
【Python】用 Python 來實現(xiàn)PDF 的各種操作(附網(wǎng)站和操作指導(dǎo))
導(dǎo)言
PDF 處理是日常工作中的常見需求,包括 PDF 合并、刪除、提取等。更復(fù)雜的任務(wù)如:將 PDF 轉(zhuǎn)換成 圖像。
下面通過幾個簡單的例子和一份代碼,幫助大家解決上面的需求,操作非常簡單。
在文末我會提供一份源碼和一個神奇的 PDF 處理網(wǎng)站幫你解決 PDF 處理的煩惱。
PyMuPDF 介紹
為什么使用 Python,那還不是 Python 有著強大的第三方工具包,我們想要的功能興許就有。
PyMuPDF 就是我們需要的工具,官方文檔對他的簡介是
PyMuPDF 是針對 MuPDF 的 Python 綁定,它是一個輕量級 PDF 和 XPS 查看器。MuPDF 可以訪問 PDF,XPS,OpenXPS,CBZ(漫畫書檔案),F(xiàn)B2 和 EPUB(電子書)格式的文件。這些是擴展名為.pdf,.xps,.oxps,.cbz,.fb2 或.epub 的文件(因此您可以使用 Python 開發(fā)電子書查看器)。
官方文檔:https://pymupdf.readthedocs.io/en/latest/intro.html
這里有個細節(jié)需要說明的是,Python 的第三方包一般是安裝的名稱和導(dǎo)入的名稱是一樣的,比如 numpy 的安裝和使用是
pip?install?numpy?#?numpy?包的安裝
import?numpy??#?numpy?包的導(dǎo)入
但是對于 PyMuPDF ?這個包就不一樣了,安裝和使用的包名是不一樣的,這個是歷史遺留下來的原因,知道有這回事就行。
PyMuPDF ?的安裝是這樣子的
pip?install?PyMuPDF
PyPI 源:https://pypi.org/project/PyMuPDF/
PyMuPDF ?的導(dǎo)入是這樣子的
import?fitz

PDF 各種處理
拆分與提取
拆分與提取 PDF 文件的,使用的是 clean 命令,同時該命令也可以用于文檔加密,壓縮、刪除頁面等操作,基本說明如下:
python?-m?fitz?clean?-h
usage:?fitz?clean?[-h]?[-password?PASSWORD]
????????????????[-encryption?{keep,none,rc4-40,rc4-128,aes-128,aes-256}]
????????????????[-owner?OWNER]?[-user?USER]?[-garbage?{0,1,2,3,4}]
????????????????[-compress]?[-ascii]?[-linear]?[-permission?PERMISSION]
????????????????[-sanitize]?[-pretty]?[-pages?PAGES]
????????????????input?output
--------------?optimize?PDF?or?create?sub-PDF?if?pages?given?--------------
positional?arguments:
input?????????????????PDF?filename
output????????????????output?PDF?filename
optional?arguments:
-h,?--help????????????show?this?help?message?and?exit
-password?PASSWORD????password
-encryption?{keep,none,rc4-40,rc4-128,aes-128,aes-256}
??????????????????????encryption?method
-owner?OWNER??????????owner?password
-user?USER????????????user?password
-garbage?{0,1,2,3,4}??garbage?collection?level
-compress?????????????compress?(deflate)?output
-ascii????????????????ASCII?encode?binary?data
-linear???????????????format?for?fast?web?display
-permission?PERMISSION
??????????????????????integer?with?permission?levels
-sanitize?????????????sanitize?/?clean?contents
-pretty???????????????prettify?PDF?structure
-pages?PAGES??????????output?selected?pages,?format:?1,5-7,50-N
以下命令只需在終端運行即可:
參數(shù):2-N 代表去除第一頁
python?-m?fitz?clean?-sanitize?-pages?2-N?F:\視覺工程師必須知道的工業(yè)相機50問.pdf?F:\去除第一頁.pdf
其他功能請自行嘗試
提取字體和圖像(非 PDF 頁面)
將字體或圖像從選定的 PDF 頁面提取到所需目錄,基本說明如下:
python?-m?fitz?extract?-h
usage:?fitz?extract?[-h]?[-images]?[-fonts]?[-output?OUTPUT]?[-password?PASSWORD]
????????????????????[-pages?PAGES]
????????????????????input
---------------------?extract?images?and?fonts?to?disk?--------------------
positional?arguments:
input?????????????????PDF?filename
optional?arguments:
-h,?--help????????????show?this?help?message?and?exit
-images???????????????extract?images
-fonts????????????????extract?fonts
-output?OUTPUT????????output?directory,?defaults?to?current
-password?PASSWORD????password
-pages?PAGES??????????only?consider?these?pages,?format:?1,5-7,50-N
將 視覺工程師必須知道的工業(yè)相機50問.pdf 文件中的圖片和字體提取到 提取結(jié)果 文件夾中
python?-m?fitz?extract?-images?-fonts?-output?F:\提取結(jié)果?F:\視覺工程師必須知道的工業(yè)相機50問.pdf
saved?9?fonts?to?'F:\提取結(jié)果'
saved?6?images?to?'F:\提取結(jié)果'
合并多份文檔
合并多份 PDF 文檔,使用的是 join 命令,可以指定頁面進行合并,同時需要關(guān)注 PDF 是否需要密碼才能打開,基本說明如下:
python?-m?fitz?join?-h
usage:?fitz?join?[-h]?-output?OUTPUT?[input?[input?...]]
----------------------------?join?PDF?documents?---------------------------
positional?arguments:
input???????????input?filenames
optional?arguments:
-h,?--help??????show?this?help?message?and?exit
-output?OUTPUT??output?filename
specify?each?input?as?'filename[,password[,pages]]'
以下命令只需在終端運行即可:合并兩份文檔的全部
python?-m?fitz?join?-output?"F:\合并兩份文檔.pdf"?"F:\視覺工程師必須知道的工業(yè)相機50問.pdf"?"F:\Modern?CMake文檔.pdf"
合并兩份文檔的部分,選擇 視覺工程師必須知道的工業(yè)相機50問 文件的第一頁和 ?Modern CMake文檔.pdf 的 5 到最后一頁進行合并,下面語句中有兩個 ,, 是因為要合并的文檔不需要密碼,如果需要密碼,就把兩個逗號替換成 密碼即可。
5-N 代表第五頁開始到文檔的末尾
python?-m?fitz?join?-output?F:\合并兩份文檔.pdf?F:\視覺工程師必須知道的工業(yè)相機50問.pdf,,1?"F:\Modern?CMake文檔.pdf",,5-N
PDF 轉(zhuǎn)換成圖片
這個功能沒辦法像上面那樣一個命令就能解決,不過通過查看文檔,我們也不難寫出代碼
import?sys,?fitz,?os,?datetime
def?pyMuPDF_fitz(pdfPath,?imagePath):
????startTime_pdf2img?=?datetime.datetime.now()#開始時間
????print("imagePath="+imagePath)
????pdfDoc?=?fitz.open(pdfPath)?#?打開文件
????for?pg?in?range(pdfDoc.pageCount):?#?遍歷所有頁面
????????page?=?pdfDoc[pg]
????????rotate?=?int(0)?#?頁面旋轉(zhuǎn)角度
????????#?每個尺寸的縮放系數(shù)為1.3,這將為我們生成分辨率提高2.6的圖像。
????????#?此處若是不做設(shè)置,默認圖片大小為:792X612, dpi=96
????????zoom_x?=?1.33333333?#(1.33333333-->1056x816)???(2-->1584x1224)
????????zoom_y?=?1.33333333
????????mat?=?fitz.Matrix(zoom_x,?zoom_y).preRotate(rotate)
????????pix?=?page.getPixmap(matrix=mat,?alpha=False)
????????if?not?os.path.exists(imagePath):#判斷存放圖片的文件夾是否存在
????????????os.makedirs(imagePath)?#?若圖片文件夾不存在就創(chuàng)建
????????pix.writePNG(imagePath+'/'+'images_%s.png'?%?pg)#將圖片寫入指定的文件夾內(nèi)
????endTime_pdf2img?=?datetime.datetime.now()#結(jié)束時間
????print('pdf2img時間=',(endTime_pdf2img?-?startTime_pdf2img).seconds)
if?__name__?==?"__main__":
????pdfPath?=?'./視覺工程師必須知道的工業(yè)相機50問.pdf'
????imagePath?=?'./提取結(jié)果'
????pyMuPDF_fitz(pdfPath,?imagePath)
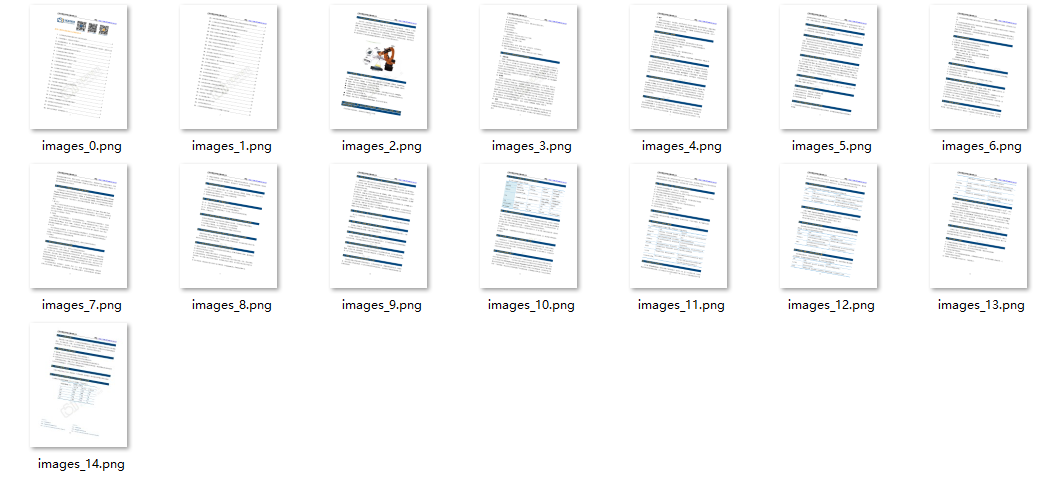
神奇的網(wǎng)站明天再放出,哈哈哈~~~
以上就是 PDF 處理的幾個常用功能,希望能夠幫到你,喜歡的朋友感謝三連~~~
參考:
https://pymupdf.readthedocs.io/en/latest/index.html https://www.jianshu.com/p/f57cc64b9f5e
往期精彩回顧
獲取一折本站知識星球優(yōu)惠券,復(fù)制鏈接直接打開:
https://t.zsxq.com/yFQV7am
本站qq群1003271085。
加入微信群請掃碼進群: