
CV大神何愷明最新一作:視覺預(yù)訓(xùn)練新范式MAE!下一個(gè)CV大模型要來?

??新智元報(bào)道??
??新智元報(bào)道??
編輯:David、桃子
【新智元導(dǎo)讀】CV大神何愷明又出力作!團(tuán)隊(duì)提出MAE模型,將NLP領(lǐng)域大獲成功的自監(jiān)督預(yù)訓(xùn)練模式用在了計(jì)算機(jī)視覺任務(wù)上,效果拔群,在NLP和CV兩大領(lǐng)域間架起了一座更簡便的橋梁。

論文成果簡介

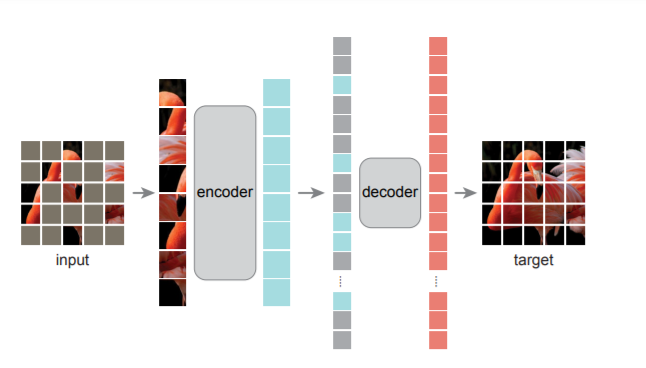
MAE模型結(jié)構(gòu)與實(shí)現(xiàn)



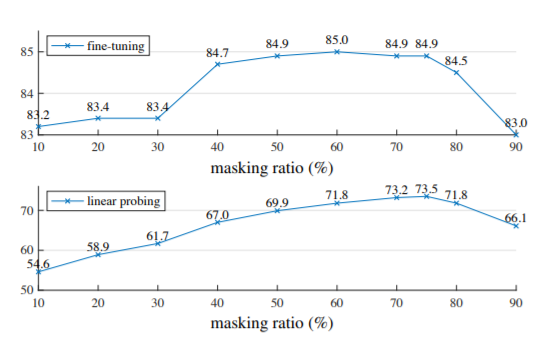
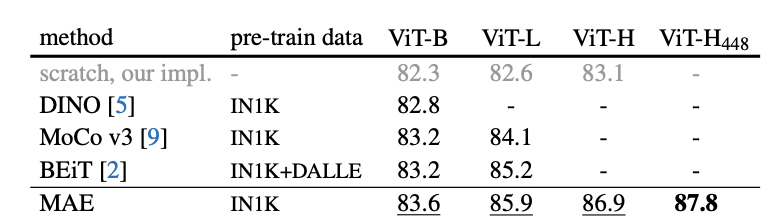
性能驚艷:ImageNet-1K最高87.8%
與當(dāng)前SOTA自監(jiān)督預(yù)訓(xùn)練方法相比,對于 ViT-B 的表現(xiàn)結(jié)果都很接近。對于 ViT-L不同方法的結(jié)果就存在很大差距,這表明更大模型的挑戰(zhàn)是減少過度擬合。
網(wǎng)友:respect
「現(xiàn)在是2021年11月12日中午,愷明剛放出來幾個(gè)小時(shí),就預(yù)定了CVPR2022 best paper candidate(這里說的是best paper candidate,不是best paper)」



作者介紹


評論
圖片
表情