
Flink SQL高效Top-N方案的實(shí)現(xiàn)原理
Top-N是我們應(yīng)用Flink進(jìn)行業(yè)務(wù)開發(fā)時(shí)的常見場景,傳統(tǒng)的DataStream API已經(jīng)有了非常成熟的實(shí)現(xiàn)方案,如果換成Flink SQL,又該怎樣操作?好在Flink SQL官方文檔已經(jīng)給出了標(biāo)準(zhǔn)答案,我們只需要照抄就行,參考鏈接:
https://ci.apache.org/projects/flink/flink-docs-release-1.13/zh/docs/dev/table/sql/queries/overview/
其語法如下:
SELECT [column_list]
FROM (
SELECT [column_list],
ROW_NUMBER() OVER ([PARTITION BY col1[, col2...]]
ORDER BY col1 [asc|desc][, col2 [asc|desc]...]) AS rownum
FROM table_name)
WHERE rownum <= N [AND conditions]
看官可能已經(jīng)能夠在日常工作中熟練應(yīng)用這種查詢風(fēng)格了。那么,F(xiàn)link內(nèi)部是如何將它轉(zhuǎn)化成高效的執(zhí)行方案的呢?接下來基于最新的Flink 1.12版本稍微探究一下。
Logical Plan
使用EXPLAIN語句觀察示例查詢的執(zhí)行計(jì)劃(部分)如下:
EXPLAIN PLAN FOR SELECT * FROM (
SELECT *,
row_number() OVER(PARTITION BY merchandiseId ORDER BY totalQuantity DESC) AS rownum
FROM (
SELECT merchandiseId, sum(quantity) AS totalQuantity
FROM rtdw_dwd.kafka_order_done_log
GROUP BY merchandiseId
)
) WHERE rownum <= 10
== Abstract Syntax Tree ==
LogicalProject(merchandiseId=[$0], totalQuantity=[$1], rownum=[$2])
+- LogicalFilter(condition=[<=($2, 10)])
+- LogicalProject(merchandiseId=[$0], totalQuantity=[$1], rownum=[ROW_NUMBER() OVER (PARTITION BY $0 ORDER BY $1 DESC NULLS LAST)])
+- ...
== Optimized Logical Plan ==
Rank(strategy=[RetractStrategy], rankType=[ROW_NUMBER], rankRange=[rankStart=1, rankEnd=10], partitionBy=[merchandiseId], orderBy=[totalQuantity DESC], select=[merchandiseId, totalQuantity, w0$o0])
+- Exchange(distribution=[hash[merchandiseId]])
+- ...
== Physical Execution Plan ==
Stage 1 : Data Source
...
Stage 2 : Operator
...
Stage 4 : Operator
...
Stage 6 : Operator
content : Rank(strategy=[RetractStrategy], rankType=[ROW_NUMBER], rankRange=[rankStart=1, rankEnd=10], partitionBy=[merchandiseId], orderBy=[totalQuantity DESC], select=[merchandiseId, totalQuantity, w0$o0])
ship_strategy : HASH
由執(zhí)行計(jì)劃可知,row_number() OVER(PARTITION BY ...)子句在邏輯計(jì)劃階段被優(yōu)化成了名為Rank的RelNode(看官可參見Calcite的相關(guān)資料了解RelNode),可以用如下的簡圖說明。
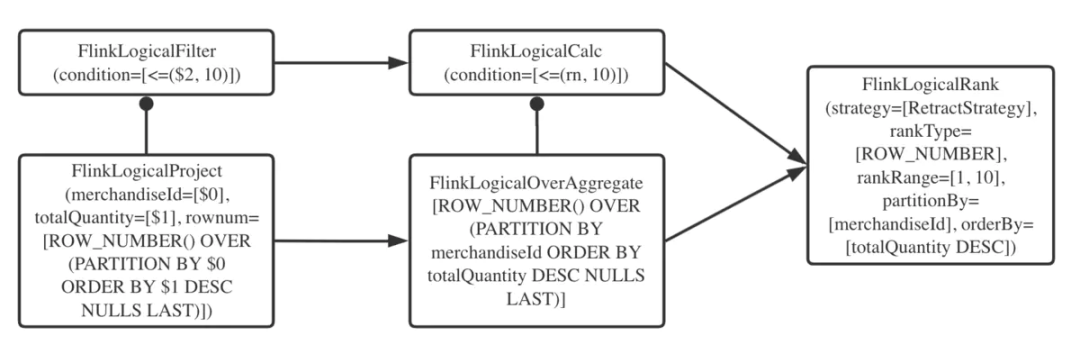
負(fù)責(zé)這個(gè)優(yōu)化的RelOptRule在Flink項(xiàng)目中名為FlinkLogicalRankRule。它將符合規(guī)則的開窗聚合操作(FlinkLogicalOverAggregate RelNode)和對排名的過濾操作(FlinkLogicalCalc RelNode)合并為FlinkLogicalRank。也就是說,只有嚴(yán)格符合上一節(jié)所述語法的查詢才能得到優(yōu)化。
FlinkLogicalRank節(jié)點(diǎn)會記錄以下主要信息:
partitionKey:分組鍵。
orderKey:排序鍵與排序規(guī)則。
rankType:排名函數(shù)的類型,即ROW_NUMBER、RANK或者DENSE_RANK。
rankRange:排名區(qū)間(即Top-N一詞中的N)。
strategy:Top-N結(jié)果的更新策略,目前有3種:
AppendFast:結(jié)果只追加,不更新;
Retract:類似于回撤流,結(jié)果會更新,前提是輸入數(shù)據(jù)沒有主鍵,或者主鍵與partitionKey不同;
UpdateFast:快速更新,前提是輸入數(shù)據(jù)有主鍵,且結(jié)果單調(diào)遞增/遞減,還要求orderKey的排序規(guī)則與結(jié)果的單調(diào)性相反(例:ORDER BY sum(quantity) DESC)。可見它的效率最高,但是也最苛刻。
outputRankNumber:是否輸出排名的序號,即在外層查詢中是否有SELECT rownum子句。顯然,如果不輸出序號,在排名發(fā)生變化時(shí)可以大大減少回撤輸出的數(shù)據(jù)量,降低Flink端的壓力,具體可參見官方文檔"No Ranking Output Optimization"一節(jié)。
Physical Plan
在流處理環(huán)境下,StreamPhysicalRankRule規(guī)則負(fù)責(zé)將FlinkLogicalRank邏輯節(jié)點(diǎn)轉(zhuǎn)換成StreamPhysicalRankRule物理節(jié)點(diǎn),并翻譯成物理執(zhí)行節(jié)點(diǎn)StreamExecRank。注意如果是分組Top-N(即有PARTITION BY子句),就會按照partitionKey的hash值分發(fā)到各個(gè)sub-task,否則會將并行度強(qiáng)制設(shè)為1,計(jì)算全局Top-N。另外從代碼可以讀出,Top-N語法目前僅支持ROW_NUMBER,暫時(shí)還不支持RANK和DENSE_RANK排名。
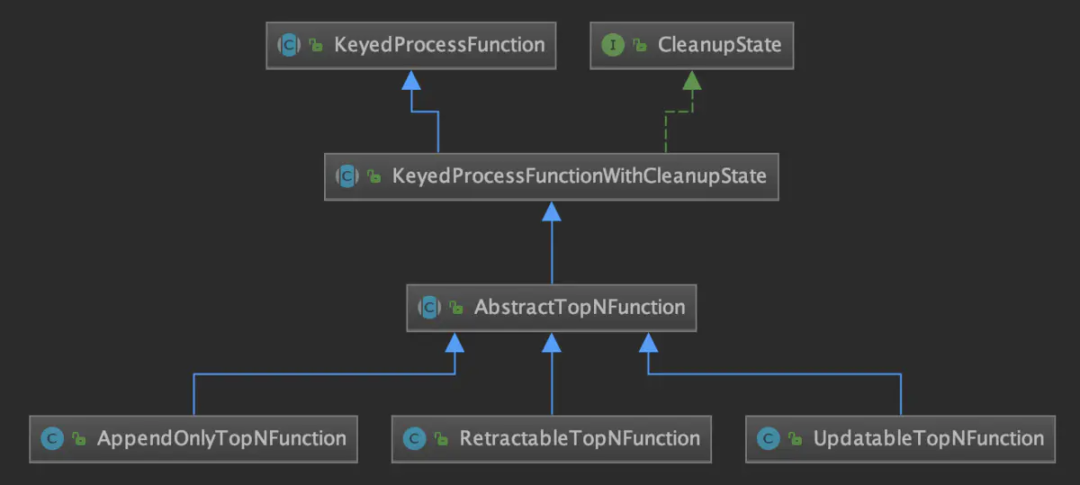
根據(jù)上文所述更新策略的不同,實(shí)際執(zhí)行時(shí)采用的ProcessFunction也不同,如下類圖所示。其中CleanupState接口表示支持空閑狀態(tài)保留時(shí)間(idle state retention time)特性。
以最常用到的RetractableTopNFunction為例,當(dāng)有一條累加數(shù)據(jù)到來時(shí),處理流程可以用如下的簡圖來說明。
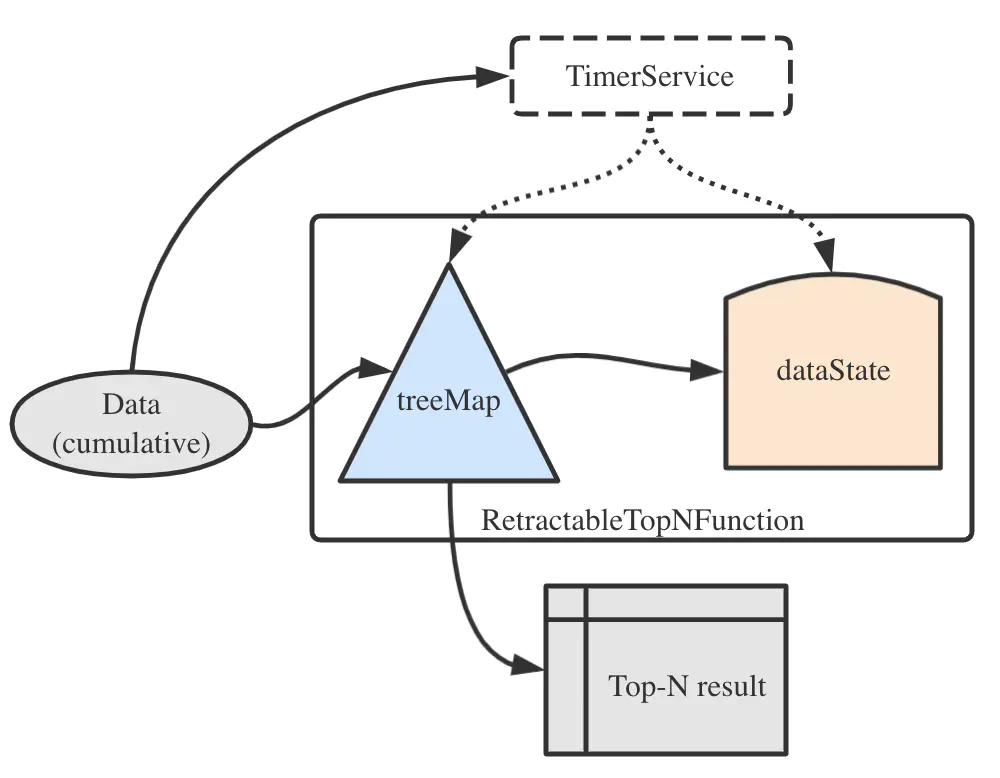
其中,dataState是MapState< RowData, List< RowData>>類型的狀態(tài),保存partitionKey與該key下面的流數(shù)據(jù),用于容錯(cuò)。而treeMap是ValueState< SortedMap< RowData, Long>>類型的狀態(tài),顧名思義,它其中維護(hù)了一個(gè)TreeMap,用于計(jì)數(shù)及輸出Top-N結(jié)果。至于這里為什么用了紅黑樹(TreeMap)而不是傳統(tǒng)的最大/最小堆(PriorityQueue),自然是因?yàn)榧t黑樹是對數(shù)復(fù)雜度的,相較于堆來說更適合Flink這種對時(shí)間敏感而對空間較不敏感的執(zhí)行環(huán)境。
另外,我們一定要記得啟用空閑狀態(tài)保留時(shí)間,這樣dataState和treeMap中的數(shù)據(jù)才不會永遠(yuǎn)積攢下去。不過空閑狀態(tài)的清理并非確定性的,所以如果要計(jì)算有時(shí)間維度的排行榜(如按天、按小時(shí)等),需要把時(shí)間維度也加入PARTITION BY子句,而不是將保留時(shí)間設(shè)為對應(yīng)的長度。
最后,在StreamExecRank中還提供了一個(gè)可配置的參數(shù)table.exec.topn.cache-size(默認(rèn)值10000),即Top-N緩存的大小。如果Top-N的規(guī)模比較大,適當(dāng)增加此值可以避免頻繁訪問狀態(tài),提高執(zhí)行效率。

八千里路云和月 | 從零到大數(shù)據(jù)專家學(xué)習(xí)路徑指南
我們在學(xué)習(xí)Flink的時(shí)候,到底在學(xué)習(xí)什么?
193篇文章暴揍Flink,這個(gè)合集你需要關(guān)注一下
Flink生產(chǎn)環(huán)境TOP難題與優(yōu)化,阿里巴巴藏經(jīng)閣YYDS
Flink CDC我吃定了耶穌也留不住他!| Flink CDC線上問題小盤點(diǎn)
我們在學(xué)習(xí)Spark的時(shí)候,到底在學(xué)習(xí)什么?
在所有Spark模塊中,我愿稱SparkSQL為最強(qiáng)!
硬剛Hive | 4萬字基礎(chǔ)調(diào)優(yōu)面試小總結(jié)
4萬字長文 | ClickHouse基礎(chǔ)&實(shí)踐&調(diào)優(yōu)全視角解析
【面試&個(gè)人成長】2021年過半,社招和校招的經(jīng)驗(yàn)之談
大數(shù)據(jù)方向另一個(gè)十年開啟 |《硬剛系列》第一版完結(jié)
我寫過的關(guān)于成長/面試/職場進(jìn)階的文章
當(dāng)我們在學(xué)習(xí)Hive的時(shí)候在學(xué)習(xí)什么?「硬剛Hive續(xù)集」
本文發(fā)自《大數(shù)據(jù)技術(shù)與架構(gòu)》公眾號,微信搜索:import_bigdata,歡迎關(guān)注。