
PyTorch學(xué)習(xí)系列教程:Tensor如何實(shí)現(xiàn)自動(dòng)求導(dǎo)
導(dǎo)讀
今天本文繼續(xù)PyTorch學(xué)習(xí)系列。雖然前幾篇推文閱讀效果不是很好(大體可能與本系列推文是新開(kāi)的一個(gè)方向有關(guān)),但自己選擇的路也要堅(jiān)持走下去啊!
前篇推文介紹了搭建一個(gè)深度學(xué)習(xí)模型的基本流程,通過(guò)若干個(gè)Epoch即完成了一個(gè)簡(jiǎn)單的手寫(xiě)數(shù)字分類(lèi)模型,效果還不錯(cuò)。在這一過(guò)程中,一個(gè)重要的細(xì)節(jié)便是模型如何學(xué)習(xí)到最優(yōu)參數(shù),答案是通過(guò)梯度下降法。實(shí)際上,梯度下降法是一類(lèi)優(yōu)化方法,是深度學(xué)習(xí)中廣泛應(yīng)用甚至可稱(chēng)得上是深度學(xué)習(xí)的基石。本篇不打算講解梯度下降法,而主要來(lái)談一談Tensor如何實(shí)現(xiàn)自動(dòng)求導(dǎo),明白這一過(guò)程方能進(jìn)一步理解各種梯度下降法的原理。
Tensor中的自動(dòng)求導(dǎo):與梯度相關(guān)的屬性,前向傳播和反向傳播
自動(dòng)求導(dǎo)探索實(shí)踐:以線性回歸為例,探索自動(dòng)求導(dǎo)過(guò)程
Tensor是PyTorch中的基礎(chǔ)數(shù)據(jù)結(jié)構(gòu),構(gòu)成了深度學(xué)習(xí)的基石,其本質(zhì)上是一個(gè)高維數(shù)組。在前序推文中,實(shí)際上提到過(guò)在創(chuàng)建一個(gè)Tensor時(shí)可以指定其是否需要梯度。那么是否指定需要梯度(requires_grad)有什么區(qū)別呢?實(shí)際上,這個(gè)參數(shù)設(shè)置True/False將直接決定該Tensor是否支持自動(dòng)求導(dǎo)并參與后續(xù)的梯度更新。具體來(lái)說(shuō),Tensor數(shù)據(jù)結(jié)構(gòu)中,與梯度直接相關(guān)的幾個(gè)重要屬性間的關(guān)系如下:
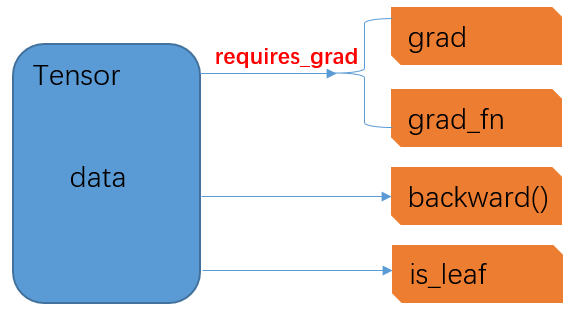
原創(chuàng)拙圖,權(quán)當(dāng)意會(huì)
在一個(gè)Tensor數(shù)據(jù)結(jié)構(gòu)中,最核心的屬性是data,這里面存儲(chǔ)了Tensor所代表的高維數(shù)組(當(dāng)然,這里雖然稱(chēng)之為高維,但實(shí)際上可以是從0維開(kāi)始的任意維度);
通過(guò)requires_grad參數(shù)控制兩個(gè)屬性,grad和grad_fn,其中前者代表當(dāng)前Tensor的梯度,后者代表經(jīng)過(guò)當(dāng)前Tensor所需求導(dǎo)的梯度函數(shù);當(dāng)requires_grad=False時(shí),grad和grad_fn都為None,且不會(huì)存在任何取值,而只有當(dāng)requires_grad=True時(shí),此時(shí)grad和grad_fn初始取值仍為None,但在后續(xù)反向傳播中可以予以賦值更新
backward(),是一個(gè)函數(shù),僅適用于標(biāo)量Tensor,即維度為0的Tensor
is_leaf:標(biāo)記了當(dāng)前Tensor在所構(gòu)建的計(jì)算圖中的位置,其中計(jì)算圖既可看做是一個(gè)有向無(wú)環(huán)圖(DAG),也可視作是一個(gè)樹(shù)結(jié)構(gòu)。當(dāng)Tensor是初始節(jié)點(diǎn)時(shí),即為葉子節(jié)點(diǎn),is_leaf=True,否則為False。
目前,Tensor支持自動(dòng)求導(dǎo)功能對(duì)數(shù)據(jù)類(lèi)型的要求是僅限于浮點(diǎn)型:"?As of now, we only support autograd for floating point? Tensor?types ( half, float, double and bfloat16) and complex?Tensor?types (cfloat, cdouble). "——引自PyTorch官方文檔
前向傳播,就是依據(jù)計(jì)算流程實(shí)現(xiàn)數(shù)據(jù)(data)的計(jì)算和計(jì)算圖的構(gòu)建:
反向傳播,反向傳播就是依據(jù)所構(gòu)建計(jì)算圖的反方向遞歸求導(dǎo)和賦值梯度:
而如果用圖形化描述這一過(guò)程,則是:
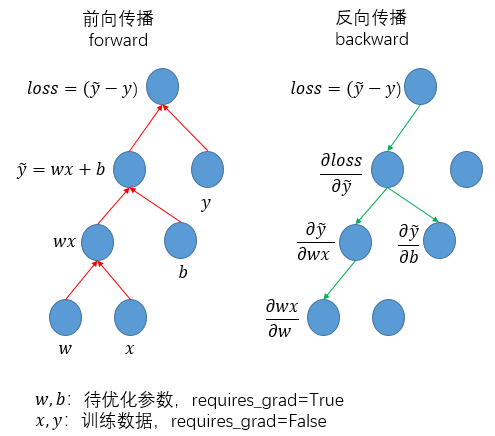
其中,在前向傳播過(guò)程中,是按照流程完成從初始輸入(一般是訓(xùn)練數(shù)據(jù)+網(wǎng)絡(luò)權(quán)重)直至最終輸出(一般是損失函數(shù))的計(jì)算過(guò)程,同步完成計(jì)算圖的構(gòu)建;而在反向傳播過(guò)程中,則是通過(guò)調(diào)用loss.backward()函數(shù),依據(jù)計(jì)算圖的相反方向遞歸完成各級(jí)求導(dǎo)(本質(zhì)上就是求導(dǎo)的鏈?zhǔn)椒▌t)。同時(shí),對(duì)于requires_grad=False的tensor,在反向傳播過(guò)程中實(shí)際不予以求導(dǎo)和更新,相應(yīng)的反向鏈條被切斷。
已進(jìn)入歷史舞臺(tái)的Variable類(lèi)型
這里,我們以一個(gè)簡(jiǎn)單的單變量線性回歸為例演示Tensor的自動(dòng)求導(dǎo)過(guò)程。
1.創(chuàng)建訓(xùn)練數(shù)據(jù)x, y和初始權(quán)重w, b
# 訓(xùn)練數(shù)據(jù),目標(biāo)擬合線性回歸 y = 2*x + 3x = torch.tensor([1., 2.])y = torch.tensor([5., 7.])# 初始權(quán)重,w=1.0, b=0.0w = torch.tensor(1.0, requires_grad=True)b = torch.tensor(0.0, requires_grad=True)
此時(shí)查看w, b和x, y的梯度相關(guān)的各項(xiàng)屬性,結(jié)果如下
# 1. 注意:x和y設(shè)置為requires_grad=Falsex.grad, x.grad_fn, x.is_leaf, y.grad, y.grad_fn, y.is_leaf# 輸出:(None, None, True, None, None, True)# 2. w和b初始梯度均為None,且二者均為葉子節(jié)點(diǎn)w.grad, w.grad_fn, w.is_leaf, b.grad, b.grad_fn, b.is_leaf# 輸出:(None, None, True, None, None, True)
2.構(gòu)建計(jì)算流程,實(shí)現(xiàn)前向傳播
# 按計(jì)算流程逐步操作,實(shí)現(xiàn)前向傳播wx = w*xwx_b = wx + bloss = (wx_b - y)loss2 = loss**2loss2_sum = sum(loss2)
查看各中間變量的梯度相關(guān)屬性:
# 1.查看是否葉子節(jié)點(diǎn)wx.is_leaf, wx_b.is_leaf, loss.is_leaf, loss2.is_leaf, loss2_sum.is_leaf# 輸出:(False, False, False, False, False)# 2.查看gradwx.grad, wx_b.grad, loss.grad, loss2.grad, loss2_sum.grad# 觸發(fā)Warning# UserWarning: The .grad attribute of a Tensor that is not a leaf Tensor is being accessed. Its .grad attribute won't be populated during autograd.backward(). If you indeed want the .grad field to be populated for a non-leaf Tensor, use .retain_grad() on the non-leaf Tensor. If you access the non-leaf Tensor by mistake, make sure you access the leaf Tensor instead. See github.com/pytorch/pytorch/pull/30531 for more informations. (Triggered internally at aten\src\ATen/core/TensorBody.h:417.)return self._grad# 輸出:(None, None, None, None, None)3.查看grad_fnwx.grad_fn, wx_b.grad_fn, loss.grad_fn, loss2.grad_fn, loss2_sum.grad_fn# 輸出:(0x23a875ee550 >,0x23a875ee8e0 >,0x23a875ee4c0 >,0x23a875ee490 >,0x23a93dde040 >)
3.對(duì)最終的loss調(diào)用backward,實(shí)現(xiàn)反向傳播
loss2_sum.backward()依次查看各中間變量和初始輸入的梯度
# 1. 中間變量(非葉子節(jié)點(diǎn))的梯度僅用于反向傳播,但不對(duì)外暴露wx.grad, wx_b.grad, loss.grad, loss2.grad, loss2_sum.grad# 輸出:(None, None, None, None, None)# 2. 檢查葉子節(jié)點(diǎn)是否獲得梯度:w, b均獲得梯度,x, y不支持求導(dǎo),仍為Nonew.grad, b.grad, x.grad, y.grad# 輸出:(tensor(-28.), tensor(-18.), None, None)
至此,即通過(guò)前向傳播的計(jì)算圖和反向傳播的梯度傳遞,完成了初始權(quán)重參數(shù)的梯度賦值過(guò)程。注意,這里w和b是網(wǎng)絡(luò)待優(yōu)化參數(shù),而一旦二者有了梯度,則可進(jìn)一步應(yīng)用梯度下降法予以更新。
而后,帶入兩組訓(xùn)練數(shù)據(jù)(x, y)=(1, 5)和(x, y)=(2, 7),并將兩組訓(xùn)練數(shù)據(jù)對(duì)應(yīng)的梯度求和:
# w的梯度:2*(1*1 + 0 - 5)*1 + 2*(1*2 + 0 - 7)*2 = -28# b的梯度:2*(1*1 + 0 - 5) + 2*(1*2 + 0 - 7) = -18
顯然,手動(dòng)計(jì)算結(jié)果與上述演示結(jié)果是一致的。
注意:在多個(gè)訓(xùn)練數(shù)據(jù)(batch_size)參與一次反向傳播時(shí),返回的參數(shù)梯度是在各訓(xùn)練數(shù)據(jù)上的求得的梯度之和。
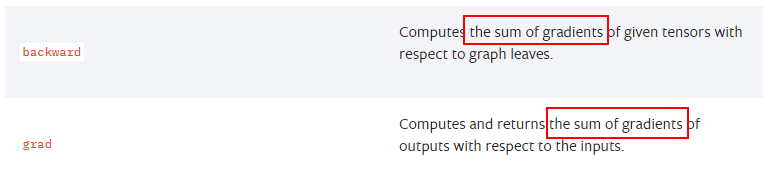
摘自PyTorch官網(wǎng)
相關(guān)閱讀: