
基于Flink打造實(shí)時(shí)計(jì)算平臺(tái)為企業(yè)賦能
點(diǎn)擊上方藍(lán)色字體,選擇“設(shè)為星標(biāo)”




隨著互聯(lián)網(wǎng)技術(shù)的廣泛使用,信息的實(shí)時(shí)性對(duì)業(yè)務(wù)的開展越來越重要,特別是業(yè)務(wù)的異常信息,沒滯后一點(diǎn)帶來的就是直接的經(jīng)濟(jì)損失。所以實(shí)時(shí)信息處理能力,越來越成為企業(yè)的重要競(jìng)爭(zhēng)力之一。Flink作為業(yè)內(nèi)公認(rèn)的性能最好的實(shí)時(shí)計(jì)算引擎,以席卷之勢(shì)被各大公司用來進(jìn)處理實(shí)時(shí)數(shù)據(jù)。然而Flink任務(wù)開發(fā)成本高,運(yùn)維工作量大,面對(duì)瞬息萬變得業(yè)務(wù)需求,工程師往往是應(yīng)接不暇。如果能有一套實(shí)時(shí)計(jì)算平臺(tái),讓工程師或者業(yè)務(wù)分析人員通過簡(jiǎn)單的SQL或者拖拽式操作就可以創(chuàng)建Flink任務(wù),無疑可以快速提升業(yè)務(wù)的迭代能力。
1. 方法論—Lambda架構(gòu)
如何設(shè)計(jì)大數(shù)據(jù)處理平臺(tái)呢?目前業(yè)界基本都是采用了Lambda架構(gòu)(Lambda Architecture),該架構(gòu)是由工程師南森·馬茨(Nathan Marz)在BackType和Twitter的大數(shù)據(jù)處理實(shí)踐中總結(jié)出的,示意圖如下。
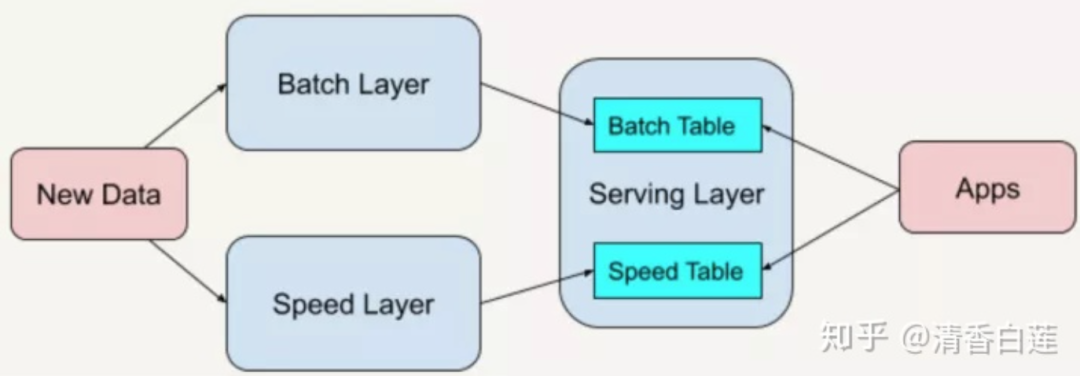
Lambda 共分為三層,分別是批處理層(Batch Layer),速度處理層(Speed Layer),以及服務(wù)層(Serving Layer),用途分別如下:
批處理層(Batch Layer),存儲(chǔ)管理主數(shù)據(jù)集和預(yù)先批處理計(jì)算好的視圖。這部分?jǐn)?shù)據(jù)對(duì)及時(shí)性要求不高,但對(duì)準(zhǔn)確性要求較高,會(huì)以批處理的方式同步到主庫中,處理過程通常以定時(shí)任務(wù)的形式存在。
速度處理層(Speed Layer),負(fù)責(zé)處理實(shí)時(shí)數(shù)據(jù)。這部分?jǐn)?shù)據(jù)需要實(shí)時(shí)的計(jì)算出結(jié)果,支持隨時(shí)供用戶查看,通常對(duì)準(zhǔn)確性要求不高,主要通過流式計(jì)算引擎計(jì)算出結(jié)果。通常這些數(shù)據(jù)最終還是會(huì)通過批處理層入庫,并針對(duì)部分計(jì)算結(jié)果進(jìn)行校驗(yàn)。
服務(wù)層(Serving Layer),數(shù)據(jù)進(jìn)入到平臺(tái)以后,會(huì)進(jìn)行存儲(chǔ)、同步、計(jì)算、分析等一系列分析計(jì)算過程。但是,最終都是需要提供給用戶使用的。針對(duì)業(yè)務(wù)需求的差異性,會(huì)有一個(gè)服務(wù)層將提煉出的數(shù)據(jù)以報(bào)表、儀表盤、API 接口等形式提供給用戶。
具體如何落實(shí),主要有兩種方式,業(yè)務(wù)場(chǎng)景和通用組件來進(jìn)行。
自底向上:從業(yè)務(wù)場(chǎng)景需求出發(fā),先做苦逼的數(shù)據(jù)搬運(yùn)工,再從中總結(jié)出重復(fù)與最耗時(shí)的工作進(jìn)行平臺(tái)化組件化,一步步堆磚頭添瓦,建立大數(shù)據(jù)平臺(tái)。這種方式可以讓數(shù)據(jù)針對(duì)具體的業(yè)務(wù)發(fā)揮作用,一開始效率非常低,需要大量的人肉工作,復(fù)雜的業(yè)務(wù)需求甚至需要資深的大數(shù)據(jù)開發(fā)工程師花費(fèi)多個(gè)人日才能處理。在平臺(tái)建設(shè)的過程中,平臺(tái)也可能會(huì)面臨不斷重構(gòu)的風(fēng)險(xiǎn)。工程團(tuán)隊(duì)與業(yè)務(wù)部門工作耦合度太高,消耗太多溝通成本。
自頂向下:先磨刀再砍柴,將大數(shù)據(jù)平臺(tái)中和具體的業(yè)務(wù)實(shí)現(xiàn)無關(guān)的通用功能組件抽離出來,做成簡(jiǎn)單易用的數(shù)據(jù)產(chǎn)品,常見的需求可以通過SQL或者簡(jiǎn)單的拖拽操作就能完成。這種方式處理需求效率高,門檻低,平臺(tái)做的好業(yè)務(wù)部們都可以自己分析數(shù)據(jù),而且工程師與業(yè)務(wù)部門工作耦合度低,可以花更多時(shí)間再平臺(tái)建設(shè)上。但前期投入成本大,對(duì)產(chǎn)品經(jīng)理/架構(gòu)師的經(jīng)驗(yàn)要求非常高,要能使開發(fā)的產(chǎn)品再未來很好的業(yè)務(wù)使用需求,否則很可能變成造輪子。
這兩種方式各有優(yōu)缺點(diǎn),具體采用哪種方式,可實(shí)際根據(jù)業(yè)務(wù)的特點(diǎn)來選擇,但更多的是兩種方式穿插采用。
2. 功能設(shè)計(jì)
Flink提供了多層的API,越上層的API使用起來越簡(jiǎn)單,但靈活性受限。越底層的API功能越強(qiáng)大,但對(duì)開發(fā)能力要求越高。

2.1 SQL定義任務(wù)
根據(jù)Uber的使用經(jīng)驗(yàn),70%的流處理任務(wù)都可以用SQL實(shí)現(xiàn),再結(jié)合UDF,基本上一般需求都能解決,業(yè)內(nèi)的大數(shù)據(jù)處理平臺(tái)上任務(wù)大部分都是也是以SQL+UDF的方式實(shí)現(xiàn)的,比如Hive,Dataworks,EasyCount與SparkSQL等。所以平臺(tái)開發(fā)語言以SQL為主,可以讓沒有大數(shù)據(jù)開發(fā)能力的業(yè)務(wù)分析人員就可以使用。通過SQL定義Flink任務(wù)的設(shè)計(jì)如下:
用DDL創(chuàng)建源表、(維表)、結(jié)果表;
用DML定義計(jì)算任務(wù)。
定義任務(wù)參數(shù),如計(jì)算資源、最大并行度、udf的jar包位置等。
示例如下:

目前(Flink 1.10)已經(jīng)實(shí)現(xiàn)了很多外部數(shù)據(jù)connector的DDL支持,對(duì)于不支持的數(shù)據(jù)源也可以通過擴(kuò)展Calcite語法,自己解析DDL,將source或sink的目標(biāo)對(duì)象映射成關(guān)系表。
Flink SQL得解析能力較弱,嵌套太多與太過復(fù)雜的SQL可能會(huì)解析失敗,所以INSERT語句不宜太復(fù)雜,可以添加對(duì)創(chuàng)建視圖的DDL的支持,簡(jiǎn)化對(duì)SQL子查詢的多次嵌套引用。這項(xiàng)功能在未來的Flink中會(huì)得到支持,具體詳見FLIP-71。目前可以通過在TableEnvironment API中將SELECT語句的執(zhí)行結(jié)果注冊(cè)為Table對(duì)象來實(shí)現(xiàn)。
Table table = tableEnvironment.sqlQuery("SELECT user_id, user_name, login_time FROM user_login_log");
tableEnvironment.registerTable("table_name", table);此外為了方便debug,可以實(shí)現(xiàn)對(duì)select語句的支持,直接打印處理結(jié)果,而不是sink到外部存儲(chǔ)。
然而SQL并非是圖靈完備語言,對(duì)于部分復(fù)雜的功能需求,可能很難甚至無法用SQL實(shí)現(xiàn)。這時(shí)候平臺(tái)需要支持讓用戶將自幾開發(fā)的Jar包上傳到平臺(tái)去運(yùn)行。
有了這兩項(xiàng)功能基本上已經(jīng)可以滿足所有的使用需求了,產(chǎn)品在此基礎(chǔ)上可以做得更加傻瓜化,也就是通過拖拽式操作來定義流失計(jì)算任務(wù)。
2.2 用戶自定義Jar
對(duì)于某些計(jì)算任務(wù)可能通過SQL定義的話執(zhí)行效率不高,通過Java或者Scala調(diào)用Flink更底層的API會(huì)更好,這時(shí)候我們希望平臺(tái)支持運(yùn)行用戶自定義Jar。實(shí)現(xiàn)方案如下:
要求用戶將Jar上傳到HDFS或者其他文件系統(tǒng),并在任務(wù)配置里面指定Jar的位置與執(zhí)行命令;
任務(wù)提交時(shí),平臺(tái)會(huì)解析任務(wù)配置,從文件系統(tǒng)下載用戶Jar包,并執(zhí)行任務(wù)的啟動(dòng)命令。
2.3 拖拽式操作
為了進(jìn)一步降低使用門檻或者提升開發(fā)效率,可以實(shí)現(xiàn)通過拖拽式操作來定義任務(wù)。其原理時(shí)將數(shù)據(jù)處理常見的SELECT、JOIN、Filter、INSERT操作以及Sink、Source Table和各種UDF等定義成流程圖中的節(jié)點(diǎn),用戶定義完流程圖后,平臺(tái)將流程圖轉(zhuǎn)化成SQL或者直接轉(zhuǎn)化成Flink代碼去執(zhí)行。
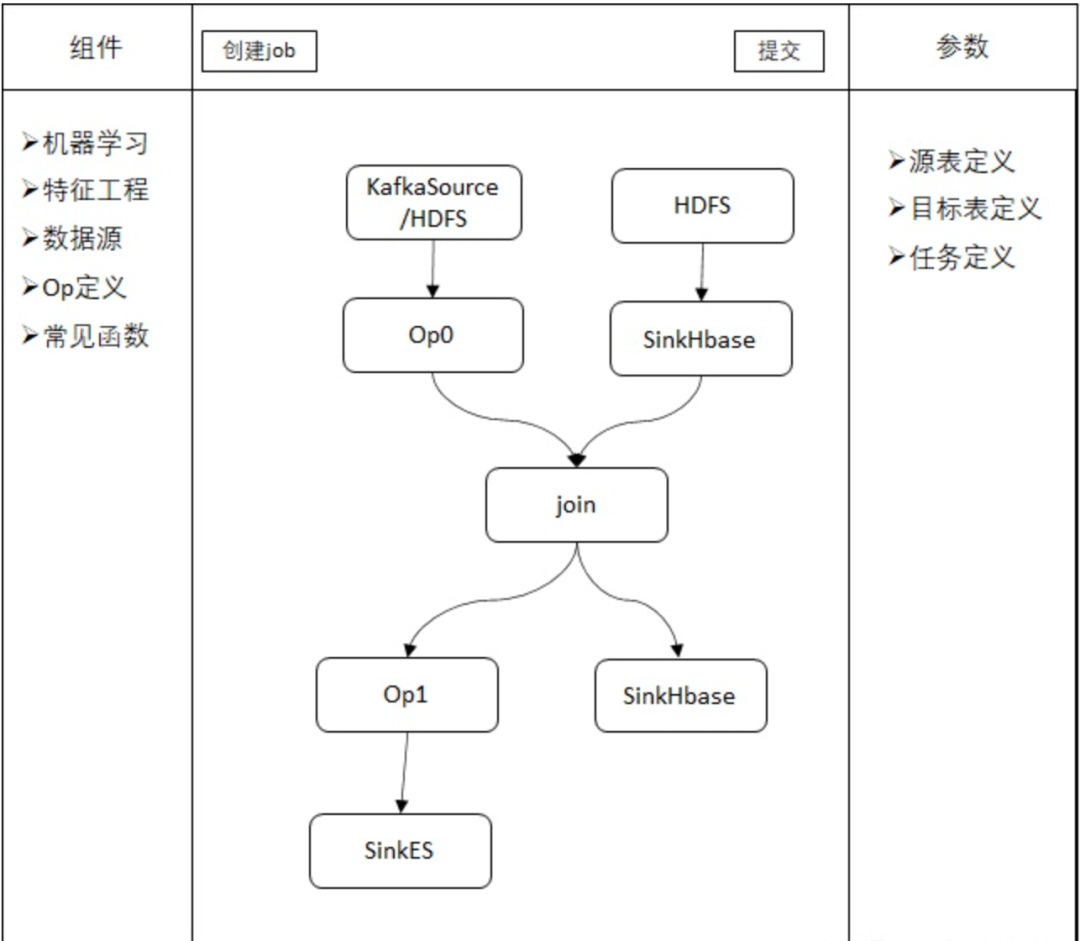
3. 平臺(tái)架構(gòu)設(shè)計(jì)
Flink通過對(duì)數(shù)據(jù)抽象成流表,實(shí)現(xiàn)了批流一體化的任務(wù)設(shè)計(jì),即同一套代碼即可以用于批處理也可以用于處理流失數(shù)據(jù),只需要修改數(shù)據(jù)源即可,處理邏輯完全不需要變。這就對(duì)實(shí)現(xiàn)Lamda架構(gòu)具備了天然優(yōu)勢(shì),不再需要專門的批處理引擎。整個(gè)平臺(tái)的架構(gòu)設(shè)計(jì)如下
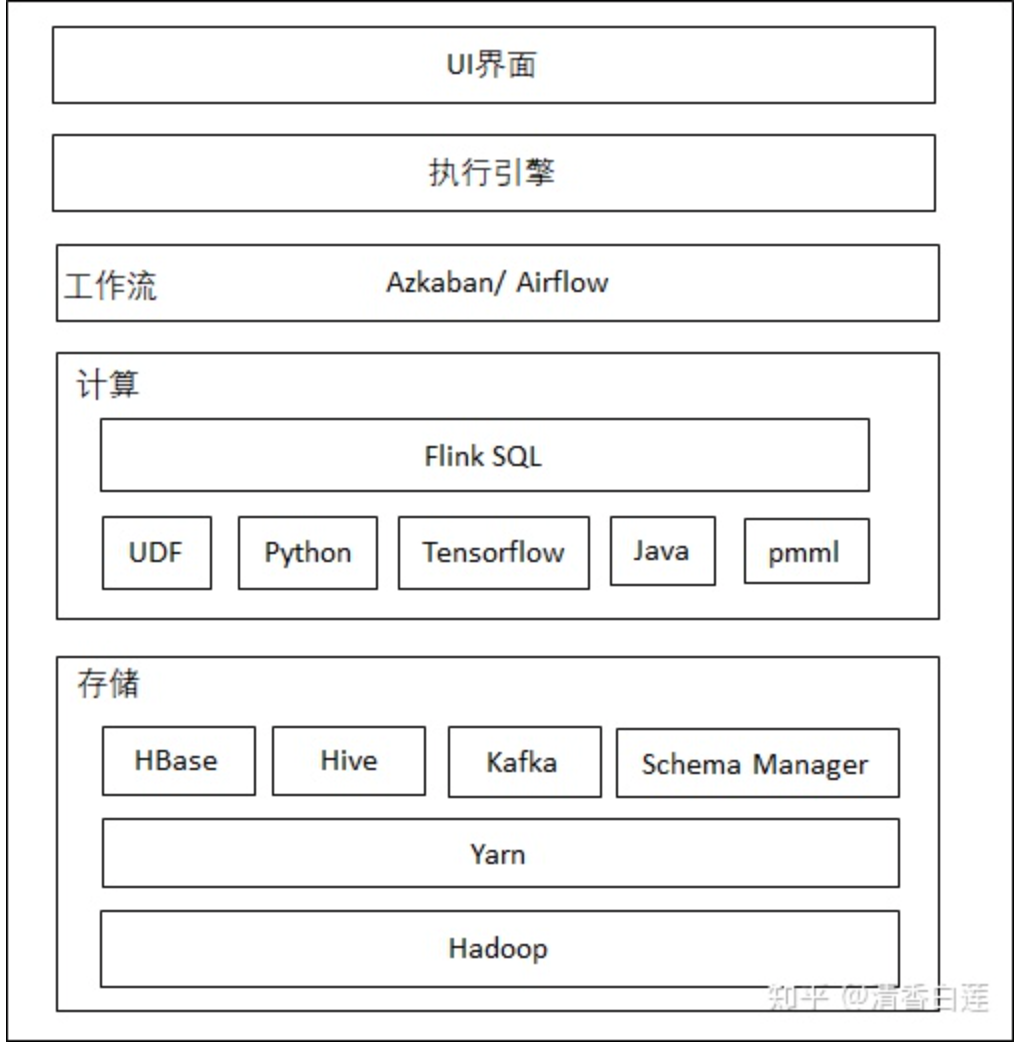
最上層為UI界面,常見任務(wù)有相應(yīng)的Op實(shí)現(xiàn),自定義任務(wù)采用Flink SQL與UDF或者用戶Jar。
執(zhí)行引擎將前端定義的業(yè)務(wù)流程通過Flink SQL API翻譯成Flink Job。
通過workflow對(duì)任務(wù)進(jìn)行調(diào)度。
在下面是負(fù)責(zé)執(zhí)行計(jì)算的flink,以及它可能會(huì)調(diào)用的其他框架,如機(jī)器學(xué)習(xí)、NLP等任務(wù)會(huì)調(diào)用tensorflow,stanford cornlp等。
最底層是物理集群,除了Flink任務(wù)外,外部數(shù)據(jù)存儲(chǔ)系統(tǒng)如HDFS、Hbase、Kafka等也可以跑在這個(gè)公共集群上。集群的管理通過Yarn或者K8S實(shí)現(xiàn)。
4. 集群資源管理
目前Flink已經(jīng)實(shí)現(xiàn)了在Yarn集群上的穩(wěn)定運(yùn)行,只要在Flink客戶端有Hadoop配置文件,就可以在客戶端通過Bash命令直接向Yarn集群提交Flink任務(wù),業(yè)內(nèi)主要也是用Yarn來管理運(yùn)行Flink任務(wù)的集群資源的,如Uber的AthenaX。Flink on Yarn提供了兩種運(yùn)行模式:
Session模式:先啟動(dòng)一個(gè)Flink集群,然后像該集群提交任務(wù),不同任務(wù)共用一個(gè)JobManager,即便沒有提交任務(wù)。由于需要預(yù)先啟動(dòng)一個(gè)Flink集群,即便沒有任務(wù)運(yùn)行,這部分物理集群資源也不能被回收;
Per-Job模式:為每個(gè)任務(wù)單獨(dú)啟動(dòng)一個(gè)集群,每個(gè)任務(wù)獨(dú)立運(yùn)行,物理集群資源可以根據(jù)任務(wù)數(shù)量按需申請(qǐng)。
這兩種方式各有優(yōu)缺點(diǎn),一般而言,如果式以頻繁提交的短期任務(wù),如批處理為主,則適合Session模式,如果以長(zhǎng)期運(yùn)行的流式任務(wù)為主,則適合用Per-Job模式。
K8S提供了更強(qiáng)大的集群資源管理工具,具有更好的用戶體驗(yàn),已經(jīng)發(fā)展為云服務(wù)廠商首選的資源管理與任務(wù)調(diào)度工具。Flink on K8S也是未來的發(fā)展趨勢(shì),F(xiàn)link社區(qū)也提供了相應(yīng)的docker image與K8S資源配置文件,用于在K8S集群中啟動(dòng)Flink集群運(yùn)行Flink任務(wù)。在Flink 1.11中將支持直接從Flink客戶端提交任務(wù)到K8S集群的功能。
5. 任務(wù)提交
有兩種模式可以將Flink任務(wù)提交到集群去執(zhí)行,即Client模式與Application模式,其中Application模式尚且不成熟,目前主要采用Client模式。
5.1 Client模式
在Client模式中,任務(wù)的提交需要有一個(gè)Flink Client,將任務(wù)需要的相關(guān)jar或者UDF都下載到本地,然后通過flink command編譯出任務(wù)的JobGraph,再將JobGraph與相關(guān)依賴提交給集群去執(zhí)行。目前業(yè)內(nèi)主要有兩者實(shí)現(xiàn)方式,個(gè)人推薦第二種方式:
啟動(dòng)一個(gè)client,所有作業(yè)都通過這個(gè)client去提交的,因?yàn)橛玫氖峭粋€(gè)進(jìn)程,所以不能加載 過多的jar包,還要注意不同任務(wù)之間UDF的沖突。
為每一個(gè)任務(wù)單獨(dú)啟動(dòng)一個(gè)client進(jìn)程(容器),在這個(gè)進(jìn)程內(nèi)下載需要的jar包,編譯出任務(wù)的JobGraph,并提交任務(wù)。這樣可以做到每個(gè)用戶用到的jar包或UDF不會(huì)沖突。

5.2 Application模式
在Client模式的缺點(diǎn)很顯著,如果請(qǐng)求量大的話,同一時(shí)刻Client需要下載大量jar包,并消耗大量CPU資源去編譯JobGraph,無論是網(wǎng)絡(luò)還是CPU都很容易成為系統(tǒng)瓶頸。
針對(duì)Client模式的確定,社區(qū)提出了Application模式,只需要將任務(wù)所需要地資源文件上傳到集群,在集群中完成Flink JobGraph的編譯與任務(wù)地執(zhí)行。Application模式社區(qū)也提出了兩種提交方式。
Flink-as-a-library
顧名思義,把flink本身作為需要本地化的依賴,用戶程序的main函數(shù)就是一個(gè)自足的應(yīng)用,因此可以直接用yarn命令來提交任務(wù)。
yarn jar MY_FLINK_JOB.jar myMainClass args...但如果集群是HA部署的話,同一時(shí)刻會(huì)有多個(gè)競(jìng)爭(zhēng)者執(zhí)行用戶程序的main函數(shù),但最后被選中的leader只有一個(gè),其他進(jìn)程需要自己退出main函數(shù)。這種打斷進(jìn)程的操作需要拋異常來實(shí)現(xiàn),這點(diǎn)在編程上很不優(yōu)雅。并且用戶對(duì)Flink集群的生命周期管理受限于execute()的時(shí)間窗口。
所以社區(qū)最終采納的是下面的ClusterEntrypoint模式。
ClusterEntrypoint
實(shí)現(xiàn)一個(gè)新的ClusterEntrypoint?即?ApplicationClusterEntryPoint?,其生命周期與用戶任務(wù)的main函數(shù)一致。它主要做以下這些事情
下載用戶jar與相關(guān)依賴資源;
選舉leader去執(zhí)行用戶程序的main函數(shù);
當(dāng)用戶的main函數(shù)執(zhí)行結(jié)束后終止該Flink集群;
確保集群的HA與容錯(cuò)性。
所以這種模式整個(gè)Flink集群的生命周期由ApplicationClusterEntryPoint,擁有更大的靈活性。目前該功能尚且處于開發(fā)階段,預(yù)計(jì)會(huì)在Flink 1.11中發(fā)布,具體進(jìn)展詳見FLIP-85。
此外如果采用的是Session模式在跑Flink on Yarn的話,還可以通過Web API來提交任務(wù)。
6. 任務(wù)編排
對(duì)于單個(gè)任務(wù)或者流式任務(wù)的編排,主要就是每個(gè)任務(wù)的優(yōu)先級(jí)問題,一般直接使用Yarn的調(diào)度功能就夠了。Yarn內(nèi)置了三種調(diào)度器,并且支持優(yōu)先級(jí)分?jǐn)?shù)的設(shè)置與優(yōu)先級(jí)ACL,一般需求都能滿足。
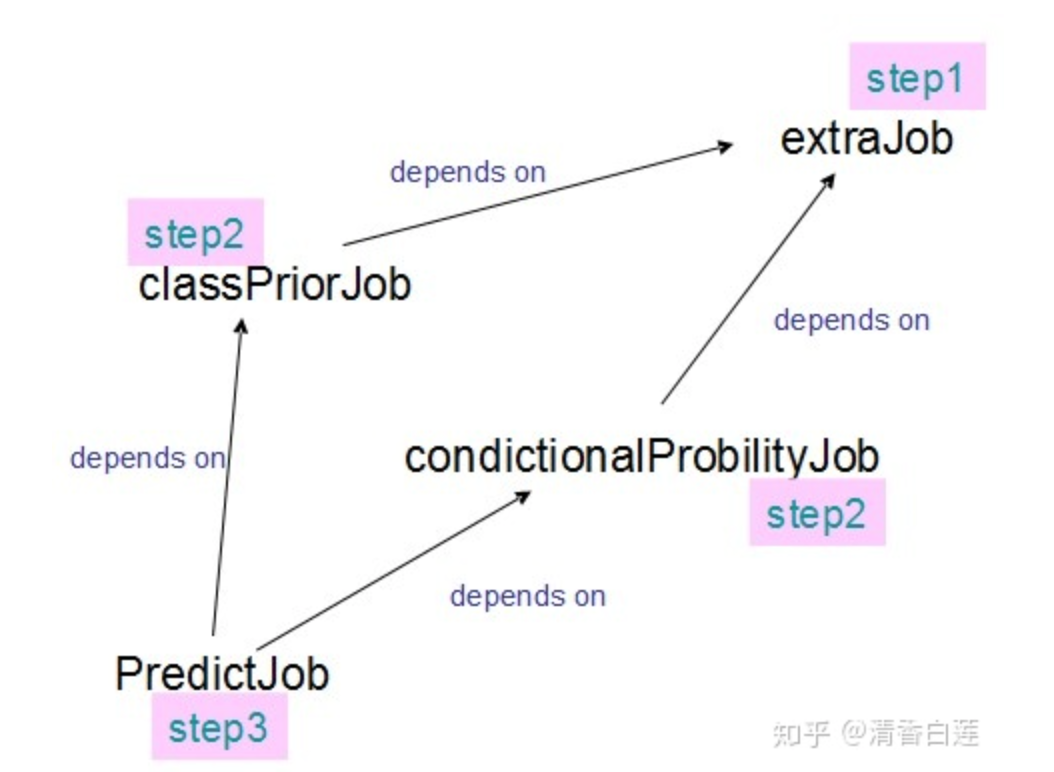
對(duì)于批處理任務(wù),整個(gè)pipeline中一般存在多個(gè)子任務(wù),不同子任務(wù)的執(zhí)行次序存在依賴關(guān)系。這時(shí)候一般采用專業(yè)的workflow框架去編排這些子任務(wù),workflow框架會(huì)對(duì)這些子任務(wù)進(jìn)行拓?fù)渑判颍偃フ{(diào)度執(zhí)行。常見的workflow有Airflow、Azkaban、Oozie、Conductor等,其中Airflow最為流行,但是它是個(gè)python項(xiàng)目,workflow也是用python定義的,Azkaban社區(qū)也較為活躍,原生支持Hadoop生態(tài)的任務(wù),用戶體驗(yàn)也較好。
7. 權(quán)限管理
平臺(tái)的建立最終是為用戶服務(wù)的,這就需要考慮用戶的多樣性,可能是企業(yè)內(nèi)部客戶、合作伙伴還有終端用戶。平臺(tái)需要根據(jù)不同用戶的不i同權(quán)限,提供不同的服務(wù)。在平臺(tái)建設(shè)過程中通常需要考慮:
用戶的權(quán)限和角色管理。
業(yè)務(wù)分組功能,針對(duì)業(yè)務(wù)分類、子分類對(duì)用戶進(jìn)行劃分。
根據(jù)數(shù)據(jù)功能進(jìn)行不同的安全等級(jí)管理,包括流程管理、血緣關(guān)系的管理等。
支持對(duì)元數(shù)據(jù)的檢索和瀏覽。
對(duì)于權(quán)限管理問題,Hadoop采用了Kerberos模塊來實(shí)現(xiàn)客戶端的身份認(rèn)證與ACL,在Flink on Yarn布署中,目前已經(jīng)支持在flink客戶端實(shí)現(xiàn)Kerberos認(rèn)證。
Kerberos只能提供服務(wù)器之間的認(rèn)證,企業(yè)需要更加精細(xì)化的權(quán)限控制,還需要更加復(fù)雜的ACL模塊,甚至是企業(yè)自己實(shí)現(xiàn)的ACL模塊。在Flink 1.11中安全訪問控制模塊將被實(shí)現(xiàn)為可插拔的而模塊,任何第三方的ACL模塊都可以輕松的集成進(jìn)來。
8. 元數(shù)據(jù)管理
元數(shù)據(jù)的管理是數(shù)倉建設(shè)必不可少的部分,可以讓用戶知道平臺(tái)中存在哪些數(shù)據(jù),他們的結(jié)構(gòu)是什么樣子,以及他們之間的關(guān)系。這樣一來,很多業(yè)務(wù)需求可以在已有的數(shù)據(jù)源的基礎(chǔ)上做些簡(jiǎn)單的計(jì)算就可以滿足,減少了大量的重復(fù)計(jì)算工作。
8.1 表管理
Hive提供了豐富的元數(shù)據(jù)存儲(chǔ)查詢功能,F(xiàn)link可以通過HiveCatalog來使用Hive的元存儲(chǔ)功能來實(shí)現(xiàn)跨session管理自己的元數(shù)據(jù)。用戶可以在某個(gè)任務(wù)里面將它的Kafka或者ElasticSerach表的Schema存入Hive的元數(shù)據(jù)庫,然后在另一個(gè)任務(wù)中通過HiveCatalog直接獲取并使用這些表。
此外Flink還可以直接讀寫Hive表。
8.2 血緣關(guān)系管理
可以通過解析每個(gè)flink sql任務(wù)的source、sink表以及維表,這樣就可以建立這些表之間的血緣關(guān)系。
9. 日志收集
日志可以幫助我們觀察整個(gè)作業(yè)運(yùn)行的情況,尤其是在job出問題之后,可以幫助我們復(fù)現(xiàn)問題現(xiàn)場(chǎng),分析原因。對(duì)于本地?zé)o法debug的代碼,也可以通過運(yùn)行日志來輔助debug。所以收集任務(wù)的運(yùn)行日志,對(duì)平臺(tái)的建設(shè)是必不可少的。
由于flink任務(wù)的運(yùn)行過程是先在客戶端編譯成JobGraph,再提交到Flink集群運(yùn)行,所以每個(gè)任務(wù)的日志包括客戶端的提交日志與任務(wù)在集群上的運(yùn)行日志。
9.1 client日志
Flink客戶端默認(rèn)使用的日志框架是log4j,可以通過修改conf/log4j-cli.properties文件對(duì)客戶端日志的輸出進(jìn)行設(shè)置。如進(jìn)行如下設(shè)置可以將flink客戶端INFO級(jí)別的日志輸出到控制臺(tái)與文件中。
log4j.rootLogger=INFO, file, console可以將通過配置輸出到郵件、消息隊(duì)列或者數(shù)據(jù)庫等,也可以通過自定義的Appender或者公司統(tǒng)一的日服API上報(bào)到公司統(tǒng)一的日志采集系統(tǒng)(如Flume、fluentd或者kafka等)。實(shí)際可根據(jù)平臺(tái)的架構(gòu)與用戶量將客戶端日志輸出到合適的位置供用戶查看。
9.2 cluster日志
如果Flink是運(yùn)行在 YARN 上,YARN 會(huì)幫我們做這件事,例如在 Container 運(yùn)行完成時(shí),YARN 會(huì)把日志收集起來傳到 HDFS,可以用命令 yarn logs -applicationId
當(dāng)然實(shí)際應(yīng)用中不大可能讓用戶這樣查看日志,一般還是要將日志上報(bào)到專業(yè)的日志服務(wù)框架如EFK中,用戶通過報(bào)表(如Kibana)或者API來查看,甚至配置郵件短信報(bào)警等。我們利用基于Flume的Log4j Appender 定制了自己的日志收集器,從服務(wù)器異步發(fā)送日志到Kafka中,再通過Kafka將日志傳到日服的數(shù)據(jù)庫中(一般是Elasticsearch)。這樣可以盡可能地降低日志采集對(duì)運(yùn)行作業(yè)的影響。
如果Flink是運(yùn)行再K8S 上,K8S本身并沒有提供日志收集功能,目前一般是使用 fluentd來收集日志。
fluentd是一個(gè)CNCF項(xiàng)目,它通過配置一些規(guī)則,比如正則匹配,就可以將logs目錄下的*.log 、*.out 及 *.gc日志定期的上傳到 HDF 或者通過kafa寫入Elasticsearch 集群,以此來解決我們的日志收集功能。這也意味著在Flink集群的POD里面,除了運(yùn)行TM或JM容器之外,我們需要再啟動(dòng)一個(gè)運(yùn)行著fluentd進(jìn)程的容器(sidecar)。
10. 監(jiān)控報(bào)警
在job出問題后,雖然日志可以幫助我復(fù)現(xiàn)問題現(xiàn)場(chǎng),分析原因。但最好還是可以實(shí)時(shí)監(jiān)控任務(wù)的運(yùn)行狀況,出現(xiàn)問題能及時(shí)報(bào)警,好做出應(yīng)急措施,防止發(fā)生生產(chǎn)事故。目前業(yè)界已經(jīng)有很多種監(jiān)控系統(tǒng)解決方案,比如在阿里內(nèi)部使用比較多的 Druid、開源InfluxDB 或者商用集群版 InfluxDB、CNCF的 Prometheus 或者 Uber 開源的 M3 等等。
10.1 Prometheus
Prometheus是一個(gè)開源的,基于metrics(度量)的一個(gè)開源監(jiān)控系統(tǒng),誕生于2012年,主要是使用go語言開發(fā)的,并于2016年成為成為CNCF第二個(gè)成員,現(xiàn)已被大量的組織使用于工業(yè)生產(chǎn)環(huán)境中。

Prometheus在指標(biāo)采集領(lǐng)域具備先天優(yōu)勢(shì),它提供了強(qiáng)大的數(shù)據(jù)模型和查詢語言,不僅可以很方便的查看系統(tǒng)的性能指標(biāo),還可以結(jié)合mtail從日志中提取Metric指標(biāo),如Error出現(xiàn)次數(shù),發(fā)送到時(shí)間序列數(shù)據(jù)庫,實(shí)現(xiàn)日志告警。
對(duì)于Flink任務(wù)平臺(tái)需要支持監(jiān)控以下指標(biāo)
Flink本身的metric,可以將精確到每個(gè)subtask的operator,主要通過promethues push gateway上報(bào)。
Flink Cluster、task/operator IO、JVM 、Source、Sink、維表IO等。
任務(wù)延遲,重啟次數(shù)等。
自定義Metric,一般針對(duì)具體任務(wù)。
10.2 Grafana
有了Prometheus來監(jiān)控任務(wù)后,還需要有一個(gè)可視化工具來展示Prometheus收集的指標(biāo)。Grafana是Prometheus的最佳搭檔,它是一款用Go語言開發(fā)的開源數(shù)據(jù)可視化工具,可以做數(shù)據(jù)監(jiān)控和數(shù)據(jù)統(tǒng)計(jì),帶有告警功能,并且自帶權(quán)限管理功能。
Grafana支持的可視化方式有很多種,不過Graph、Table、Pie chart 這三種基本就已經(jīng)滿足數(shù)據(jù)展現(xiàn)要求了。

使用起來也很簡(jiǎn)單,跟商業(yè)的BI報(bào)表工具類似,先選擇圖表類型

然后選擇數(shù)據(jù)庫,寫好sql,就可以制定一個(gè)報(bào)表。

11. 總結(jié)
流失計(jì)算是在內(nèi)存中事實(shí)進(jìn)行的,數(shù)據(jù)很多時(shí)候也是直接來自生產(chǎn)環(huán)境,無論是框架還是業(yè)務(wù)邏輯都比批處理復(fù)雜多了。對(duì)平臺(tái)的建設(shè)也提出了嚴(yán)峻的挑戰(zhàn),F(xiàn)link作為新一代的流失計(jì)算引擎,功能還在不斷完善中,剛開始使用必然會(huì)踩很多坑。當(dāng)然踩坑的過程也是學(xué)習(xí)的過程,為了趟過坑,你必然要做很多的技術(shù)調(diào)研,對(duì)平臺(tái)與很多組件的認(rèn)知也會(huì)不斷加深。


版權(quán)聲明:
文章不錯(cuò)?點(diǎn)個(gè)【在看】吧!??