
目標(biāo)檢測(cè)yolo--2016
從五個(gè)方面解讀CVPR2016 目標(biāo)檢測(cè)論文YOLO: Unified, Real-Time Object Detection
創(chuàng)新
核心思想
效果
改進(jìn)
實(shí)踐
1. 創(chuàng)新
YOLO將物體檢測(cè)作為回歸問(wèn)題求解。基于一個(gè)單獨(dú)的end-to-end網(wǎng)絡(luò),完成從原始圖像的輸入到物體位置和類別的輸出。從網(wǎng)絡(luò)設(shè)計(jì)上,YOLO與rcnn、fast rcnn及faster rcnn的區(qū)別如下:
[1] YOLO訓(xùn)練和檢測(cè)均是在一個(gè)單獨(dú)網(wǎng)絡(luò)中進(jìn)行。YOLO沒有顯示地求取region proposal的過(guò)程。而rcnn/fast rcnn 采用分離的模塊(獨(dú)立于網(wǎng)絡(luò)之外的selective search方法)求取候選框(可能會(huì)包含物體的矩形區(qū)域),訓(xùn)練過(guò)程因此也是分成多個(gè)模塊進(jìn)行。Faster rcnn使用RPN(region proposal network)卷積網(wǎng)絡(luò)替代rcnn/fast rcnn的selective
search模塊,將RPN集成到fast rcnn檢測(cè)網(wǎng)絡(luò)中,得到一個(gè)統(tǒng)一的檢測(cè)網(wǎng)絡(luò)。盡管RPN與fast rcnn共享卷積層,但是在模型訓(xùn)練過(guò)程中,需要反復(fù)訓(xùn)練RPN網(wǎng)絡(luò)和fast rcnn網(wǎng)絡(luò)(注意這兩個(gè)網(wǎng)絡(luò)核心卷積層是參數(shù)共享的)。
[2]
YOLO將物體檢測(cè)作為一個(gè)回歸問(wèn)題進(jìn)行求解,輸入圖像經(jīng)過(guò)一次inference,便能得到圖像中所有物體的位置和其所屬類別及相應(yīng)的置信概率。而rcnn/fast rcnn/faster rcnn將檢測(cè)結(jié)果分為兩部分求解:物體類別(分類問(wèn)題),物體位置即bounding box(回歸問(wèn)題)。
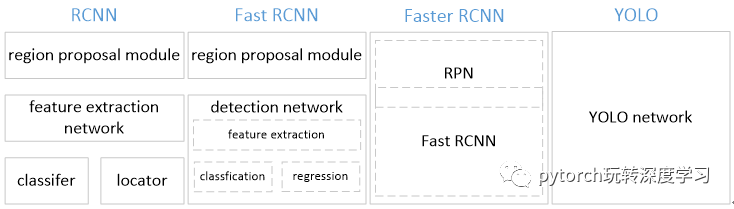
2. 核心思想
2.1 網(wǎng)絡(luò)定義
YOLO檢測(cè)網(wǎng)絡(luò)包括24個(gè)卷積層和2個(gè)全連接層,如下圖所示。

其中,卷積層用來(lái)提取圖像特征,全連接層用來(lái)預(yù)測(cè)圖像位置和類別概率值。
YOLO網(wǎng)絡(luò)借鑒了GoogLeNet分類網(wǎng)絡(luò)結(jié)構(gòu)。不同的是,YOLO未使用inception
module,而是使用1x1卷積層(此處1x1卷積層的存在是為了跨通道信息整合)+3x3卷積層簡(jiǎn)單替代。
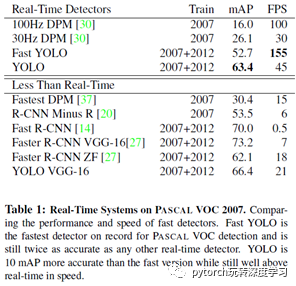
YOLO論文中,作者還給出一個(gè)更輕快的檢測(cè)網(wǎng)絡(luò)fast YOLO,它只有9個(gè)卷積層和2個(gè)全連接層。使用titan x GPU,fast YOLO可以達(dá)到155fps的檢測(cè)速度,但是mAP值也從YOLO的63.4%降到了52.7%,但卻仍然遠(yuǎn)高于以往的實(shí)時(shí)物體檢測(cè)方法(DPM)的mAP值。
2.2 輸出representation定義
本部分給出YOLO全連接輸出層的定義。
YOLO將輸入圖像分成SxS個(gè)格子,每個(gè)格子負(fù)責(zé)檢測(cè)‘落入’該格子的物體。若某個(gè)物體的中心位置的坐標(biāo)落入到某個(gè)格子,那么這個(gè)格子就負(fù)責(zé)檢測(cè)出這個(gè)物體。如下圖所示,圖中物體狗的中心點(diǎn)(紅色原點(diǎn))落入第5行、第2列的格子內(nèi),所以這個(gè)格子負(fù)責(zé)預(yù)測(cè)圖像中的物體狗。

每個(gè)格子輸出B個(gè)bounding box(包含物體的矩形區(qū)域)信息,以及C個(gè)物體屬于某種類別的概率信息。
Bounding box信息包含5個(gè)數(shù)據(jù)值,分別是x,y,w,h,和confidence。其中x,y是指當(dāng)前格子預(yù)測(cè)得到的物體的bounding box的中心位置的坐標(biāo)。w,h是bounding box的寬度和高度。注意:實(shí)際訓(xùn)練過(guò)程中,w和h的值使用圖像的寬度和高度進(jìn)行歸一化到[0,1]區(qū)間內(nèi);x,y是bounding box中心位置相對(duì)于當(dāng)前格子位置的偏移值,并且被歸一化到[0,1]。
confidence反映當(dāng)前bounding box是否包含物體以及物體位置的準(zhǔn)確性,計(jì)算方式如下:
confidence = P(object)
* IOU, 其中,若bounding box包含物體,則P(object) = 1;否則P(object) = 0. IOU(intersection over union)為預(yù)測(cè)bounding
box與物體真實(shí)區(qū)域的交集面積(以像素為單位,用真實(shí)區(qū)域的像素面積歸一化到[0,1]區(qū)間)。
因此,YOLO網(wǎng)絡(luò)最終的全連接層的輸出維度是 S*S*(B*5 + C)。YOLO論文中,作者訓(xùn)練采用的輸入圖像分辨率是448x448,S=7,B=2;采用VOC 20類標(biāo)注物體作為訓(xùn)練數(shù)據(jù),C=20。因此輸出向量為7*7*(20 + 2*5)=1470維。作者開源出的YOLO代碼中,全連接層輸出特征向量各維度對(duì)應(yīng)內(nèi)容如下:

注:
*由于輸出層為全連接層,因此在檢測(cè)時(shí),YOLO訓(xùn)練模型只支持與訓(xùn)練圖像相同的輸入分辨率。
*雖然每個(gè)格子可以預(yù)測(cè)B個(gè)bounding box,但是最終只選擇只選擇IOU最高的bounding box作為物體檢測(cè)輸出,即每個(gè)格子最多只預(yù)測(cè)出一個(gè)物體。當(dāng)物體占畫面比例較小,如圖像中包含畜群或鳥群時(shí),每個(gè)格子包含多個(gè)物體,但卻只能檢測(cè)出其中一個(gè)。這是YOLO方法的一個(gè)缺陷。
2.3 Loss函數(shù)定義
YOLO使用均方和誤差作為loss函數(shù)來(lái)優(yōu)化模型參數(shù),即網(wǎng)絡(luò)輸出的S*S*(B*5 + C)維向量與真實(shí)圖像的對(duì)應(yīng)S*S*(B*5 + C)維向量的均方和誤差。如下式所示。其中, 、iouError和classError分別代表預(yù)測(cè)數(shù)據(jù)與標(biāo)定數(shù)據(jù)之間的坐標(biāo)誤差、IOU誤差和分類誤差。
、iouError和classError分別代表預(yù)測(cè)數(shù)據(jù)與標(biāo)定數(shù)據(jù)之間的坐標(biāo)誤差、IOU誤差和分類誤差。
 【1】
【1】
YOLO對(duì)上式loss的計(jì)算進(jìn)行了如下修正。
[1] 位置相關(guān)誤差(坐標(biāo)、IOU)與分類誤差對(duì)網(wǎng)絡(luò)loss的貢獻(xiàn)值是不同的,因此YOLO在計(jì)算loss時(shí),使用 修正。
修正。
[2] 在計(jì)算IOU誤差時(shí),包含物體的格子與不包含物體的格子,二者的IOU誤差對(duì)網(wǎng)絡(luò)loss的貢獻(xiàn)值是不同的。若采用相同的權(quán)值,那么不包含物體的格子的confidence值近似為0,變相放大了包含物體的格子的confidence誤差在計(jì)算網(wǎng)絡(luò)參數(shù)梯度時(shí)的影響。為解決這個(gè)問(wèn)題,YOLO 使用 修正
修正 。(注此處的‘包含’是指存在一個(gè)物體,它的中心坐標(biāo)落入到格子內(nèi))。
。(注此處的‘包含’是指存在一個(gè)物體,它的中心坐標(biāo)落入到格子內(nèi))。
[3]
對(duì)于相等的誤差值,大物體誤差對(duì)檢測(cè)的影響應(yīng)小于小物體誤差對(duì)檢測(cè)的影響。這是因?yàn)椋嗤奈恢闷钫即笪矬w的比例遠(yuǎn)小于同等偏差占小物體的比例。YOLO將物體大小的信息項(xiàng)(w和h)進(jìn)行求平方根來(lái)改進(jìn)這個(gè)問(wèn)題。(注:這個(gè)方法并不能完全解決這個(gè)問(wèn)題)。
綜上,YOLO在訓(xùn)練過(guò)程中Loss計(jì)算如下式所示:

其中, 為網(wǎng)絡(luò)預(yù)測(cè)值,帽 為標(biāo)注值。
為網(wǎng)絡(luò)預(yù)測(cè)值,帽 為標(biāo)注值。 表示物體落入格子i中,
表示物體落入格子i中, 和
和 分別表示物體落入與未落入格子i的第j個(gè)bounding box內(nèi)。
分別表示物體落入與未落入格子i的第j個(gè)bounding box內(nèi)。
注:
*
YOLO方法模型訓(xùn)練依賴于物體識(shí)別標(biāo)注數(shù)據(jù),因此,對(duì)于非常規(guī)的物體形狀或比例,YOLO的檢測(cè)效果并不理想。
*
YOLO采用了多個(gè)下采樣層,網(wǎng)絡(luò)學(xué)到的物體特征并不精細(xì),因此也會(huì)影響檢測(cè)效果。
* YOLO loss函數(shù)中,大物體IOU誤差和小物體IOU誤差對(duì)網(wǎng)絡(luò)訓(xùn)練中l(wèi)oss貢獻(xiàn)值接近(雖然采用求平方根方式,但沒有根本解決問(wèn)題)。因此,對(duì)于小物體,小的IOU誤差也會(huì)對(duì)網(wǎng)絡(luò)優(yōu)化過(guò)程造成很大的影響,從而降低了物體檢測(cè)的定位準(zhǔn)確性。
2.4 訓(xùn)練
YOLO模型訓(xùn)練分為兩步:
1)預(yù)訓(xùn)練。使用ImageNet
1000類數(shù)據(jù)訓(xùn)練YOLO網(wǎng)絡(luò)的前20個(gè)卷積層+1個(gè)average池化層+1個(gè)全連接層。訓(xùn)練圖像分辨率resize到224x224。
2)用步驟1)得到的前20個(gè)卷積層網(wǎng)絡(luò)參數(shù)來(lái)初始化YOLO模型前20個(gè)卷積層的網(wǎng)絡(luò)參數(shù),然后用VOC 20類標(biāo)注數(shù)據(jù)進(jìn)行YOLO模型訓(xùn)練。為提高圖像精度,在訓(xùn)練檢測(cè)模型時(shí),將輸入圖像分辨率resize到448x448。
(訓(xùn)練過(guò)程中的參數(shù)設(shè)置,請(qǐng)參考原始論文)
3. 效果
下表給出了YOLO與其他物體檢測(cè)方法,在檢測(cè)速度和準(zhǔn)確性方面的比較結(jié)果(使用VOC 2007數(shù)據(jù)集)。
論文中,作者還給出了YOLO與Fast RCNN在各方面的識(shí)別誤差比例,如下圖。YOLO對(duì)背景內(nèi)容的誤判率(4.75%)比f(wàn)ast rcnn的誤判率(13.6%)低很多。但是YOLO的定位準(zhǔn)確率較差,占總誤差比例的19.0%,而fast rcnn僅為8.6%。

綜上,YOLO具有如下優(yōu)點(diǎn):
快。YOLO將物體檢測(cè)作為回歸問(wèn)題進(jìn)行求解,整個(gè)檢測(cè)網(wǎng)絡(luò)pipeline簡(jiǎn)單。在titan x GPU上,在保證檢測(cè)準(zhǔn)確率的前提下(63.4% mAP,VOC 2007 test set),可以達(dá)到45fps的檢測(cè)速度。
背景誤檢率低。YOLO在訓(xùn)練和推理過(guò)程中能‘看到’整張圖像的整體信息,而基于region proposal的物體檢測(cè)方法(如rcnn/fast rcnn),在檢測(cè)過(guò)程中,只‘看到’候選框內(nèi)的局部圖像信息。因此,若當(dāng)圖像背景(非物體)中的部分?jǐn)?shù)據(jù)被包含在候選框中送入檢測(cè)網(wǎng)絡(luò)進(jìn)行檢測(cè)時(shí),容易被誤檢測(cè)成物體。測(cè)試證明,YOLO對(duì)于背景圖像的誤檢率低于fast rcnn誤檢率的一半。
通用性強(qiáng)。YOLO對(duì)于藝術(shù)類作品中的物體檢測(cè)同樣適用。它對(duì)非自然圖像物體的檢測(cè)率遠(yuǎn)遠(yuǎn)高于DPM和RCNN系列檢測(cè)方法。
但相比RCNN系列物體檢測(cè)方法,YOLO具有以下缺點(diǎn):
識(shí)別物體位置精準(zhǔn)性差。
召回率低。
4. 改進(jìn)
為提高物體定位精準(zhǔn)性和召回率,YOLO作者提出了YOLO9000,提高訓(xùn)練圖像的分辨率,引入了faster rcnn中anchor box的思想,對(duì)各網(wǎng)絡(luò)結(jié)構(gòu)及各層的設(shè)計(jì)進(jìn)行了改進(jìn),輸出層使用卷積層替代YOLO的全連接層,聯(lián)合使用coco物體檢測(cè)標(biāo)注數(shù)據(jù)和imagenet物體分類標(biāo)注數(shù)據(jù)訓(xùn)練物體檢測(cè)模型。相比YOLO,YOLO9000在識(shí)別種類、精度、速度、和定位準(zhǔn)確性等方面都有大大提升。(yolo9000詳解有空給出)
5. 實(shí)踐
使用YOLO訓(xùn)練自己的物體識(shí)別模型也非常方便,只需要將配置文件中的20類,更改為自己要識(shí)別的物體種類個(gè)數(shù)即可。
訓(xùn)練時(shí),建議使用YOLO提供的檢測(cè)模型(使用VOC 20類標(biāo)注物體訓(xùn)練得到)去除最后的全連接層初始化網(wǎng)絡(luò)。