
終于用上分庫分表了!
1、騰訊可視化, 低代碼生成器,正式開源! 2、一行代碼解決緩存擊穿的問題 3、Java反射到底慢在哪? 4、比 MyBatis 快 100 倍,天生支持聯(lián)表! 5、這份Java日志格式規(guī)范,強啊!
前言
大家好,今天跟大家聊聊分庫分表。
什么是分庫分表
為什么需要分庫分表
如何分庫分表
什么時候開始考慮分庫分表
分庫分表會導(dǎo)致哪些問題
分庫分表中間件簡介
1. 什么是分庫分表
分庫:就是一個數(shù)據(jù)庫分成多個數(shù)據(jù)庫,部署到不同機器。
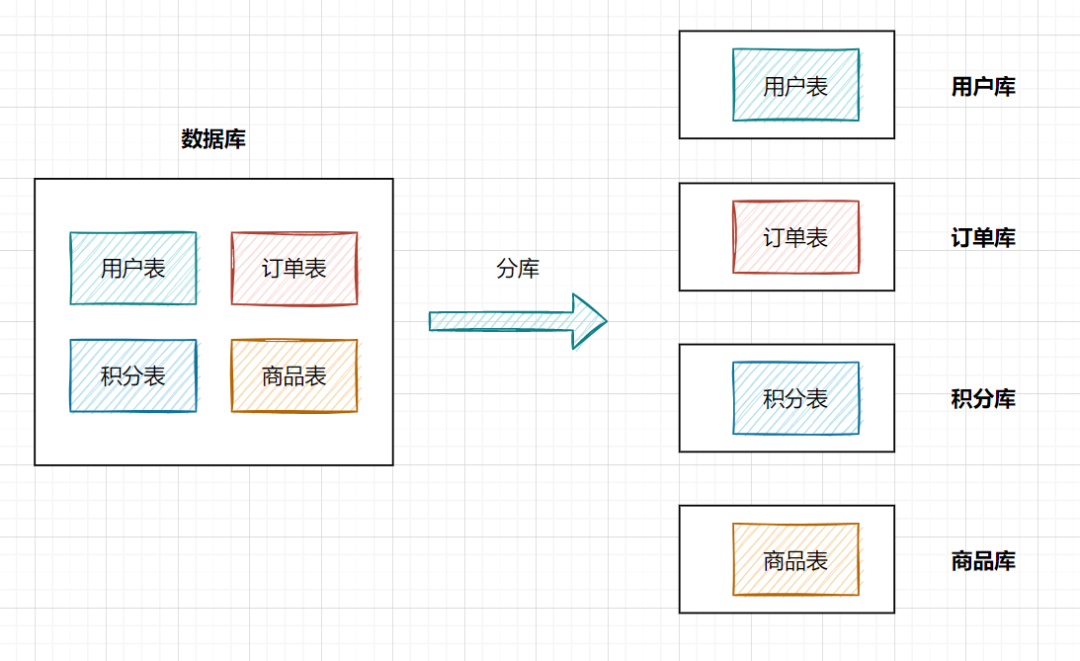
分表:就是一個數(shù)據(jù)庫表分成多個表。

2. 為什么需要分庫分表
2.1 為什么需要分庫呢?
如果業(yè)務(wù)量劇增,數(shù)據(jù)庫可能會出現(xiàn)性能瓶頸,這時候我們就需要考慮拆分?jǐn)?shù)據(jù)庫。從這幾方面來看:
磁盤存儲
業(yè)務(wù)量劇增,MySQL單機磁盤容量會撐爆,拆成多個數(shù)據(jù)庫,磁盤使用率大大降低。
并發(fā)連接支撐
我們知道數(shù)據(jù)庫連接是有限的。在高并發(fā)的場景下,大量請求訪問數(shù)據(jù)庫,MySQL單機是扛不住的!當(dāng)前非常火的微服務(wù)架構(gòu)出現(xiàn),就是為了應(yīng)對高并發(fā)。它把訂單、用戶、商品等不同模塊,拆分成多個應(yīng)用,并且把單個數(shù)據(jù)庫也拆分成多個不同功能模塊的數(shù)據(jù)庫(訂單庫、用戶庫、商品庫),以分擔(dān)讀寫壓力。
2.2 為什么需要分表?
數(shù)據(jù)量太大的話,SQL的查詢就會變慢。如果一個查詢SQL沒命中索引,千百萬數(shù)據(jù)量級別的表可能會拖垮整個數(shù)據(jù)庫。
即使SQL命中了索引,如果表的數(shù)據(jù)量超過一千萬的話,查詢也是會明顯變慢的。這是因為索引一般是B+樹結(jié)構(gòu),數(shù)據(jù)千萬級別的話,B+樹的高度會增高,查詢就變慢啦。
小伙伴們是否還記得,MySQL的B+樹的高度怎么計算的呢? 順便復(fù)習(xí)一下吧
InnoDB存儲引擎最小儲存單元是頁,一頁大小就是16k。B+樹葉子存的是數(shù)據(jù),內(nèi)部節(jié)點存的是鍵值+指針。索引組織表通過非葉子節(jié)點的二分查找法以及指針確定數(shù)據(jù)在哪個頁中,進而再去數(shù)據(jù)頁中找到需要的數(shù)據(jù),B+樹結(jié)構(gòu)圖如下:
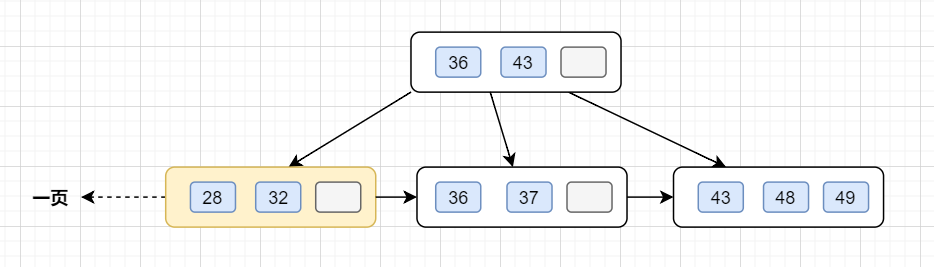
假設(shè)B+樹的高度為2的話,即有一個根結(jié)點和若干個葉子結(jié)點。這棵B+樹的存放總記錄數(shù)為=根結(jié)點指針數(shù)*單個葉子節(jié)點記錄行數(shù)。
如果一行記錄的數(shù)據(jù)大小為1k,那么單個葉子節(jié)點可以存的記錄數(shù) ?
=16k/1k =16.非葉子節(jié)點內(nèi)存放多少指針呢?我們假設(shè)主鍵ID為bigint類型,長度為8字節(jié)(面試官問你int類型,一個int就是32位,4字節(jié)),而指針大小在InnoDB源碼中設(shè)置為6字節(jié),所以就是
8+6=14字節(jié),16k/14B =16*1024B/14B = 1170
因此,一棵高度為2的B+樹,能存放1170 * 16=18720條這樣的數(shù)據(jù)記錄。同理一棵高度為3的B+樹,能存放1170 *1170 *16 =21902400,大概可以存放兩千萬左右的記錄。B+樹高度一般為1-3層,如果B+到了4層,查詢的時候會多查磁盤的次數(shù),SQL就會變慢。
因此單表數(shù)據(jù)量太大,SQL查詢會變慢,所以就需要考慮分表啦。
3. 如何分庫分表
3.1 垂直拆分
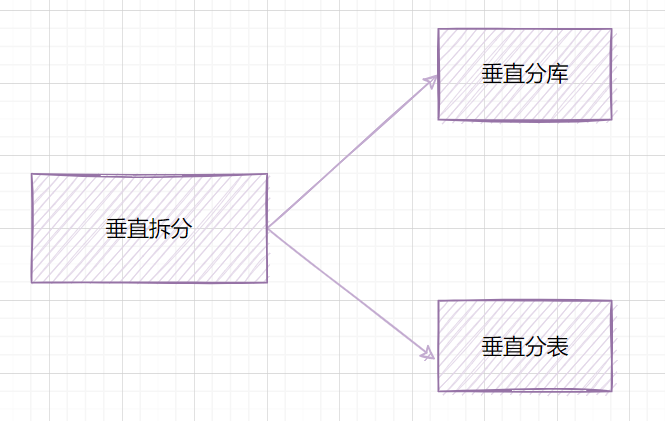
3.1.1 垂直分庫
在業(yè)務(wù)發(fā)展初期,業(yè)務(wù)功能模塊比較少,為了快速上線和迭代,往往采用單個數(shù)據(jù)庫來保存數(shù)據(jù)。數(shù)據(jù)庫架構(gòu)如下:
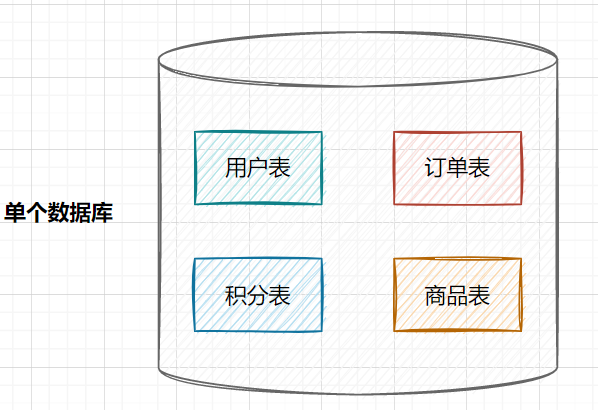
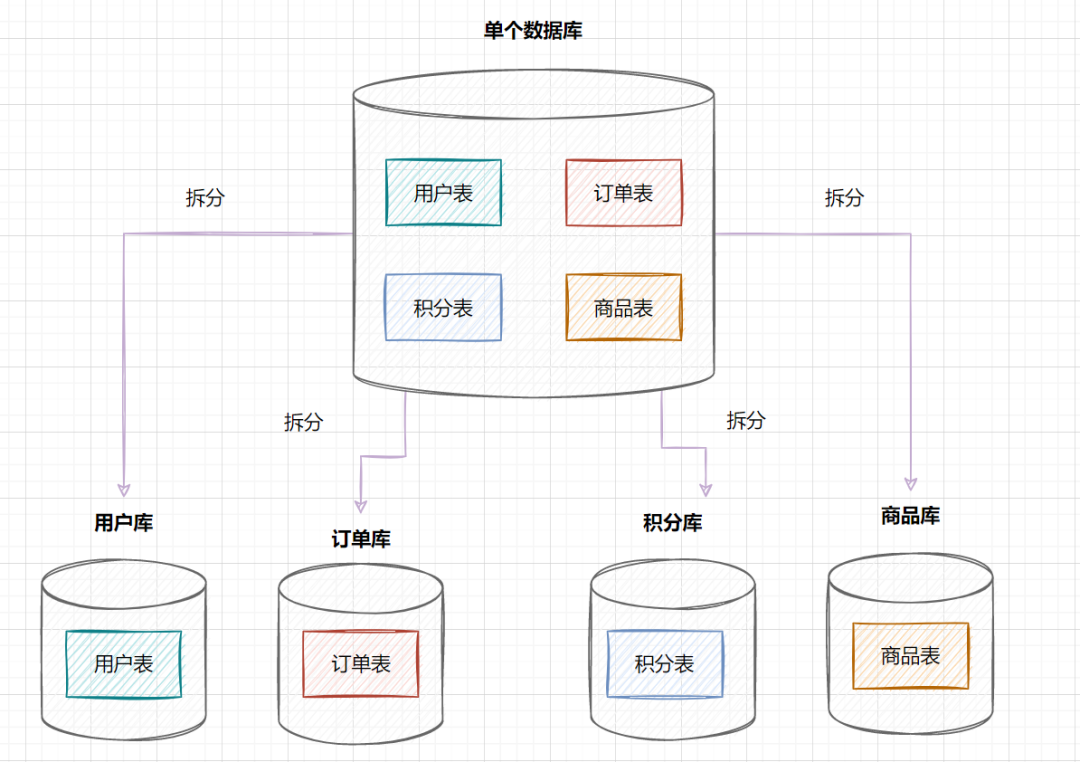
但是隨著業(yè)務(wù)蒸蒸日上,系統(tǒng)功能逐漸完善。這時候,可以按照系統(tǒng)中的不同業(yè)務(wù)進行拆分,比如拆分成用戶庫、訂單庫、積分庫、商品庫,把它們部署在不同的數(shù)據(jù)庫服務(wù)器,這就是垂直分庫。
垂直分庫,將原來一個單數(shù)據(jù)庫的壓力分擔(dān)到不同的數(shù)據(jù)庫,可以很好應(yīng)對高并發(fā)場景。數(shù)據(jù)庫垂直拆分后的架構(gòu)如下:
3.1.2 垂直分表
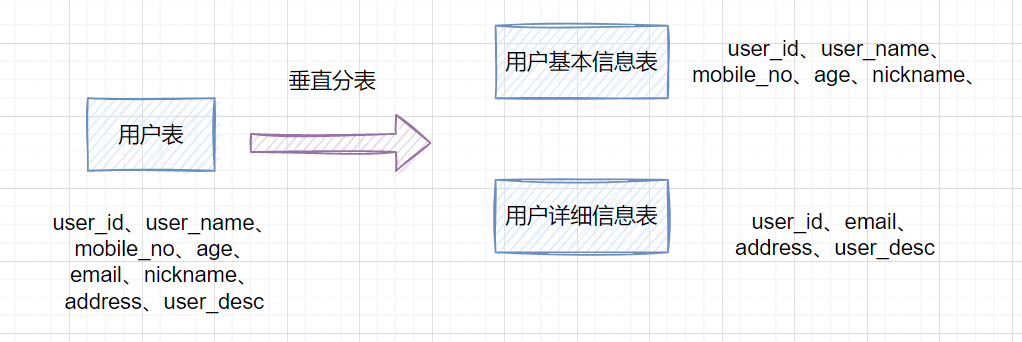
如果一個單表包含了幾十列甚至上百列,管理起來很混亂,每次都select *的話,還占用IO資源。這時候,我們可以將一些不常用的、數(shù)據(jù)較大或者長度較長的列拆分到另外一張表。
比如一張用戶表,它包含user_id、user_name、mobile_no、age、email、nickname、address、user_desc,如果email、address、user_desc等字段不常用,我們可以把它拆分到另外一張表,命名為用戶詳細(xì)信息表。這就是垂直分表
3.2 水平拆分
3.2.1 水平分庫
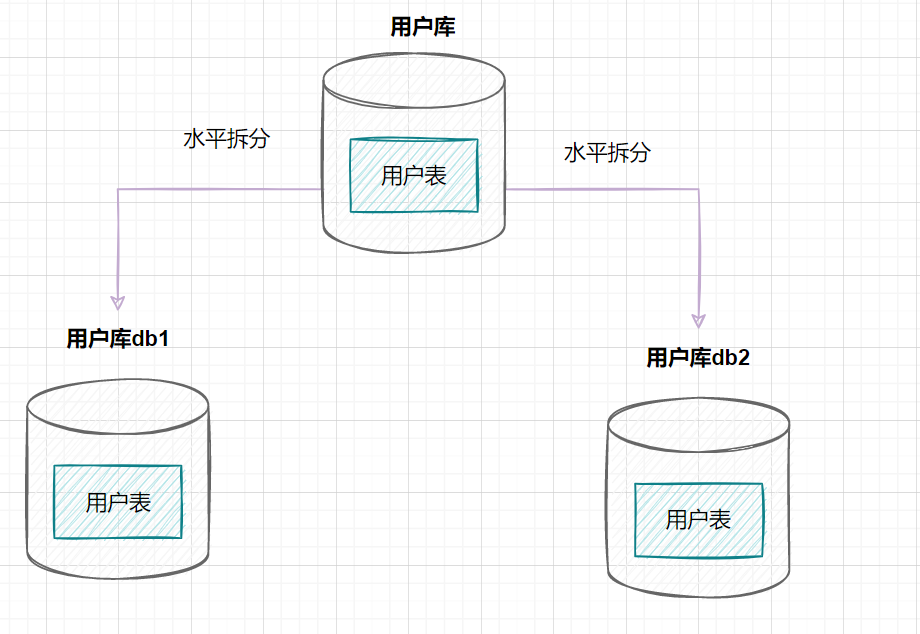
水平分庫是指,將表的數(shù)據(jù)量切分到不同的數(shù)據(jù)庫服務(wù)器上,每個服務(wù)器具有相同的庫和表,只是表中的數(shù)據(jù)集合不一樣。它可以有效的緩解單機單庫的性能瓶頸和壓力。
用戶庫的水平拆分架構(gòu)如下:
3.2.2 水平分表
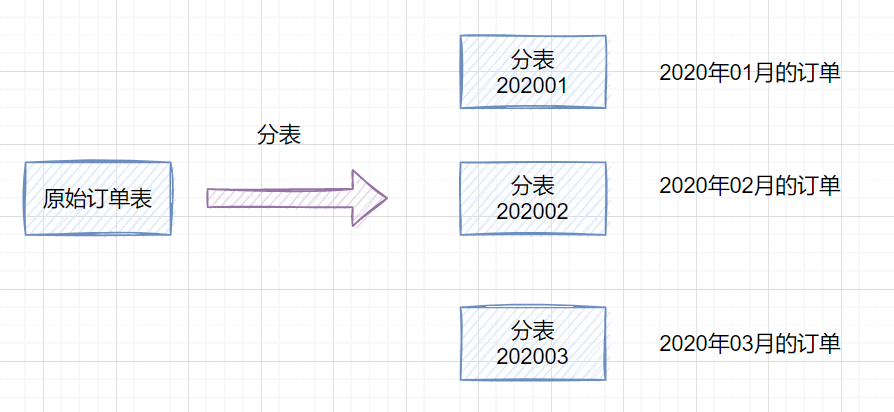
如果一個表的數(shù)據(jù)量太大,可以按照某種規(guī)則(如hash取模、range),把數(shù)據(jù)切分到多張表去。
一張訂單表,按時間range拆分如下:
3.3. 水平分庫分表策略
分庫分表策略一般有幾種,使用與不同的場景:
range范圍
hash取模
range+hash取模混合
3.3.1 range范圍
range,即范圍策略劃分表。比如我們可以將表的主鍵,按照從0~1000萬的劃分為一個表,1000~2000萬劃分到另外一個表。如下圖:
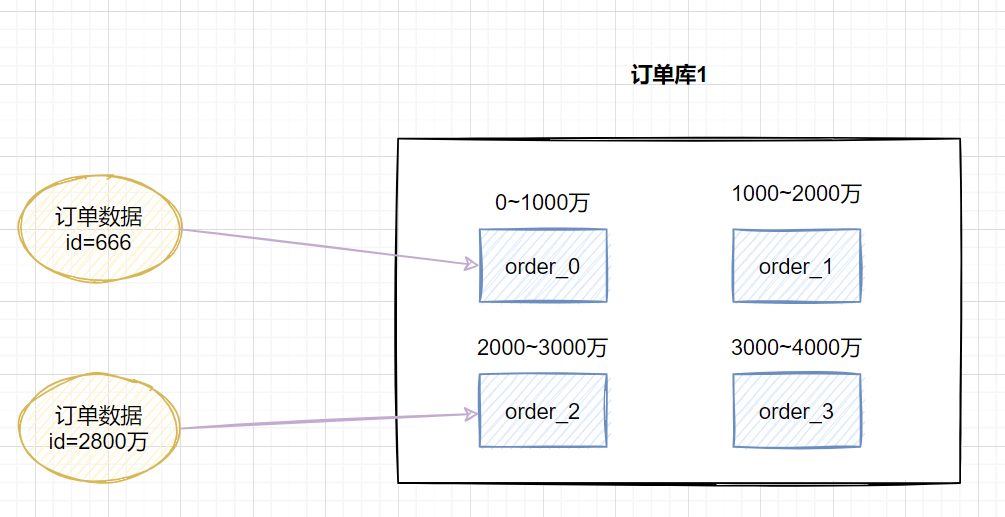
當(dāng)然,有時候我們也可以按時間范圍來劃分,如不同年月的訂單放到不同的表,它也是一種range的劃分策略。
這種方案的優(yōu)點:
這種方案有利于擴容,不需要數(shù)據(jù)遷移。假設(shè)數(shù)據(jù)量增加到5千萬,我們只需要水平增加一張表就好啦,之前
0~4000萬的數(shù)據(jù),不需要遷移。
缺點:
這種方案會有熱點問題,因為訂單id是一直在增大的,也就是說最近一段時間都是匯聚在一張表里面的。比如最近一個月的訂單都在
1000萬~2000萬之間,平時用戶一般都查最近一個月的訂單比較多,請求都打到order_1表啦,這就導(dǎo)致數(shù)據(jù)熱點問題。
3.3.2 hash取模
hash取模策略:指定的路由key(一般是user_id、訂單id作為key)對分表總數(shù)進行取模,把數(shù)據(jù)分散到各個表中。
比如原始訂單表信息,我們把它分成4張分表:
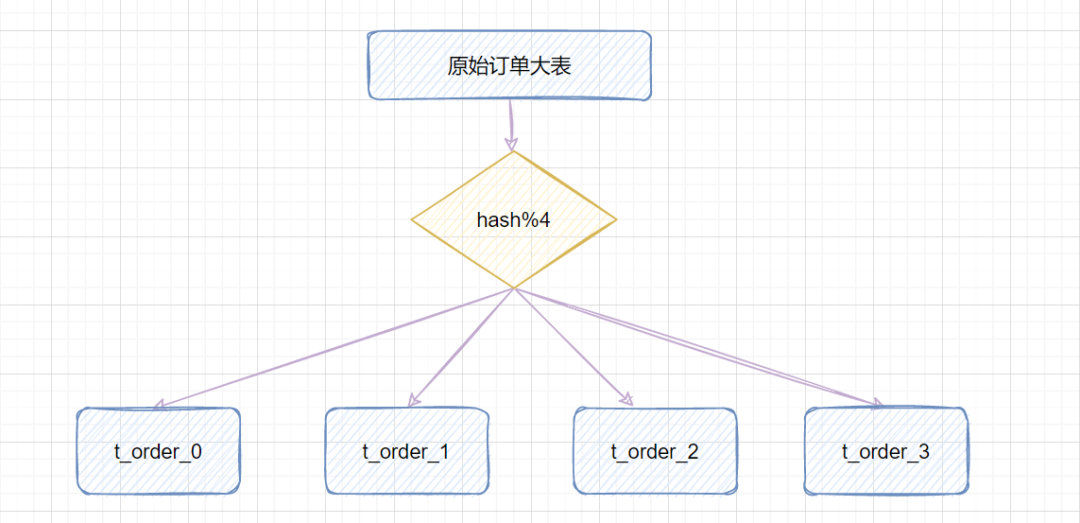
比如id=1,對4取模,就會得到1,就把它放到
t_order_1;id=3,對4取模,就會得到3,就把它放到
t_order_3;
這種方案的優(yōu)點:
hash取模的方式,不會存在明顯的熱點問題。
缺點:
如果一開始按照hash取模分成4個表了,未來某個時候,表數(shù)據(jù)量又到瓶頸了,需要擴容,這就比較棘手了。比如你從4張表,又?jǐn)U容成
8張表,那之前id=5的數(shù)據(jù)是在(5%4=1,即t_order_1),現(xiàn)在應(yīng)該放到(5%8=5,即t_order_5),也就是說歷史數(shù)據(jù)要做遷移了。
3.3.3 range+hash取模混合
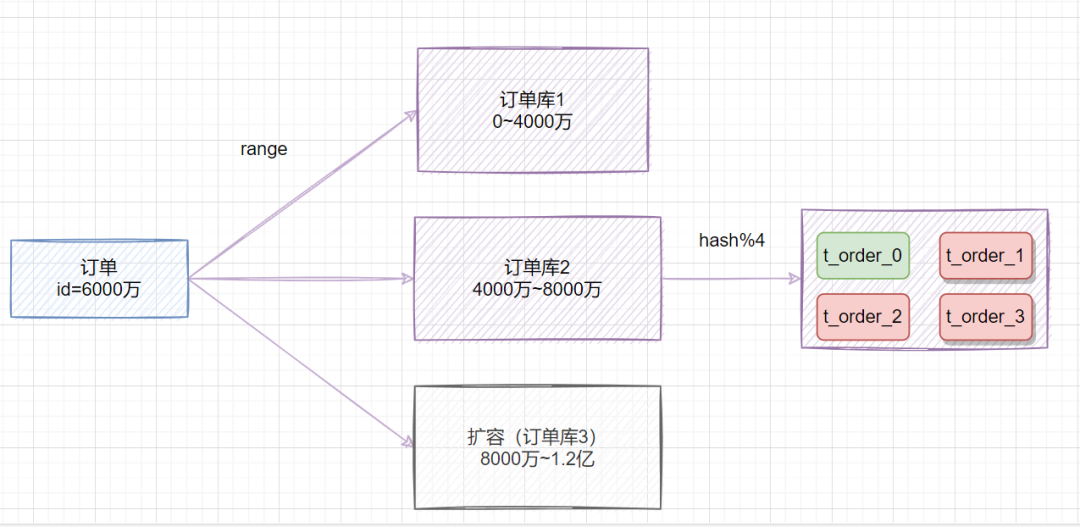
既然range存在熱點數(shù)據(jù)問題,hash取模擴容遷移數(shù)據(jù)比較困難,我們可以綜合兩種方案一起嘛,取之之長,棄之之短。
比較簡單的做法就是,在拆分庫的時候,我們可以先用range范圍方案,比如訂單id在0~4000萬的區(qū)間,劃分為訂單庫1;id在4000萬~8000萬的數(shù)據(jù),劃分到訂單庫2,將來要擴容時,id在8000萬~1.2億的數(shù)據(jù),劃分到訂單庫3。然后訂單庫內(nèi),再用hash取模的策略,把不同訂單劃分到不同的表。
4. 什么時候才考慮分庫分表呢?
4.1 什么時候分表?
如果你的系統(tǒng)處于快速發(fā)展時期,如果每天的訂單流水都新增幾十萬,并且,訂單表的查詢效率明變慢時,就需要規(guī)劃分庫分表了。一般B+樹索引高度是2~3層最佳,如果數(shù)據(jù)量千萬級別,可能高度就變4層了,數(shù)據(jù)量就會明顯變慢了。不過業(yè)界流傳,一般500萬數(shù)據(jù)就要考慮分表了。
4.2 什么時候分庫
業(yè)務(wù)發(fā)展很快,還是多個服務(wù)共享一個單體數(shù)據(jù)庫,數(shù)據(jù)庫成為了性能瓶頸,就需要考慮分庫了。比如訂單、用戶等,都可以抽取出來,新搞個應(yīng)用(其實就是微服務(wù)思想),并且拆分?jǐn)?shù)據(jù)庫(訂單庫、用戶庫)。
5. 分庫分表會導(dǎo)致哪些問題
分庫分表之后,也會存在一些問題:
事務(wù)問題
跨庫關(guān)聯(lián)
排序問題
分頁問題
分布式ID
5.1 事務(wù)問題
分庫分表后,假設(shè)兩個表在不同的數(shù)據(jù)庫,那么本地事務(wù)已經(jīng)無效啦,需要使用分布式事務(wù)了。
5.2 跨庫關(guān)聯(lián)
跨節(jié)點Join的問題:解決這一問題可以分兩次查詢實現(xiàn)
5.3 排序問題
跨節(jié)點的count,order by,group by以及聚合函數(shù)等問題:可以分別在各個節(jié)點上得到結(jié)果后在應(yīng)用程序端進行合并。
5.4 分頁問題
方案1:在個節(jié)點查到對應(yīng)結(jié)果后,在代碼端匯聚再分頁。
方案2:把分頁交給前端,前端傳來pageSize和pageNo,在各個數(shù)據(jù)庫節(jié)點都執(zhí)行分頁,然后匯聚總數(shù)量前端。這樣缺點就是會造成空查,如果分頁需要排序,也不好搞。
5.5 分布式ID
數(shù)據(jù)庫被切分后,不能再依賴數(shù)據(jù)庫自身的主鍵生成機制啦,最簡單可以考慮UUID,或者使用雪花算法生成分布式ID。
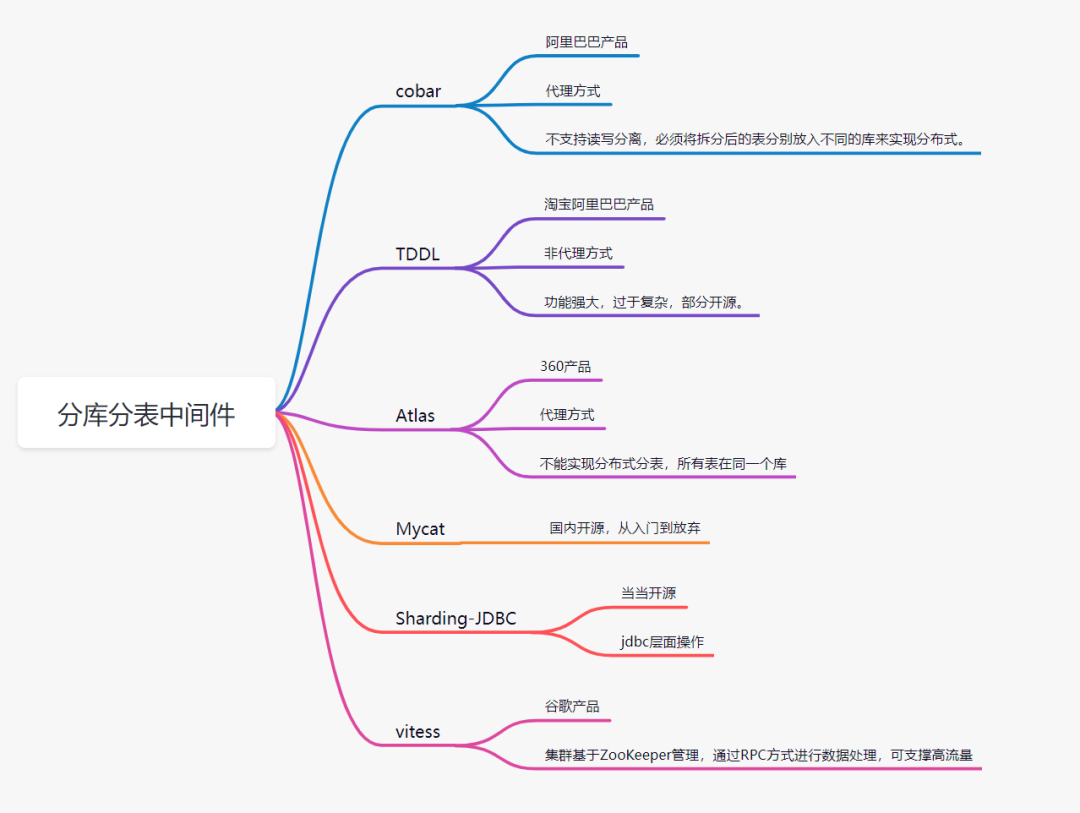
6. 分庫分表中間件
目前流行的分庫分表中間件比較多:
cobar
Mycat
Sharding-JDBC
Atlas
TDDL(淘寶)
vitess
往期熱門文章:
1、巨坑,常見的 update 語句很容易造成Bug 2、完爆90%的數(shù)據(jù)庫性能毛病! 3、Spring Boot性能太差,教你幾招輕松搞定 4、Fastjson 2 來了,性能繼續(xù)提升,還能再戰(zhàn)十年 5、笑死!程序員延壽指南開源了 6、用 Dubbo 傳輸文件?被老板一頓揍! 7、45 個 Git 經(jīng)典操作場景,專治不會合代碼! 8、@Transactional 注解失效的3種原因及解決辦法 9、小學(xué)生們在B站講算法,網(wǎng)友:我只會阿巴阿巴 10、Spring爆出比Log4j2還大的漏洞?