
PyTorch的自動求導(dǎo)機(jī)制詳細(xì)解析,PyTorch的核心魔法
點(diǎn)擊上方“小白學(xué)視覺”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時間送達(dá)

作者:Vaibhav Kumar
編譯:ronghuaiyang
這篇文章詳細(xì)解析了PyTorch的自動求導(dǎo)機(jī)制,讓你了解PyTorch的核心魔法。

我們都同意,當(dāng)涉及到大型神經(jīng)網(wǎng)絡(luò)時,我們都不擅長微積分。通過顯式求解數(shù)學(xué)方程來計算這樣大的復(fù)合函數(shù)的梯度是不現(xiàn)實(shí)的,特別是這些曲線存在于大量的維數(shù)中,是無法理解的。
要處理14維空間中的超平面,想象一個三維空間,大聲地對自己說“14”。每個人都這么做——Geoffrey Hinton
這就是PyTorch的autograd發(fā)揮作用的地方。它抽象了復(fù)雜的數(shù)學(xué),幫助我們“神奇地”計算高維曲線的梯度,只需要幾行代碼。這篇文章試圖描述autograd的魔力。
PyTorch基礎(chǔ)
在進(jìn)一步討論之前,我們需要了解一些基本的PyTorch概念。
張量:簡單地說,它只是PyTorch中的一個n維數(shù)組。張量支持一些額外的增強(qiáng),這使它們獨(dú)一無二:除了CPU,它們可以加載或GPU更快的計算。在設(shè)置.requires_grad = True的時候,他們開始形成一個反向圖,跟蹤應(yīng)用于他們的每個操作,使用所謂的動態(tài)計算圖(DCG)計算梯度(后面會進(jìn)一步解釋)。
在早期版本的PyTorch中,使用torch.autograd.Variable類用于創(chuàng)建支持梯度計算和操作跟蹤的張量,但截至PyTorch v0.4.0,Variable類已被禁用。torch.Tensor和torch.autograd.Variable現(xiàn)在是同一個類。更準(zhǔn)確地說, torch.Tensor能夠跟蹤歷史并表現(xiàn)得像舊的Variable。
import torchimport numpy as npx = torch.randn(2, 2, requires_grad = True)# From numpyx = np.array([1., 2., 3.]) #Only Tensors of floating point dtype can require gradientsx = torch.from_numpy(x)# Now enable gradientx.requires_grad_(True)# _ above makes the change in-place (its a common pytorch thing)
注意:根據(jù)PyTorch的設(shè)計,梯度只能計算浮點(diǎn)張量,這就是為什么我創(chuàng)建了一個浮點(diǎn)類型的numpy數(shù)組,然后將它設(shè)置為啟用梯度的PyTorch張量。
Autograd:這個類是一個計算導(dǎo)數(shù)的引擎(更精確地說是雅克比向量積)。它記錄了梯度張量上所有操作的一個圖,并創(chuàng)建了一個稱為動態(tài)計算圖的非循環(huán)圖。這個圖的葉節(jié)點(diǎn)是輸入張量,根節(jié)點(diǎn)是輸出張量。梯度是通過跟蹤從根到葉的圖形,并使用鏈?zhǔn)椒▌t將每個梯度相乘來計算的。
神經(jīng)網(wǎng)絡(luò)和反向傳播
神經(jīng)網(wǎng)絡(luò)只不過是經(jīng)過精心調(diào)整(訓(xùn)練)以輸出所需結(jié)果的復(fù)合數(shù)學(xué)函數(shù)。調(diào)整或訓(xùn)練是通過一種稱為反向傳播的出色算法完成的。反向傳播用來計算相對于輸入權(quán)值的損失梯度,以便以后更新權(quán)值,最終減少損失。
在某種程度上,反向傳播只是鏈?zhǔn)椒▌t的一個花哨的名字—— Jeremy Howard
創(chuàng)建和訓(xùn)練神經(jīng)網(wǎng)絡(luò)包括以下基本步驟:
定義體系結(jié)構(gòu)
使用輸入數(shù)據(jù)在體系結(jié)構(gòu)上向前傳播
計算損失
反向傳播,計算每個權(quán)重的梯度
使用學(xué)習(xí)率更新權(quán)重
損失變化引起的輸入權(quán)值的微小變化稱為該權(quán)值的梯度,并使用反向傳播計算。然后使用梯度來更新權(quán)值,使用學(xué)習(xí)率來整體減少損失并訓(xùn)練神經(jīng)網(wǎng)絡(luò)。
這是以迭代的方式完成的。對于每個迭代,都要計算幾個梯度,并為存儲這些梯度函數(shù)構(gòu)建一個稱為計算圖的東西。PyTorch通過構(gòu)建一個動態(tài)計算圖(DCG)來實(shí)現(xiàn)這一點(diǎn)。此圖在每次迭代中從頭構(gòu)建,為梯度計算提供了最大的靈活性。例如,對于前向操作(函數(shù))Mul ,向后操作函數(shù)MulBackward被動態(tài)集成到后向圖中以計算梯度。
動態(tài)計算圖
支持梯度的張量(變量)和函數(shù)(操作)結(jié)合起來創(chuàng)建動態(tài)計算圖。數(shù)據(jù)流和應(yīng)用于數(shù)據(jù)的操作在運(yùn)行時定義,從而動態(tài)地構(gòu)造計算圖。這個圖是由底層的autograd類動態(tài)生成的。你不必在啟動訓(xùn)練之前對所有可能的路徑進(jìn)行編碼——你運(yùn)行的是你所區(qū)分的。
一個簡單的DCG用于兩個張量的乘法會是這樣的:
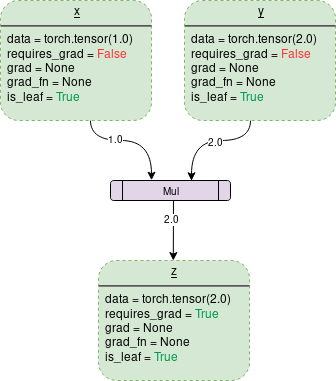
圖中的每個點(diǎn)輪廓框是一個變量,紫色矩形框是一個操作。
每個變量對象都有幾個成員,其中一些成員是:
Data:它是一個變量持有的數(shù)據(jù)。x持有一個1x1張量,其值等于1.0,而y持有2.0。z持有兩個的乘積,即2.0。
requires_grad:這個成員(如果為true)開始跟蹤所有的操作歷史,并形成一個用于梯度計算的向后圖。對于任意張量a,可以按如下方式對其進(jìn)行原地處理:a.requires_grad_(True)。
grad: grad保存梯度值。如果requires_grad 為False,它將持有一個None值。即使requires_grad 為真,它也將持有一個None值,除非從其他節(jié)點(diǎn)調(diào)用.backward()函數(shù)。例如,如果你對out關(guān)于x計算梯度,調(diào)用out.backward(),則x.grad的值為?out/?x。
grad_fn:這是用來計算梯度的向后函數(shù)。
is_leaf:如果:
它被一些函數(shù)顯式地初始化,比如
x = torch.tensor(1.0)或x = torch.randn(1, 1)(基本上是本文開頭討論的所有張量初始化方法)。它是在張量的操作之后創(chuàng)建的,所有張量都有
requires_grad = False。它是通過對某個張量調(diào)用
.detach()方法創(chuàng)建的。
在調(diào)用backward()時,只計算requires_grad和is_leaf同時為真的節(jié)點(diǎn)的梯度。
當(dāng)打開 requires_grad = True時,PyTorch將開始跟蹤操作,并在每個步驟中存儲梯度函數(shù),如下所示:
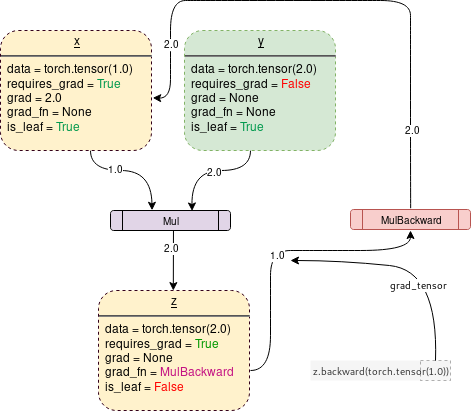
在PyTorch下生成上圖的代碼是:
Backward()函數(shù)
Backward函數(shù)實(shí)際上是通過傳遞參數(shù)(默認(rèn)情況下是1x1單位張量)來計算梯度的,它通過Backward圖一直到每個葉節(jié)點(diǎn),每個葉節(jié)點(diǎn)都可以從調(diào)用的根張量追溯到葉節(jié)點(diǎn)。然后將計算出的梯度存儲在每個葉節(jié)點(diǎn)的.grad中。請記住,在正向傳遞過程中已經(jīng)動態(tài)生成了后向圖。backward函數(shù)僅使用已生成的圖形計算梯度,并將其存儲在葉節(jié)點(diǎn)中。
讓我們分析以下代碼:
import torch# Creating the graphx = torch.tensor(1.0, requires_grad = True)z = x ** 3z.backward() #Computes the gradientprint(x.grad.data) #Prints '3' which is dz/dx
需要注意的一件重要事情是,當(dāng)調(diào)用z.backward()時,一個張量會自動傳遞為z.backward(torch.tensor(1.0))。torch.tensor(1.0)是用來終止鏈?zhǔn)椒▌t梯度乘法的外部梯度。這個外部梯度作為輸入傳遞給MulBackward函數(shù),以進(jìn)一步計算x的梯度。傳遞到.backward()中的張量的維數(shù)必須與正在計算梯度的張量的維數(shù)相同。例如,如果梯度支持張量x和y如下:
x = torch.tensor([0.0, 2.0, 8.0], requires_grad = True)y = torch.tensor([5.0 , 1.0 , 7.0], requires_grad = True)z = x * y
然后,要計算z關(guān)于x或者y的梯度,需要將一個外部梯度傳遞給z.backward()函數(shù),如下所示:
z.backward(torch.FloatTensor([1.0, 1.0, 1.0])z.backward() 會給出 RuntimeError: grad can be implicitly created only for scalar outputs
反向函數(shù)傳遞的張量就像梯度加權(quán)輸出的權(quán)值。從數(shù)學(xué)上講,這是一個向量乘以非標(biāo)量張量的雅可比矩陣(本文將進(jìn)一步討論),因此它幾乎總是一個維度的單位張量,與 backward張量相同,除非需要計算加權(quán)輸出。
tldr :向后圖是由autograd類在向前傳遞過程中自動動態(tài)創(chuàng)建的。
Backward()只是通過將其參數(shù)傳遞給已經(jīng)生成的反向圖來計算梯度。
數(shù)學(xué)—雅克比矩陣和向量
從數(shù)學(xué)上講,autograd類只是一個雅可比向量積計算引擎。雅可比矩陣是一個非常簡單的單詞,它表示兩個向量所有可能的偏導(dǎo)數(shù)。它是一個向量相對于另一個向量的梯度。
注意:在這個過程中,PyTorch從不顯式地構(gòu)造整個雅可比矩陣。直接計算JVP (Jacobian vector product)通常更簡單、更有效。
如果一個向量X = [x1, x2,…xn]通過f(X) = [f1, f2,…fn]來計算其他向量,則雅可比矩陣(J)包含以下所有偏導(dǎo)組合:
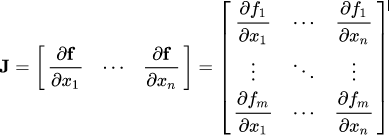
上面的矩陣表示f(X)相對于X的梯度。
假設(shè)一個啟用PyTorch梯度的張量X:
X = [x1,x2,…,xn](假設(shè)這是某個機(jī)器學(xué)習(xí)模型的權(quán)值)
X經(jīng)過一些運(yùn)算形成一個向量Y
Y = f(X) = [y1, y2,…,ym]
然后使用Y計算標(biāo)量損失l。假設(shè)向量v恰好是標(biāo)量損失l關(guān)于向量Y的梯度,如下:
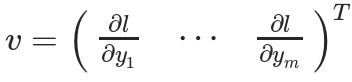
向量v稱為grad_tensor,并作為參數(shù)傳遞給backward() 函數(shù)。
為了得到損失的梯度l關(guān)于權(quán)重X的梯度,雅可比矩陣J是向量乘以向量v
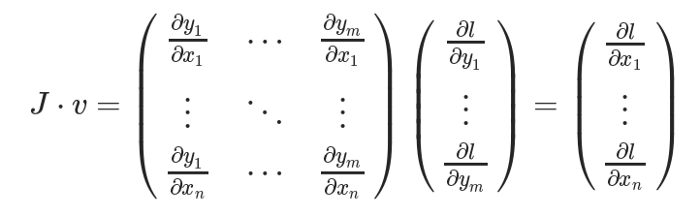
這種計算雅可比矩陣并將其與向量v相乘的方法使PyTorch能夠輕松地為非標(biāo)量輸出提供外部梯度。
好消息!
小白學(xué)視覺知識星球
開始面向外開放啦??????
下載1:OpenCV-Contrib擴(kuò)展模塊中文版教程 在「小白學(xué)視覺」公眾號后臺回復(fù):擴(kuò)展模塊中文教程,即可下載全網(wǎng)第一份OpenCV擴(kuò)展模塊教程中文版,涵蓋擴(kuò)展模塊安裝、SFM算法、立體視覺、目標(biāo)跟蹤、生物視覺、超分辨率處理等二十多章內(nèi)容。 下載2:Python視覺實(shí)戰(zhàn)項(xiàng)目52講 在「小白學(xué)視覺」公眾號后臺回復(fù):Python視覺實(shí)戰(zhàn)項(xiàng)目,即可下載包括圖像分割、口罩檢測、車道線檢測、車輛計數(shù)、添加眼線、車牌識別、字符識別、情緒檢測、文本內(nèi)容提取、面部識別等31個視覺實(shí)戰(zhàn)項(xiàng)目,助力快速學(xué)校計算機(jī)視覺。 下載3:OpenCV實(shí)戰(zhàn)項(xiàng)目20講 在「小白學(xué)視覺」公眾號后臺回復(fù):OpenCV實(shí)戰(zhàn)項(xiàng)目20講,即可下載含有20個基于OpenCV實(shí)現(xiàn)20個實(shí)戰(zhàn)項(xiàng)目,實(shí)現(xiàn)OpenCV學(xué)習(xí)進(jìn)階。 交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動駕駛、計算攝影、檢測、分割、識別、醫(yī)學(xué)影像、GAN、算法競賽等微信群(以后會逐漸細(xì)分),請掃描下面微信號加群,備注:”昵稱+學(xué)校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會根據(jù)研究方向邀請進(jìn)入相關(guān)微信群。請勿在群內(nèi)發(fā)送廣告,否則會請出群,謝謝理解~