
一行代碼讓你的pandas運行得更快
選自:towardsdatascience
作者:Parul Pandey
原文:https://towardsdatascience.com/get-faster-pandas-with-modin-even-on-your-laptops-b527a2eeda74
編譯:機器之心(almosthuman2014)
參與:Geek AI、Chita
Pandas 是數(shù)據(jù)科學(xué)領(lǐng)域的工作者都熟知的程序庫。它提供高性能、易于使用的數(shù)據(jù)結(jié)構(gòu)和數(shù)據(jù)分析工具。但是,當(dāng)處理過于龐大的數(shù)據(jù)時,單個內(nèi)核上運行的 Pandas 就會變得力不從心,人們不得不求助于不同的分布式系統(tǒng)來提高性能。然而,為了提高性能而做的這種權(quán)衡會帶來陡峭的學(xué)習(xí)曲線。
本質(zhì)上,用戶只是想讓 Pandas 運行得更快,而不是為了特定的硬件設(shè)置而優(yōu)化其工作流。這意味著人們希望在處理 10KB 的數(shù)據(jù)集時,可以使用與處理 10TB 數(shù)據(jù)集時相同的 Pandas 腳本。Modin 提供了一個優(yōu)化 Pandas 的解決方案,這樣數(shù)據(jù)科學(xué)家就可以把時間花在從數(shù)據(jù)中提取價值上,而不是花在提取數(shù)據(jù)的工具上。
Modin

Modin 是加州大學(xué)伯克利分校 RISELab 的一個早期項目,旨在促進分布式計算在數(shù)據(jù)科學(xué)領(lǐng)域的應(yīng)用。它是一個多進程的數(shù)據(jù)幀(Dataframe)庫,具有與 Pandas 相同的應(yīng)用程序接口(API),使用戶可以加速他們的 Pandas 工作流。
在一臺 8 核的機器上,用戶只需要修改一行代碼,Modin 就能將 Pandas 查詢?nèi)蝿?wù)加速 4 倍。
該系統(tǒng)是為希望程序運行得更快、伸縮性更好,而無需進行重大代碼更改的 Pandas 用戶設(shè)計的。這項工作的最終目標(biāo)是能夠在云環(huán)境中使用 Pandas。
安裝
Modin 是完全開源的,可以通過下面的 GitHub 鏈接獲得:
https://github.com/modin-project/modin
我們可以使用如下所示的 PyPi 指令來安裝 Modin:
pip?install?modin在 Windows 環(huán)境下,Ray 是安裝 Modin 所需的依賴之一。Windows 本身并不支持 Ray,所以為了安裝它,用戶需要使用 WSL(適用 Linux 的 Windows 子系統(tǒng))。
Modin 如何加速數(shù)據(jù)處理過程
在筆記本上
在具有 4 個 CPU 內(nèi)核的現(xiàn)代筆記本上處理適用于該機器的數(shù)據(jù)幀時,Pandas 僅僅使用了 1 個 CPU 內(nèi)核,而 Modin 則能夠使用全部 4 個內(nèi)核。
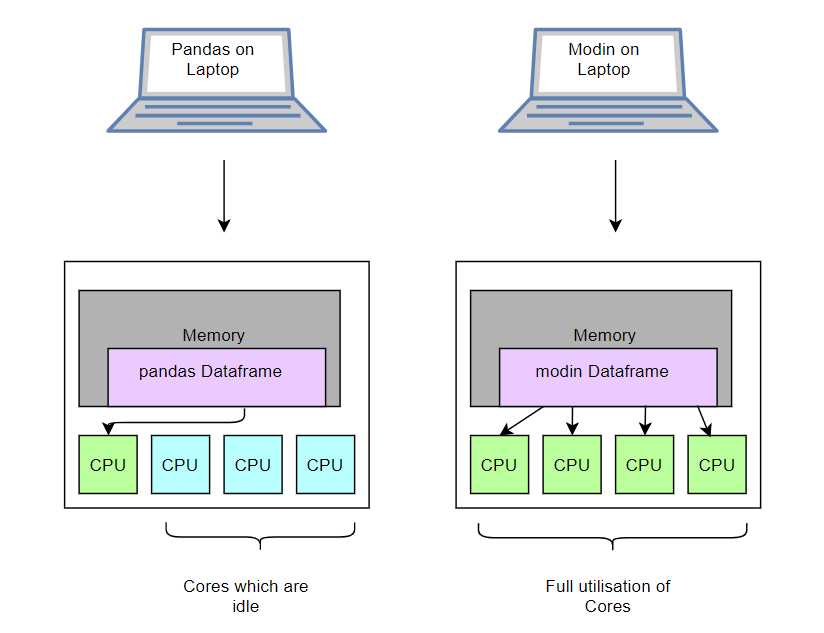
Pandas 和 Modin 對 CPU 內(nèi)核的使用情況
從本質(zhì)上講,Modin 所做的只是增加了 CPU 所有內(nèi)核的利用率,從而提供了更好的性能。
在大型機器上
在大型機器上,Modin 的作用就變得更加明顯了。假設(shè)我們有一臺服務(wù)器或一臺非常強大的機器,Pandas 仍然只會利用一個內(nèi)核,而 Modin 會使用所有的內(nèi)核。下圖顯示了在一臺擁有 144 內(nèi)核的計算機上通過 Pandas 和 Modin 使用「read_csv」函數(shù)的性能對比情況:
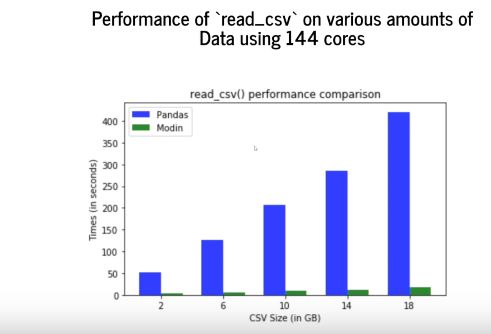
Pandas 的運行時間會隨著數(shù)據(jù)量的變化而線性增長,因為它僅僅使用 1 個內(nèi)核。而從上圖中可能很難看到綠色條形圖的增長,因為 Modin 的運行時間實在太短了。
通常,Modin 使用「read_csv」函數(shù)讀取 2G 數(shù)據(jù)需要 2 秒,而?讀取 18G 數(shù)據(jù)大約需要不到 18 秒。
架構(gòu)
接下來,本文將解析 Modin 的架構(gòu)。
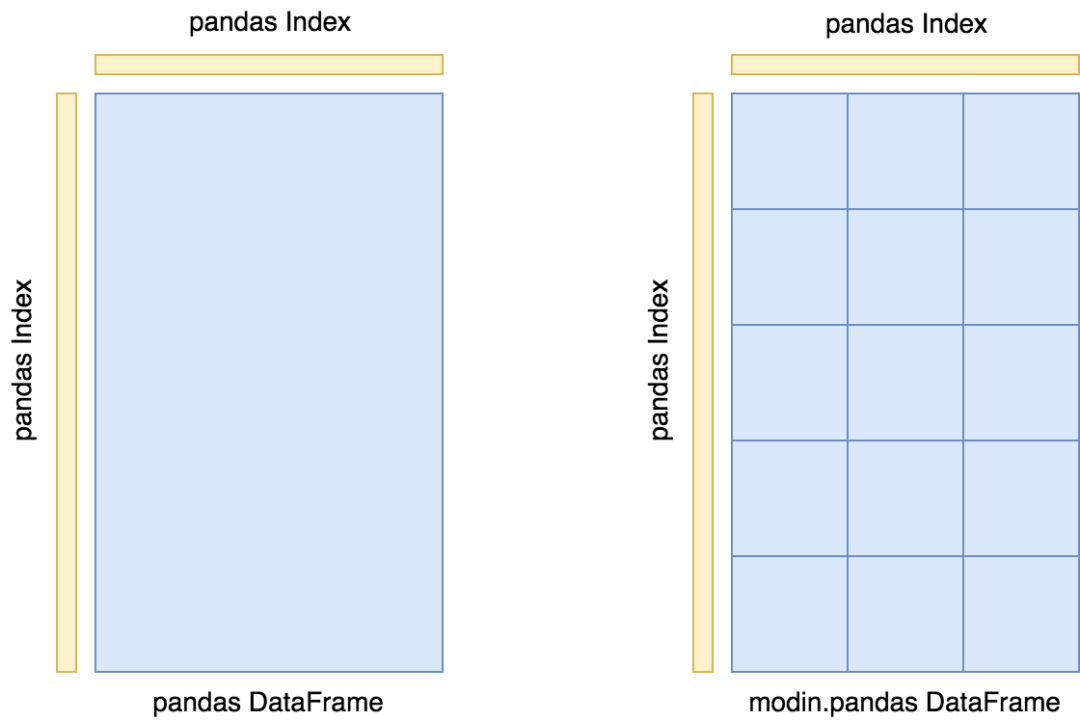
數(shù)據(jù)幀分區(qū)
Modin 對數(shù)據(jù)幀的分區(qū)模式是沿著列和行同時進行劃分的,因為這樣為 Modins 在支持的列數(shù)和行數(shù)上都提供了靈活性和可伸縮性。
系統(tǒng)架構(gòu)
Modin 被分為不同的層:
Pandas API 在最頂層暴露給用戶。
下一層為查詢編譯器,它接收來自 Pandas API 層的查詢并執(zhí)行某些優(yōu)化。
最后一層為分區(qū)管理器(Partition Manager),負責(zé)數(shù)據(jù)布局并對發(fā)送到每個分區(qū)的任務(wù)進行重組、分區(qū)和序列化。
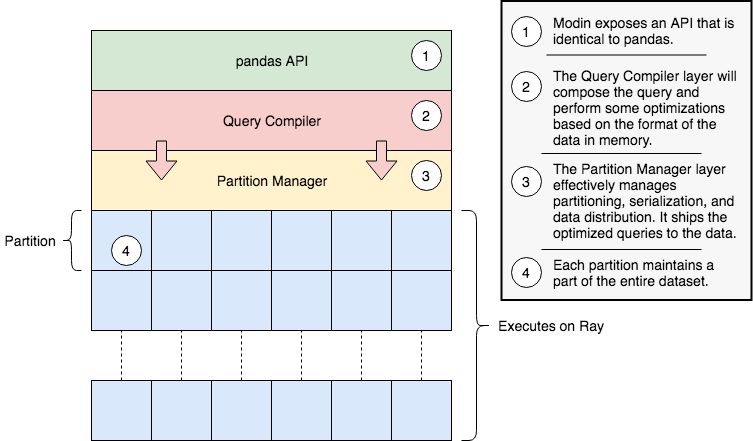
modin 的一般架構(gòu)
在 Modin 中實現(xiàn) Pandas API
pandas 有大量的 API,這可能也是它應(yīng)用如此廣泛的原因之一。
pandas API
由于 Pandas 具有這么多種操作,Modin 采用了一種數(shù)據(jù)驅(qū)動的方法。也就是說 Modin 的創(chuàng)造者找出了人們最常用的 Pandas 操作。他們研究了 Kaggle 平臺上的 Pandas 使用數(shù)據(jù),對上面所有的 notebook 和腳本進行了分析,最終總結(jié)出最受歡迎的 Pandas 方法如下:
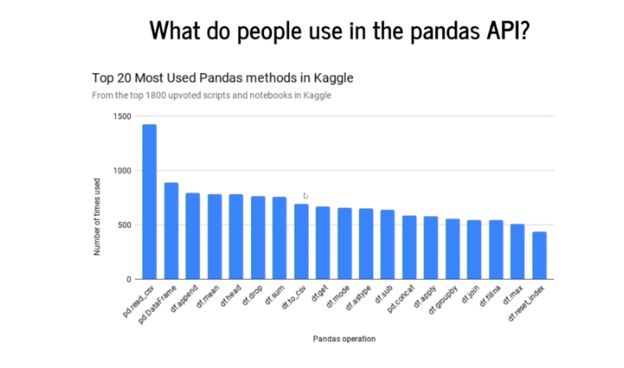
「pd.read_CSV」是目前最常用的 Pandas 方法,其次是「pd.Dataframe」方法。因此,在 Modin 中,設(shè)計者們開始實現(xiàn)一些 Pandas 操作,并按照它們受歡迎程度從高到低的順序進行優(yōu)化:
目前,Modin 支持大約 71%?的 Pandas API。
根據(jù)研究,這代表了 93%?的使用場景。
Ray
Modin 利用 Ray 以毫不費力的方式加速 Pandas 的 notebook、腳本和程序庫。Ray 是一個針對大規(guī)模機器學(xué)習(xí)和強化學(xué)習(xí)應(yīng)用的高性能分布式執(zhí)行框架。同樣的代碼可以在單臺機器上運行以實現(xiàn)高效的多進程,也可以在集群上用于大型計算。你可以通過下面的 GitHub 鏈接獲取 Ray:http://github.com/ray-project/ray。
使用方法
導(dǎo)入
Modin 封裝了 Pandas,并透明地分發(fā)數(shù)據(jù)和計算任務(wù),它通過修改一行代碼就加速了 Pandas 的工作流。用戶可以繼續(xù)使用以前的 Pandas notebook,同時體驗 Modin 帶來的大幅加速,甚至在一臺機器上。用戶需要做的只是修改導(dǎo)入程序包的聲明,引入「modin.pandas」而不是「pandas」。
import?numpy?as?np
import?modin.pandas?as?pd
我們將使用 Numpy 構(gòu)建一個由隨機整數(shù)組成的簡單數(shù)據(jù)集。請注意,我們并不需要在這里指定分區(qū)。
data?=?np.random.randint(0,100,size?=?(2**16,?2**4))
df?=?pd.DataFrame(data)
df?=?df.add_prefix("Col:")當(dāng)我們將數(shù)據(jù)的類型打印在屏幕上時,會顯示出「Modin 數(shù)據(jù)幀」。
type(df)
modin.pandas.dataframe.DataFrame如果我們使用「head」命令打印出前五行數(shù)據(jù),它會像 Pandas 一樣顯示出 HTML 表單。
df.head()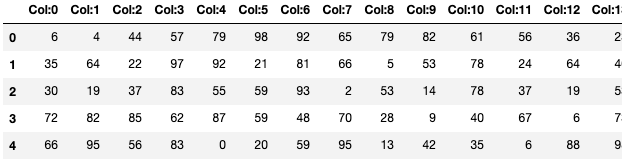
對比實驗
Modin 會管理數(shù)據(jù)分區(qū)和重組,從而使用戶能夠?qū)⒆⒁饬杏趶臄?shù)據(jù)中提取出價值。下面的代碼是在一臺 2013 年的擁有 4 個 CPU 內(nèi)核和 32 GB RAM 內(nèi)存的 iMac 機器上運行的。
pd.read_csv
「read_csv」是目前為止最常用的 Pandas 操作。接下來,本文將對分別在 Pandas 和 Modin 環(huán)境下使用「read_csv」函數(shù)的性能進行一個簡單的對比。
pandas
%%time
import?pandas?
pandas_csv_data?=?pandas.read_csv("../800MB.csv")
-----------------------------------------------------------------
CPU?times:?user?26.3?s,?sys:?3.14?s,?total:?29.4s
Wall?time:?29.5?sModin
%%time
modin_csv_data?=?pd.read_csv("../750MB.csv")
-----------------------------------------------------------------
CPU?times:?user?76.7?ms,?sys:?5.08?ms,?total:?81.8?ms
Wall?time:?7.6?s通過使用 Modin,只需要修改導(dǎo)入聲明就可以在一臺 4 核機器上以普通 Pandas 4 倍的速度執(zhí)行「read_csv」操作。
df.groupby
Pandas 的「groupby」聚合函數(shù)底層編寫得非常好,運行速度非常快。但是即使如此,Modin 的性能也比 Pandas 要好。
Pandas
%%time
import?pandas
_?=?pandas_csv_data.groupby(by=pandas_csv_data.col_1).sum()
-----------------------------------------------------------------
CPU?times:?user?5.98?s,?sys:?1.77?s,?total:?7.75?s
Wall?time:?7.74?smodin
%%time
results?=?modin_csv_data.groupby(by=modin_csv_data.col_1).sum()
-----------------------------------------------------------------
CPU?times:?user?3.18?s,?sys:?42.2?ms,?total:?3.23?s
Wall?time:?7.3?sPandas 實現(xiàn)的默認設(shè)置
如果想要使用尚未實現(xiàn)或優(yōu)化的 Pandas API,實際上可以使用默認的 Pandas API。這使得該系統(tǒng)可以用于使用 Modin 中尚未實現(xiàn)操作的 notebook 中(盡管由于即將使用 Pandas API,性能會有所下降)。當(dāng)使用默認的 Pandas API 時,你將看到一個警告:
dot_df?=?df.dot(df.T)
當(dāng)計算完成后,該操作會返回一個分布式的 Modin 數(shù)據(jù)幀。
type(dot_df)
-----------------
modin.pandas.dataframe.DataFrame結(jié)語
Modin 項目仍處于早期階段,但對 Pandas 來說是一個非常有發(fā)展前景的補充。Modin 為用戶處理所有的數(shù)據(jù)分區(qū)和重組任務(wù),這樣我們就可以集中精力處理工作流。Modin 的基本目標(biāo)是讓用戶能夠在小數(shù)據(jù)和大數(shù)據(jù)上使用相同的工具,而不用考慮改變 API 來適應(yīng)不同的數(shù)據(jù)規(guī)模。
_往期文章推薦_