
入門爬蟲?一文搞定!

文章分三個(gè)個(gè)部分
兩個(gè)爬蟲庫requests和selenium如何使用 html解析庫BeautifulSoup如何使用 動(dòng)態(tài)加載的網(wǎng)頁數(shù)據(jù)用requests怎么抓
兩個(gè)爬蟲庫
requests
假設(shè)windows下安裝好了python和pip。
下面用pip安裝爬蟲庫requests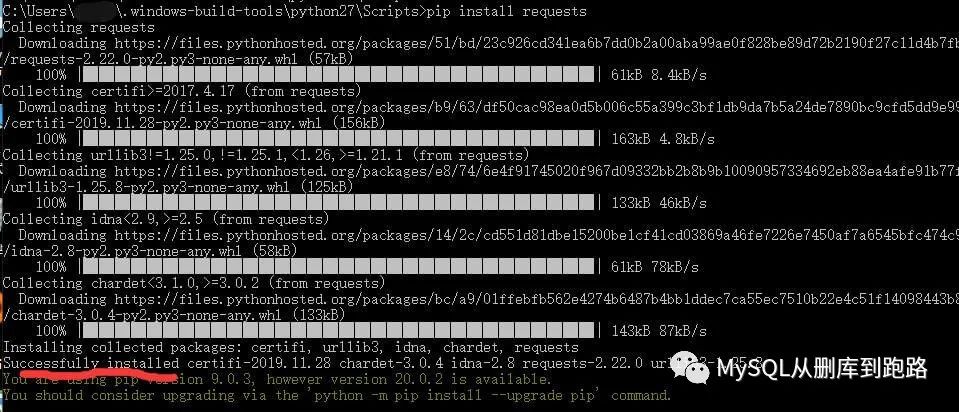
★如果提示pip版本低,不建議升級,升級后可能python本身版本低,導(dǎo)致pip指令報(bào)錯(cuò)。
”
進(jìn)入Python命令行驗(yàn)證requests庫是否能夠使用
看到import requests和requests.get函數(shù)都沒有報(bào)錯(cuò),說明安裝成功可以開發(fā)我們的第一個(gè)爬蟲程序了!
將代碼文件命名為test.py,用IDEL打開。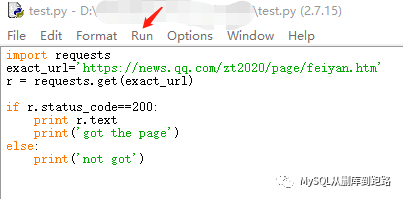
最簡單的爬蟲就這么幾行!
引入requests庫, 用get函數(shù)訪問對應(yīng)地址, 判定是否抓取成功的狀態(tài),r.text打印出抓取的數(shù)據(jù)。
然后菜單欄點(diǎn)擊Run->Run Module 會(huì)彈出Python的命令行窗口,并且返回結(jié)果。我們訪問的是騰訊發(fā)布新冠肺炎疫情的地址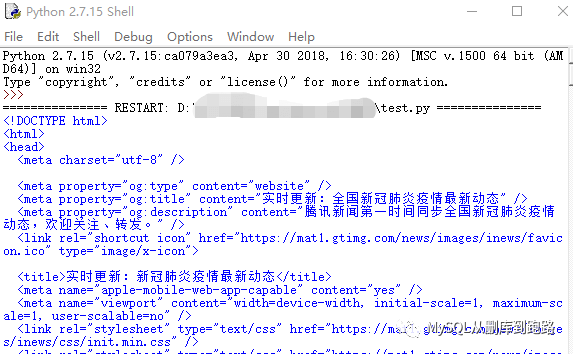
如果沒有IDEL,直接cmd命令行運(yùn)行按照下面執(zhí)行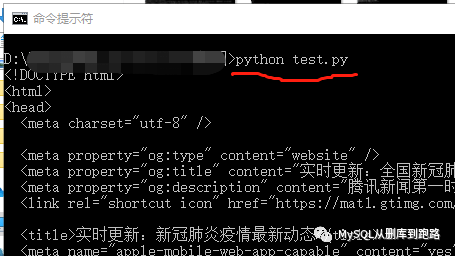
selenium
selenium庫會(huì)啟動(dòng)瀏覽器,用瀏覽器訪問地址獲取數(shù)據(jù)。下面我們演示用selenium抓取網(wǎng)頁,并解析爬取的html數(shù)據(jù)中的信息。先安裝selenium
接下來安裝解析html需要的bs4和lxml。
安裝bs4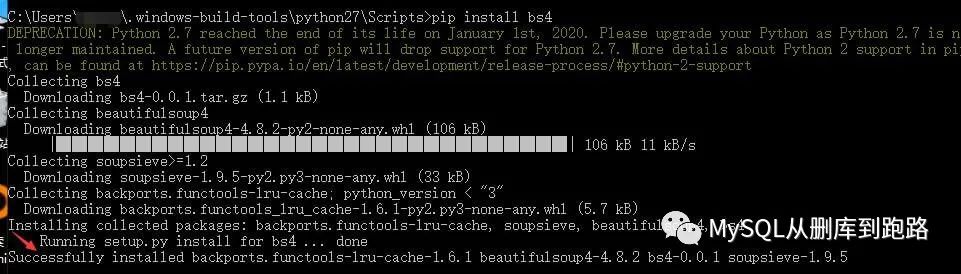
安裝lxml
要確保windows環(huán)境變量path的目錄下有chromedriver
我d盤的instantclient_12_2已經(jīng)加到path里了。所以chromedriver解壓到這個(gè)目錄。chromedriver不同的版本對應(yīng)Chrome瀏覽器的不同版本,開始我下載的chromedriver對應(yīng)Chrome瀏覽器的版本是71-75(圖中最下面的),我的瀏覽器版本是80所以重新下載了一個(gè)才好使。
代碼如下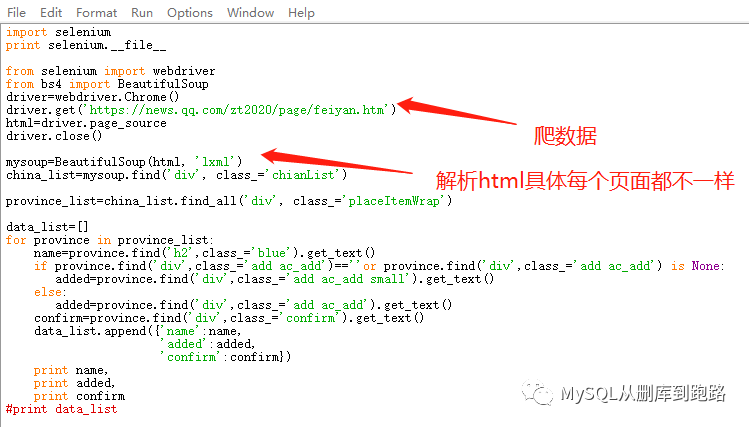
Python執(zhí)行過程中會(huì)彈出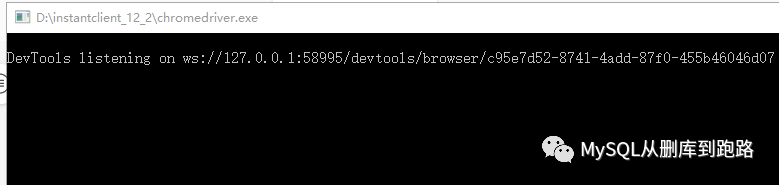
瀏覽器也自動(dòng)啟動(dòng),訪問目標(biāo)地址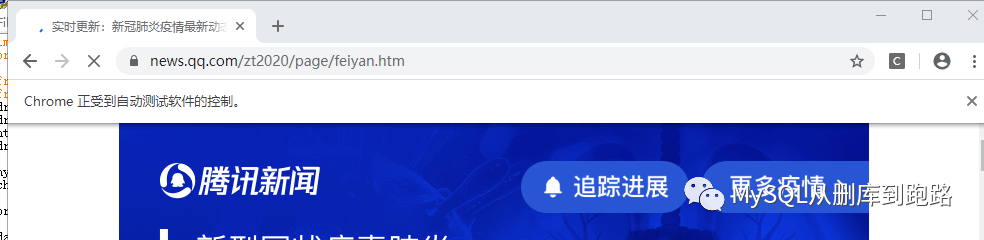
IDEL打印結(jié)果如下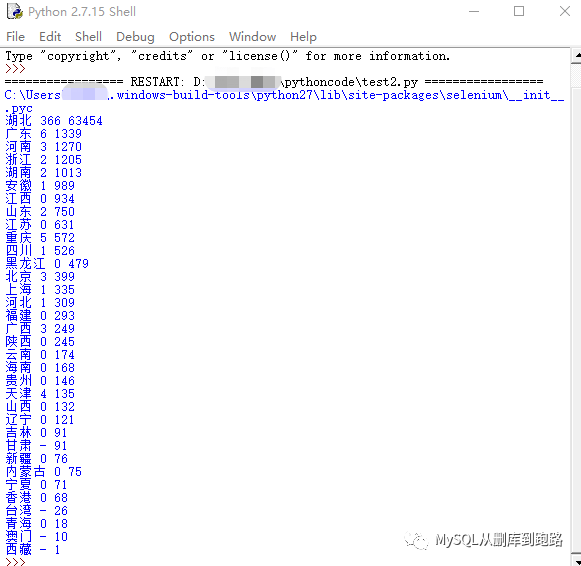
HTML解析庫BeautifulSoup
selenium例子中爬取數(shù)據(jù)后使用BeautifulSoup庫對html進(jìn)行解析,提取了感興趣的部分。如果不解析,抓取的就是一整個(gè)html數(shù)據(jù),有時(shí)也是xml數(shù)據(jù),xml數(shù)據(jù)對標(biāo)簽的解析和html是一樣的道理,兩者都是來區(qū)分?jǐn)?shù)據(jù)的。這種格式的數(shù)據(jù)結(jié)構(gòu)一個(gè)頁面一個(gè)樣子,解析起來很麻煩。BeautifulSoup提供了強(qiáng)大的解析功能,可以幫助我們省去不少麻煩。
使用之前安裝BeautifulSoup和lxml。首先代碼要引入這個(gè)庫(參考上面selenium庫代碼)
from?bs4?import?BeautifulSoup??
然后,抓取
r?=?request.get(url)??????
r.encoding='utf8'??
html=r.read()?#urlopen獲取的內(nèi)容都在html中??
mysoup=BeautifulSoup(html,?'lxml')?#html的信息都在mysoup中了???
假設(shè)我們對html中的如下部分?jǐn)?shù)據(jù)感興趣
??
????????20200214 ??
????????1 ??
????????11 ??
????????張三 ??
??????
??????
????????20200214 ??
????????4 ??
????????17 ??
????????李斯 ??
??????
首先要找到tag標(biāo)簽為的數(shù)據(jù),而這類數(shù)據(jù)不止一條,我們以兩條為例。那么需要用到beautifulsoup的find_all函數(shù),返回的結(jié)果應(yīng)該是兩個(gè)數(shù)據(jù)。當(dāng)處理每一個(gè)數(shù)據(jù)時(shí),里面的等標(biāo)簽都是唯一的,這時(shí)使用find函數(shù)。
mysoup=BeautifulSoup(html,?'lxml')????
data_list=mysoup.find_all('data')??
for?data?in?data_list:#list應(yīng)該有兩個(gè)元素??
????day?=?data.find('day').get_text()?#get_text是獲取字符串,可以用.string代替??
????id?=?data.find('id').get_text()??
????rank?=?data.find('rank').get_text()??
????name?=?data.find('name').get_text()??
????#print?name??可以print測試解析結(jié)果??
這是beautifulsoup最簡單的用法,find和find_all不僅可以按照標(biāo)簽的名字定位元素,還可以按照class,style等各種屬性,以及文本內(nèi)容text作為條件來查找你感興趣的內(nèi)容,非常強(qiáng)大。
requests庫如何抓取網(wǎng)頁的動(dòng)態(tài)加載數(shù)據(jù)
還是以新冠肺炎的疫情統(tǒng)計(jì)網(wǎng)頁為例。本文開頭requests例子最后打印的結(jié)果里面只有標(biāo)題、欄目名稱之類的,沒有累計(jì)確診、累計(jì)死亡等等的數(shù)據(jù)。因?yàn)檫@個(gè)頁面的數(shù)據(jù)是動(dòng)態(tài)加載上去的,不是靜態(tài)的html頁面。需要按照我上面寫的步驟來獲取數(shù)據(jù),關(guān)鍵是獲得URL和對應(yīng)參數(shù)formdata。下面以火狐瀏覽器講講如何獲得這兩個(gè)數(shù)據(jù)。
肺炎頁面右鍵,出現(xiàn)的菜單選擇檢查元素。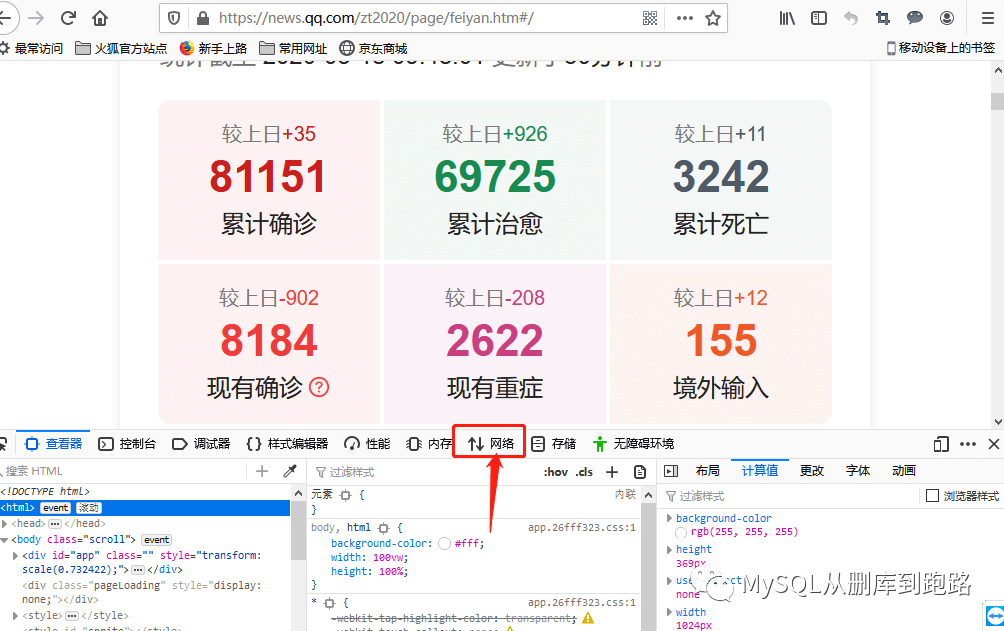
點(diǎn)擊上圖紅色箭頭網(wǎng)絡(luò)選項(xiàng),然后刷新頁面。如下,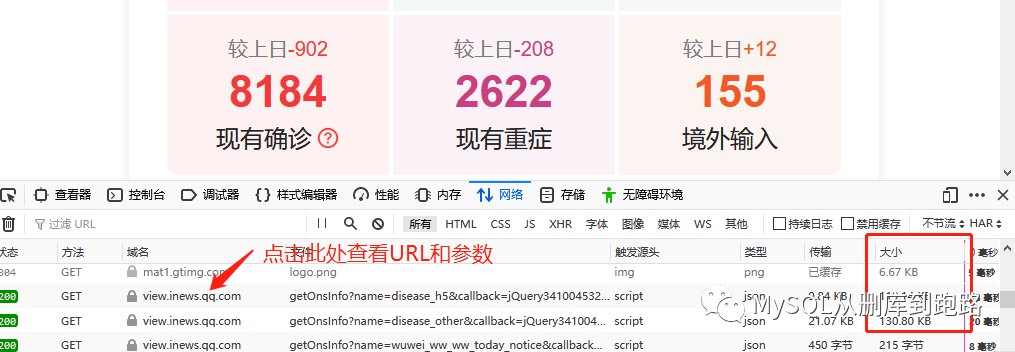
這里會(huì)出現(xiàn)很多網(wǎng)絡(luò)傳輸記錄,觀察最右側(cè)紅框“大小”那列,這列表示這個(gè)http請求傳輸?shù)臄?shù)據(jù)量大小,動(dòng)態(tài)加載的數(shù)據(jù)一般數(shù)據(jù)量會(huì)比其它頁面元素的傳輸大,119kb相比其它按字節(jié)計(jì)算的算是很大的數(shù)據(jù)了,當(dāng)然網(wǎng)頁的裝飾圖片有的也很大,這個(gè)需要按照文件類型那列來甄別。
url帶參數(shù)
然后點(diǎn)擊域名列對應(yīng)那行,如下
可以在消息頭中看見請求網(wǎng)址,url的尾部問號后面已經(jīng)把參數(shù)寫上了。
圖中url解釋,name是disease_h5,callback是頁面回調(diào)函數(shù),我們不需要有回調(diào)動(dòng)作,所以設(shè)置為空,_對應(yīng)的是時(shí)間戳(Python很容易獲得時(shí)間戳的),因?yàn)椴樵兎窝谆颊邤?shù)量和時(shí)間是緊密相關(guān)的。
我們?nèi)绻褂脦?shù)的URL,那么就用
url='網(wǎng)址/g2/getOnsInfo?name=disease_h5&callback=&_=%d'%int(stamp*1000)?????
requests.get(url)???
url和參數(shù)分離
點(diǎn)擊參數(shù)可以看見url對應(yīng)的參數(shù)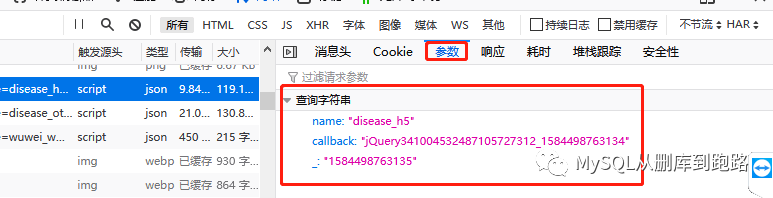
如果使用參數(shù)和url分離的形式那么
那么就這樣
url="網(wǎng)址/g2/getOnsInfo"??
formdata?=?{'name':?'disease_h5',???
'callback':?'',???
'_':?當(dāng)前時(shí)間戳????
}????
requests.get(url,?formdata)??
找url和參數(shù)需要耐心分析,才能正確甄別url和參數(shù)的含義,進(jìn)行正確的編程實(shí)現(xiàn)。參數(shù)是否可以空,是否可以硬編碼寫死,是否有特殊要求,比較依賴經(jīng)驗(yàn)。
總結(jié)
學(xué)完本文,閱讀爬蟲代碼就很容易了,所有代碼都是為了成功get到url做的準(zhǔn)備以及抓到數(shù)據(jù)之后的解析而已。
有的url很簡單,返回一個(gè).dat文件,里面直接就是json格式的數(shù)據(jù)。有的需要設(shè)置大量參數(shù),才能獲得,而且獲得的是html格式的,需要解析才能提取數(shù)據(jù)。
爬到的數(shù)據(jù)可以存入數(shù)據(jù)庫,寫入文件,也可以現(xiàn)抓現(xiàn)展示不存儲。

往期推薦


以上三位小伙伴,快來聯(lián)系小編領(lǐng)取小小紅包一份哦!小編微信:Mayyy530
