
一行代碼讓 pandas 的 apply 速度飆到極致!

來(lái)源:Python數(shù)據(jù)科學(xué)
作者:東哥起飛
vaex是pandas的替代工具。它利用了內(nèi)存映射的原理,所以比pandas能快上幾百倍,但是vaex目前功能有限,所以暫時(shí)pandas還是無(wú)法撼動(dòng)的。
1.?pandas提速的方法回顧
如果想要讓pandas提速,筆者總結(jié)有兩個(gè)方法:
1.?向量化
向量化是最優(yōu)的方法,舉個(gè)例子,我們將向量化定義為使用Numpy表示整個(gè)數(shù)組而不是元素的計(jì)算。下面有兩個(gè)數(shù)組:
array_1?=?np.array([1,2,3,4,5])
array_2?=?np.array([6,7,8,9,10])
我們希望創(chuàng)建一個(gè)新數(shù)組,該數(shù)組是兩個(gè)數(shù)組的總和,結(jié)果應(yīng)該是:
result?=?[7,9,11,13,15]
當(dāng)然,我們也可以在Python中使用for循環(huán)將這些數(shù)組求和,但這非常慢。替代的是,Numpy允許我們直接在陣列上進(jìn)行操作,這要快得多,尤其是大型陣列。
result?=?array_1?+?array_2
2. 并行化
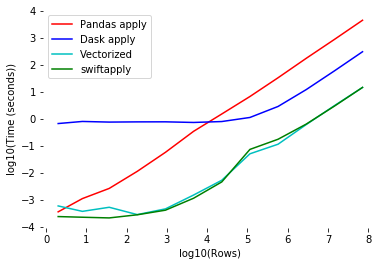
本次給大家分享一個(gè)神器?Swifter,可以自動(dòng)讓apply的運(yùn)行速度達(dá)到最快,并且只需要一行代碼!
2. Swifter介紹
import?pandas?as?pd
import?swifter
df.swifter.apply(lambda?x:?x.sum()?-?x.min())
長(zhǎng)按掃碼添加“Python小助手”
▼點(diǎn)擊成為社區(qū)會(huì)員? ?喜歡就點(diǎn)個(gè)在看吧
評(píng)論
圖片
表情