
ECV 2021 冠軍方案解讀:占道經(jīng)營識別方案

極市導(dǎo)讀
?本文為獲得占道經(jīng)營識別冠軍的威富團隊方案解讀,團隊選用了基于YOLOv5的one-stage檢測框架,最后達到了104.3FPS?>>加入極市CV技術(shù)交流群,走在計算機視覺的最前沿
我們參加了反光衣識別、駕駛員不良駕駛識別、船只數(shù)量檢測、機動車識別、占道經(jīng)營檢測和電動車進電梯檢測,下面以占道經(jīng)營為例介紹整個情況。
團隊介紹
團隊來自深圳市威富視界有限公司&中國科學(xué)院半導(dǎo)體研究所高速電路與神經(jīng)網(wǎng)絡(luò)實驗室,成員分別為寧欣、石園、榮倩倩,排名不分先后。

ECV 2021極市計算機視覺開發(fā)者榜單大賽介紹
ECV-2021將聚集于計算機視覺領(lǐng)域的前言科技與應(yīng)用創(chuàng)新,全面升級賽制,設(shè)立超百萬獎金,旨在匯聚全球AI人才解決AI產(chǎn)業(yè)實際問題,促進人才技術(shù)交流,提升開發(fā)者人才的算法開發(fā)到落地應(yīng)用的工程化能力,推動計算機視覺算法人才的專業(yè)工程化能力認證。
ECV-2021將采取多賽題并行的競賽形式,圍繞智慧城市、交通、安防、城管、海洋、銀行等實際業(yè)務(wù)場景設(shè)置八個賽題,各賽題為渣土車車牌識別、反光衣識別、駕駛員不良駕駛識別、船只數(shù)量檢測、機動車識別、占道經(jīng)營檢測、電動車進電梯檢測和人體解析分割。同時為賽題著提供真實場景數(shù)據(jù)集、免費云端算力支持、便捷在線訓(xùn)練系統(tǒng)、OpenVINO工具套件等,幫助參賽者全程線上無障礙開發(fā)、加速模型推理,真正實現(xiàn)在線編碼訓(xùn)練、模型轉(zhuǎn)換、模型測試等一站式競賽體驗。
任務(wù)介紹
賽道6——占道經(jīng)營檢測
近年來地鐵經(jīng)濟對拉動經(jīng)濟發(fā)展、增加就業(yè)起到了積極作用,如何有序管理攤位經(jīng)營,維護城市交通順暢和人員安全,是當前城市管理非常重要的問題。該賽題希望通過占道經(jīng)營檢測算法的開發(fā),利用計算機視覺技術(shù)的“火眼金睛”,輔助城管人員,降低城市管理成本,使城市管理能更加智能高效,進而有效減少城市違規(guī)占道經(jīng)營的情況。
挑戰(zhàn)賽的參與者對圖片中的占道經(jīng)營行為進行目標檢測,給出目標框和對應(yīng)的類別信息,其類別為固定擺攤fixed_stall(街道、人行道周邊的地位攤位)、移動擺攤move_stall(三輪車、販賣小貨車等)、遮陽傘sunshade(遮陽傘、臨時販賣小棚)。數(shù)據(jù)集是由監(jiān)控攝像頭采集的現(xiàn)場場景數(shù)據(jù),訓(xùn)練數(shù)據(jù)集包括10147張,測試數(shù)據(jù)集包含4346張。
評價指標
該賽道最終得分采用準確度、算法性能絕對值的綜合得分形式,具體形式如下:

說明:
(1)算法性能指的賽道標準值是 100 FPS, 如果所得性能值FPS≥賽道標準值FPS,則算法性能值得分=1;
(2)獲獎評審標準:參賽者需要獲得算法精度和算法性能值的成績,且算法精度≥0.6,算法性能值FPS≥5,才能進入獲獎評選;
(3)算法精度和性能均取自算法轉(zhuǎn)換OpenVINO模型后的對應(yīng)值;
(4)?本題規(guī)定predicted bounding box和ground truth bounding box的IoU(交叉比)作為結(jié)果目標匹配的依據(jù),其中IoU值>0.5且目標類別標簽相匹配的目標視為正確結(jié)果,其它視為正確結(jié)果,其它視為錯誤。
威富視界&中國科學(xué)院半導(dǎo)體研究所兩支團隊榮獲四個第一、兩個第二
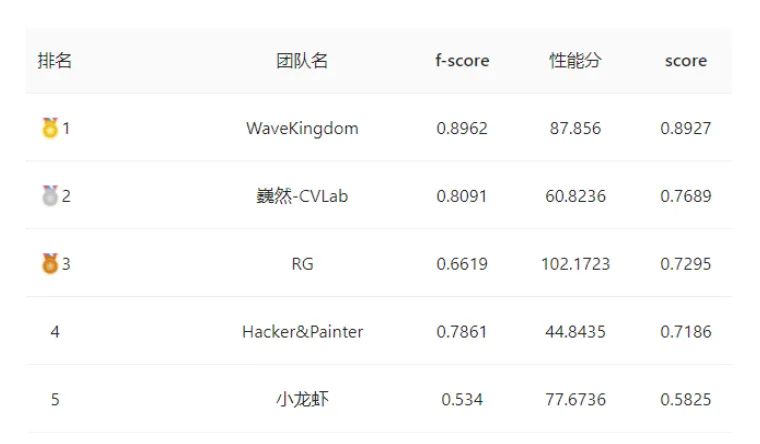
賽題特點
圖像尺寸不一、近景和遠景目標尺度差異大。
數(shù)據(jù)集圖片尺寸不一,相差較大。一方面,由于計算資源和算法性能的限制,大尺寸的圖像不能作為網(wǎng)絡(luò)的輸入,而單純將原圖像縮放到小圖會使得目標丟失大量信息。另一方面,圖像中近景和遠景的目標尺度差異大,對于檢測器來說,是個巨大的挑戰(zhàn)。
目標在圖像中分布密集,并且遮擋嚴重。
數(shù)據(jù)集均是利用攝像頭從真實場景采集,部分數(shù)據(jù)的目標密集度較大。無論是賽道一中的行人還是賽道二中的小攤販都出現(xiàn)了頻繁出現(xiàn)遮擋現(xiàn)象,目標的漏檢情況相對嚴重。
主要工作
1、主體框架選擇
目前,基于深度學(xué)習的目標檢測技術(shù)包括anchor-based和anchor-free兩大類。首先我們先是分析兩者的優(yōu)缺點:
anchor-based:
1)優(yōu)點:加入了先驗知識,模型訓(xùn)練相對穩(wěn)定;密集的anchor box可有效提高召回率,對于小目標檢測來說提升非常明顯。
2)缺點:對于多類別目標檢測,超參數(shù)scale和aspect ratio相對難設(shè)計;冗余box非常多,可能會造成正負樣本失衡;在進行目標類別分類時,超參IOU閾值需根據(jù)任務(wù)情況調(diào)整。
anchor-free:
1)優(yōu)點:計算量減少;可靈活使用。
2)缺點:存在正負樣本嚴重不平衡;兩個目標中心重疊的情況下,造成語義模糊性;檢測結(jié)果相對不穩(wěn)定。
我們又考慮到比賽任務(wù)情況:
1)小攤位占道識別是小攤位檢測,都屬于多類別檢測,目標的scale和aspect ratio都在一定范圍之內(nèi),屬可控因素。
2)比賽數(shù)據(jù)中存在很多目標遮擋情況,這有可能會造成目標中心重合,如果采用anchor-free,會造成語義模糊性;
3)scale和aspect ratio可控,那么超參IOU調(diào)整相對簡單;
4)大賽對模型部署沒有特殊要求,因此,部署方案相對較多,模型性能有很大改進。
因此,在anchor-based和anchor-free兩者中,我們偏向于選擇基于anchor-based的算法。
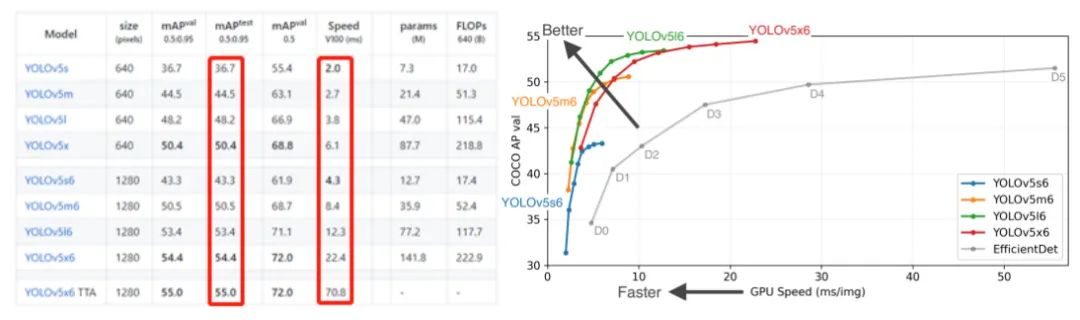
眾所周知,YOLO系列性能在目標檢測算法一直引人矚目,特別是最近的YOLOv5在速度上更是令人驚訝。從下圖可以看出,YOLOv5在模型大小方面選擇靈活,訓(xùn)練周期相對較短。另外,在保證速度的同時,模型精度也是可觀。因此,我們選用YOLOv5作為baseline,然后依據(jù)賽道的任務(wù)情況在此基礎(chǔ)上進行改進。
首先根據(jù)訓(xùn)練數(shù)據(jù)集進行分析,在10147張訓(xùn)練圖像中,總共有3個類別。存在以下三種情況:(1)樣本不平衡;(2)場景樣本不均衡;(3)多種狀態(tài)小攤位,例如重疊、殘缺、和占比小且遮擋。
另外,要權(quán)衡檢測分類的精度和模型運行的速度,因此我們決定選用檢測分類精度較好的目標檢測框架,同時使用模型壓縮和模型加速方法完成加速。其主體思路為:
目標檢測框架:基于YOLOv5的one-stage檢測框架;
模型優(yōu)化:采用優(yōu)化策略,比如數(shù)據(jù)增強、SAM優(yōu)化器、Varifocal Loss、凍結(jié)訓(xùn)練策略;
訓(xùn)練時間優(yōu)化:采用Yolov5+Cache+圖像編解碼;
模型壓縮:OpenVINO轉(zhuǎn)換后INT8量化;
模型加速:訓(xùn)練C++封裝部署。
我們針對以上策略進行詳細介紹:
(1)數(shù)增強策略
從數(shù)據(jù)角度,我們通過粘貼、裁剪、mosaic、仿射變換、顏色空間轉(zhuǎn)換等對樣本進行增強,增加目標多樣性,以提升模型的檢測與分類精度。
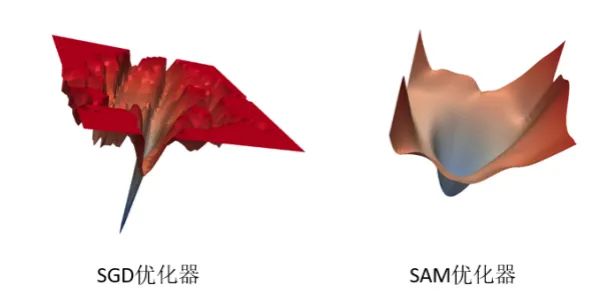
(2)SAM優(yōu)化器
SAM優(yōu)化器[4]可使損失值和損失銳度同時最小化,并可以改善各種基準數(shù)據(jù)集(例如CIFAR-f10、100g,ImageNet,微調(diào)任務(wù))和模型的模型泛化能力,從而產(chǎn)生了多種最新性能。另外, SAM優(yōu)化器具有固有的魯棒性。
經(jīng)實驗對比,模型進行優(yōu)化器梯度歸一化和采用SAM優(yōu)化器,約有0.027點的提升。
(3)Varifocal Loss損失函數(shù)
Varifocal Loss主要訓(xùn)練密集目標檢測器使IOU感知的分類得分(IASC)回歸,來提高檢測精度。而目標遮擋是密集目標的特征之一,因此嘗試使用該loss來緩解目標遮擋造成漏檢現(xiàn)象。并且與focal loss不同,varifocal loss是不對稱對待正負樣本所帶來的損失。
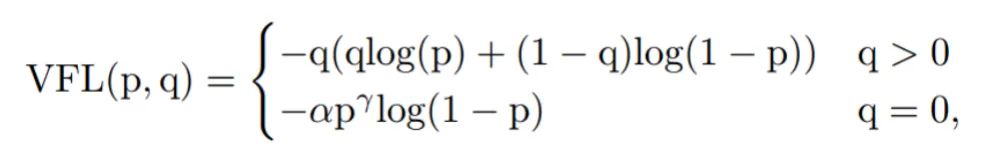
在比賽過程中,p輸入為前景類的預(yù)測概率;q為ground-truth;減少負樣本的損失貢獻,而正樣本不降低正權(quán)重。因為正樣本相對于負樣本是非常罕見的,應(yīng)保留他們的學(xué)習信息。
(4)凍結(jié)訓(xùn)練
在訓(xùn)練過程中采取常規(guī)訓(xùn)練與凍結(jié)訓(xùn)練想相結(jié)合的方式迭代,進一步抑制訓(xùn)練過程中容易出現(xiàn)的過擬合現(xiàn)象,具體訓(xùn)練方案是:1)常規(guī)訓(xùn)練;2)加入凍結(jié)模塊的分步訓(xùn)練1;3)加入凍結(jié)模塊的分步訓(xùn)練2。
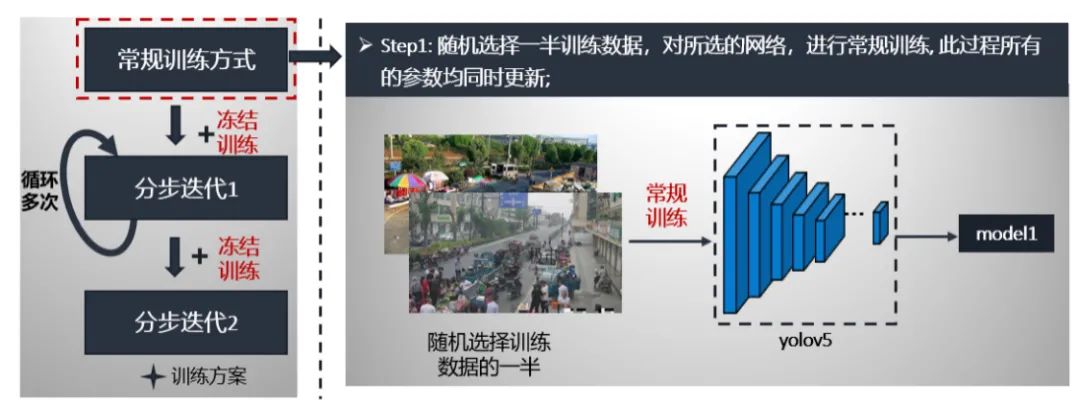
我們詳細講解以上步驟。第一步:從訓(xùn)練數(shù)據(jù)中隨機選取一半,進行yolov5常規(guī)訓(xùn)練,該過程中所有的參數(shù)是同時更新的。最后獲得在a榜上最好模型model1。具體流程如下:
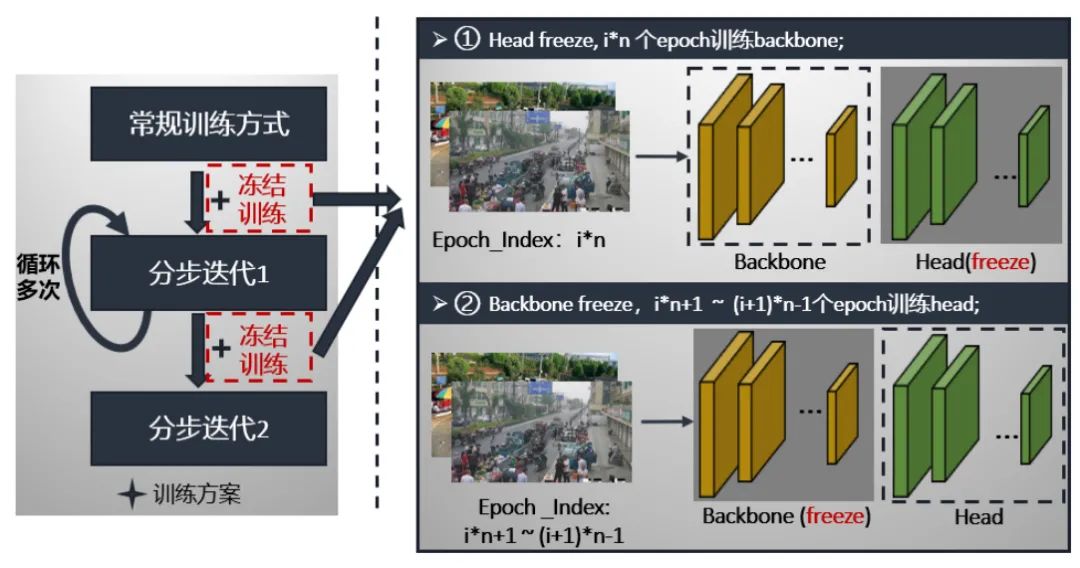
在介紹第二步和第三步之前,我們先介紹一下凍結(jié)模塊。凍結(jié)模塊的特點就是將backbone和head輪流凍結(jié),每epoch只更新未凍結(jié)部分的參數(shù)。我們以5個epoch為一個階段,第一個epoch為head凍結(jié),只訓(xùn)練backbone;第2~5個epoch為backbone凍結(jié),只訓(xùn)練head。這樣輪流更新backbone和head的參數(shù),具體過程如下:
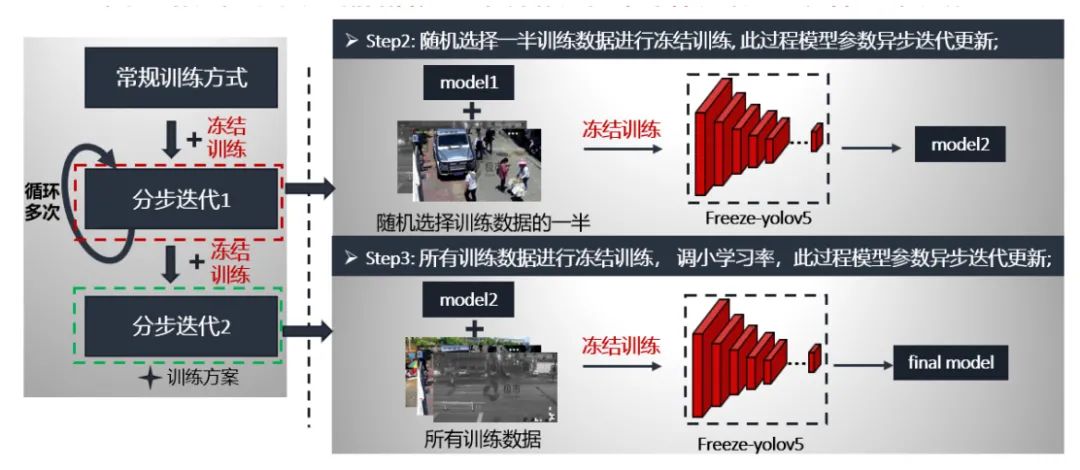
第二步分布迭代1就是采用的凍結(jié)模塊進行,數(shù)據(jù)是隨機選取訓(xùn)練數(shù)據(jù)的一半,預(yù)訓(xùn)練模型是第一步常規(guī)訓(xùn)練的最好模型,按照凍結(jié)訓(xùn)練方式進行訓(xùn)練。這個流程循環(huán)多次,獲得model2。
第三步分布迭代2同樣采用的是凍結(jié)模塊進行,數(shù)據(jù)是所有訓(xùn)練數(shù)據(jù),由于參數(shù)已經(jīng)學(xué)過,這時我們將學(xué)習率調(diào)小一個量級,同樣也是按照凍結(jié)訓(xùn)練方式進行訓(xùn)練。這個流程只循環(huán)一次,獲得最終的模型。
兩步的具體流程如下:
(5)訓(xùn)練時間優(yōu)化
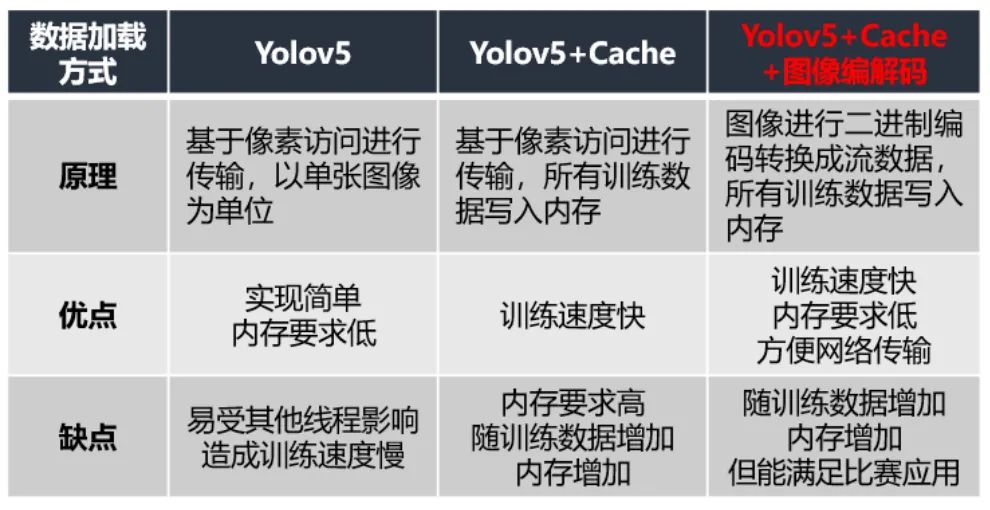
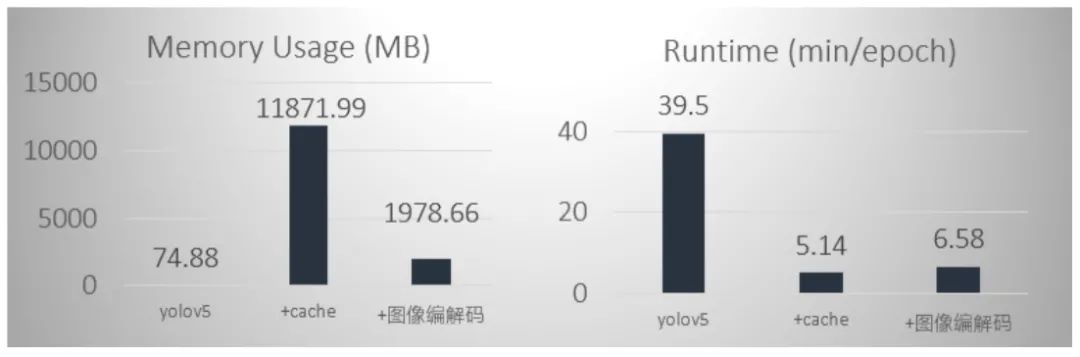
最初我們直接采用yolov5訓(xùn)練,這種數(shù)據(jù)加載方式是以張為單位,基于像素的訪問,但是訓(xùn)練時速度很慢,可能受其他線程影響造成的,大概一輪要40分鐘左右。然后我們就嘗試了cache這種方式,它是將所有訓(xùn)練數(shù)據(jù)存入到內(nèi)存中,我們以6406403的輸入圖像為例,占道數(shù)據(jù)總共有10147張,全部讀進去大約占11.6G的內(nèi)存,平臺是提供12G的內(nèi)存,幾乎將內(nèi)存占滿,也會導(dǎo)致訓(xùn)練變慢;于是我們就嘗試改進訓(xùn)練讀取數(shù)據(jù)方式,我們采用的是cache+圖像編解碼的方式,內(nèi)存占用僅是cache的1/6,由于添加了編解碼,速度比cache慢點,但從數(shù)據(jù)比較來看,相差無幾。這樣既能節(jié)省內(nèi)存又能加快訓(xùn)練速度。節(jié)省了我們訓(xùn)練過程的極力值和加快實驗的步伐。
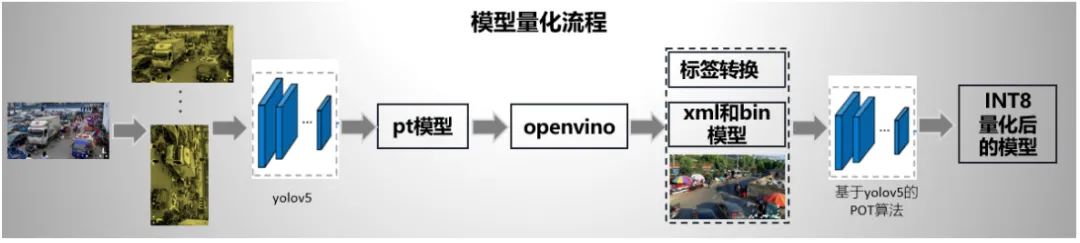
(6)模型量化
我們考慮完精度后,我們考慮模型量化問題。我們用的是openvino 2020自帶的工具將模型轉(zhuǎn)換為INT8類型,主要為:(1)POT,主要是用于INT8轉(zhuǎn)換;(2)accuracy_check,用來檢查模型在指定數(shù)據(jù)集上的推理精確度。
POT提供了多種量化和輔助算法來幫助量化權(quán)重和激活圖后的模型恢復(fù)精度。這里僅介紹我們對比的兩種方案:一種是DefaultQuantization,旨在執(zhí)行快速且準確的神經(jīng)網(wǎng)絡(luò)的INT8量化。但是我們在該賽道使用該方法mAP為0;另一種算法是AccuracyAwareQuantization,它是執(zhí)行精確的INT8量化,允許在量化后精度下降在預(yù)定的范圍內(nèi),同時犧牲一定的性能提升,并需要更多的時間量化。我們設(shè)定的精度下降閾值是0.005。
我們整個模型量化流程為:
實驗結(jié)果
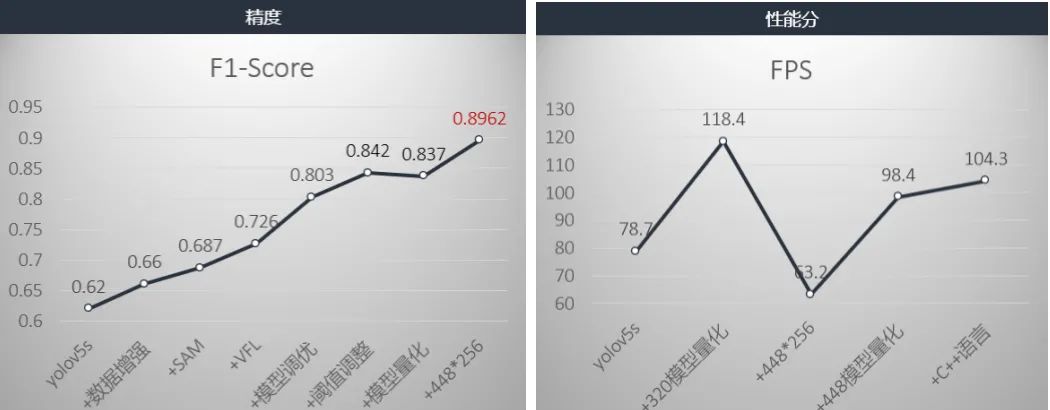
關(guān)于精度方面我們添加各種trick后,精度F1-Score提升到了0.842。沒有量化之前,性能約為78.7FPS,我們進行了基于openvino的模型量化,精度降低為0.837,但性能提升了118.4。而我們比賽性能要求是100FPS為滿分。因此,我們就將輸入圖像從320調(diào)整為448,模型就提升到了0.8962,沒有量化之前性能分為63.2,量化后為98.4,然后我們由將python語言換成了c++語言,達到了104.3FPS。
討論與總結(jié)
本文針對2021極市計算機視覺開發(fā)者榜單大賽任務(wù)了總結(jié)與歸納。相關(guān)結(jié)論可以歸納為以下幾點:
數(shù)據(jù)分析對于訓(xùn)練模型至關(guān)重要。數(shù)據(jù)不平衡、圖像尺寸和目標大小不一、目標密集和遮擋等問題,應(yīng)選用對應(yīng)的baseline和應(yīng)對策略。例如,數(shù)據(jù)不平衡可嘗試過采樣、focal loss、varifocal loss、數(shù)據(jù)增強等策略;圖像尺寸和目標大小不一可采用多尺度、數(shù)據(jù)裁剪等方法。 針對算法精度和性能兩者取舍來說,可先實驗網(wǎng)絡(luò)大小和輸入圖片大小對模型結(jié)果的影響,不同任務(wù)和不同數(shù)據(jù)情況,兩者相差較大。所以不能一味為了提高速度,單純壓縮網(wǎng)絡(luò)大小; 針對性能要求時,可采用OpenVINO INT8、C++等方式部署模型,也可采用模型壓縮等方式,這樣可在保證速度的前提下,使用較大網(wǎng)絡(luò),提升模型精度。
參考文獻
https://github.com/ultralytics/yolov5.git https://www.cvmart.net/ Zhang H , ?Wang Y , ?Dayoub F , et al. VarifocalNet: An IoU-aware Dense Object Detector[J]. ?2020. Pierre F,?Ariel K,?Hossein M,?Behnam N; Sharpness-Aware Minimization for Efficiently Improving Generalization[2020]
如果覺得有用,就請分享到朋友圈吧!
公眾號后臺回復(fù)“CVPR21檢測”獲取CVPR2021目標檢測論文下載~

#?CV技術(shù)社群邀請函?#

備注:姓名-學(xué)校/公司-研究方向-城市(如:小極-北大-目標檢測-深圳)
即可申請加入極市目標檢測/圖像分割/工業(yè)檢測/人臉/醫(yī)學(xué)影像/3D/SLAM/自動駕駛/超分辨率/姿態(tài)估計/ReID/GAN/圖像增強/OCR/視頻理解等技術(shù)交流群
每月大咖直播分享、真實項目需求對接、求職內(nèi)推、算法競賽、干貨資訊匯總、與?10000+來自港科大、北大、清華、中科院、CMU、騰訊、百度等名校名企視覺開發(fā)者互動交流~
