
最新NLP賽事實(shí)踐總結(jié)!
賽題介紹
國(guó)內(nèi)車(chē)企為提升產(chǎn)品競(jìng)爭(zhēng)力、更好走向海外市場(chǎng),提出了海外市場(chǎng)智能交互的需求。但世界各國(guó)在“數(shù)據(jù)安全”上有著嚴(yán)格法律約束,要做好海外智能化交互,本土企業(yè)面臨的最大挑戰(zhàn)是數(shù)據(jù)缺少。本賽題要求選手通過(guò)NLP相關(guān)人工智能算法來(lái)實(shí)現(xiàn)汽車(chē)領(lǐng)域多語(yǔ)種遷移學(xué)習(xí)。
賽事地址:https://challenge.xfyun.cn/topic/info?type=car-multilingual&ch=ds22-dw-gzh01
賽事任務(wù)
本次遷移學(xué)習(xí)任務(wù)中,訊飛智能汽車(chē)BU將提供較多的車(chē)內(nèi)人機(jī)交互中文語(yǔ)料,以及少量的中英、中日、中阿平行語(yǔ)料作為訓(xùn)練集。
參賽選手通過(guò)提供的數(shù)據(jù)構(gòu)建模型,進(jìn)行意圖分類(lèi)及關(guān)鍵信息抽取任務(wù),最終使用英語(yǔ)、日語(yǔ)、阿拉伯語(yǔ)進(jìn)行測(cè)試評(píng)判。
1.初賽
- 訓(xùn)練集:中文語(yǔ)料30000條,中英平行語(yǔ)料1000條,中日平行語(yǔ)料1000條
- 測(cè)試集A:英文語(yǔ)料500條,日文語(yǔ)料500條
- 測(cè)試集B:英文語(yǔ)料500條,日文語(yǔ)料500條
2.復(fù)賽
- 訓(xùn)練集:中文語(yǔ)料同初賽,中阿拉伯平行語(yǔ)料1000條
- 測(cè)試集A:阿拉伯文語(yǔ)料500條
- 測(cè)試集B:阿拉伯文語(yǔ)料500條
賽題數(shù)據(jù)
本次比賽為參賽選手提供三類(lèi)車(chē)內(nèi)交互功能語(yǔ)料,其中包括命令控制類(lèi)、導(dǎo)航類(lèi)、音樂(lè)類(lèi)。
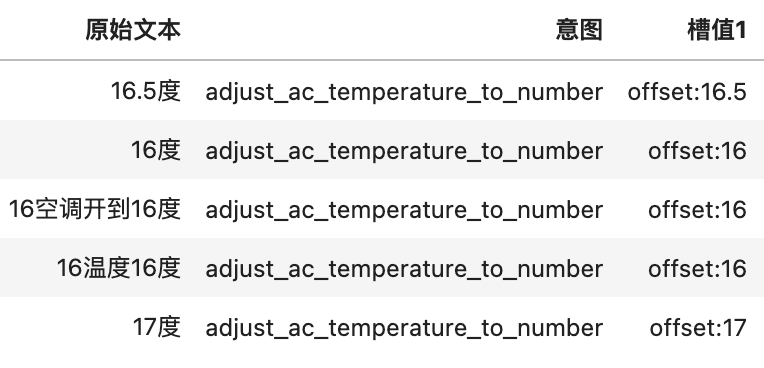
較多的中文語(yǔ)料和較少的多語(yǔ)種平行語(yǔ)料均帶有意圖分類(lèi)和關(guān)鍵信息,選手需充分利用所提供數(shù)據(jù),在英、日、阿拉伯語(yǔ)料的意圖分類(lèi)和關(guān)鍵信息抽取任務(wù)上取得較好效果。數(shù)據(jù)所含標(biāo)簽種類(lèi)及取值類(lèi)型如下表所示。
| 變量 | 數(shù)值格式 | 解釋 |
|---|---|---|
| intent | string | 整句意圖標(biāo)簽 |
| device | string | 操作設(shè)備名稱(chēng)標(biāo)簽 |
| mode | string | 操作設(shè)備模式標(biāo)簽 |
| offset | string | 操作設(shè)備調(diào)節(jié)量標(biāo)簽 |
| endloc | string | 目的地標(biāo)簽 |
| landmark | string | 周邊搜索參照標(biāo)簽 |
| singer | string | 歌手 |
| song | string | 歌曲 |
評(píng)估指標(biāo)
本模型依據(jù)提交的結(jié)果文件,采用accuracy進(jìn)行評(píng)價(jià)。
注:
每條數(shù)據(jù)的關(guān)鍵信息多抽或者少抽均算錯(cuò)誤,最終得分取意圖分類(lèi)和關(guān)鍵信息抽取的平均值; 預(yù)測(cè)過(guò)程中不得進(jìn)行語(yǔ)種轉(zhuǎn)換,必須使用測(cè)試集提供的語(yǔ)種直接進(jìn)行意圖分類(lèi)和關(guān)鍵信息抽取任務(wù)。
解題思路
意圖分類(lèi)為典型的文本任務(wù); 信息抽取為實(shí)體抽取任務(wù);
賽題任務(wù)有以下特點(diǎn):
多語(yǔ)種文本,需要考慮多語(yǔ)種BERT; 短文本,可以嘗試進(jìn)行關(guān)鍵詞匹配;
步驟1:導(dǎo)入庫(kù)
import pandas as pd # 讀取文件
import numpy as np # 數(shù)值計(jì)算
import nagisa # 日文分詞
from sklearn.feature_extraction.text import TfidfVectorizer # 文本特征提取
from sklearn.linear_model import LogisticRegression # 邏輯回歸
from sklearn.pipeline import make_pipeline # 組合流水線
步驟2:讀取數(shù)據(jù)
# 讀取數(shù)據(jù)
train_cn = pd.read_excel('汽車(chē)領(lǐng)域多語(yǔ)種遷移學(xué)習(xí)挑戰(zhàn)賽初賽訓(xùn)練集/中文_trian.xlsx')
train_ja = pd.read_excel('汽車(chē)領(lǐng)域多語(yǔ)種遷移學(xué)習(xí)挑戰(zhàn)賽初賽訓(xùn)練集/日語(yǔ)_train.xlsx')
train_en = pd.read_excel('汽車(chē)領(lǐng)域多語(yǔ)種遷移學(xué)習(xí)挑戰(zhàn)賽初賽訓(xùn)練集/英文_train.xlsx')
test_ja = pd.read_excel('testA.xlsx', sheet_name='日語(yǔ)_testA')
test_en = pd.read_excel('testA.xlsx', sheet_name='英文_testA')
步驟3:文本分詞
# 文本分詞
train_ja['words'] = train_ja['原始文本'].apply(lambda x: ' '.join(nagisa.tagging(x).words))
train_en['words'] = train_en['原始文本'].apply(lambda x: x.lower())
test_ja['words'] = test_ja['原始文本'].apply(lambda x: ' '.join(nagisa.tagging(x).words))
test_en['words'] = test_en['原始文本'].apply(lambda x: x.lower())
步驟4:構(gòu)建模型
# 訓(xùn)練TFIDF和邏輯回歸
pipline = make_pipeline(
TfidfVectorizer(),
LogisticRegression()
)
pipline.fit(
train_ja['words'].tolist() + train_en['words'].tolist(),
train_ja['意圖'].tolist() + train_en['意圖'].tolist()
)
# 模型預(yù)測(cè)
test_ja['意圖'] = pipline.predict(test_ja['words'])
test_en['意圖'] = pipline.predict(test_en['words'])
test_en['槽值1'] = np.nan
test_en['槽值2'] = np.nan
test_ja['槽值1'] = np.nan
test_ja['槽值2'] = np.nan
# 寫(xiě)入提交文件
writer = pd.ExcelWriter('submit.xlsx')
test_en.drop(['words'], axis=1).to_excel(writer, sheet_name='英文_testA', index=None)
test_ja.drop(['words'], axis=1).to_excel(writer, sheet_name='日語(yǔ)_testA', index=None)
writer.save()
writer.close()整理不易,點(diǎn)贊三連↓