
使用 Pytorch 進(jìn)行多類圖像分類
點(diǎn)擊上方“小白學(xué)視覺(jué)”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)


此數(shù)據(jù)包含大小為150x150、分布在6個(gè)類別下的約25k圖像。
{'建筑物':0,'森林':1,'冰川':2,'山':3,'海':4,'街道':5}
訓(xùn)練、測(cè)試和預(yù)測(cè)數(shù)據(jù)在每個(gè) zip 文件中分開(kāi)。訓(xùn)練中有大約 14k 圖像,測(cè)試中有 3k,預(yù)測(cè)中有 7k。
這是一個(gè)多類圖像分類問(wèn)題,目標(biāo)是將這些圖像以更高的精度分類到正確的類別中。
基本理解python、pytorch和分類問(wèn)題。
做一些探索性數(shù)據(jù)分析 (EDA) 來(lái)分析和可視化數(shù)據(jù),以便更好地理解。
定義一些實(shí)用函數(shù)來(lái)執(zhí)行各種任務(wù),從而可以保持代碼的模塊化。
加載各種預(yù)先訓(xùn)練的模型并根據(jù)我們的問(wèn)題對(duì)它們進(jìn)行微調(diào)。
為每個(gè)模型嘗試各種超參數(shù)。
保存模型的權(quán)重并記錄指標(biāo)。
結(jié)論
未來(lái)的工作
讓我們深入研究代碼!
1. 庫(kù)
首先,導(dǎo)入所有重要的庫(kù)。
import osimport torchimport tarfileimport torchvisionimport torch.nn as nnfrom PIL import Imageimport matplotlib.pyplot as pltimport torch.nn.functional as Ffrom torchvision import transformsfrom torchvision.utils import make_gridfrom torch.utils.data import random_splitfrom torchvision.transforms import ToTensorfrom torchvision.datasets import ImageFolderfrom torch.utils.data import Dataset, DataLoaderfrom torchvision.datasets.utils import download_url
2. 圖片文件夾到數(shù)據(jù)集
由于我們的數(shù)據(jù)存在于文件夾中,因此讓我們將它們轉(zhuǎn)換為數(shù)據(jù)集。
transform_train = transforms.Compose([transforms.Resize((150,150)), #becasue vgg takes 150*150transforms.RandomHorizontalFlip(),transforms.RandomVerticalFlip(),transforms.ToTensor(),transforms.Normalize((.5, .5, .5), (.5, .5, .5))])#Augmentation is not done for test/validation data.transform_test = transforms.Compose([transforms.Resize((150,150)), #becasue vgg takes 150*150transforms.ToTensor(),transforms.Normalize((.5, .5, .5), (.5, .5, .5))])
train_ds = ImageFolder('../input/intel-image-classification/seg_train/seg_train', transform=transform_train)test_ds = ImageFolder('../input/intel-image-classification/seg_test/seg_test', transform=transform_test)pred_ds = ImageFolder('/kaggle/input/intel-image-classification/seg_pred/', transform=transform_test)
3. 探索性數(shù)據(jù)分析 (EDA)
作為 EDA 的一部分,讓我們?cè)谶@里回答一些問(wèn)題,但這里并未廣泛涵蓋 EDA。
讓我們繼續(xù)回答一些問(wèn)題。
a) 數(shù)據(jù)集中有多少?gòu)垐D片?
回答 :

這意味著有 14034 張圖像用于訓(xùn)練,3000 張圖像用于測(cè)試/驗(yàn)證,7301 張圖像用于預(yù)測(cè)。
b) 你能告訴我圖像的大小嗎?
回答:

這意味著圖像的大小為 150 * 150,具有三個(gè)通道,其標(biāo)簽為 0。
c) 你能打印一批訓(xùn)練圖像嗎?
回答:此問(wèn)題的答案將在創(chuàng)建數(shù)據(jù)加載器后給出,因此請(qǐng)等待并繼續(xù)下面給出的下一個(gè)標(biāo)題。
4. 創(chuàng)建數(shù)據(jù)加載器
為將批量加載數(shù)據(jù)的所有數(shù)據(jù)集創(chuàng)建一個(gè)數(shù)據(jù)加載器。
batch_size=128train_dl = DataLoader(train_ds, batch_size, shuffle=True, num_workers=4, pin_memory=True)val_dl = DataLoader(test_ds, batch_size, num_workers=4, pin_memory=True)pred_dl = DataLoadebatch_size=128train_dl = DataLoader(train_ds, batch_size, shuffle=True, num_workers=4, pin_memory=True)val_dl = DataLoader(test_ds, batch_size, num_workers=4, pin_memory=True)pred_dl = DataLoader(pred_ds, batch_size, num_workers=4, pin_memory=True)r(pred_ds, batch_size, num_workers=4, pin_memory=True)
batch_size=128train_dl = DataLoader(train_ds, batch_size, shuffle=True, num_workers=4, pin_memory=True)val_dl = DataLoader(test_ds, batch_size, num_workers=4, pin_memory=True)pred_dl = DataLoader(pred_ds, batch_size, num_workers=4, pin_memory=True)
5. 生成類名
雖然可以通過(guò)查看文件夾名稱手動(dòng)列出類名稱,但作為一個(gè)好習(xí)慣,我們應(yīng)該為此編寫(xiě)代碼。

6. 創(chuàng)建精度函數(shù)
定義一個(gè)函數(shù)來(lái)計(jì)算我們模型的準(zhǔn)確性。

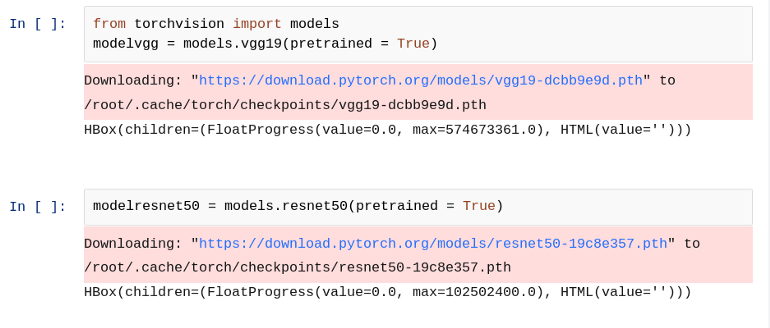
7. 下載預(yù)訓(xùn)練模型
下載我們選擇的任何預(yù)訓(xùn)練模型,可以根據(jù)需要自由選擇任何模型,這里我選擇了兩個(gè)模型 VGG 和 ResNet50 來(lái)做實(shí)驗(yàn)。讓我們下載模型。
8. 凍結(jié)所有圖層
下載模型后,可以根據(jù)需要訓(xùn)練整個(gè)架構(gòu)。一種可能的策略是我們可以訓(xùn)練預(yù)訓(xùn)練模型的某些層,而一些層則不能。在這里,我選擇了這樣一種策略,即在新輸入的模型訓(xùn)練期間不必訓(xùn)練任何現(xiàn)有層,因此通過(guò)將模型的每個(gè)參數(shù)的 requires_grad 設(shè)置為 False 來(lái)保持所有層凍結(jié)。

9. 添加我們自己的分類器層
現(xiàn)在要將下載的預(yù)訓(xùn)練模型用作我們自己的分類器,我們必須對(duì)其進(jìn)行一些更改,因?yàn)槲覀円A(yù)測(cè)的類數(shù)可能與模型已訓(xùn)練的類數(shù)不同。另一個(gè)原因是有可能(幾乎在所有情況下)模型已經(jīng)過(guò)訓(xùn)練以檢測(cè)某些特定類型的事物,但我們想使用該模型檢測(cè)不同的事物。
所以模型的一些變化是可以有我們自己的分類層,它會(huì)根據(jù)我們的要求進(jìn)行分類。因此,我們想在預(yù)訓(xùn)練模型中添加什么架構(gòu)完全取決于我們自己。在這里,我選擇了人們遵循的最常見(jiàn)的策略,即用我們自己的分類層替換模型的最后一層。
另一個(gè)策略是我們可以從最后一個(gè)圖層刪除一些層,例如我們刪除了最后三層并添加了我們自己的分類層,為了更好地理解,請(qǐng)參見(jiàn)下文。
預(yù)訓(xùn)練的VGG 模型:
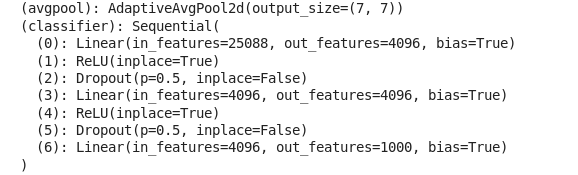
上圖中顯示了 VGG 模型的最后兩層(avgpool 和 classsifer)。我們可以看到這個(gè)預(yù)訓(xùn)練模型是為對(duì)1000個(gè)類進(jìn)行分類而設(shè)計(jì)的,但是我們只需要 6 類分類,所以稍微改變一下這個(gè)模型。
替換最后一層后的新模型:

我已經(jīng)用我自己的分類器層替換了分類器層,因?yàn)槲覀兛梢钥吹接?6 個(gè) out_features,這意味著 6 個(gè)輸出,但在預(yù)訓(xùn)練模型中還有一些其他的數(shù)字,因?yàn)槟P徒?jīng)過(guò)訓(xùn)練,可以對(duì)這些數(shù)量的類進(jìn)行分類。
小伙伴們可能會(huì)問(wèn)為什么分類器層內(nèi)部的一些 in-features 和 out_features 發(fā)生了變化?
所以讓我們回答這個(gè)。我們可以為這些選擇任何數(shù)字,但請(qǐng)記住,第一個(gè)線性層內(nèi)的 in_features 必須相同,即 25088,因?yàn)樗遣坏酶牡妮敵鰧訑?shù)。
與 ResNet50 相同:
預(yù)訓(xùn)練模型(最后兩層)


請(qǐng)注意,第一個(gè)線性層 層中的 in_features 與 2048 相同,而最后一個(gè) 線性層層中的 out_features 為 6。除了上面提到的,其他任何 in_features 和 out_features 都可以根據(jù)我們的選擇進(jìn)行更改。
10.創(chuàng)建基類
創(chuàng)建一個(gè)基類,其中將包含將來(lái)要使用的所有有用函數(shù),這樣做只是為了確保 DRY的概念,因?yàn)檫@兩個(gè)模型都需要該類中的函數(shù),如果不在這里實(shí)現(xiàn),我們必須分別為每個(gè)模型定義這些函數(shù),這將違反DRY概念。
class ImageClassificationBase(nn.Module):def training_step(self, batch):images, labels = batchout = self(images) # Generate predictionsloss = F.cross_entropy(out, labels) # Calculate lossreturn lossdef validation_step(self, batch):images, labels = batchout = self(images) # Generate predictionsloss = F.cross_entropy(out, labels) # Calculate lossacc = accuracy(out, labels) # Calculate accuracyreturn {'val_loss': loss.detach(), 'val_acc': acc}def validation_epoch_end(self, outputs):batch_losses = [x['val_loss'] for x in outputs]epoch_loss = torch.stack(batch_losses).mean() # Combine lossesbatch_accs = [x['val_acc'] for x in outputs]epoch_acc = torch.stack(batch_accs).mean() # Combine accuraciesreturn {'val_loss': epoch_loss.item(), 'val_acc': epoch_acc.item()}def epoch_end(self, epoch, result):print("Epoch [{}], train_loss: {:.4f}, val_loss: {:.4f}, val_acc: {:.4f}".format(epoch, result['train_loss'], result['val_loss'], result['val_acc']))
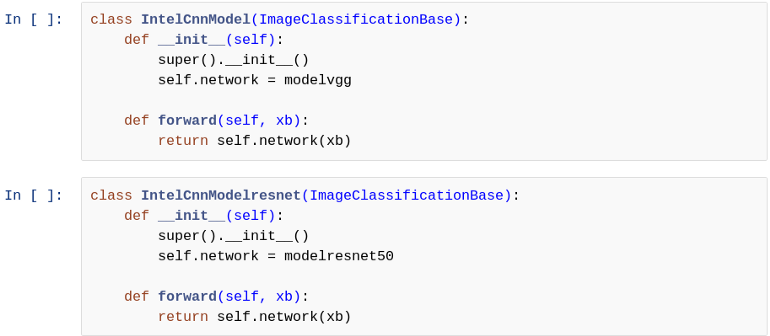
11.繼承基類
通過(guò)繼承基類為每個(gè)模型創(chuàng)建一個(gè)類,該類具有任何模型訓(xùn)練期間所需的所有有用函數(shù)。
12.創(chuàng)建繼承類的對(duì)象
實(shí)例化該類

13. 檢查設(shè)備
創(chuàng)建一個(gè)函數(shù)來(lái)檢查當(dāng)前存在哪個(gè)設(shè)備。如果存在 GPU,則選擇它,否則選擇 CPU 作為工作設(shè)備。

在這里,我使用 GPU,因此它將設(shè)備類型顯示為 CUDA。
14. 移動(dòng)到設(shè)備
創(chuàng)建一個(gè)可以將張量和模型移動(dòng)到特定設(shè)備的函數(shù)。

15. 設(shè)備數(shù)據(jù)加載器
創(chuàng)建DeviceDataLoader類,該類包裝DataLoader以將數(shù)據(jù)移動(dòng)到特定設(shè)備,然后可以從該設(shè)備生成一批數(shù)據(jù)。


在這里我們可以看到張量和兩個(gè)模型都已發(fā)送到當(dāng)前存在的適當(dāng)設(shè)備。
16.評(píng)估和擬合函數(shù)
讓我們定義一個(gè)評(píng)估函數(shù),用于評(píng)估模型在不可見(jiàn)數(shù)據(jù)上的性能,并定義一個(gè)擬合函數(shù),該函數(shù)可用于模型的訓(xùn)練。
class ImageClassificationBase(nn.Module):def training_step(self, batch):images, labels = batchout = self(images) # Generate predictionsloss = F.cross_entropy(out, labels) # Calculate lossreturn lossdef validation_step(self, batch):images, labels = batchout = self(images) # Generate predictionsloss = F.cross_entropy(out, labels) # Calculate lossacc = accuracy(out, labels) # Calculate accuracyreturn {'val_loss': loss.detach(), 'val_acc': acc}def validation_epoch_end(self, outputs):batch_losses = [x['val_loss'] for x in outputs]epoch_loss = torch.stack(batch_losses).mean() # Combine lossesbatch_accs = [x['val_acc'] for x in outputs]epoch_acc = torch.stack(batch_accs).mean() # Combine accuraciesreturn {'val_loss': epoch_loss.item(), 'val_acc': epoch_acc.item()}def epoch_end(self, epoch, result):print("Epoch [{}], train_loss: {:.4f}, val_loss: {:.4f}, val_acc: {:.4f}".format(epoch, result['train_loss'], result['val_loss'], result['val_acc']))
17. 訓(xùn)練(第一階段)
讓我們訓(xùn)練我們的模型,即 VGG 。
num_epochs = 10opt_func = torch.optim.Adamlr = 0.00001history = fit(num_epochs, lr, model, train_dl, val_dl, opt_func)Epoch [0], train_loss: 0.8719, val_loss: 0.3769, val_acc: 0.8793Epoch [1], train_loss: 0.4265, val_loss: 0.3104, val_acc: 0.8942Epoch [2], train_loss: 0.3682, val_loss: 0.2884, val_acc: 0.9016Epoch [3], train_loss: 0.3354, val_loss: 0.2819, val_acc: 0.8988Epoch [4], train_loss: 0.3205, val_loss: 0.2704, val_acc: 0.9033Epoch [5], train_loss: 0.2977, val_loss: 0.2722, val_acc: 0.9021Epoch [6], train_loss: 0.2853, val_loss: 0.2629, val_acc: 0.9068Epoch [7], train_loss: 0.2784, val_loss: 0.2625, val_acc: 0.9045Epoch [8], train_loss: 0.2697, val_loss: 0.2623, val_acc: 0.9033Epoch [9], train_loss: 0.2530, val_loss: 0.2629, val_acc: 0.9018
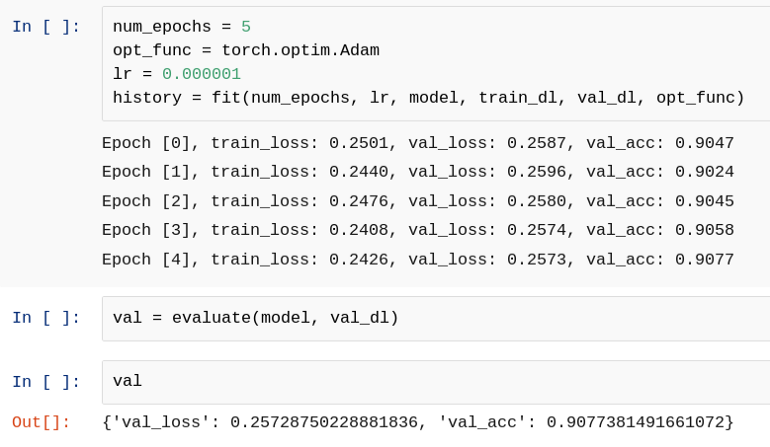
18. 訓(xùn)練(第二階段)
讓我們訓(xùn)練更多的歷元并評(píng)估該模型。
19. 訓(xùn)練(第 3 階段)
讓我們訓(xùn)練我們的模型 2 ,即 ResNet50 。
num_epochs = 10opt_func = torch.optim.Adamlr = 0.00001history = fit(num_epochs, lr, model2, train_dl, val_dl, opt_func)Epoch [0], train_loss: 1.6437, val_loss: 1.4135, val_acc: 0.7686Epoch [1], train_loss: 1.2088, val_loss: 0.9185, val_acc: 0.8582Epoch [2], train_loss: 0.8531, val_loss: 0.6467, val_acc: 0.8594Epoch [3], train_loss: 0.6709, val_loss: 0.5129, val_acc: 0.8640Epoch [4], train_loss: 0.5773, val_loss: 0.4416, val_acc: 0.8693Epoch [5], train_loss: 0.5215, val_loss: 0.4002, val_acc: 0.8739Epoch [6], train_loss: 0.4796, val_loss: 0.3725, val_acc: 0.8767Epoch [7], train_loss: 0.4582, val_loss: 0.3559, val_acc: 0.8795Epoch [8], train_loss: 0.4391, val_loss: 0.3430, val_acc: 0.8819Epoch [9], train_loss: 0.4262, val_loss: 0.3299, val_acc: 0.8823
num_epochs = 5opt_func = torch.optim.Adamlr = 0.0001history = fit(num_epochs, lr, model2, train_dl, val_dl, opt_func)Epoch [0], train_loss: 0.4183, val_loss: 0.3225, val_acc: 0.8753Epoch [1], train_loss: 0.3696, val_loss: 0.2960, val_acc: 0.8855Epoch [2], train_loss: 0.3533, val_loss: 0.2977, val_acc: 0.8814Epoch [3], train_loss: 0.3382, val_loss: 0.2970, val_acc: 0.8891Epoch [4], train_loss: 0.3289, val_loss: 0.2849, val_acc: 0.8933
20. 訓(xùn)練(第 4 階段)
讓我們訓(xùn)練更多的歷元并評(píng)估該模型。

21. 預(yù)測(cè)單個(gè)圖像
定義一個(gè)函數(shù),該函數(shù)可由模型用于預(yù)測(cè)單個(gè)圖像。
def predict_single(input,label, model):input = to_device(input,device)inputs = input.unsqueeze(0) # unsqueeze the input i.e. add an additonal dimensionpredictions = model(inputs)prediction = predictions[0].detach().cpu()print(f"Prediction is {np.argmax(prediction)} of Model whereas given label is {label}")
22.預(yù)測(cè)
讓我們預(yù)測(cè)一下

可以看出,目前 VGG 給出了錯(cuò)誤的預(yù)測(cè),盡管它具有良好的驗(yàn)證精度?(val_acc),而 ResNet 給出了正確的預(yù)測(cè),但我們不能說(shuō)它會(huì)在每張圖像上預(yù)測(cè)正確。
因此,讓我們針對(duì)更多的歷元訓(xùn)練這兩個(gè)模型,以便將誤差最小化,即 val_loss 可以盡可能地減少,并且兩個(gè)模型都可以更準(zhǔn)確地執(zhí)行。
現(xiàn)在,輪到小伙伴們預(yù)測(cè)整個(gè) pred 文件夾/數(shù)據(jù)集了。
提示:使用 pred_dl 作為數(shù)據(jù)加載器批量加載 pred 數(shù)據(jù)進(jìn)行預(yù)測(cè)。練習(xí)它,并嘗試使用集成預(yù)測(cè)的概念來(lái)獲得更正確的預(yù)測(cè)數(shù)量。
23.保存模型
在很好地訓(xùn)練模型后,讓我們保存它,以便我們可以將其用作下一個(gè)標(biāo)題中給出的未來(lái)工作。

24. 未來(lái)工作
使用我們保存的模型集成兩個(gè)模型的預(yù)測(cè),進(jìn)行最終預(yù)測(cè)并將此項(xiàng)目轉(zhuǎn)換為flask/stream-lit網(wǎng)絡(luò)應(yīng)用程序。
好消息,小白學(xué)視覺(jué)團(tuán)隊(duì)的知識(shí)星球開(kāi)通啦,為了感謝大家的支持與厚愛(ài),團(tuán)隊(duì)決定將價(jià)值149元的知識(shí)星球現(xiàn)時(shí)免費(fèi)加入。各位小伙伴們要抓住機(jī)會(huì)哦!
下載1:OpenCV-Contrib擴(kuò)展模塊中文版教程 在「小白學(xué)視覺(jué)」公眾號(hào)后臺(tái)回復(fù):擴(kuò)展模塊中文教程,即可下載全網(wǎng)第一份OpenCV擴(kuò)展模塊教程中文版,涵蓋擴(kuò)展模塊安裝、SFM算法、立體視覺(jué)、目標(biāo)跟蹤、生物視覺(jué)、超分辨率處理等二十多章內(nèi)容。 下載2:Python視覺(jué)實(shí)戰(zhàn)項(xiàng)目52講 在「小白學(xué)視覺(jué)」公眾號(hào)后臺(tái)回復(fù):Python視覺(jué)實(shí)戰(zhàn)項(xiàng)目,即可下載包括圖像分割、口罩檢測(cè)、車道線檢測(cè)、車輛計(jì)數(shù)、添加眼線、車牌識(shí)別、字符識(shí)別、情緒檢測(cè)、文本內(nèi)容提取、面部識(shí)別等31個(gè)視覺(jué)實(shí)戰(zhàn)項(xiàng)目,助力快速學(xué)校計(jì)算機(jī)視覺(jué)。 下載3:OpenCV實(shí)戰(zhàn)項(xiàng)目20講 在「小白學(xué)視覺(jué)」公眾號(hào)后臺(tái)回復(fù):OpenCV實(shí)戰(zhàn)項(xiàng)目20講,即可下載含有20個(gè)基于OpenCV實(shí)現(xiàn)20個(gè)實(shí)戰(zhàn)項(xiàng)目,實(shí)現(xiàn)OpenCV學(xué)習(xí)進(jìn)階。 交流群
歡迎加入公眾號(hào)讀者群一起和同行交流,目前有SLAM、三維視覺(jué)、傳感器、自動(dòng)駕駛、計(jì)算攝影、檢測(cè)、分割、識(shí)別、醫(yī)學(xué)影像、GAN、算法競(jìng)賽等微信群(以后會(huì)逐漸細(xì)分),請(qǐng)掃描下面微信號(hào)加群,備注:”昵稱+學(xué)校/公司+研究方向“,例如:”張三?+?上海交大?+?視覺(jué)SLAM“。請(qǐng)按照格式備注,否則不予通過(guò)。添加成功后會(huì)根據(jù)研究方向邀請(qǐng)進(jìn)入相關(guān)微信群。請(qǐng)勿在群內(nèi)發(fā)送廣告,否則會(huì)請(qǐng)出群,謝謝理解~
