在執(zhí)行,由每個(gè)節(jié)點(diǎn)的Task Tracker服務(wù)管理著,而且每個(gè)節(jié)點(diǎn)上還存放著分布式文件系統(tǒng)中的文件數(shù)據(jù)塊,由每個(gè)節(jié)點(diǎn)上的DataNode服務(wù)管理著。
4. Hive調(diào)優(yōu)
1. JOIN調(diào)優(yōu)
Hive假定查詢中最后一個(gè)表上最大的表,所以,在對每行記錄進(jìn)行連接操作時(shí),它會嘗試將其他表緩存起來,然后掃描最后那個(gè)表進(jìn)行計(jì)算。因此我們需要保證連續(xù)join查詢中表的大小從左往右是依次增加的。
#?低效查詢
select?*?from?big_table?a?
left?join?small_table?b?on?a.id?=?b.id??
#?高效查詢
select?*?from?small_table?a?
right?join?big_table?b?on?a.id?=?b.id??
另外,如果其中一張表是小表,還可以放入內(nèi)存,Hive就可以在map端執(zhí)行連接操作(稱為 map-side JOIN),從而省略了常規(guī)連接操作中的reduce過程。
set?hive.auto.convert.join=true;
用戶可以自己配置小表的大小(單位:字節(jié))
set?hive.mapjoin.smalltable.filesize=30000000;
2. 使用 EXPLAIN
使用explain很簡單,就是在SQL語句最前面加上 EXPLAIN 關(guān)鍵詞即可,更多姿勢:
explain:查看執(zhí)行計(jì)劃的基本內(nèi)容;
explain analyze:用實(shí)際的SQL行數(shù)注釋計(jì)劃。從 Hive 2.2.0?開始支持;
explain authorization:查看SQL操作相關(guān)權(quán)限的信息;
explain ast:輸出查詢的抽象語法樹。AST 在 Hive 2.1.0?版本刪除了,存在bug,轉(zhuǎn)儲AST可能會導(dǎo)致OOM錯(cuò)誤,將在4.0.0版本修復(fù);
explain extended:加上 extended 可以輸出有關(guān)計(jì)劃的額外信息。
使用EXPLAIN可以幫助我們?nèi)チ私鈎ive執(zhí)行順序,協(xié)助優(yōu)化Hive,對我們提升Hive腳本效率有著很大的幫助。
explain
select
??count(0)?t1,
??count(distinct?cust_id)?t2
from
??dm_dl.cust_info
where
??inc_day?=?'20210920'
limit
??1
輸出內(nèi)容如下,可以看下我的注釋,輸出主要兩部分:
1)stage dependencies:負(fù)責(zé)輸出每個(gè)stage之間的依賴
2)stage plan:每個(gè)stage的執(zhí)行計(jì)劃。stage里會有MapReduce的執(zhí)行計(jì)劃樹,分為Map端和Reduce端,關(guān)鍵詞為 Map Operator Tree 和 Reduce Operator Tree。
每個(gè)stage都是一個(gè)獨(dú)立的MapReduce Job,可以從執(zhí)行計(jì)劃的描述大概猜到具體做了什么步驟,另外,執(zhí)行計(jì)劃中關(guān)于數(shù)據(jù)量的值僅供參考,因?yàn)槭穷A(yù)估的,可能與實(shí)際的有一定出入。
STAGE?DEPENDENCIES:?#?顯示每個(gè)stage之間的前后依賴關(guān)系
?Stage-1?is?a?root?stage
?Stage-0?depends?on?stages:?Stage-1
?
STAGE?PLANS:?#?執(zhí)行計(jì)劃明細(xì)
?Stage:?Stage-1?#?第一個(gè)stage
??Map?Reduce?
???Map?Operator?Tree:?#?Map端的邏輯操作樹
????TableScan?#?掃描table
?????alias:?cust_info
?????Statistics:?Num?rows:?1115055?Data?size:?113735610?Basic?stats:?COMPLETE?Column?stats:?NONE
?????Select?Operator
??????expressions:?cust_id?(type:?string)
??????outputColumnNames:?_col1
??????Statistics:?Num?rows:?1115055?Data?size:?113735610?Basic?stats:?COMPLETE?Column?stats:?NONE
?????Group?By?Operator
??????aggregations:?count(0),?count(DISTINCT?_col1)
??????keys:?_col1?(type:?string)
??????mode:?hash
??????outputColumnNames:?_col0,?_col1,?_col2
??????Statistics:?Num?rows:?1115055?Data?size:?113735610?Basic?stats:?COMPLETE?Column?stats:?NONE
?????Reduce?Output?Operator
??????key?expressions:?_col0?(type:?string)
??????sort?order:?+?#?可以看到聚合后的結(jié)果是有排序的
??????Statistics:?Num?rows:?1115055?Data?size:?113735610?Basic?stats:?COMPLETE?Column?stats:?NONE
??????TopN?Hash?Memory?Usage:?0.1
??????value?expressions:?_col1?(type:?bigint)
??????
??????
???Reduce?Operator?Tree:?#?Reduce端的邏輯操作樹
????Group?By?Operator
?????aggregations:?count(VALUE._col0),?count(DISTINCT?KEY._col0:0._col0)
?????mode:?mergepartial
?????outputColumnNames:?_col0,?_col1
?????Statistics:?Num?rows:?1?Data?size:?24?Basic?stats:?COMPLETE?Column?stats:?NONE
????Limit
?????Number?of?rows:?1
?????Statistics:?Num?rows:?1?Data?size:?24?Basic?stats:?COMPLETE?Column?stats:?NONE
????File?Output?Operator?#?文件輸出操作
?????compressed:?false
?????Statistics:?Num?rows:?1?Data?size:?24?Basic?stats:?COMPLETE?Column?stats:?NONE
?????table:
??????input?format:?org.apache.hadoop.mapred.TextInputFormat
??????output?format:?org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
??????serde:?org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
??????
??????
Stage:?Stage-0
?Fetch?Operator
??limit:?1
??Processor?Tree:
???ListSink
加入關(guān)鍵字 explain formatted 就可以以json格式輸出啦。
{
????"STAGE?DEPENDENCIES":?{
????????"Stage-1":?{
????????????"ROOT?STAGE":?"TRUE"
????????},?
????????"Stage-0":?{
????????????"DEPENDENT?STAGES":?"Stage-1"
????????}
????},?
????"STAGE?PLANS":?{
????????"Stage-1":?{
????????????"Map?Reduce":?{
????????????????"Map?Operator?Tree:":?[
????????????????????{
????????????????????????"TableScan":?{
????????????????????????????"alias:":?"cust_info",?
????????????????????????????"filterExpr:":?"(inc_day?=?'20210920')?(type:?boolean)",?
????????????????????????????"Statistics:":?"Num?rows:?1115055?Data?size:?113735610?Basic?stats:?COMPLETE?Column?stats:?NONE",?
????????????????????????????"children":?{
????????????????????????????????"Select?Operator":?{
????????????????????????????????????"expressions:":?"cust_id?(type:?string)",?
????????????????????????????????????"outputColumnNames:":?[
????????????????????????????????????????"_col1"
????????????????????????????????????],?
????????????????????????????????????"Statistics:":?"Num?rows:?1115055?Data?size:?113735610?Basic?stats:?COMPLETE?Column?stats:?NONE",?
????????????????????????????????????"children":?{
????????????????????????????????????????"Group?By?Operator":?{
????????????????????????????????????????????"aggregations:":?[
????????????????????????????????????????????????"count(0)",?
????????????????????????????????????????????????"count(DISTINCT?_col1)"
????????????????????????????????????????????],?
????????????????????????????????????????????"keys:":?"_col1?(type:?string)",?
????????????????????????????????????????????"mode:":?"hash",?
????????????????????????????????????????????"outputColumnNames:":?[
????????????????????????????????????????????????"_col0",?
????????????????????????????????????????????????"_col1",?
????????????????????????????????????????????????"_col2"
????????????????????????????????????????????],?
????????????????????????????????????????????"Statistics:":?"Num?rows:?1115055?Data?size:?113735610?Basic?stats:?COMPLETE?Column?stats:?NONE",?
????????????????????????????????????????????"children":?{
????????????????????????????????????????????????"Reduce?Output?Operator":?{
????????????????????????????????????????????????????"key?expressions:":?"_col0?(type:?string)",?
????????????????????????????????????????????????????"sort?order:":?"+",?
????????????????????????????????????????????????????"Statistics:":?"Num?rows:?1115055?Data?size:?113735610?Basic?stats:?COMPLETE?Column?stats:?NONE",?
????????????????????????????????????????????????????"TopN?Hash?Memory?Usage:":?"0.1",?
????????????????????????????????????????????????????"value?expressions:":?"_col1?(type:?bigint)"
????????????????????????????????????????????????}
????????????????????????????????????????????}
????????????????????????????????????????}
????????????????????????????????????}
????????????????????????????????}
????????????????????????????}
????????????????????????}
????????????????????}
????????????????],?
????????????????"Reduce?Operator?Tree:":?{
????????????????????"Group?By?Operator":?{
????????????????????????"aggregations:":?[
????????????????????????????"count(VALUE._col0)",?
????????????????????????????"count(DISTINCT?KEY._col0:0._col0)"
????????????????????????],?
????????????????????????"mode:":?"mergepartial",?
????????????????????????"outputColumnNames:":?[
????????????????????????????"_col0",?
????????????????????????????"_col1"
????????????????????????],?
????????????????????????"Statistics:":?"Num?rows:?1?Data?size:?24?Basic?stats:?COMPLETE?Column?stats:?NONE",?
????????????????????????"children":?{
????????????????????????????"Limit":?{
????????????????????????????????"Number?of?rows:":?"1",?
????????????????????????????????"Statistics:":?"Num?rows:?1?Data?size:?24?Basic?stats:?COMPLETE?Column?stats:?NONE",?
????????????????????????????????"children":?{
????????????????????????????????????"File?Output?Operator":?{
????????????????????????????????????????"compressed:":?"false",?
????????????????????????????????????????"Statistics:":?"Num?rows:?1?Data?size:?24?Basic?stats:?COMPLETE?Column?stats:?NONE",?
????????????????????????????????????????"table:":?{
????????????????????????????????????????????"input?format:":?"org.apache.hadoop.mapred.TextInputFormat",?
????????????????????????????????????????????"output?format:":?"org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat",?
????????????????????????????????????????????"serde:":?"org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe"
????????????????????????????????????????}
????????????????????????????????????}
????????????????????????????????}
????????????????????????????}
????????????????????????}
????????????????????}
????????????????}
????????????}
????????},?
????????"Stage-0":?{
????????????"Fetch?Operator":?{
????????????????"limit:":?"1",?
????????????????"Processor?Tree:":?{
????????????????????"ListSink":?{?}
????????????????}
????????????}
????????}
????}
}
5. HiveSQL背后實(shí)現(xiàn)原理
平時(shí)我們經(jīng)常寫Hive SQL,我們知道Hive會自動幫我們轉(zhuǎn)譯成MapReduce Job,調(diào)用集群分布式能力去完成任務(wù)計(jì)算。那么,Hive是如何將SQL轉(zhuǎn)化成MapReduce Job的?可以見下圖:

主要就是通過5步完成,從Hive SQl --> AST Tree --> Query Block --> Operator Tree --> MapReduce Job --> 執(zhí)行計(jì)劃DAG。

推薦閱讀
歡迎長按掃碼關(guān)注「數(shù)據(jù)管道」