
Flink 原理 | 深入解讀 Flink SQL 1.13
Flink SQL 1.13 概覽
核心 feature 解讀 重要改進解讀 Flink SQL 1.14 未來規(guī)劃 總結(jié)
 GitHub 地址
GitHub 地址 一、Flink SQL 1.13 概覽
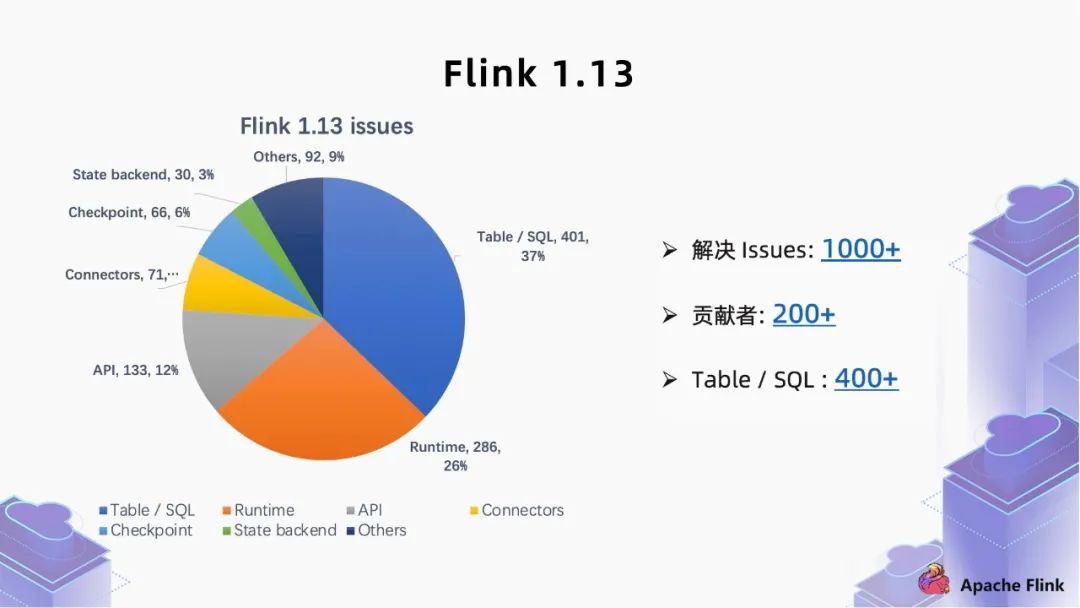
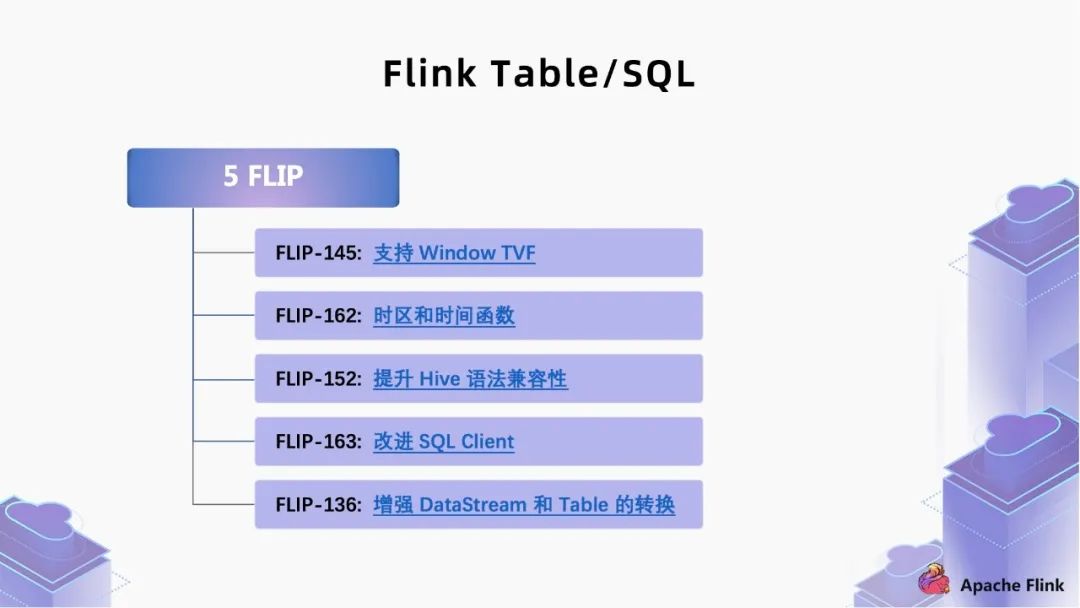
二、 核心 feature 解讀
1. FLIP-145:支持 Window TVF

■ 1.1 Window TVF 語法
SELECTTUMBLE_START(bidtime,INTERVAL '10' MINUTE),TUMBLE_END(bidtime,INTERVAL '10' MINUTE),TUMBLE_ROWTIME(bidtime,INTERVAL '10' MINUTE),SUM(price)FROM MyTableGROUP BY TUMBLE(bidtime,INTERVAL '10' MINUTE)
SELECT WINDOW_start,WINDOW_end,WINDOW_time,SUM(price)FROM Table(TUMBLE(Table myTable,DESCRIPTOR(biztime),INTERVAL '10' MINUTE))GROUP BY WINDOW_start,WINDOW_end

■ 1.2 Cumulate Window
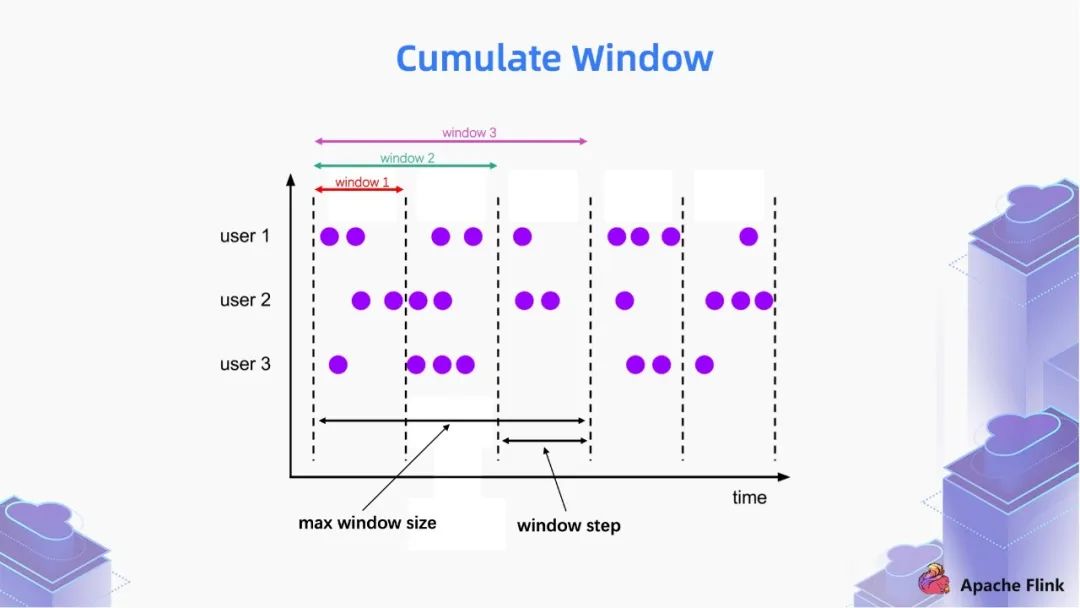
第一個 window 統(tǒng)計的是一個區(qū)間的數(shù)據(jù);
第二個 window 統(tǒng)計的是第一區(qū)間和第二個區(qū)間的數(shù)據(jù);
第三個 window 統(tǒng)計的是第一區(qū)間,第二個區(qū)間和第三個區(qū)間的數(shù)據(jù)。

INSERT INTO cumulative_UVSELECT date_str,MAX(time_str),COUNT(DISTINCT user_id) as UVFROM (SELECTDATE_FORMAT(ts,'yyyy-MM-dd') as date_str,SUBSTR(DATE_FORMAT(ts,'HH:mm'),1,4) || '0' as time_str,user_idFROM user_behavior)GROUP BY date_str
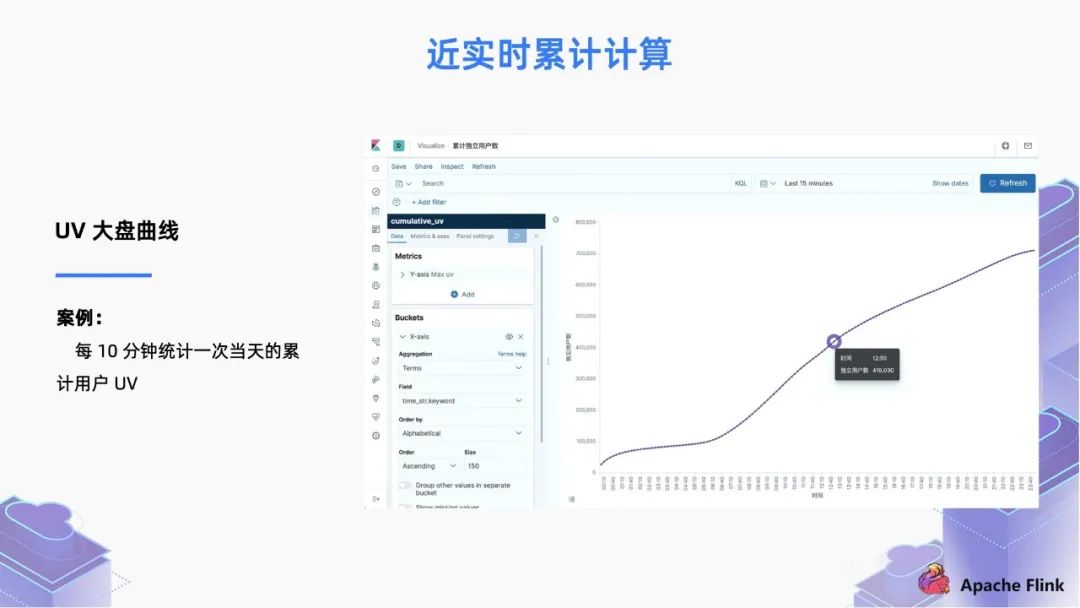
1.13 版本前的寫法有很多缺點,首先這個聚合操作是每條記錄都會計算一次。其次,在追逆數(shù)據(jù)的時候,消費堆積的數(shù)據(jù)時,UV 大盤的曲線就會跳變。
在 1.13 版本支持了 TVF 寫法,基于 cumulate window,我們可以修改為下面的寫法,將每條數(shù)據(jù)按照 Event Time 精確地分到每個 Window 里面, 每個窗口的計算通過 watermark 觸發(fā),即使在追數(shù)據(jù)場景中也不會跳變。
INSERT INTO cumulative_UVSELECT WINDOW_end,COUNT(DISTINCT user_id) as UVFROM Table(CUMULATE(Table user_behavior,DESCRIPTOR(ts),INTERVAL '10' MINUTES,INTERVAL '1' DAY)))GROUP BY WINDOW_start,WINDOW_end
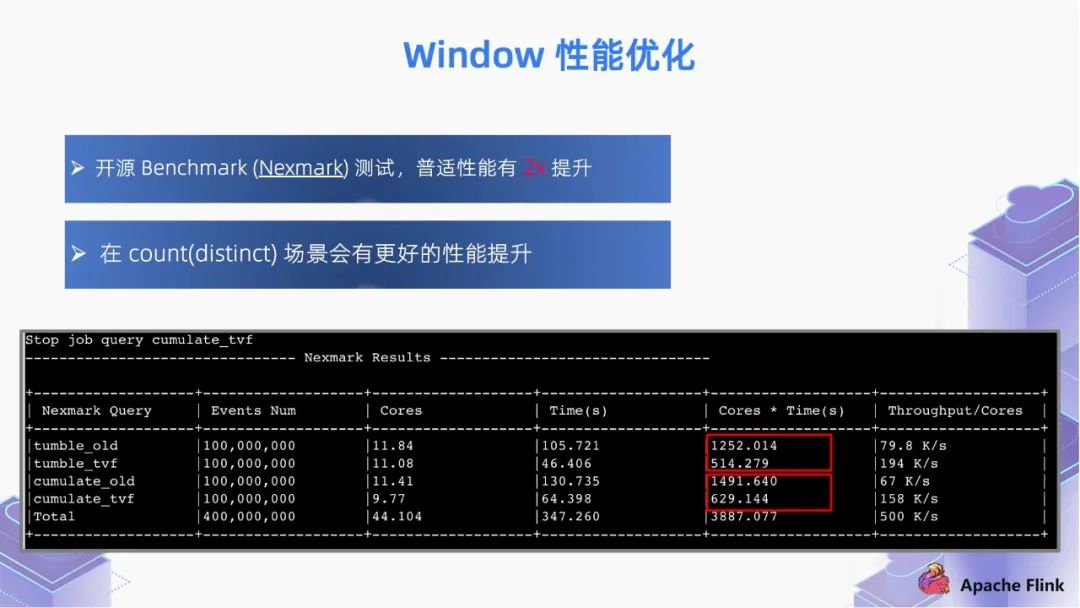
■ 1.3 Window 性能優(yōu)化
內(nèi)存優(yōu)化:通過內(nèi)存預(yù)分配,緩存 window 的數(shù)據(jù),通過 window watermark 觸發(fā)計算,通過申請一些內(nèi)存 buffer 避免高頻的訪問 state;
切片優(yōu)化:將 window 切片,盡可能復(fù)用已計算結(jié)果,如 hop window,cumulate window。計算過的分片數(shù)據(jù)無需再次計算,只需對切片的計算結(jié)果進行復(fù)用;
算子優(yōu)化:window 算子支持 local-global 優(yōu)化;同時支持 count(distinct) 自動解熱點優(yōu)化;
遲到數(shù)據(jù):支持將遲到數(shù)據(jù)計算到后續(xù)分片,保證數(shù)據(jù)準(zhǔn)確性。

■ 1.4 多維數(shù)據(jù)分析


2. FLIP-162:時區(qū)和時間函數(shù)
■ 2.1 時區(qū)問題分析
PROCTIME() 函數(shù)應(yīng)該考慮時區(qū),但未考慮時區(qū);
CURRENT_TIMESTAMP/CURRENT_TIME/CURRENT_DATE/NOW() 函數(shù)未考慮時區(qū);
Flink 的時間屬性,只支持定義在 TIMESTAMP 這種數(shù)據(jù)類型上面,這個類型是無時區(qū)的,TIMESTAMP 類型不考慮時區(qū),但用戶希望是本地時區(qū)的時間。
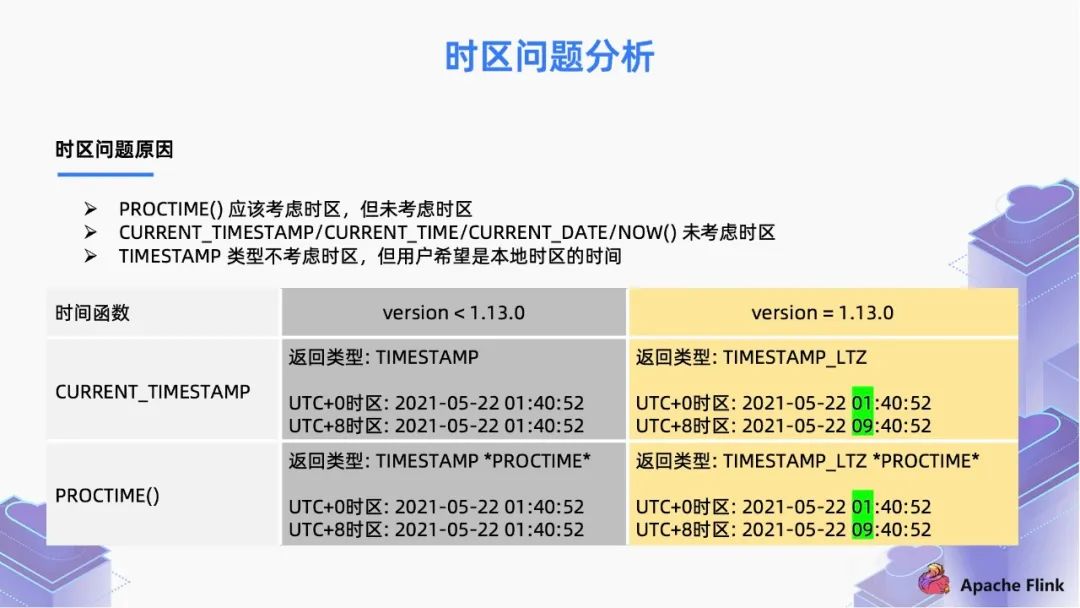
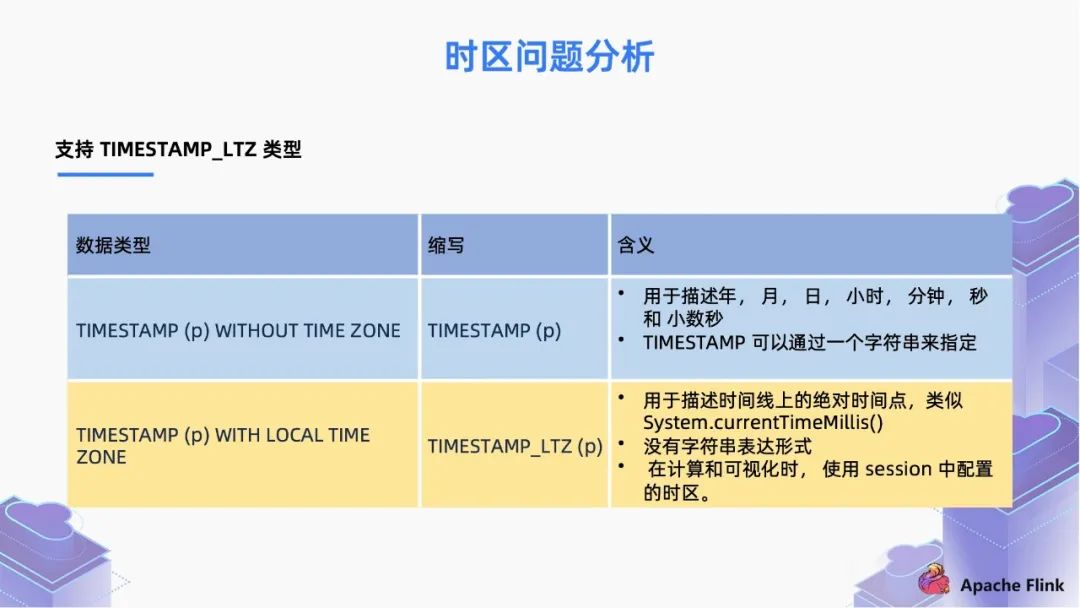
如果我們配置使用 TIMESTAMP,它可以是字符串類型的。用戶不管是從英國還是中國時區(qū)來觀察,這個值都是一樣的;
但是對于 TIMSTAMP_TLZ 來說,它的來源就是一個 Long 值,表示從時間原點流逝過的時間。同一時刻,從時間原點流逝的時間在所有時區(qū)都是相同的,所以這個 Long 值是絕對時間的概念。當(dāng)我們在不同的時區(qū)去觀察這個值,我們會用本地的時區(qū)去解釋成 “年-月-日-時-分-秒” 的可讀格式,這就是 TIMSTAMP_TLZ 類型,TIMESTAMP_LTZ 類型也更加符合用戶在不同時區(qū)下的使用習(xí)慣。

■ 2.2 時間函數(shù)糾正
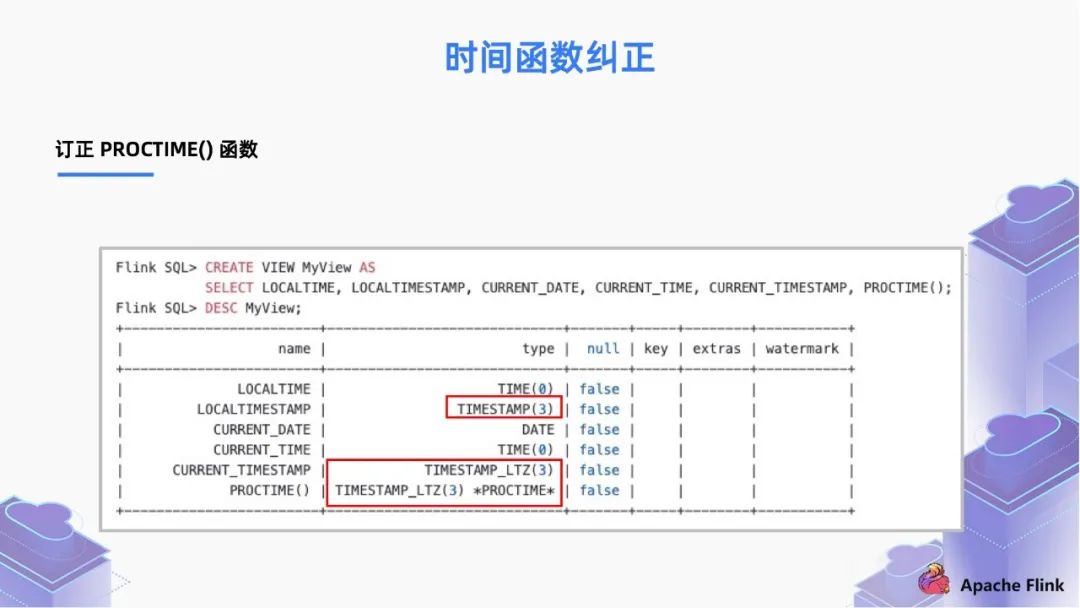
在 1.13 版本之前,它總是返回 UTC 的 TIMESTAMP;
而現(xiàn)在,我們把返回類型變?yōu)榱?TIMESTAMP_LTZ。
PROCTIME 除了表示函數(shù)之外,也可以表示時間屬性的標(biāo)記。

在 1.13 版本之前,如果我們需要做按天的 window 操作,你需要手動解決時區(qū)問題,去做一些 8 小時的偏移然后再減回去;
在 FLIP-162 中我們解決了這個問題,現(xiàn)在用戶使用的時候十分簡單,只需要聲明 proctime 屬性,因為 PROCTIME() 函數(shù)的返回值是TIMESTAMP_LTZ,所以結(jié)果是會考慮本地的時區(qū)。下圖的例子顯示了在不同的時區(qū)下,proctime 屬性的 window 的聚合是按照本地時區(qū)進行的。

在流模式中是 per-record 計算,即每條數(shù)據(jù)都計算一次;
在 Batch 模式是 query-start 計算,即在作業(yè)開始前計算一次。例如我們常用的一些 Batch 計算引擎,如 Hive 也是在每一個批開始前計算一次。

■ 2.3 時間類型使用
當(dāng)作業(yè)的上游源數(shù)據(jù)包含了字符串的時間(如:2021-4-15 14:00:00)這樣的場景,直接聲明為 TIMESTAMP 然后把 Event time 定義在上面即可,窗口在計算的時候會基于時間字符串進行切分,最終會計算出符合你實際想要的預(yù)想結(jié)果;

當(dāng)上游數(shù)據(jù)源的打點時間屬于 long 值,表示的是一個絕對時間的含義。在 1.13 版本你可以把 Event time 定義在 TIMESTAMP_LTZ 上面。此時定義在 TIMESTAMP_LTZ 類型上的各種 WINDOW 聚合,都能夠自動的解決 8 小時的時區(qū)偏移問題,無需按照之前的 SQL 寫法額外做時區(qū)的修改和訂正。

■ 2.4 夏令時支持

三、重要改進解讀
1. FLIP-152:提升 Hive 語法兼容性



2. FLIP-163:改進 SQL Client

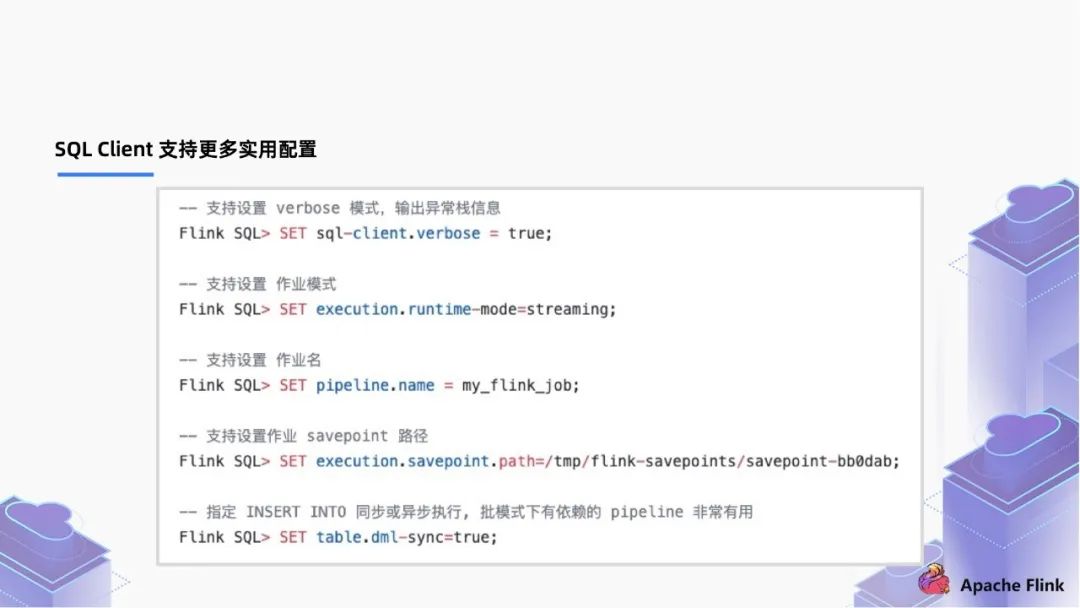
通過 SET SQL-client.verbose = true , 開啟 verbose,通過開啟 verbose 打印整個信息,相對以前只輸出一句話更加容易追蹤錯誤信息; 通過 SET execution.runtime-mode=streaming / batch 支持設(shè)置批/流作業(yè)模式; 通過 SET pipline.name=my_Flink_job 設(shè)置作業(yè)名稱; 通過 SET execution.savepoint.path=/tmp/Flink-savepoints/savepoint-bb0dab 設(shè)置作業(yè) savepoint 路徑; 對于有依賴的多個作業(yè),通過 SET Table.dml-sync=true 去選擇是否異步執(zhí)行,例如離線作業(yè),作業(yè) a 跑完才能跑作業(yè) b,通過設(shè)置為 true 實現(xiàn)執(zhí)行有依賴關(guān)系的 pipeline 調(diào)度。
4. 同時支持 STATEMENT SET語法:

在 1.13 版本之前需要啟動 2 個 query 去完成這個作業(yè); 在 1.13 版本,我們可以把這些放到一個 statement 里面,以一個作業(yè)的方式去執(zhí)行,能夠?qū)崿F(xiàn)節(jié)點的復(fù)用,節(jié)約資源。
3. FLIP-136:增強 DataStream 和 Table 的轉(zhuǎn)換
支持 DataStream 和 Table 轉(zhuǎn)換時傳遞 EVENT TIME 和 WATERMARK;
Table Table = TableEnv.fromDataStream(dataStream,Schema.newBuilder().columnByMetadata("rowtime","TIMESTMP(3)").watermark("rowtime","SOURCE_WATERMARK()").build());)
支持 Changelog 數(shù)據(jù)流在 Table 和 DataStream 間相互轉(zhuǎn)換。
//DATASTREAM 轉(zhuǎn) TableStreamTableEnvironment.fromChangelogStream(DataStream<ROW>): TableStreamTableEnvironment.fromChangelogStream(DataStream<ROW>,Schema): Table//Table 轉(zhuǎn) DATASTREAMStreamTableEnvironment.toChangelogStream(Table): DataStream<ROW>StreamTableEnvironment.toChangelogStream(Table,Schema): DataStream<ROW>
四、Flink SQL 1.14 未來規(guī)劃
1.14 版本主要有以下幾點規(guī)劃:
刪除 Legacy Planner:從 Flink 1.9 開始,在阿里貢獻了 Blink-Planner 之后,很多一些新的 Feature 已經(jīng)基于此 Blink Planner 進行開發(fā),以前舊的 Legacy Planner 會徹底刪除;
完善 Window TVF:支持 session window,支持 window TVF 的 allow -lateness 等;
提升 Schema Handling:全鏈路的 Schema 處理能力以及關(guān)鍵校驗的提升;
增強 Flink CDC 支持:增強對上游 CDC 系統(tǒng)的集成能力,F(xiàn)link SQL 內(nèi)更多的算子支持 CDC 數(shù)據(jù)流。
五、總結(jié)
本文詳細解讀了 Flink SQL 1.13 的核心功能和重要改進。
支持 Window TVF;
系統(tǒng)地解決時區(qū)和時間函數(shù)問題;
提升 Hive 和 Flink 的兼容性;
改進 SQL Client;
增強 DataStream 和 Table 的轉(zhuǎn)換。
更多 Flink 相關(guān)技術(shù)交流,可掃碼加入社區(qū)釘釘大群~
 戳我,立即報名!
戳我,立即報名!