
Flink 實踐 | 作業(yè)幫基于 Flink 的實時計算平臺實踐
摘要:本文整理自作業(yè)幫實時計算負責人張迎在 Flink Forward Asia 2021 的分享。在作業(yè)幫實時計算演進過程中,F(xiàn)link 起到了重要的作用,特別是借助于 FlinkSQL 極大的提高了實時任務的開發(fā)效率。這篇文章主要分享 FlinkSQL 在作業(yè)幫的使用情況、實踐經(jīng)驗,以及隨著任務規(guī)模增長,在從 0 到 1 搭建實時計算平臺的過程中遇到的問題及解決方案。內容包括:
發(fā)展歷程 Flink SQL 應用實踐 平臺建設 總結展望
一、發(fā)展歷程
作業(yè)幫主要運用人工智能、大數(shù)據(jù)等技術,為學生提供更高效的學習解決方案。因此業(yè)務上的數(shù)據(jù),主要是學生的到課情況、知識點掌握的情況這些。整體架構上,無論是 binlog 還是普通日志,經(jīng)過采集后寫入 Kafka,分別由實時和離線計算寫入存儲層,基于 OLAP 再對外提供對應的產(chǎn)品化服務,比如工作臺、BI 分析工具。
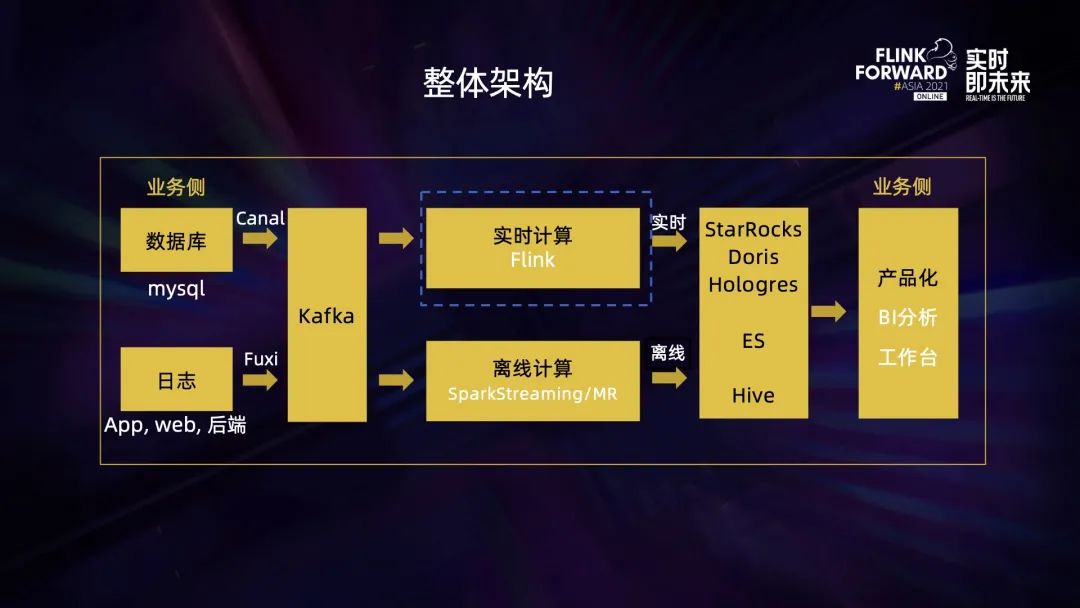
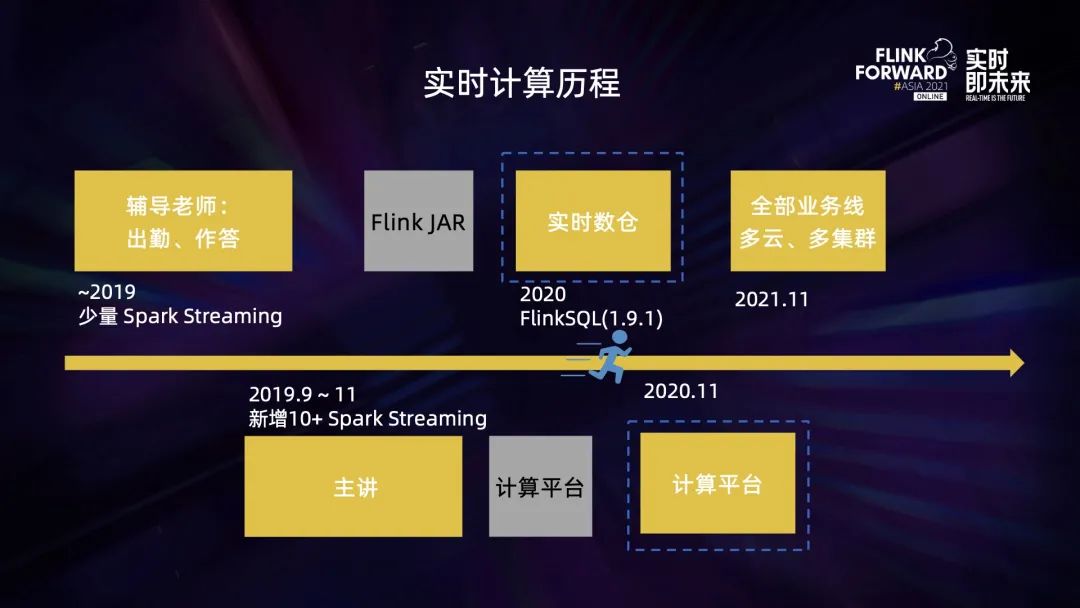
作業(yè)幫的實時計算目前基本以 Flink 為主,發(fā)展歷程大概有三個階段:
19 年,實時計算包含少量的 SparkStreaming 作業(yè),提供到輔導老師、主講側。在解決實時需求的過程中,就會發(fā)現(xiàn)開發(fā)效率很低,數(shù)據(jù)幾乎無法復用; 之后常規(guī)的做法,是在生產(chǎn)實踐中逐步應用 Flink JAR,積累經(jīng)驗后開始搭建平臺以及應用 Flink SQL。不過在 20 年,業(yè)務提出了非常多的實時計算需求,而我們開發(fā)人力儲備不足。當時 Flink SQL 1.9 發(fā)布不久,SQL 功能變化較大,所以我們的做法是直接在實時數(shù)倉方向應用 Flink SQL,目前整個實時數(shù)倉超過 90% 的任務都是使用 Flink SQL 實現(xiàn)的; 到了 20 年 11 月份,F(xiàn)link 作業(yè)很快增加到幾百條,我們開始從 0 到 1 搭建實時計算平臺,已經(jīng)支持了公司全部重要的業(yè)務線,計算部署在多個云的多個集群上。
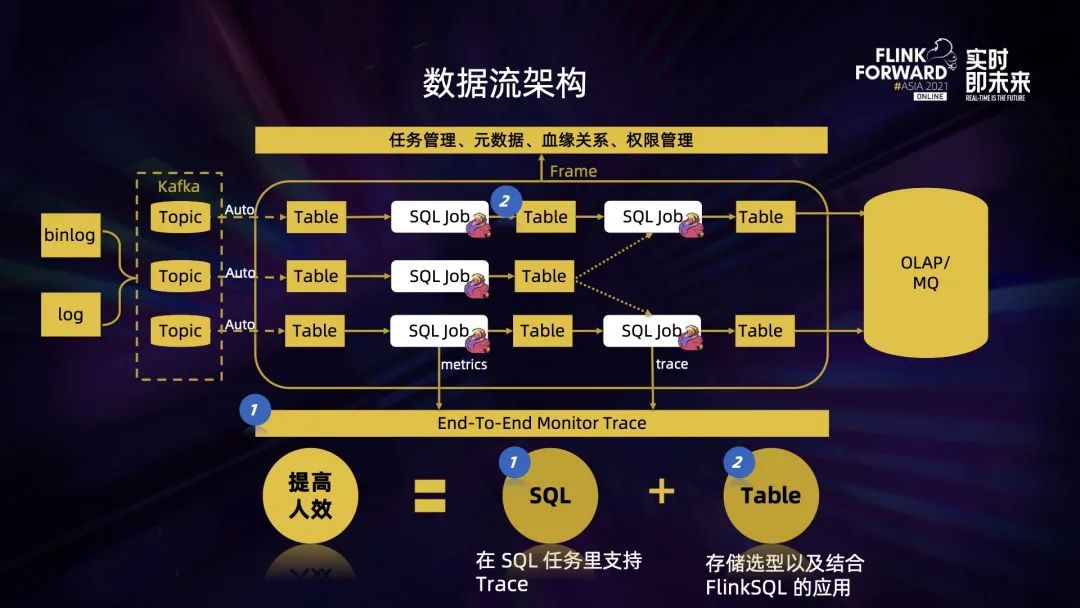
接下來介紹兩個方面:
FlinkSQL 實踐遇到的典型問題以及解決方案; 實時計算平臺建設過程中的一些思考。
二、Flink SQL 應用實踐
同時,考慮實際應用時,也需要在元數(shù)據(jù)表的基礎上,能夠對表屬性進行新增或者替換:
新增:元數(shù)據(jù)記錄的是表級別的屬性,但是 SQL 作業(yè)里可能需要增加任務級別的屬性。比如對于 Kafka 源表,增加作業(yè)的 group.id 來記錄 offset; 替換:線下測試時,在引用元數(shù)據(jù)表的基礎上,只需要定義 broker topic 等屬性覆蓋源表,這樣可以快速的構建一個線下測試表。
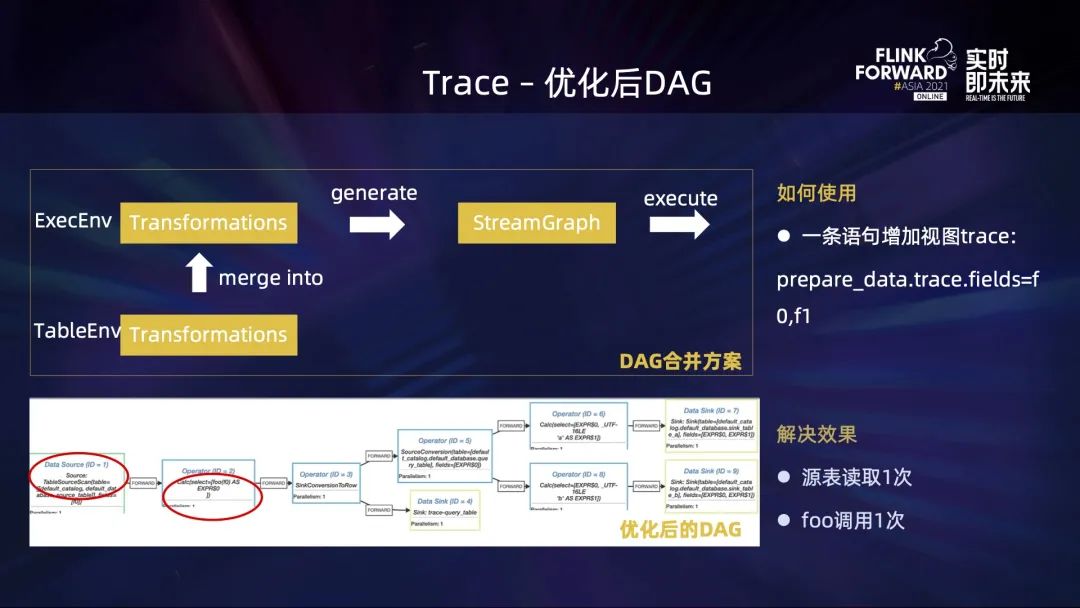
2.1 SQL 增加 Trace 功能


注:我們當時是基于 1.9 開發(fā)的,這里為了講述清楚,也使用了一些后來加入的 feature https://issues.apache.org/jira/browse/FLINK-16361 https://issues.apache.org/jira/browse/FLINK-18840
從上圖下方的實際 DAG 看不太符合預期:
DAG 被分成了上下不相關的兩部分,Kafka 源表也就是DataSource部分,讀取了兩次; foo 方法調用了三次。
2.2 Table 的選型及設計
我們的解決方案是基于 Redis 實現(xiàn),首先有幾點好處:
高 qps、低延遲:這個應該是所有實時計算都關注的; TTL:用戶不用關心數(shù)據(jù)如何退場,給定一個合理的 TTL 就可以了; 通過使用 protobuf 等高性能且緊湊的序列化方式,以及使用 TTL,存儲上整體不到 200G,redis 的內存壓力可以接受; 貼合計算模型:計算本身為了確保時序性,會進行 keyBy 的操作,把需要同時處理的數(shù)據(jù) shuffle 到同一并發(fā)上,因此也不依賴存儲過多考慮鎖的優(yōu)化。
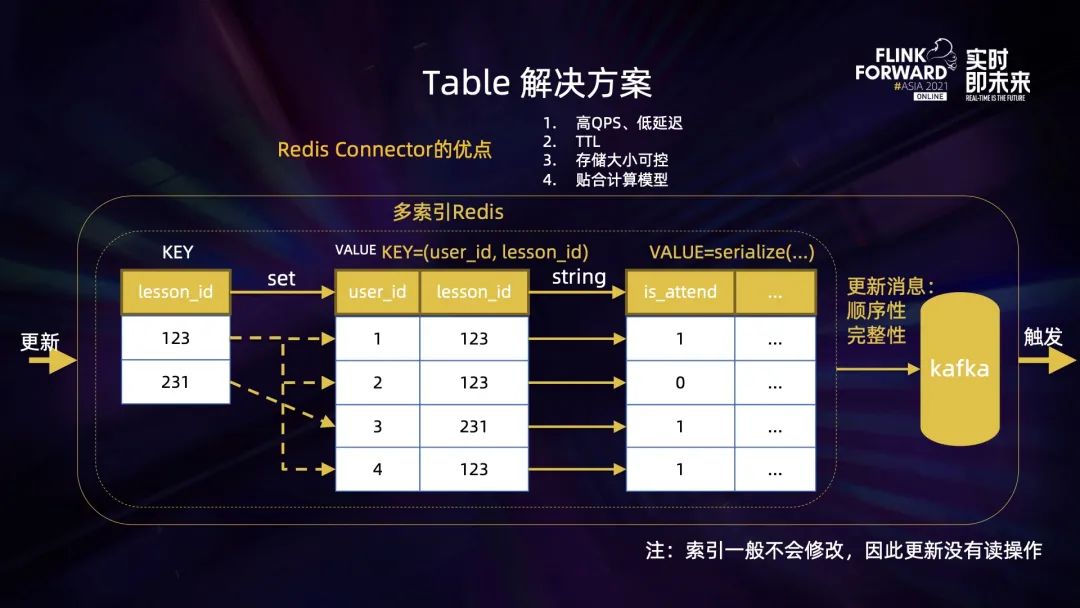
上圖舉了一個學生在某個章節(jié)是否到課的表的例子:
多索引:數(shù)據(jù)首先按照 string 格式存儲,比如 key=(uid, lesson_id), value=serialize(is_attend, ...),這樣我們就可以在 SQL 里 JOIN ON uid AND lesson_id 了。如果 JOIN ON 其他字段,比如 lesson_id 怎么辦?我們的做法,是會同時寫入一個 lesson_id 為 key 的 set,set 里的元素是對應的 (uid, lesson_id)。接下來查找 lesson_id = 123 時,先取出該 set 下所有元素,然后再通過 pipeline 的方式查找到所有的 VALUE 返回; 觸發(fā)消息:寫入 redis 后,會同時寫入一條更新消息到 Kafka. 兩個存儲之間的一致性、順序性、不丟數(shù)據(jù)都在 Redis Connector 的實現(xiàn)里保證。
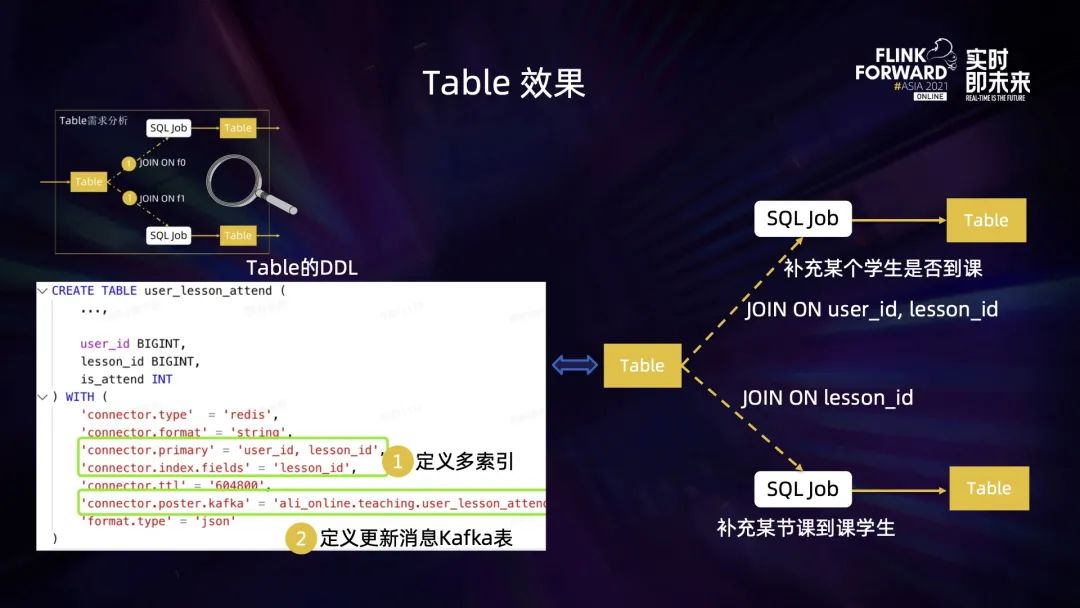
DDL 里幾個比較重要的屬性:
primary 定義了主鍵,對應 string 的數(shù)據(jù)結構,例如例子里的 uid + lesson_id; index.fields 定義了輔助查找的索引字段,例如例子里的 lesson_id;索引也可以定義多個; poster.kafka 定義接收觸發(fā)消息的 kafka 表,這個表同樣定義在了元數(shù)據(jù),用戶可以在后續(xù)的 SQL 作業(yè)里無需定義直接讀取該表。
三、平臺建設

平臺支持的功能,出發(fā)點主要有 3 個:
統(tǒng)一:統(tǒng)一不同云廠商不同的集群環(huán)境、Flink 版本、提交方式等;之前 hadoop 客戶端散落在用戶的提交機上,對集群數(shù)據(jù)、任務安全都有隱患,同時增加了集群后續(xù)的升級、遷移成本。我們希望通過平臺統(tǒng)一任務的提交入口以及提交方式; 易用:通過平臺交互能夠提供更多易用功能,比如調試、語義檢測,這些都能提高任務測試的人效,以及記錄任務的版本歷史支持方便的上線及回滾操作; 規(guī)范:權限控制、流程審批等,類似于在線服務的上線流程,通過平臺,能夠把實時任務的研發(fā)流程規(guī)范起來。
3.1 規(guī)范 - 實時任務流程管理

但是規(guī)范還是要執(zhí)行,有些問題類似在線服務,實時計算里也會遇到:
記不清:任務在線上跑了一年,最初的需求可能是口口相傳,好一點記了 wiki 或者郵件,但是都容易在任務交接中記不清楚; 不規(guī)范:UDF 也好,DataStream 的代碼也好,都沒有遵守規(guī)范,可讀性差,導致后面接手的同學升級改不動、或者不敢改,沒法長久的維護下去。包括實時任務的 SQL 怎么寫也應該有規(guī)范; 找不到:線上運行中的任務,依賴了某個 jar,對應的是哪個 git 模塊的哪個 commitId,出了問題怎么第一時間找到對應的代碼實現(xiàn); 瞎修改:一直正常的任務,周末突然報警了,原因是私自修改了線上任務的 SQL。
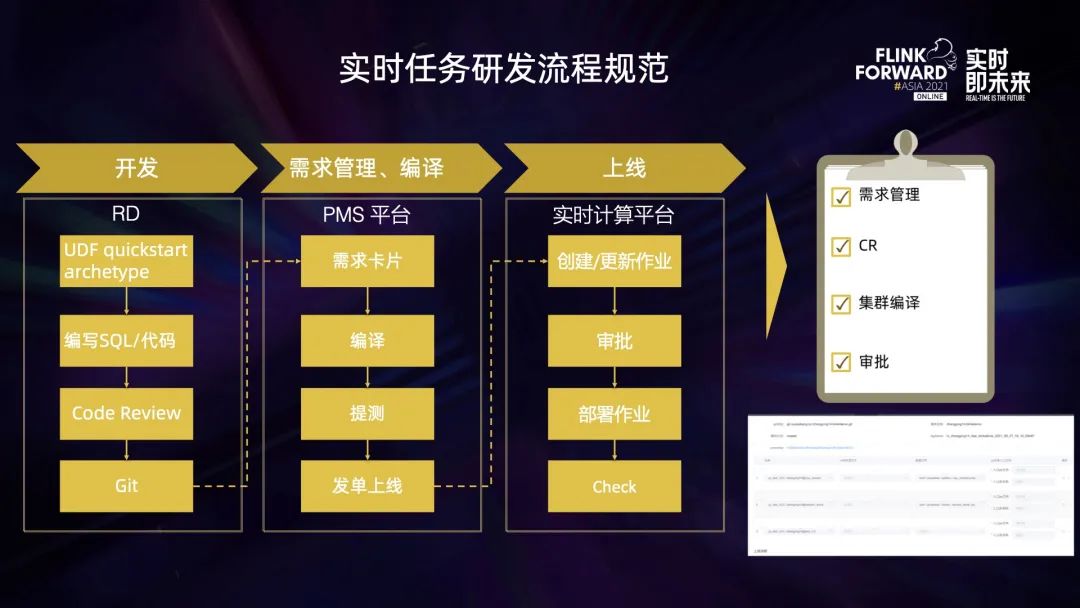
規(guī)范主要分為三部分:
開發(fā):RD 可以從 UDF archetype 項目上快速創(chuàng)建一個 UDF 模塊,這個是參考了 flink quickstart。創(chuàng)建出來的 UDF 模塊可以正常編譯,包含了類似 WordCount 這種 udf 示例,也有默認的 ReadMe、VersionHelper 這些輔助方法。按照業(yè)務需求修改后,經(jīng)過 CR 上傳到 Git; 需求管理、編譯:提交的代碼會關聯(lián)到需求卡片上,經(jīng)過集群編譯、QA測試,才能發(fā)單上線; 上線:根據(jù)模塊及編譯產(chǎn)出,選擇更新/創(chuàng)建哪些作業(yè),經(jīng)過作業(yè) owner 或者 leader 審批后,重新部署。
3.2 易用 - 監(jiān)控
我們目前的 Flink 作業(yè)都運行在 Yarn 上。作業(yè)啟動后,預期是 Prometheus 來抓取 Yarn 分配的 Container,然后對接報警系統(tǒng),用戶就可以基于報警系統(tǒng)配置 Kafka 延遲、Checkpoint 失敗這些報警。在搭建這條通路時主要遇到了兩個問題:
PrometheusReporter 啟動 HTTPServer 后,Prometheus 怎么能動態(tài)感知;也需要能夠控制 metric 的大小,避免采集大量無用數(shù)據(jù); 我們 SQL 的源表,基本是以 Kafka 為主。相比第三方的工具,在計算平臺上配置 Kafka 延遲報警會更加方便。因為能夠天然的拿到任務讀取的 topic、group.id,同時也可以跟任務失敗使用同一個報警組。再配合上報警模板,配置報警非常簡便。

在官方 PrometheusReporter 的基礎上增加了 discovery 的功能。Container 的 HTTPServer 啟動后,把對應的 ip:port 以臨時節(jié)點的形式注冊到 zk 上,然后利用 Prometheus 的 discover targets 監(jiān)聽 zk 節(jié)點的變化。由于是臨時節(jié)點,Container 銷毀時節(jié)點消失,Prometheus 也能夠感知不再抓取。這樣就很簡便的搭建起來 Prometheus 抓取的通路。 KafkaConsumer.records-lag 是比較實用、重要的延遲指標,主要做了兩個工作。修改 KafkaConnector,在 KafkaConsumer.poll 之后再 expose 出來,確保 records-lag 指標可見。另外在做這個的過程中,發(fā)現(xiàn)不同 Kafka 版本的這個指標格式不同(https://cwiki.apache.org/confluence/pages/viewpage.action?pageId=74686649),我們的做法是都打平為一種格式,注冊到 flink 的 metrics 里。這樣不同版本暴露出來的指標是一致的。
四、總結展望

下一步規(guī)劃主要分為三部分:
支持資源彈性伸縮,平衡實時作業(yè)的成本以及時效性; 我們是從 1.9 開始大規(guī)模應用 Flink SQL 的,現(xiàn)在版本升級變化很大,需要考慮如何讓業(yè)務能夠低成本的升級使用新版本里 feature; 探索流批一體在實際業(yè)務場景上的落地。
往期精選




? ??戳我,查看原文視頻~
??戳我,查看原文視頻~
評論
圖片
表情