
SSD目標(biāo)檢測(cè)
點(diǎn)擊上方“小白學(xué)視覺(jué)”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)
本文來(lái)自自知乎:https://zhuanlan.zhihu.com/p/31427288
如有侵權(quán),請(qǐng)聯(lián)系刪除
作者 | 白裳
轉(zhuǎn)載 |??計(jì)算機(jī)視覺(jué)CV
SSD,全稱Single Shot MultiBox Detector,是Wei Liu在ECCV 2016上提出的一種目標(biāo)檢測(cè)算法,截至目前是主要的檢測(cè)框架之一,相比Faster RCNN有明顯的速度優(yōu)勢(shì),相比YOLO又有明顯的mAP優(yōu)勢(shì)(不過(guò)已經(jīng)被CVPR 2017的YOLO9000超越)。

SSD具有如下主要特點(diǎn):
從YOLO中繼承了將detection轉(zhuǎn)化為regression的思路,一次完成目標(biāo)定位與分類 基于Faster RCNN中的Anchor,提出了相似的Prior box; 加入基于特征金字塔(Pyramidal Feature Hierarchy)的檢測(cè)方式,即在不同感受野的feature map上預(yù)測(cè)目標(biāo)
本文接下來(lái)都以SSD 300為例進(jìn)行分析。
SSD300網(wǎng)絡(luò)結(jié)構(gòu)
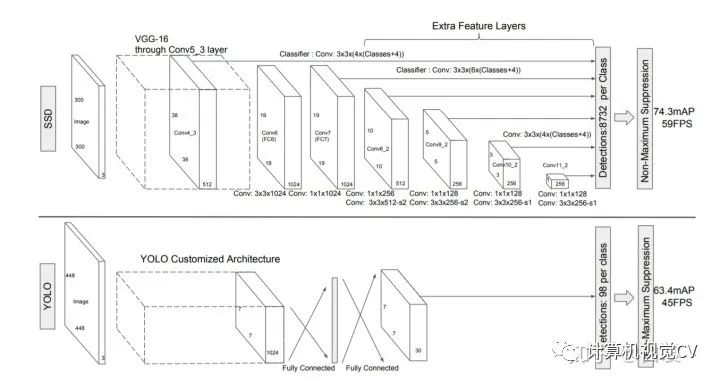
上圖2是原論文中的SSD300與YOLO網(wǎng)絡(luò)結(jié)構(gòu)圖。位什么要把SSD與YOLO對(duì)比呢?因?yàn)榻刂沟侥壳澳繕?biāo)檢測(cè)分為了2種主流框架:
Two stages:以Faster RCNN為代表,即RPN網(wǎng)絡(luò)先生成proposals目標(biāo)定位,再對(duì)proposals進(jìn)行classification+bounding box regression完成目標(biāo)分類。 Single shot:以YOLO/SSD為代表,一次性完成classification+bounding box regression。
那么來(lái)看同為Single shot方式的SSD/YOLO區(qū)別:
YOLO在卷積層后接全連接層,即檢測(cè)時(shí)只利用了最高層Feature maps(包括Faster RCNN也是如此) SSD采用金字塔結(jié)構(gòu),即利用了conv4-3/conv-7/conv6-2/conv7-2/conv8_2/conv9_2這些大小不同的feature maps,在多個(gè)feature maps上同時(shí)進(jìn)行softmax分類和位置回歸 SSD還加入了Prior box
對(duì)比如圖3。

Prior Box
在SSD300中引入了Prior Box,實(shí)際上與Faster RCNN Anchor非常類似,就是一些目標(biāo)的預(yù)選框,后續(xù)通過(guò)classification+bounding box regression獲得真實(shí)目標(biāo)的位置。
SSD按照如下規(guī)則生成prior box:
以feature map上每個(gè)點(diǎn)的中點(diǎn)為中心,生成一些列同心的prior box 正方形prior box最小邊長(zhǎng)為和最大邊長(zhǎng)為:


每在prototxt設(shè)置一個(gè)aspect ratio,會(huì)生成2個(gè)長(zhǎng)方形,長(zhǎng)寬為:


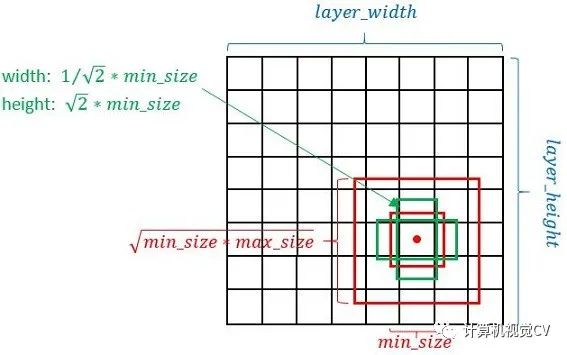
而每個(gè)feature map對(duì)應(yīng)prior box的min_size和max_size由以下公式?jīng)Q定:

公式中的 是指進(jìn)行預(yù)測(cè)時(shí)使用feature map的數(shù)量,如SSD300使用conv4-3等6個(gè)feature maps進(jìn)行預(yù)測(cè),所以
是指進(jìn)行預(yù)測(cè)時(shí)使用feature map的數(shù)量,如SSD300使用conv4-3等6個(gè)feature maps進(jìn)行預(yù)測(cè),所以 。同時(shí)原文設(shè)定
。同時(shí)原文設(shè)定 ,
, 。
。
那么:
對(duì)于conv4-3:  ,
, ,
,
對(duì)于conv-7:  ,
, ,
,
....
顯然可以用上述公式推導(dǎo)出每個(gè)feature maps使用的Prior Box size。但是在SSD300中prior box設(shè)置并不能完全和上述公式對(duì)應(yīng):
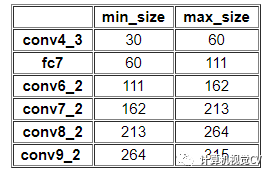
不過(guò)依然可以看出:SSD使用感受野小的feature map檢測(cè)小目標(biāo),使用感受野大的feature map檢測(cè)更大目標(biāo)。
更具體一點(diǎn),來(lái)看SSD300在conv4_3層的Prior Box設(shè)置conv4_3生成prior box的conv4_3_norm_priorbox層prototxt定義如下,可以清晰的看到 和
和 以及
以及 等值。
等值。
layer {
name: "conv4_3_norm_mbox_priorbox"
type: "PriorBox"
bottom: "conv4_3_norm"
bottom: "data"
top: "conv4_3_norm_mbox_priorbox"
prior_box_param {
min_size: 30.0
max_size: 60.0
aspect_ratio: 2
flip: true
clip: false
variance: 0.1
variance: 0.1
variance: 0.2
variance: 0.2
step: 8
offset: 0.5
}
}
知道了priorbox如何產(chǎn)生,接下來(lái)分析prior box如何使用。這里還是以conv4_3分析。
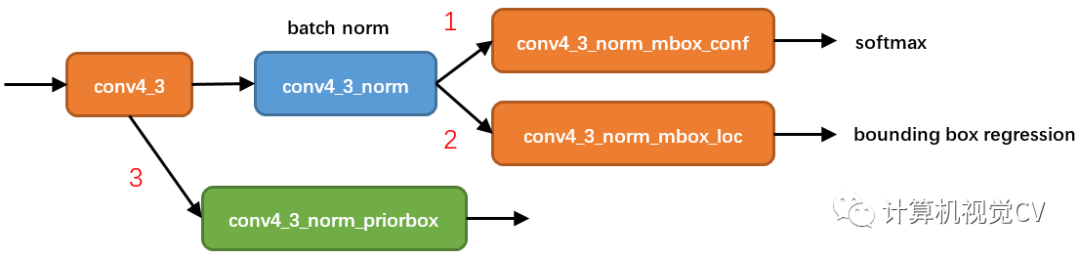
從圖5可以看到,在conv4_3網(wǎng)絡(luò)分為了3條線路:
經(jīng)過(guò)一次batch norm+一次卷積后,生成了**[1, num_class*num_priorbox, layer_height, layer_width]**大小的feature用于softmax分類目標(biāo)和非目標(biāo)(其中num_class是目標(biāo)類別,SSD300中num_class = 21,即20個(gè)類別+1個(gè)背景) 經(jīng)過(guò)一次batch norm+一次卷積后,生成了**[1, 4*num_priorbox, layer_height, layer_width]**大小的feature用于bounding box regression(即每個(gè)點(diǎn)一組[dxmin,dymin,dxmax,dymax],參考Faster R-CNN 2.5節(jié)) 生成了**[1, 2, 4*num_priorbox*layer_height*layer_width]**大小的prior box blob,其中2個(gè)channel分別存儲(chǔ)prior box的4個(gè)點(diǎn)坐標(biāo)(x1, y1, x2, y2)和對(duì)應(yīng)的4個(gè)參數(shù)variance
后續(xù)通過(guò)softmax分類判定Prior box是否包含目標(biāo),然后再通過(guò)bounding box regression即可可獲取目標(biāo)的精確位置,熟悉Faster RCNN的讀者應(yīng)該對(duì)上述過(guò)程應(yīng)該并不陌生。其實(shí)pribox box的與Faster RCNN中的anchor非常類似,都是目標(biāo)的預(yù)設(shè)框,沒(méi)有本質(zhì)的差異。區(qū)別是每個(gè)位置的prior box一般是4~6個(gè),少于Faster RCNN默認(rèn)的9個(gè)anchor;同時(shí)prior box是設(shè)置在不同尺度的feature maps上的,而且大小不同。
還有一個(gè)細(xì)節(jié)就是上面prototxt中的4個(gè)variance,這實(shí)際上是一種bounding regression中的權(quán)重。在圖4線路(2)中,網(wǎng)絡(luò)輸出[dxmin,dymin,dxmax,dymax],即對(duì)應(yīng)下面代碼中bbox;然后利用如下方法進(jìn)行針對(duì)prior box的位置回歸:
decode_bbox->set_xmin(
prior_bbox.xmin() + prior_variance[0] * bbox.xmin() * prior_width);
decode_bbox->set_ymin(
prior_bbox.ymin() + prior_variance[1] * bbox.ymin() * prior_height);
decode_bbox->set_xmax(
prior_bbox.xmax() + prior_variance[2] * bbox.xmax() * prior_width);
decode_bbox->set_ymax(
prior_bbox.ymax() + prior_variance[3] * bbox.ymax() * prior_height);
上述代碼可以在SSD box_utils.cpp的void DecodeBBox()函數(shù)見(jiàn)到。
SSD的數(shù)據(jù)流
對(duì)于新學(xué)習(xí)SSD的人,肯定有一個(gè)很大的困惑,就是這么多feature maps和Prior Box,如何組合在一起進(jìn)行forwards/backwards。本節(jié)專門介紹SSD的數(shù)據(jù)流動(dòng)方式,也許有點(diǎn)難。但是只有了解SSD的數(shù)據(jù)流動(dòng)方式才能真的理解。
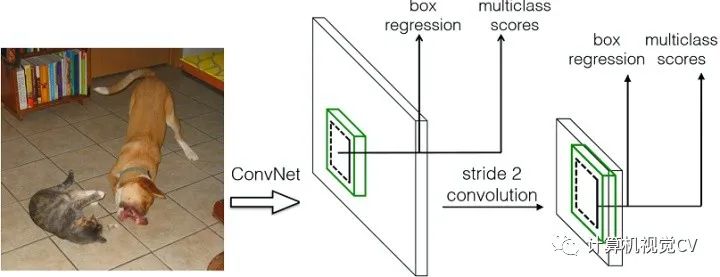
上一節(jié)以conv4_3 feature map分析了如何檢測(cè)到目標(biāo)的真實(shí)位置,但是SSD 300是使用包括conv4_3在內(nèi)的共計(jì)6個(gè)feature maps一同檢測(cè)出最終目標(biāo)的。在網(wǎng)絡(luò)運(yùn)行的時(shí)候顯然不能像圖6一樣:一個(gè)feature map單獨(dú)計(jì)算一次multiclass softmax socre+box regression(雖然原理如此,但是不能如此實(shí)現(xiàn))。
那么多個(gè)feature maps如何協(xié)同工作?這時(shí)候就要用到Permute,F(xiàn)latten和Concat這3種層了。其中conv4_3_norm_conf_perm的prototxt定義如下:
layer {
name: "conv4_3_norm_mbox_conf_perm"
type: "Permute"
bottom: "conv4_3_norm_mbox_conf"
top: "conv4_3_norm_mbox_conf_perm"
permute_param {
order: 0
order: 2
order: 3
order: 1
}
}
Permute是SSD中自帶的層,上面conv4_3_norm_mbox_conf_perm的的定義。Permute相當(dāng)于交換caffe blob中的數(shù)據(jù)維度。在正常情況下caffe blob的順序?yàn)椋?/p>
bottom blob = [batch_num, channel, height, width]
經(jīng)過(guò)conv4_3_norm_mbox_conf_perm后的caffe blob為:
top blob = [batch_num, height, width, channel]
而Flattlen和Concat層都是caffe自帶層。
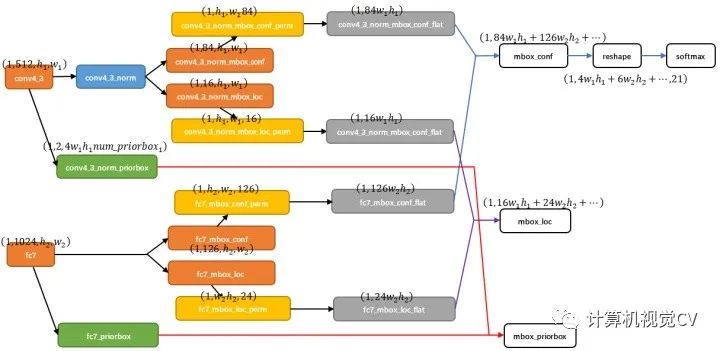
圖7 SSD中部分層caffe blob shape變化
那么接下來(lái)以conv4_3和fc7為例分析SSD是如何將不同size的feature map組合在一起進(jìn)行prediction。圖7展示了conv4_3和fc7合并在一起的過(guò)程中caffe blob shape變化(其他層類似,考慮到圖片大小沒(méi)有畫(huà)出來(lái),請(qǐng)腦補(bǔ))。
對(duì)于conv4_3 feature map,conv4_3_norm_priorbox(priorbox層)設(shè)置了每個(gè)點(diǎn)共有4個(gè)prior box。由于SSD 300共有21個(gè)分類,所以conv4_3_norm_mbox_conf的channel值為num_priorbox * num_class = 4 * 21 = 84;而每個(gè)prior box都要回歸出4個(gè)位置變換量,所以conv4_3_norm_mbox_loc的caffe blob channel值為4 * 4 = 16。 fc7每個(gè)點(diǎn)有6個(gè)prior box,其他feature map同理。 經(jīng)過(guò)一系列圖7展示的caffe blob shape變化后,最后拼接成mbox_conf和mbox_loc。而mbox_conf后接reshape,再進(jìn)行softmax(為何在softmax前進(jìn)行reshape,F(xiàn)aster RCNN有提及)。 最后這些值輸出detection_out_layer,獲得檢測(cè)結(jié)果
可以看到,SSD一次判斷priorbox到底是背景 or 是20種目標(biāo)類別之一,相當(dāng)于將Faster R-CNN的RPN與后續(xù)proposal再分類進(jìn)行了整合。
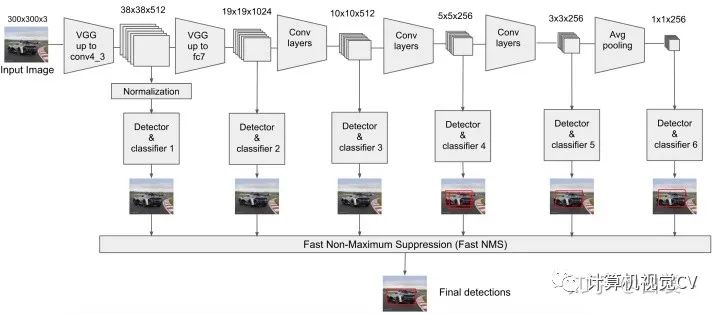
SSD網(wǎng)絡(luò)結(jié)構(gòu)優(yōu)劣分析
SSD算法的優(yōu)點(diǎn)應(yīng)該很明顯:運(yùn)行速度可以和YOLO媲美,檢測(cè)精度可以和Faster RCNN媲美。除此之外,還有一些雞毛蒜皮的優(yōu)點(diǎn),不解釋了。這里談?wù)勅秉c(diǎn):
需要人工設(shè)置prior box的min_size,max_size和aspect_ratio值。網(wǎng)絡(luò)中prior box的基礎(chǔ)大小和形狀不能直接通過(guò)學(xué)習(xí)獲得,而是需要手工設(shè)置。而網(wǎng)絡(luò)中每一層feature使用的prior box大小和形狀恰好都不一樣,導(dǎo)致調(diào)試過(guò)程非常依賴經(jīng)驗(yàn)。 雖然采用了pyramdial feature hierarchy的思路,但是對(duì)小目標(biāo)的recall依然一般,并沒(méi)有達(dá)到碾壓Faster RCNN的級(jí)別。作者認(rèn)為,這是由于SSD使用conv4_3低級(jí)feature去檢測(cè)小目標(biāo),而低級(jí)特征卷積層數(shù)少,存在特征提取不充分的問(wèn)題。
SSD訓(xùn)練過(guò)程
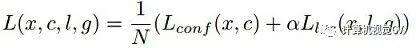
對(duì)于SSD,雖然paper中指出采用了所謂的“multibox loss”,但是依然可以清晰看到SSD loss分為了confidence loss和location loss(bouding box regression loss)兩部分,其中N是match到GT(Ground Truth)的prior box數(shù)量;而α參數(shù)用于調(diào)整confidence loss和location loss之間的比例,默認(rèn)α=1。SSD中的confidence loss是典型的softmax loss:
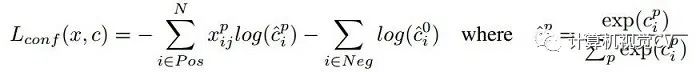
其中
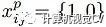
代表第i個(gè)prior box匹配到了第j個(gè)class為p類別的GT box;而location loss是典型的smooth L1 loss:
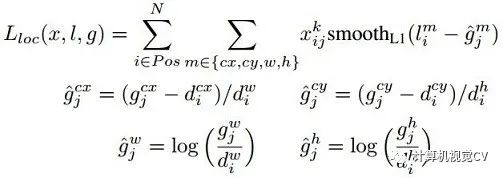
Matching strategy:
在訓(xùn)練時(shí),groundtruth boxes 與 default boxes(就是prior boxes) 按照如下方式進(jìn)行配對(duì):
首先,尋找與每一個(gè)ground truth box有最大的jaccard overlap的default box,這樣就能保證每一個(gè)groundtruth box與唯一的一個(gè)default box對(duì)應(yīng)起來(lái)(所謂的jaccard overlap就是IoU,如圖9)。 SSD之后又將剩余還沒(méi)有配對(duì)的default box與任意一個(gè)groundtruth box嘗試配對(duì),只要兩者之間的jaccard overlap大于閾值,就認(rèn)為match(SSD 300 閾值為0.5)。 顯然配對(duì)到GT的default box就是positive,沒(méi)有配對(duì)到GT的default box就是negative。
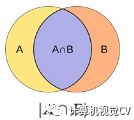
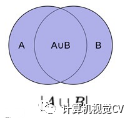

圖9 jaccard overlap
Hard negative mining:
值得注意的是,一般情況下negative default boxes數(shù)量>>positive default boxes數(shù)量,直接訓(xùn)練會(huì)導(dǎo)致網(wǎng)絡(luò)過(guò)于重視負(fù)樣本,從而loss不穩(wěn)定。所以需要采取:
所以SSD在訓(xùn)練時(shí)會(huì)依據(jù)confidience score排序default box,挑選其中confidence高的box進(jìn)行訓(xùn)練,控制 
Data augmentation:
數(shù)據(jù)增廣。即對(duì)每一張image進(jìn)行如下之一變換獲取一個(gè)patch進(jìn)行訓(xùn)練:
直接使用原始的圖像(即不進(jìn)行變換) 采樣一個(gè)patch,保證與GT之間最小的IoU為:0.1,0.3,0.5,0.7 或 0.9 完全隨機(jī)的采樣一個(gè)patch

同時(shí)在原文中還提到:
采樣的patch占原始圖像大小比例在  之間
之間采樣的patch的長(zhǎng)寬比在  之間
之間當(dāng) Ground truth box中心恰好在采樣的patch中時(shí),保留整個(gè)GT box 最后每個(gè)patch被resize到固定大小,并且以0.5的概率隨機(jī)的水平翻轉(zhuǎn)
最終以這些處理好的patches進(jìn)行訓(xùn)練。
其實(shí)Matching strategy,Hard negative mining,Data augmentation,都是為了加快網(wǎng)絡(luò)收斂而設(shè)計(jì)的。尤其是Data augmentation,翻來(lái)覆去的randomly crop,保證每一個(gè)prior box都獲得充分訓(xùn)練而已。后續(xù)有Focal loss解決這個(gè)問(wèn)題。
代碼實(shí)現(xiàn)
SSD github :https://github.com/weiliu89/caffe/tree/ssd
SSD paper :?https://arxiv.org/abs/1512.02325