
基于Apache Hudi構(gòu)建智能湖倉(cāng)實(shí)踐(附亞馬遜工程師代碼)
轉(zhuǎn)自:hudi
數(shù)據(jù)倉(cāng)庫(kù)的數(shù)據(jù)體系嚴(yán)格、治理容易,業(yè)務(wù)規(guī)模越大,ROI 越高;數(shù)據(jù)湖的數(shù)據(jù)種類豐富,治理困難,業(yè)務(wù)規(guī)模越大,ROI 越低,但勝在靈活。
現(xiàn)在,魚和熊掌我都想要,應(yīng)該怎么辦?湖倉(cāng)一體架構(gòu)就在這種情況下,快速在產(chǎn)業(yè)內(nèi)普及。
要構(gòu)建湖倉(cāng)一體架構(gòu)并不容易,需要解決非常多的數(shù)據(jù)問題。比如,計(jì)算層、存儲(chǔ)層、異構(gòu)集群層都要打通,對(duì)元數(shù)據(jù)要進(jìn)行統(tǒng)一的管理和治理。對(duì)于很多業(yè)內(nèi)技術(shù)團(tuán)隊(duì)而言,已經(jīng)是個(gè)比較大的挑戰(zhàn)。
可即便如此,在亞馬遜云科技技術(shù)專家潘超看來,也未必最能貼合企業(yè)級(jí)大數(shù)據(jù)處理的最新理念。在 11 月 18 日晚上 20:00 的直播中,潘超詳細(xì)分享了亞馬遜云科技眼中的智能湖倉(cāng)架構(gòu),以及以流式數(shù)據(jù)接入為主的最佳實(shí)踐。
傳統(tǒng)湖倉(cāng)一體架構(gòu)的不足之處是,著重解決點(diǎn)的問題,也就是“湖”和“倉(cāng)”的打通,而忽視了面的問題:數(shù)據(jù)在整個(gè)數(shù)據(jù)平臺(tái)的自由流轉(zhuǎn)。
潘超認(rèn)為,現(xiàn)代數(shù)據(jù)平臺(tái)架構(gòu)應(yīng)該具有幾個(gè)關(guān)鍵特征:
以任何規(guī)模來存儲(chǔ)數(shù)據(jù);
在整套架構(gòu)涉及的所有產(chǎn)品體系中,獲得最佳性價(jià)比;
實(shí)現(xiàn)無縫的數(shù)據(jù)訪問,實(shí)現(xiàn)數(shù)據(jù)的自由流動(dòng);
實(shí)現(xiàn)數(shù)據(jù)的統(tǒng)一治理;
用 AI/ML 解決業(yè)務(wù)難題;
在構(gòu)建企業(yè)級(jí)現(xiàn)代數(shù)據(jù)平臺(tái)架構(gòu)時(shí),這五個(gè)關(guān)鍵特征,實(shí)質(zhì)上覆蓋了三方視角 ——
對(duì)于架構(gòu)師而言,第一點(diǎn)和第二點(diǎn)值得引起注意。前者是遷移上云的一大核心訴求,后者是架構(gòu)評(píng)審一定會(huì)過問的核心事項(xiàng);
對(duì)于開發(fā)者而言,第三點(diǎn)和第四點(diǎn)尤為重要,對(duì)元數(shù)據(jù)的管理最重要實(shí)現(xiàn)的是數(shù)據(jù)在整個(gè)系統(tǒng)內(nèi)的自由流動(dòng)和訪問,而不僅僅是打通數(shù)據(jù)湖和數(shù)據(jù)倉(cāng)庫(kù);
對(duì)于產(chǎn)品經(jīng)理而言,第五點(diǎn)點(diǎn)明了當(dāng)下大數(shù)據(jù)平臺(tái)的價(jià)值導(dǎo)向,即數(shù)據(jù)的收集和治理,應(yīng)以解決業(yè)務(wù)問題為目標(biāo)。
為了方便理解,也方便通過 Demo 演示,潘超將這套架構(gòu)體系,同等替換為了亞馬遜云科技現(xiàn)有產(chǎn)品體系,包括:Amazon Athena、Amazon Aurora 、Amazon MSK、Amazon EMR 等,而流式數(shù)據(jù)入湖,重點(diǎn)涉及 Amazon MSK、Amazon EMR,以及另一個(gè)核心服務(wù):Apache Hudi。

Amazon MSK 是亞馬遜托管的高可用、強(qiáng)安全的 Kafka 服務(wù),是數(shù)據(jù)分析領(lǐng)域,負(fù)責(zé)消息傳遞的基礎(chǔ),也因此在流式數(shù)據(jù)入湖部分舉足輕重。
之所以以 Amazon MSK 舉例,而不是修改 Kafka 代碼直接構(gòu)建這套系統(tǒng),是為了最大程度將開發(fā)者的注意力聚焦于流式應(yīng)用本身,而不是管理和維護(hù)基礎(chǔ)設(shè)施。況且,一旦你決定從頭構(gòu)建 PaaS 層基礎(chǔ)設(shè)施,涉及到的工作就不僅僅是拉起一套 Kafka 集群了。一張圖可以很形象地反映這個(gè)問題:

這張圖從左至右,依次為不使用任何云服務(wù)的工作列表,使用 EC2 的工作列表,以及使用 MSK 的工作列表,工作量和 ROI 高下立現(xiàn)。
而對(duì)于 MSK 來說,擴(kuò)展能力是其重要特性。MSK 可以自動(dòng)擴(kuò)容,也可以手動(dòng) API 擴(kuò)容。但如果對(duì)自己的“動(dòng)手能力”沒有充足的信心,建議選擇自動(dòng)擴(kuò)容。
Amazon MSK 的自動(dòng)擴(kuò)容可以根據(jù)存儲(chǔ)利用率來設(shè)定閾值,建議設(shè)定 50%-60%。自動(dòng)擴(kuò)容每次擴(kuò)展 Max(10GB,10%* 集群存儲(chǔ)空間),同時(shí)自動(dòng)擴(kuò)展每次有6 個(gè)小時(shí)的冷卻時(shí)間。一次如果一次需要擴(kuò)容更大的容量,可以使用手動(dòng)擴(kuò)容。
這種擴(kuò)容既包括橫向擴(kuò)容 —— 通過 API 或者控制臺(tái)向集群添加新的 Brokers,期間不會(huì)影響集群的可用性,也包括縱向擴(kuò)容 —— 調(diào)整集群 Broker 節(jié)點(diǎn)的 EC2 實(shí)例類型。
但無論是自動(dòng)還是手動(dòng),是橫向還是縱向,前提都是你已經(jīng)做好了磁盤監(jiān)控,可以使用 CloudWatch 云監(jiān)控集成的監(jiān)控服務(wù),也可以在 MSK 里勾選其他的監(jiān)控服務(wù) (Prometheus),最終監(jiān)控結(jié)果都能可視化顯示。
需要注意的是,MSK 集群增加 Broker,每個(gè)舊 Topic 的分區(qū)如果想重分配,需要手動(dòng)執(zhí)行。重分配的時(shí)候,會(huì)帶來額外的帶寬,有可能會(huì)影響業(yè)務(wù),所以可以通過一些參數(shù)控制 Broker 間流量帶寬,防止過程當(dāng)中對(duì)業(yè)務(wù)造成太大的影響。當(dāng)然像 Cruise 一樣的開源工具,也可以多多用起來。Cruise 是做大規(guī)模集群的管理的 MSK 工具,它可以幫你做 Broker 間負(fù)載的 Re-balance 。
關(guān)于 MSK 集群的高可用,有三點(diǎn)需要注意:
對(duì)于兩 AZ 部署的集群,副本因子至少保證為 3。如果只有 1,那么當(dāng)集群滾動(dòng)升級(jí)的時(shí)候,就不能對(duì)外提供服務(wù)了;
最小的 ISR(in-sync replicas)最多設(shè)置為 RF - 1,不然也會(huì)影響集群的滾動(dòng)升級(jí);
當(dāng)客戶端連接 Broker 節(jié)點(diǎn)時(shí),雖然配置一個(gè) Broker 節(jié)點(diǎn)的連接地址就可以,但還是建議配置多個(gè)。MSK 故障節(jié)點(diǎn)自動(dòng)替換以及在滾動(dòng)升級(jí)的過程中,如果客戶端只配備了一個(gè) Broker 節(jié)點(diǎn),可能會(huì)鏈接超時(shí)。如果配置了多個(gè),還可以重試連接。
在 CPU 層面,CloudWatch 里有兩個(gè)關(guān)于 MSK 的指標(biāo)值得注意,一個(gè)是 CpuSystem,另一個(gè)是 CpuUser,推薦保持在 60% 以下,這樣在 MSK 升級(jí)維護(hù)時(shí),都有足夠的 CPU 資源可用。
如果 CPU 利用率過高,觸發(fā)報(bào)警,則可以通過以下幾種方式來擴(kuò)展 MSK 集群:
垂直擴(kuò)展,通過滾動(dòng)升級(jí)進(jìn)行替換。每個(gè) Broker 的替換大概需要 10-15 分鐘的時(shí)間。當(dāng)然,是否替換集群內(nèi)所有機(jī)器,要根據(jù)實(shí)際情況做選擇,以免造成資源浪費(fèi);
橫向拓展,Topic 增加分區(qū)數(shù);
添加 Broker 到集群,之前創(chuàng)建的 Topic 進(jìn)行 reassign Partitions,重分配會(huì)消耗集群資源,當(dāng)然這是可控的。
最后,關(guān)于 ACK 參數(shù)的設(shè)置也值得注意,ACK = 2 意味著在生產(chǎn)者發(fā)送消息后,等到所有副本都接收到消息,才返回成功。這雖然保證了消息的可靠性,但吞吐率最低。比如日志類數(shù)據(jù),參考業(yè)務(wù)具體情況,就可以酌情設(shè)置 ACK = 1,容忍數(shù)據(jù)丟失的可能,但大幅提高了吞吐率。
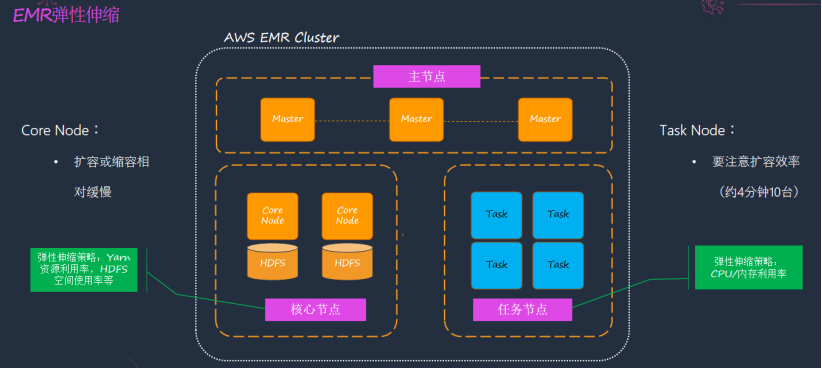
Amazon EMR 是托管的 Hadoop 生態(tài),常用的 Hadoop 組件在 EMR 上都會(huì)有,但是 EMR 核心特征有兩點(diǎn),一是存算分離,二是資源動(dòng)態(tài)擴(kuò)縮。

在大數(shù)據(jù)領(lǐng)域,存算分離概念的熱度,不下于流批一體、湖倉(cāng)一體。以亞馬遜云科技產(chǎn)品棧為例,實(shí)現(xiàn)存算分離后,數(shù)據(jù)是在 S3 上存儲(chǔ),EMR 只是一個(gè)計(jì)算集群,是一個(gè)無狀態(tài)的數(shù)據(jù)。而數(shù)據(jù)與元數(shù)據(jù)都在外部,集群簡(jiǎn)化為無狀態(tài)的計(jì)算資源,用的時(shí)候打開,不用的時(shí)候關(guān)閉就可以。
舉個(gè)例子,凌晨 1 點(diǎn)到 5 點(diǎn),大批 ETL 作業(yè),開啟集群。其他時(shí)間則完全不用開啟集群。用時(shí)開啟,不用關(guān)閉,對(duì)于上云企業(yè)而言,交服務(wù)費(fèi)就像交電費(fèi),格外節(jié)省。
而資源的動(dòng)態(tài)擴(kuò)縮主要是指根據(jù)不同的工作負(fù)載,動(dòng)態(tài)擴(kuò)充節(jié)點(diǎn),按使用量計(jì)費(fèi)。但如果數(shù)據(jù)是在 HDFS 上做存算分離與動(dòng)態(tài)擴(kuò)縮,就不太容易操作了,擴(kuò)縮容如果附帶 DataNote 數(shù)據(jù),就會(huì)引發(fā)數(shù)據(jù)的 Re-balance,非常影響效率。如果單獨(dú)擴(kuò)展 NodeManager,在云下的場(chǎng)景,資源不再是彈性的,集群也一般是預(yù)制好的,與云上有本質(zhì)區(qū)別。
EMR 有三類節(jié)點(diǎn),第一類是 Master 主節(jié)點(diǎn),部署著 Resource Manager 等服務(wù);Core 核心節(jié)點(diǎn),有 DataNote,NodeManager, 依然可以選用 HDFS;第三類是任務(wù)節(jié)點(diǎn),運(yùn)行著 EMR 的 NodeManager 服務(wù),是一個(gè)計(jì)算節(jié)點(diǎn)。所以,EMR 的擴(kuò)縮,在于核心節(jié)點(diǎn)與任務(wù)節(jié)點(diǎn)的擴(kuò)縮,可以根據(jù) YARN 上 Application 的個(gè)數(shù)、CPU 的利用率等指標(biāo)配置擴(kuò)縮策略。也可以使用 EMR 提供 Managed Scaling 策略其內(nèi)置了智能算法來實(shí)現(xiàn)自動(dòng)擴(kuò)縮,也是推薦的方式,對(duì)開發(fā)者而言是無感的。
那么應(yīng)該如何利用 MSK 和 EMR 做數(shù)據(jù)湖的入湖呢?其詳細(xì)架構(gòu)圖如下,分作六步詳解:
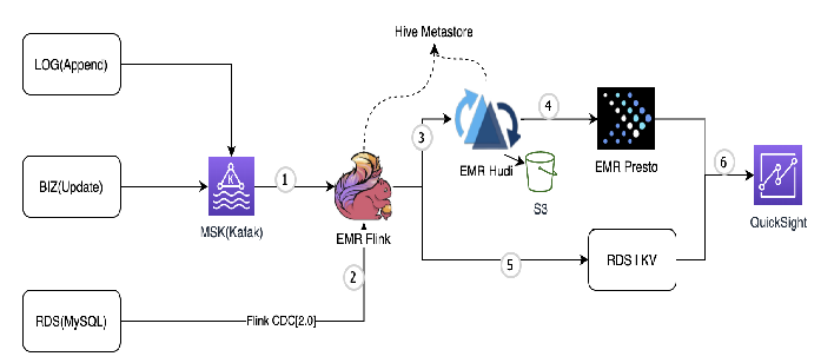
圖中標(biāo)號(hào) 1:日志數(shù)據(jù)和業(yè)務(wù)數(shù)據(jù)發(fā)送?MSK(Kafka),通過 Flink(TableAPI) 建立Kafka 表,消費(fèi) Kafka 數(shù)據(jù),Hive Metastore 存儲(chǔ) Schema;
圖中標(biāo)號(hào) 2:RDS(MySQL) 中的數(shù)據(jù)通過 Flink CDC(flink-cdc-connector) 直接消費(fèi) Binlog 數(shù)據(jù),?需搭建其他消費(fèi) Binlog 的服務(wù) (?如 Canal,Debezium)。注意使?flink-cdc-connector 的 2.x 版本,?持parallel reading, lock-free and checkpoint feature;
圖中標(biāo)號(hào) 3:使用Flink Hudi Connector, 將數(shù)據(jù)寫?Hudi(S3) 表, 對(duì)于?需 Update 的數(shù)據(jù)使?Insert 模式寫?,對(duì)于需要 Update 的 數(shù)據(jù) (業(yè)務(wù)數(shù)據(jù)和 CDC 數(shù)據(jù)) 使用Upsert 模式寫?;
圖中標(biāo)號(hào) 4:使用Presto 作為查詢引擎,對(duì)外提供查詢服務(wù)。此條數(shù)據(jù)鏈路的延遲取決于入Hudi 的延遲及 Presto 查詢的延遲,總體在分鐘級(jí)別;
圖中標(biāo)號(hào) 5:對(duì)于需要秒級(jí)別延遲的指標(biāo),直接在 Flink 引擎中做計(jì)算,計(jì)算結(jié)果輸出到 RDS 或者 KV 數(shù)據(jù)庫(kù),對(duì)外提供 API 查詢服務(wù);
圖中標(biāo)號(hào) 6:使用QuickSight 做數(shù)據(jù)可視化,支持多種數(shù)據(jù)源接入。
當(dāng)然,在具體的實(shí)踐過程中,仍需要開發(fā)者對(duì)數(shù)據(jù)湖方案有足夠的了解,才能切合場(chǎng)景選擇合適的調(diào)參配置。
Q/A 問答
MSK 托管的是 Apache Kafka,其 API 是完全兼容的,業(yè)務(wù)應(yīng)用代碼不需要調(diào)整,更換為 MSK 的鏈接地址即可。如果已有的 Kafka 集群數(shù)據(jù)要遷移到 MSK,可以使用 MirrorMaker2 做數(shù)據(jù)同步,然后切換應(yīng)用鏈接地址即可。
參考文檔:
https://docs.aws.amazon.com/msk/latest/developerguide/migration.htmlhttps://d1.awsstatic.com/whitepapers/amazon-msk-migration-guide.pdf?did=wp_card&trk=wp_card
MSK 支持 Schema Registry, 不僅支持使用 AWS Glue 作為 Schema Registry, 還支持第三方的比如 confluent-schema-registry
總體來講是分鐘級(jí)別延遲。和數(shù)據(jù)量,選擇的 Hudi 表類型,計(jì)算資源都有關(guān)系。
Amazon EMR 比標(biāo)準(zhǔn) Apache Spark 快 3 倍以上。
Amazon EMR 在 Spark3.0 上比開源 Spark 快 1.7 倍,在 TPC-DS 3TB 數(shù)據(jù)的測(cè)試。
參見:
https://aws.amazon.com/cn/blogs/big-data/run-apache-spark-3-0-workloads-1-7-times-faster-with-amazon-emr-runtime-for-apache-spark/
?Amazon EMR 在 Spark 2.x 上比開源 Spark 快 2~3 倍以上
?Amazon Presto 比開源的 PrestoDB 快 2.6 倍。
參見:
https://aws.amazon.com/cn/blogs/big-data/amazon-emr-introduces-emr-runtime-for-prestodb-which-provides-a-2-6-times-speedup/
這在本次分享中的現(xiàn)代化數(shù)據(jù)平臺(tái)建設(shè)和 Amazon 的智能湖倉(cāng)架構(gòu)圖中都有所體現(xiàn),Amazon 的智能湖倉(cāng)架構(gòu)靈活擴(kuò)展,安全可靠 ; 專門構(gòu)建,極致性能 ; 數(shù)據(jù)融合,統(tǒng)一治理 ; 敏捷分析,深度智能 ; 擁抱開源,開發(fā)共贏。湖倉(cāng)一體只是開始,智能湖倉(cāng)才是終極。
log_uri="s3://*****/emr/log/"key_name="****"jdbc="jdbc:mysql:\/\/*****.ap-southeast-1.rds.amazonaws.com:3306\/hive_metadata_01?createDatabaseIfNotExist=true"cluster_name="tech-talk-001"aws emr create-cluster \--termination-protected \--region ap-southeast-1 \--applications Name=Hadoop Name=Hive Name=Flink Name=Tez Name=SparkName=JupyterEnterpriseGateway Name=Presto Name=HCatalog \--scale-down-behavior TERMINATE_AT_TASK_COMPLETION \--release-label emr-6.4.0 \--ebs-root-volume-size 50 \--service-role EMR_DefaultRole \--enable-debugging \--instance-groups InstanceGroupType=MASTER,InstanceCount=1,InstanceType=m5.xlargeInstanceGroupType=CORE,InstanceCount=2,InstanceType=m5.xlarge \--managed-scaling-policyComputeLimits='{MinimumCapacityUnits=2,MaximumCapacityUnits=5,MaximumOnDemandCapacityUnits=2,MaximumCoreCapacityUnits=2,UnitType=Instances}' \--name "${cluster_name}" \--log-uri "${log_uri}" \--ec2-attributes '{"KeyName":"'${key_name}'","SubnetId":"subnet-0f79e4471cfa74ced","InstanceProfile":"EMR_EC2_DefaultRole"}' \--configurations '[{"Classification": "hive-site","Properties":{"javax.jdo.option.ConnectionURL": "'${jdbc}'","javax.jdo.option.ConnectionDriverName":"org.mariadb.jdbc.Driver","javax.jdo.option.ConnectionUserName":"admin","javax.jdo.option.ConnectionPassword": "xxxxxx"}}]'
# MSK集群創(chuàng)建可以通過CLI, 也可以通過Console創(chuàng)建# 下載kafka,創(chuàng)建topic寫?數(shù)據(jù)wget https://dlcdn.apache.org/kafka/2.6.2/kafka_2.12-2.6.2.tgz# msk zk地址,broker 地址zk_servers=*****.c3.kafka.ap-southeast-1.amazonaws.com:2181bootstrap_server=******.5ybaio.c3.kafka.ap-southeast-1.amazonaws.com:9092topic=tech-talk-001# 創(chuàng)建tech-talk-001 topic./bin/kafka-topics.sh --create --zookeeper ${zk_servers} --replication-factor 2 --partitions 4--topic ${topic}# 寫?消息./bin/kafka-console-producer.sh --bootstrap-server ${bootstrap_server} --topic ${topic}{"id":"1","name":"customer"}{"id":"2","name":"aws"}# 消費(fèi)消息./bin/kafka-console-consumer.sh --bootstrap-server ${bootstrap_server} --topic ${topic}
# 啟動(dòng)flink on yarn session cluster# 下載kafka connectorsudo wget -P /usr/lib/flink/lib/ https://repo1.maven.org/maven2/org/apache/flink/flink-sql?connector-kafka_2.12/1.13.1/flink-sql-connector-kafka_2.12-1.13.1.jar && sudo chown flink:flink/usr/lib/flink/lib/flink-sql-connector-kafka_2.12-1.13.1.jar# hudi-flink-bundle 0.10.0sudo wget -P /usr/lib/flink/lib/ https://dxs9dnjebzm6y.cloudfront.net/tmp/hudi-flink?bundle_2.12-0.10.0-SNAPSHOT.jar && sudo chown flink:flink /usr/lib/flink/lib/hudi-flink?bundle_2.12-0.10.0-SNAPSHOT.jar# 下載 cdc connectorsudo wget -P /usr/lib/flink/lib/ https://repo1.maven.org/maven2/com/ververica/flink-sql?connector-mysql-cdc/2.0.0/flink-sql-connector-mysql-cdc-2.0.0.jar && sudo chown flink:flink/usr/lib/flink/lib/flink-sql-connector-mysql-cdc-2.0.0.jar# flink sessionflink-yarn-session -jm 1024 -tm 4096 -s 2 \-D state.checkpoints.dir=s3://*****/flink/checkpoints \-D state.backend=rocksdb \-D state.checkpoint-storage=filesystem \-D execution.checkpointing.interval=60000 \-D state.checkpoints.num-retained=5 \-D execution.checkpointing.mode=EXACTLY_ONCE \-D execution.checkpointing.externalized-checkpoint-retention=RETAIN_ON_CANCELLATION \-D state.backend.incremental=true \-D execution.checkpointing.max-concurrent-checkpoints=1 \-D rest.flamegraph.enabled=true \-d
# 這是使?flink sql client寫SQL提交作業(yè)# 啟動(dòng)client/usr/lib/flink/bin/sql-client.sh -s application_*****# result-modeset sql-client.execution.result-mode=tableau;# set default parallesimset 'parallelism.default' = '1';
# 創(chuàng)建kafka表CREATE TABLE kafka_tb_001 (id string,name string,`ts` TIMESTAMP(3) METADATA FROM 'timestamp') WITH ('connector' = 'kafka','topic' = 'tech-talk-001','properties.bootstrap.servers' = '****:9092','properties.group.id' = 'test-group-001','scan.startup.mode' = 'latest-offset','format' = 'json','json.ignore-parse-errors' = 'true','json.fail-on-missing-field' = 'false','sink.parallelism' = '2');# 創(chuàng)建flink hudi表CREATE TABLE flink_hudi_tb_106(uuid string,name string,ts TIMESTAMP(3),logday VARCHAR(255),hh VARCHAR(255))PARTITIONED BY (`logday`,`hh`)WITH ('connector' = 'hudi','path' = 's3://*****/teck-talk/flink_hudi_tb_106/','table.type' = 'COPY_ON_WRITE','write.precombine.field' = 'ts','write.operation' = 'upsert','hoodie.datasource.write.recordkey.field' = 'uuid','hive_sync.enable' = 'true','hive_sync.metastore.uris' = 'thrift://******:9083','hive_sync.table' = 'flink_hudi_tb_106','hive_sync.mode' = 'HMS','hive_sync.username' = 'hadoop','hive_sync.partition_fields' = 'logday,hh','hive_sync.partition_extractor_class' = 'org.apache.hudi.hive.MultiPartKeysValueExtractor');# 插?數(shù)據(jù)insert into flink_hudi_tb_106 select id as uuid,name,ts,DATE_FORMAT(CURRENT_TIMESTAMP, 'yyyy?MM-dd') as logday, DATE_FORMAT(CURRENT_TIMESTAMP, 'hh') as hh from kafka_tb_001;# 除了在創(chuàng)建表是指定同步數(shù)據(jù)的?式,也可以通過cli同步hudi表元數(shù)據(jù)到hive,但要注意分區(qū)格式./run_sync_tool.sh --jdbc-url jdbc:hive2:\/\/*****:10000 --user hadop --pass hadoop --partitioned-by logday --base-path s3://****/ --database default --table *****# presto 查詢數(shù)據(jù)presto-cli --server *****:8889 --catalog hive --schema default
# 創(chuàng)建mysql CDC表CREATE TABLE mysql_cdc_002 (id INT NOT NULL,name STRING,create_time TIMESTAMP(3),modify_time TIMESTAMP(3),PRIMARY KEY(id) NOT ENFORCED) WITH ('connector' = 'mysql-cdc','hostname' = '*******','port' = '3306','username' = 'admin','password' = '*****','database-name' = 'cdc_test_db','table-name' = 'test_tb_01','scan.startup.mode' = 'initial');# 創(chuàng)建hudi表CREATE TABLE hudi_cdc_002 (id INT ,name STRING,create_time TIMESTAMP(3),modify_time TIMESTAMP(3)) WITH ('connector' = 'hudi','path' = 's3://******/hudi_cdc_002/','table.type' = 'COPY_ON_WRITE','write.precombine.field' = 'modify_time','hoodie.datasource.write.recordkey.field' = 'id','write.operation' = 'upsert','write.tasks' = '2','hive_sync.enable' = 'true','hive_sync.metastore.uris' = 'thrift://*******:9083','hive_sync.table' = 'hudi_cdc_002','hive_sync.db' = 'default','hive_sync.mode' = 'HMS','hive_sync.username' = 'hadoop');# 寫?數(shù)據(jù)insert into hudi_cdc_002 select * from mysql_cdc_002;
# sysbench 寫?mysql數(shù)據(jù)# 下載sysbenchcurl -s https://packagecloud.io/install/repositories/akopytov/sysbench/script.rpm.sh | sudobashsudo yum -y install sysbench# 注意當(dāng)前使用的“l(fā)ua”并未提供構(gòu)建,請(qǐng)根據(jù)自身情況定義,上述?到表結(jié)構(gòu)如下CREATE TABLE if not exists `test_tb_01` (int NOT NULL AUTO_INCREMENT,varchar(155) DEFAULT NULL,timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATECURRENT_TIMESTAMP,PRIMARY KEY (`id`)ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;# 創(chuàng)建表sysbench creates.lua --mysql-user=admin --mysql-password=admin123456 --mysql?host=****.rds.amazonaws.com --mysql-db=cdc_test_db --report-interval=1 --events=1 run# 插?數(shù)據(jù)sysbench insert.lua --mysql-user=admin --mysql-password=admin123456 --mysql?host=****.rds.amazonaws.com --mysql-db=cdc_test_db --report-interval=1 --events=500 --time=0 --threads=1 --skip_trx=true run# 更新數(shù)據(jù)sysbench update.lua --mysql-user=admin --mysql-password=admin123456 --mysql?host=****.rds.amazonaws.com --mysql-db=cdc_test_db --report-interval=1 --events=1000 --time=0 --threads=10 --skip_trx=true --update_id_min=3 --update_id_max=500 run# 刪除表sysbench drop.lua --mysql-user=admin --mysql-password=admin123456 --mysql?host=****.rds.amazonaws.com --mysql-db=cdc_test_db --report-interval=1 --events=1 run