NightOwls 檢測(cè)挑戰(zhàn)賽簡(jiǎn)介檢測(cè) RGB 攝像機(jī)拍攝的夜間場(chǎng)景圖片中的行人,是一個(gè)非常重要但是未被充分重視的問(wèn)題,當(dāng)前最新的視覺(jué)檢測(cè)算法并不能很好地預(yù)測(cè)出結(jié)果。官方 baseline 在 Caltech(著名行人檢測(cè)數(shù)據(jù)集)上的 Miss Rate(越小越好)可以達(dá)到 7.36%,但在夜間行人數(shù)據(jù)集上卻只能達(dá)到 63.99%。夜間行人檢測(cè)是許多系統(tǒng)(如安全可靠的自動(dòng)駕駛汽車(chē))的關(guān)鍵組成部分,但使用計(jì)算機(jī)視覺(jué)方法解決夜間場(chǎng)景的檢測(cè)問(wèn)題并未受到太多關(guān)注,因此 CVPR 2020 Scalability in Autonomous Driving Workshop 開(kāi)展了相應(yīng)的比賽。NightOwls Detetection Challenge 2020 共有三個(gè)賽題:?jiǎn)螏腥藱z測(cè)(該賽題與 2019 年相同)、多幀行人檢測(cè),以及檢測(cè)單幀中所有物體(包括行人、自行車(chē)、摩托車(chē)三個(gè)類(lèi)別):- Pedestrian Detection from a Single Frame (same as 2019 competition)
- Pedestrian Detection from a Multiple Frames
- All Objects Detection (pedestrian, cyclist, motorbike) from a Single Frame

Track 1: Pedestrian detection from a single frame該任務(wù)只要求檢測(cè)行人(對(duì)應(yīng) Ground truth 中 category_id = 1 的行人類(lèi)別),且所用算法只能將當(dāng)前幀用作檢測(cè)的輸入,該題目與 ICCV 2019 NightOwls 挑戰(zhàn)賽相同。Track 2: Pedestrian detection from multiple frames該任務(wù)的要求與任務(wù) 1 相同,都是只檢測(cè)行人,但是該任務(wù)允許使用當(dāng)前幀以及所有先前幀 (N, N-1, N-2, …) 來(lái)預(yù)測(cè)當(dāng)前幀的行人。這兩個(gè)任務(wù)的數(shù)據(jù)集由 279000 張全注釋的圖片組成,這些圖片來(lái)源于歐洲多個(gè)城市黎明和夜間的 40 個(gè)視頻,并涵蓋了不同的天氣條件。模型效果評(píng)估使用的是行人檢測(cè)中常用的指標(biāo)Average Miss Rate metric,但是僅考慮高度 > = 50px 的非遮擋目標(biāo)。
Track 3: All Objects Detection (pedestrian, cyclist, motorbike) from a Single Frame該任務(wù)要求檢測(cè)出幀里所有在訓(xùn)練集中出現(xiàn)過(guò)的類(lèi)別,包括自行車(chē)、摩托車(chē),并且不允許使用視頻序列信息。
這次比賽的主要難點(diǎn)包含以下幾個(gè)方面:與常規(guī)檢測(cè)數(shù)據(jù)集不同,該競(jìng)賽考慮到實(shí)際駕駛情況,所用數(shù)據(jù)是在車(chē)輛行進(jìn)過(guò)程中采集的,所以當(dāng)車(chē)速較快或者有相對(duì)運(yùn)動(dòng)的時(shí)候會(huì)產(chǎn)生持續(xù)的運(yùn)動(dòng)模糊圖像。并且由于攝像頭是普通的RGB相機(jī),因此在光線較弱的環(huán)境下收集的圖片質(zhì)量大幅度下降,這也是影響模型效果的主要原因。
這是由于收集數(shù)據(jù)主要來(lái)自于夜間環(huán)境所導(dǎo)致的必然結(jié)果,所以在進(jìn)行數(shù)據(jù)增強(qiáng)的時(shí)候需要謹(jǐn)慎,不同增強(qiáng)方式會(huì)造成較大的影響。該比賽的數(shù)據(jù)集涵蓋了不同的城市和天氣,之前常用的行人檢測(cè)數(shù)據(jù)集一般未同時(shí)滿(mǎn)足這兩個(gè)條件。該數(shù)據(jù)具有多樣性,且與常用數(shù)據(jù)集的數(shù)據(jù)分布存在較大差異。該比賽數(shù)據(jù)集與常用于訓(xùn)練預(yù)訓(xùn)練模型的數(shù)據(jù)集(如 COCO 數(shù)據(jù)集、OBJ365)的數(shù)據(jù)分布存在很大的不同,因此對(duì)基于常用數(shù)據(jù)集預(yù)訓(xùn)練的模型進(jìn)行 fine-tune 的效果不如預(yù)期。DeepBlueAI 團(tuán)隊(duì)解決方案DeepBlueAI 團(tuán)隊(duì)在單幀行人檢測(cè)和多幀行人檢測(cè)兩個(gè)賽道中取得了冠軍成績(jī),在檢測(cè)單幀中所有物體賽道中獲得了亞軍。

就檢測(cè)器而言,該團(tuán)隊(duì)首先通過(guò)常規(guī)檢測(cè)所累積的經(jīng)驗(yàn)構(gòu)造出一個(gè) baseline:Baseline = Backbone + DCN? + FPN + Cascade + anchor ratio (2.44)
這些模塊早已是各個(gè)比賽的「常客」,也被許多專(zhuān)業(yè)人士進(jìn)行了比較透徹的分析,此處不再贅述。DeepBlueAI 團(tuán)隊(duì)進(jìn)行了簡(jiǎn)單的實(shí)驗(yàn),發(fā)現(xiàn)這些模塊總是有用,進(jìn)而將這套算法作為 baseline,加上一些行人檢測(cè)的小 trick,如將 anchor ratio 改為 2.44、針對(duì)標(biāo)注為 ignore 的目標(biāo)在訓(xùn)練過(guò)程中 loss 不進(jìn)行回傳處理。? 通過(guò)觀察實(shí)驗(yàn)發(fā)現(xiàn),baseline 將背景中的石柱、燈柱等物體檢測(cè)為行人,這種情況大多和 head 效果不好有關(guān)。該團(tuán)隊(duì)基于此進(jìn)行了實(shí)驗(yàn),如 TSD [7]、CLS [8]、double head [9],并最終選擇了效果好且性?xún)r(jià)比高的 double head 結(jié)構(gòu)(如下圖所示):
通過(guò)觀察實(shí)驗(yàn)發(fā)現(xiàn),baseline 將背景中的石柱、燈柱等物體檢測(cè)為行人,這種情況大多和 head 效果不好有關(guān)。該團(tuán)隊(duì)基于此進(jìn)行了實(shí)驗(yàn),如 TSD [7]、CLS [8]、double head [9],并最終選擇了效果好且性?xún)r(jià)比高的 double head 結(jié)構(gòu)(如下圖所示):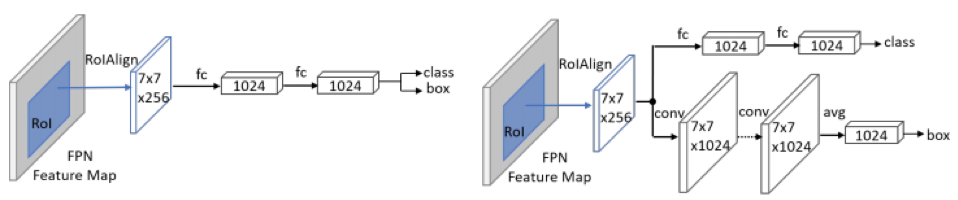
Double Heads 結(jié)構(gòu)
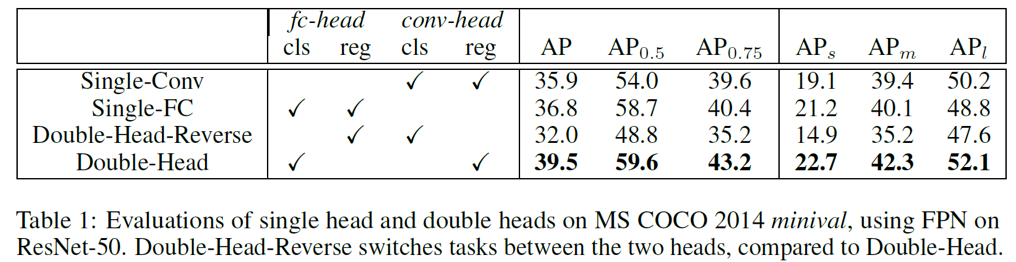
通過(guò)對(duì)比實(shí)驗(yàn)可以發(fā)現(xiàn):使用 FC-head 做分類(lèi)、Conv-head 做回歸,可以得到最好的效果。分類(lèi)更多地需要語(yǔ)義信息,而坐標(biāo)框回歸則更多地需要空間信息,double head 方法采用分而治之的思想,針對(duì)不同的需求設(shè)計(jì) head 結(jié)構(gòu),因此更加有效。當(dāng)然這種方法也會(huì)導(dǎo)致計(jì)算量的增加。在平衡速度和準(zhǔn)確率的情況下,該團(tuán)隊(duì)最終選擇了 3 個(gè)殘差 2 個(gè) Non-local 共 5 個(gè)模塊。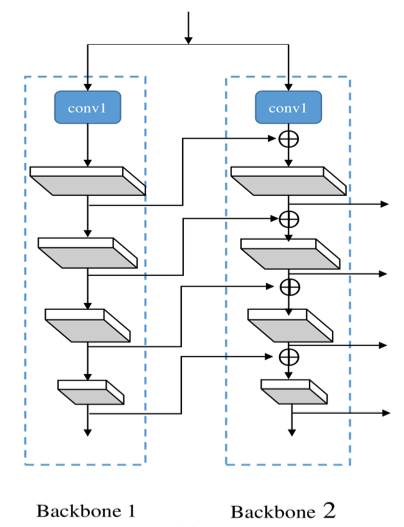
合并功能更強(qiáng)大的 backbone 可提高目標(biāo)檢測(cè)器的性能。CBNet 作者提出了一種新穎的策略,通過(guò)相鄰 backbone 之間的復(fù)合連接 (Composite Connection) 來(lái)組合多個(gè)相同的 backbone。用這種方式他們構(gòu)建出了一個(gè)更強(qiáng)大的 backbone,稱(chēng)為「復(fù)合骨干網(wǎng)絡(luò)」(Composite Backbone Network)。當(dāng)然這也帶來(lái)了模型參數(shù)大小和訓(xùn)練時(shí)間的增加,屬于 speed–accuracy trade-off。該團(tuán)隊(duì)也嘗試過(guò)其他的改進(jìn)方式,但最終還是選擇了實(shí)用性更強(qiáng)的 CBNet,該方法不用再額外擔(dān)心預(yù)訓(xùn)練權(quán)重的問(wèn)題。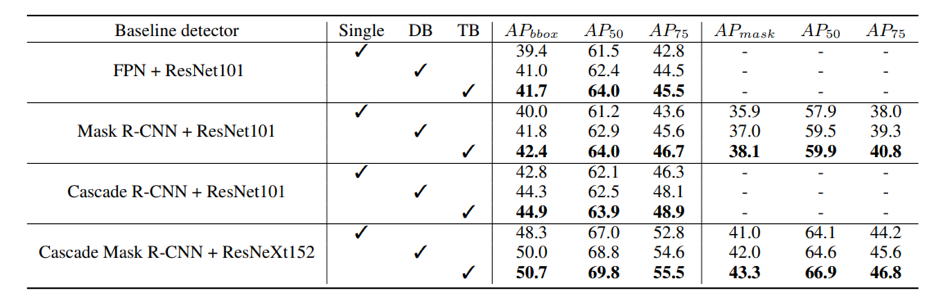
該團(tuán)隊(duì)選擇了性?xún)r(jià)比較高的雙 backbone 模型結(jié)構(gòu)。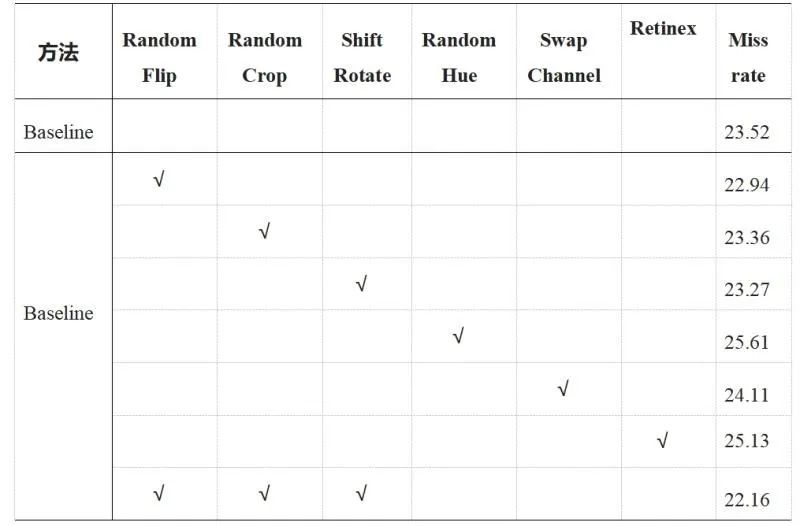
該團(tuán)隊(duì)發(fā)現(xiàn) Pixel-level 的增強(qiáng)方式導(dǎo)致了性能結(jié)果大幅下降,因此沒(méi)有在這個(gè)方向繼續(xù)嘗試。而圖像增強(qiáng)方式 Retinex,從視覺(jué)上看帶來(lái)了圖像增強(qiáng),但是該方法可能破壞了原有圖片的結(jié)構(gòu)信息,導(dǎo)致最終結(jié)果沒(méi)有提升。于是,該團(tuán)隊(duì)最終選擇了 Spatial-level 的增強(qiáng)方式,使得結(jié)果有一定的提升。1. 將 Cascade rcnn + DCN + FPN 作為 baseline;
2. 將原有 head 改為 Double head;
3. 將 CBNet 作為 backbone;
4. 使用 cascade rcnn COCO-Pretrained weight;
5. 數(shù)據(jù)增強(qiáng);
6. 多尺度訓(xùn)練 + Testing tricks。
下圖展示了該團(tuán)隊(duì)使用的方法在本地驗(yàn)證集上的結(jié)果: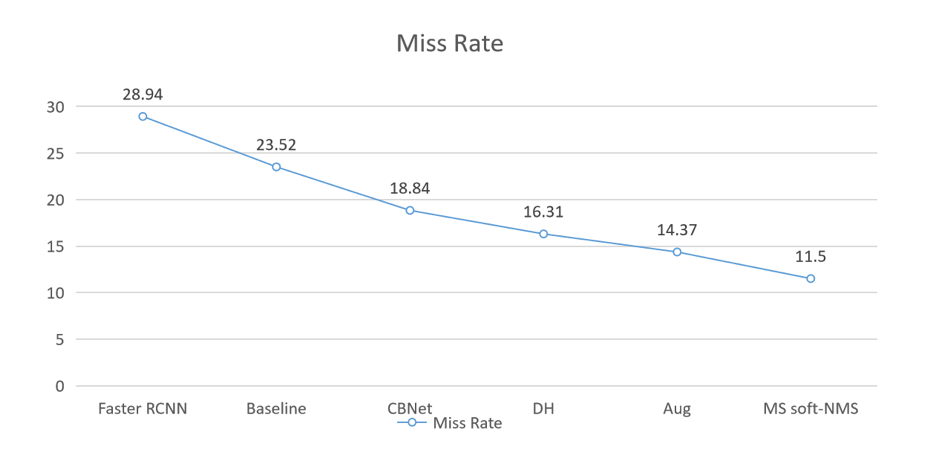
該團(tuán)隊(duì)將今年的成績(jī)與去年 ICCV 2019 同賽道冠軍算法進(jìn)行對(duì)比,發(fā)現(xiàn)在不使用額外數(shù)據(jù)集的情況下,去年單模型在 9 個(gè)尺度的融合下達(dá)到 11.06,而該團(tuán)隊(duì)的算法在只用 2 個(gè)尺度的情況下就可以達(dá)到 10.49。該團(tuán)隊(duì)雖然獲得了不錯(cuò)的成績(jī),但也基于已有的經(jīng)驗(yàn)提出了一些未來(lái)工作方向:1. 由于數(shù)據(jù)的特殊性,該團(tuán)隊(duì)嘗試使用一些增強(qiáng)方式來(lái)提高圖片質(zhì)量、亮度等屬性,使圖片中的行人更易于檢測(cè)。但結(jié)果證明這些增強(qiáng)方式可能破壞原有圖片結(jié)構(gòu),效果反而降低。該團(tuán)隊(duì)相信會(huì)有更好的夜間圖像處理辦法,只是還需要更多研究和探索。2. 在允許使用之前幀信息的賽道二中,該團(tuán)隊(duì)僅使用了一些簡(jiǎn)單的 IoU 信息。由于收集這個(gè)數(shù)據(jù)集的攝像頭一直在移動(dòng),該團(tuán)隊(duì)之前在類(lèi)似的數(shù)據(jù)集上使用過(guò)一些 SOTA 的方法,卻沒(méi)有取得好的效果。他們認(rèn)為之后可以在如何利用時(shí)序幀信息方面進(jìn)行深入的探索。3. 該領(lǐng)域存在大量白天行人檢測(cè)的數(shù)據(jù)集,因此該團(tuán)隊(duì)認(rèn)為之后可以嘗試 Domain Adaption 方向的方法,以充分利用行人數(shù)據(jù)集。參考文獻(xiàn):
[1]?Lin T Y , Dollár, Piotr, Girshick R , et al. Feature Pyramid Networks for Object Detection[J]. 2016.[2]?Dai J, Qi H, Xiong Y, et al. Deformable Convolutional Networks[J]. 2017.[3]?Cai Z , Vasconcelos N . Cascade R-CNN: Delving into High Quality Object Detection[J]. 2017.[4]?Xie S , Girshick R , Dollar P , et al. Aggregated Residual Transformations for Deep Neural Networks[C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE Computer Society, 2017.[5]?Bochinski E , Eiselein V , Sikora T . High-Speed tracking-by-detection without using image information[C]// 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS). IEEE, 2017.[6]?Henriques J F , Caseiro R , Martins P , et al. High-Speed Tracking with Kernelized Correlation Filters[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(3):583-596.[7]?Song G , Liu Y , Wang X . Revisiting the Sibling Head in Object Detector[J]. 2020.[8]?Li A , Yang X , Zhang C . Rethinking Classification and Localization for Cascade R-CNN[J]. 2019.[9]?Wu, Y., Chen, Y., Yuan, L., Liu, Z., Wang, L., Li, H., & Fu, Y. (2019). Rethinking Classification and Localization in R-CNN. ArXiv, abs/1904.06493.[10]?Liu, Y., Wang, Y., Wang, S., Liang, T., Zhao, Q., Tang, Z., & Ling, H. (2020). CBNet: A Novel Composite Backbone Network Architecture for Object Detection. ArXiv, abs/1909.03625.


