
nnUNet圖像分割教程!從環(huán)境配置到訓(xùn)練與推理

向AI轉(zhuǎn)型的程序員都關(guān)注了這個號??????
nnUNet是什么?
nnU-Net是由德國癌癥研究中心、海德堡大學(xué)以及海德堡大學(xué)醫(yī)院研究人員(Fabian Isensee, Jens Petersen, Andre Klein)提出來的一個自適應(yīng)任何新數(shù)據(jù)集的醫(yī)學(xué)影像分割框架,該框架能根據(jù)給定數(shù)據(jù)集的屬性自動調(diào)整所有超參數(shù),整個過程無需人工干預(yù)。僅僅依賴于樸素的U-Net結(jié)構(gòu)(就是原始U-Net)和魯棒的訓(xùn)練方案,nnU-Net在六個得到公認的分割挑戰(zhàn)中實現(xiàn)了最先進的性能。
關(guān)于nnUNet,如果你想更加深入的了解,我推薦看一下這論文
https://arxiv.org/abs/1809.10486
更深入的學(xué)習(xí)還是建議精讀論文。
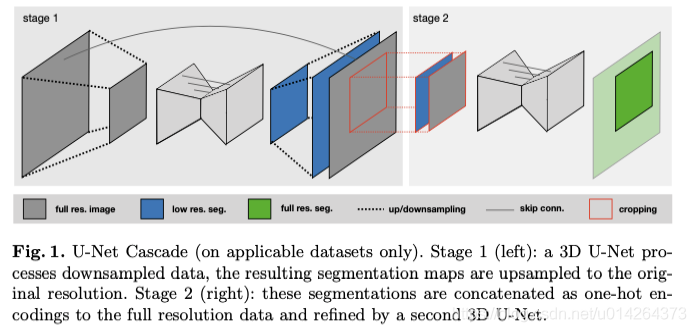
一、配置虛擬環(huán)境

上圖所示為nnUNet的官方readme文檔建議的環(huán)境配置,如果你對cuda,cudnn,torch之類的詞語還不算熟悉,可以看一下我的另一篇博客用人話講解深度學(xué)習(xí)中CUDA,cudatookit,cudnn和pytorch的關(guān)系
https://blog.csdn.net/m0_68239345/article/details/128803487?spm=1001.2014.3001.5501
至于為什么要在虛擬環(huán)境中安裝nnUNet,當(dāng)我們在安裝包的時候,pip install django安裝一個包會附帶安裝數(shù)個其他關(guān)聯(lián)的包。但是當(dāng)我們刪除這個包的時候,我們之后僅僅刪除這一個包,安裝時附帶的其他包并不會刪除。**簡單來說,當(dāng)我們的環(huán)境使用時間長的時候,我們的包是很難進行管理的。**所以非常建議在一個全新的虛擬環(huán)境中來完成接下來的操作!!!
二、安裝nnUNet框架
此時,你應(yīng)該已經(jīng)配置好了自己的虛擬環(huán)境并且可以打印出類似上圖的環(huán)境版本(可以更高,但最好不要太低),注意,后續(xù)的操作均要在你激活你想要使用的那個虛擬環(huán)境的前提下進行!!!!
1.安裝nnUNet
根據(jù)readme文檔,這里應(yīng)該有兩種方案可供選擇
(1)用作標準化基線、開箱即用的分割算法或使用預(yù)訓(xùn)練模型進行推理:
pip install nnunet
git clone https://github.com/MIC-DKFZ/nnUNet.git
cd nnUNet
pip install -e .#最后這個點也不能忽略
對于我來說,因為我后續(xù)是要改網(wǎng)絡(luò)代碼的,所以我選擇第二種方法,下面詳細說明一下這三行命令都是什么意思:
git clone其實就是把人家github上的代碼克隆過來,這一步其實和直接復(fù)制粘貼代碼文件是一樣的,總共也就1Mb
cd nnUNet不用說了,就是進入文件夾
其實這個時候就已經(jīng)有一個nnUNet完整的文件夾了,里面包含這些東西:

最后pip install -e .相當(dāng)于python setup.py,也就是運行上圖這個setup.py文件
這個文件是用來干什么的呢?
安裝nnUNet需要的python包
向終端添加幾個新命令。這些命令用于運行整個nnU-Net pipeline。您可以從系統(tǒng)上的任何位置執(zhí)行它們。所有nnU-Net命令都帶有前綴“nnUNet_”,以便于識別。
這一步我遇到的兩個問題:
(1)從github上git clone代碼的時候速度慢的離譜(20kb/s),這個問題主要是github的域名在國內(nèi)被限制了,網(wǎng)上有很多方法解決,比如下面這個網(wǎng)址可以參考https://www.jianshu.com/p/d58ab49ba98b
(2)運行pip命令的時候速度很慢,這個問題導(dǎo)致我運行pip install -e .的時候超時報錯了,同樣給出解決方法的鏈接解決Linux,Ubuntu下使用python包管理工具pip命令安裝和下載包速度很慢、失敗或者connection timeout等問題_一點兒也不萌的萌萌的博客-CSDN博客_linux 下載python failed: connection timed out.
2.安裝隱藏層hiddenlayer(可選)
隱藏層使nnU-net能夠給出其生成的網(wǎng)絡(luò)拓撲圖(后面會細說),安裝命令如下(這是一整行命令,請務(wù)必一起復(fù)制粘貼)
pip install
--upgrade git+https://github.com/FabianIsensee/hiddenlayer.git@more_plotted_details#egg=hiddenlayer
這里我遇到的唯一問題就是上面說的pip命令速度太慢,也是根據(jù)上述解決方案來解決的。
三、數(shù)據(jù)集準備
nnUNet對于你要訓(xùn)練的數(shù)據(jù)是有嚴格要求的,這第一點就體現(xiàn)在我們保存數(shù)據(jù)的路徑上,請初學(xué)者務(wù)必按照我下面的樣式來創(chuàng)建相應(yīng)的文件夾并存入數(shù)據(jù)!!!
第一步:你現(xiàn)在應(yīng)該有一個名為nnUNet的文件夾(上面有圖),進入它,在里面創(chuàng)建一個名為nnUNetFrame的文件夾

第二步:在nnUNetFrame文件夾中創(chuàng)建一個名為DATASET的文件夾,后面我們會用它來存放數(shù)據(jù)

第三步:在DATASET文件夾中創(chuàng)建三個文件夾,它們分別是nnUNet_raw,nnUNet_preprocessed,nnUNet_trained_models

第四步:進入上面第二個文件夾nnUNet_raw,創(chuàng)建nnUNet_cropped_data文件夾和nnUNet_raw_data文件夾,右邊存放原始數(shù)據(jù),左邊存放crop以后的數(shù)據(jù)。

第五步:進入右邊文件夾nnUNet_raw_data,創(chuàng)建一個名為Task01_BrainTumour的文件夾(解釋:這個Task01_BrainTumour是nnUNet的作者參加的一個十項全能競賽的子任務(wù)名,也是我要實踐的分割任務(wù),類似的還有Task02_Heart,就是分割心臟的。如果你想分割自己的數(shù)據(jù)集,建議Task_id從500開始,這樣以確保不會與nnUNet的預(yù)訓(xùn)練模型發(fā)生沖突(ID不能超過999))
第六步:將下載好的公開數(shù)據(jù)集或者自己的數(shù)據(jù)集放在上面創(chuàng)建好的任務(wù)文件夾下,下面還以Task01_BrainTumour競賽為例,解釋下數(shù)據(jù)應(yīng)該怎么存放和編輯:
進入這個網(wǎng)站http://medicaldecathlon.com/.下載對應(yīng)的數(shù)據(jù)集(<–網(wǎng)上學(xué)科議建<–),取代上面你自己創(chuàng)建的Task01_BrainTumour文件夾。
你會發(fā)現(xiàn)目錄是這個樣子的:json文件是對三個文件夾內(nèi)容的字典呈現(xiàn)(關(guān)乎你的訓(xùn)練),imagesTr是你的訓(xùn)練數(shù)據(jù)集,打開后你會發(fā)現(xiàn)很多的有序的nii.gz的訓(xùn)練文件,而labelsTr里時對應(yīng)這個imagesTr的標簽文件,同樣為nii.gz。目前只能是nii.gz文件,nii文件都不行。訓(xùn)練階段的imageTs文件夾先不管,其實這個文件夾出現(xiàn)在任何位置都可以。(解釋:nnUNet使用的是五折交叉驗證,并沒有驗證集)

四、設(shè)置nnUNet讀取文件的路徑
nnUNet是如何知道你的文件存放在哪兒呢,當(dāng)然要在環(huán)境中創(chuàng)建一個路徑,這個路徑你唯一需要更改的是/nnUNet之前的路徑,因為后面的路徑你和我是一樣的。
第一步:在home目錄下按ctrl + h,顯示隱藏文件
第二步:找到.bashrc文件,打開
第三步:在文檔末尾添加下面三行,保存文件。

第四步:在home下打開終端,輸入source .bashrc來更新該文檔
現(xiàn)在nnUNet已經(jīng)知道怎么讀取你的文件了。
五、數(shù)據(jù)集轉(zhuǎn)換
1.數(shù)據(jù)集轉(zhuǎn)換是什么,為什么要進行數(shù)據(jù)集轉(zhuǎn)換?
nnUNet要求將原始數(shù)據(jù)轉(zhuǎn)換成特定的格式,以便了解如何讀取和解釋數(shù)據(jù)。
每個分割數(shù)據(jù)集存儲為單獨的“任務(wù)”。命名包括任務(wù)與任務(wù)ID,即三位整數(shù)和相關(guān)聯(lián)的任務(wù)名稱。
比如Task001_BrainTumour的任務(wù)名稱為“腦瘤”,任務(wù)ID為1。
在每個任務(wù)文件夾中,預(yù)期的結(jié)構(gòu)如下:

圖像可能具有多種模態(tài),這對于醫(yī)學(xué)圖像來說尤其常見。
nnU-Net通過其后綴(文件名末尾的四位整數(shù))識別成像模態(tài)。因此,圖像文件必須遵循以下命名約定:case_identifier_XXXX.nii.gz
這里,XXXX是模態(tài)標識符。dataset.json文件中指定了這些標識符所屬的模態(tài)
標簽文件保存為case_identifier.nii.gz
此命名方案產(chǎn)生以下文件夾結(jié)構(gòu)。用戶有責(zé)任將其數(shù)據(jù)轉(zhuǎn)換為這種格式!
下面是MSD的第一個任務(wù)的示例:BrainTumor。每個圖像有四種模態(tài):FLAIR(0000)、T1w(0001)、T1gd(0002)和T2w(0003)。請注意,imagesTs文件夾是可選的,不必存在
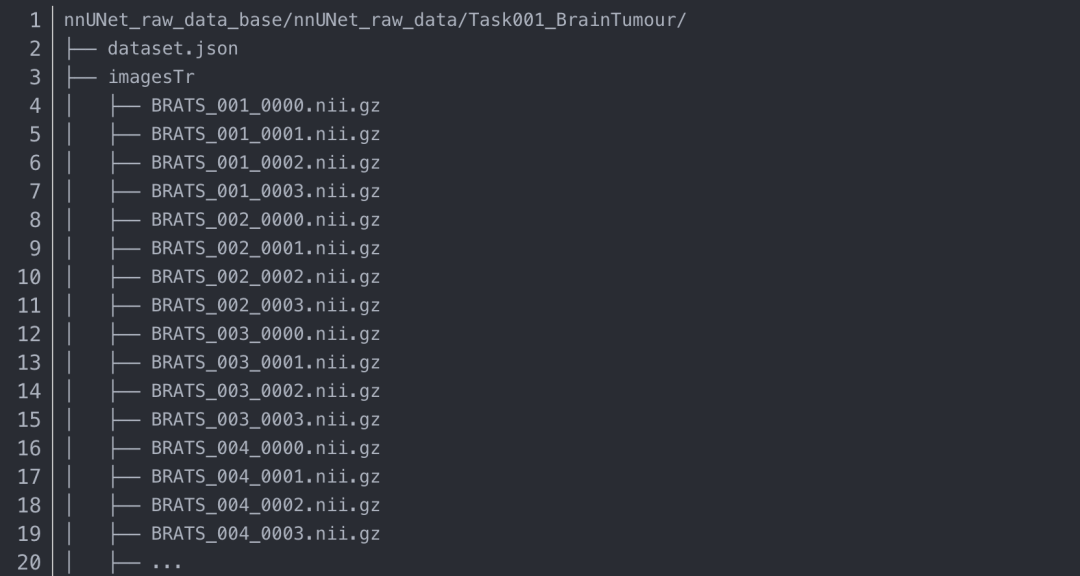
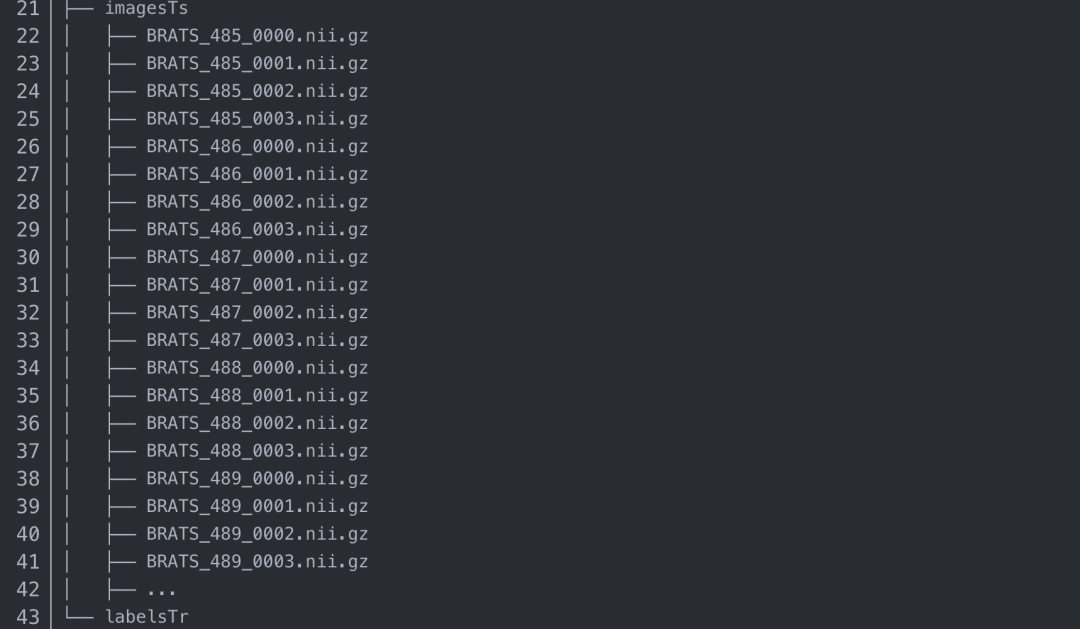

2.運行數(shù)據(jù)集轉(zhuǎn)換的命令
nnUNet_convert_decathlon_task -i /home/work/nnUNet/nnUNetFrame/DATASET/nnUNet_raw/nnUNet_raw_data/Task01_BrainTumour
轉(zhuǎn)換操作完成以后,你會發(fā)現(xiàn)在你的Task01_BrainTumour文件夾旁邊,出現(xiàn)了一個Task001_BrainTumour文件夾,打開看一下,里面的格式應(yīng)該和我上面展示的一樣
3.關(guān)于dataset.json文件
這個文件包含你的訓(xùn)練數(shù)據(jù)信息和任務(wù)信息,如果你按照我的建議下載了Task01的數(shù)據(jù)集,那里面是包含dataset.json文件的,如果你有訓(xùn)練自己的數(shù)據(jù)集的需求,在我的另一篇博客里會有詳細的說明。
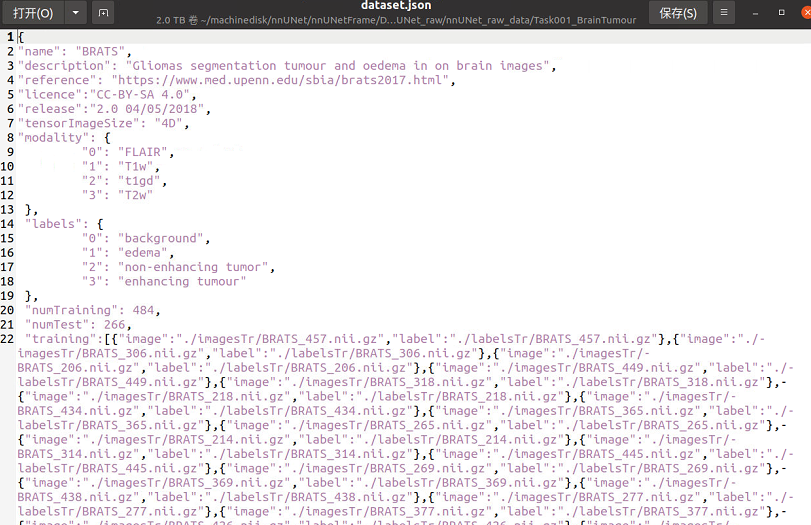
六、數(shù)據(jù)預(yù)處理
nnUNet_plan_and_preprocess -t 1 --verify_dataset_integrity
只需要一行命令,因為我們的Task_id是1,所以這里的數(shù)字就是1。這個過程會消耗很多的時間,速度慢的原因在于對要進行插值等各種操作。
根據(jù)nnUNet框架,三維醫(yī)學(xué)圖像分割的通用預(yù)處理可以分為四步,分別是數(shù)據(jù)格式的轉(zhuǎn)換,裁剪crop,重采樣resample以及標準化normalization。如果你想進一步學(xué)習(xí),推薦學(xué)習(xí)這篇文章如何針對三維醫(yī)學(xué)圖像分割任務(wù)進行通用數(shù)據(jù)預(yù)處理:nnUNet中預(yù)處理流程總結(jié)及代碼分析
https://zhuanlan.zhihu.com/p/335970913
運行“nnUNet_plan_and_preprocess”將使用預(yù)處理數(shù)據(jù)填充文件夾
我們將在nnUNet_preprocessed/Task001_BrainTumour中找到這條命令的輸出結(jié)果。使用2D U-Net以及所有適用的3D U-Net的預(yù)處理數(shù)據(jù)創(chuàng)建子文件夾。它還將為2D和3D配置創(chuàng)建“plans”文件(結(jié)尾為.pkl)。這些文件包含生成的分割 pipeline 配置,將由nnUNetTrainer讀取(見下文)。請注意,預(yù)處理的數(shù)據(jù)文件夾僅包含訓(xùn)練案例。測試圖像沒有經(jīng)過預(yù)處理。測試集的預(yù)處理將會在推理過程中實時進行。

另外,`–verify_dataset_integrity”應(yīng)至少在給定數(shù)據(jù)集上首次運行命令時運行。這將對數(shù)據(jù)集執(zhí)行一些檢查,以確保其與nnU-Net兼容。如果此檢查通過一次,則可以在以后的運行中省略。如果您遵守數(shù)據(jù)集轉(zhuǎn)換指南(請參見上文),那么這條命令一定會通過的。
七、模型訓(xùn)練
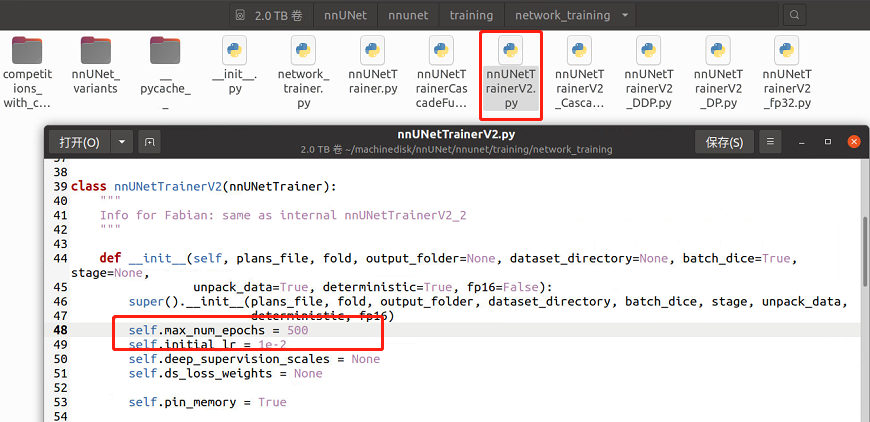
1.寫在訓(xùn)練前:更改epoch
nnUNet默認原始的epoch是1000,這太久了,我們打開nnUNet/nnunet/training/network_training/nnUNetTrainerV2.p
第48行的max_epoch來修改epoch
2.關(guān)于訓(xùn)練的運行命令
nnU-Net在5倍交叉驗證中訓(xùn)練所有U-Net配置。這使nnU-Net能夠確定訓(xùn)練數(shù)據(jù)集的后處理和集合(參見下文)
我們在數(shù)據(jù)預(yù)處理那一步的時候創(chuàng)建了三個U-Net配置:2D U-Net、對全分辨率圖像進行操作的3D U-Net以及3D U-Net級聯(lián),其中級聯(lián)的第一個U-Net在下采樣圖像中創(chuàng)建粗分割圖,然后由第二個U-Net進行細化。我們在訓(xùn)練的時候可以自由選用它們。
訓(xùn)練模型使用“nnUNet_train”命令完成。命令的一般結(jié)構(gòu)為:
nnUNet_train CONFIGURATION TRAINER_CLASS_NAME TASK_NAME_OR_ID FOLD --npz (additional options)
CONFIGURATION是一個字符串,用于標識所請求的U-Net配置。
TRAINER_CLASS_NAME是model trainer的名稱。如果您實施定制trainers(nnU-Net作為一個框架),您可以在此處指定您的定制trainers。
TASK_NAME_OR_ID指定應(yīng)訓(xùn)練的數(shù)據(jù)集,F(xiàn)OLD指定訓(xùn)練的是5倍交叉驗證的哪一倍。
“–npz”使模型在最終驗證期間保存softmax輸出。它僅適用于計劃在之后運行“nnUNet_find_best_configuration”的訓(xùn)練
(這是nnU Nets自動選擇最佳性能(集合)配置,見下文)。
對于我們的Task01來說,應(yīng)該運行的命令如下
nnUNet_train 3d_fullres nnUNetTrainerV2 1 0 --npz
3d_fullres代表我們選用對全分辨率圖像進行操作的3D U-Net
nnUNetTrainerV2是我們選用的訓(xùn)練器
1代表你的任務(wù)ID
0代表五折交叉驗證中的第0折
下面給出各種配置的nnUNet網(wǎng)絡(luò)需要的訓(xùn)練命令
2D U-Net
For FOLD in [0, 1, 2, 3, 4], run:
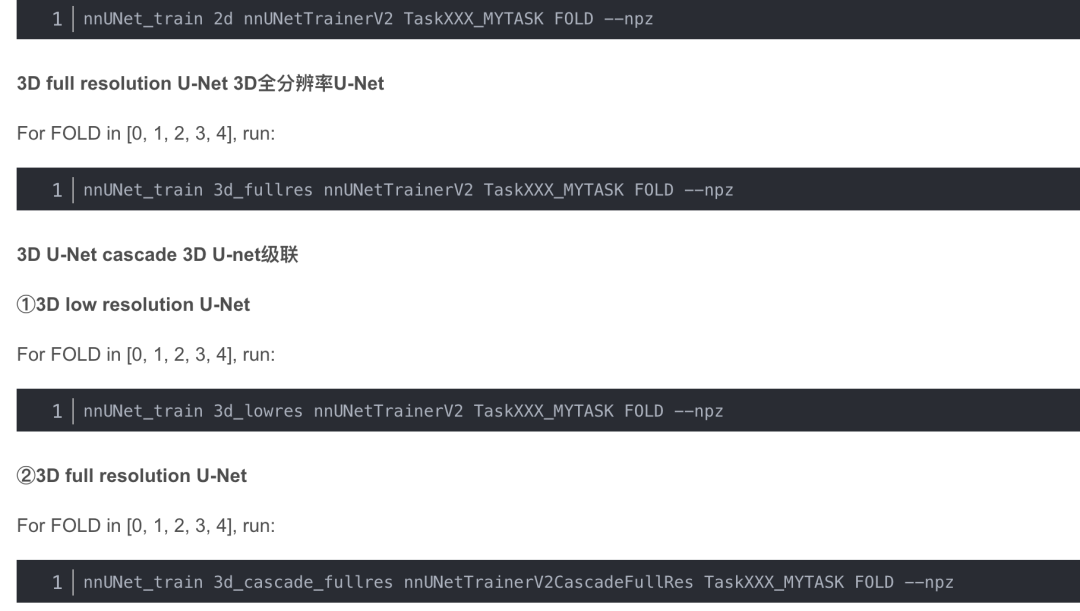
注意,級聯(lián)的3D全分辨率U-Net需要預(yù)先完成低分辨率U-Net的five folds!
3.訓(xùn)練結(jié)果
訓(xùn)練后的模型將寫入RESULTS_FOLDER/nnUNet文件夾。對于我們的項目來說,就是會存在/home/work/nnUNet/nnUNetFrame/DATASET/nnUNet_trained_models/nnUNet這個路徑下。
每次訓(xùn)練都會獲得一個自動生成的輸出文件夾名稱,根據(jù)我們的訓(xùn)練配置,我們會得到3d_fullres/Task001_BrainTumour這個文件夾。關(guān)于它的樹狀圖如下(為簡潔起見,有些文件僅在一個文件夾下詳細展開):
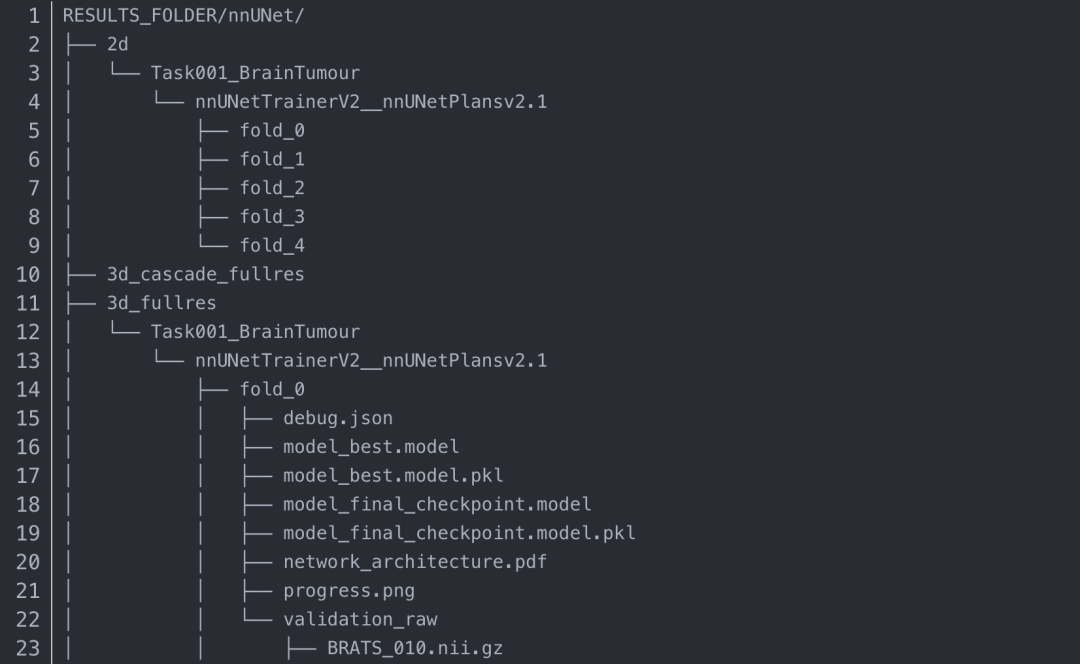
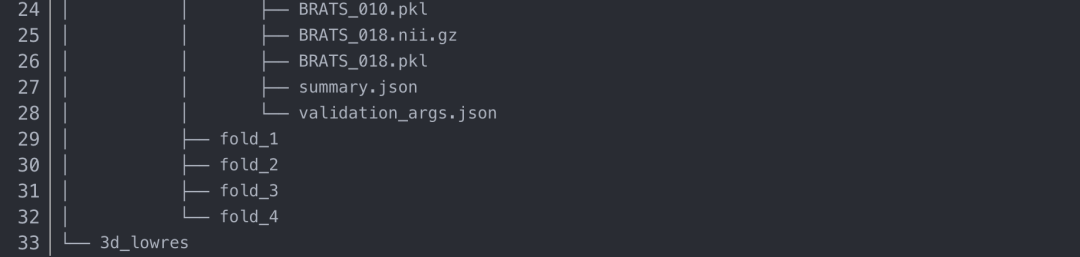
如果你的訓(xùn)練成功了,應(yīng)該會得到和我下圖一樣的結(jié)果

下面詳細講講這些訓(xùn)練后得到的文件都是什么

現(xiàn)在我們想看看我們訓(xùn)練的結(jié)果怎么樣,有兩種方法:


包含背景在內(nèi)的4個標簽,分別是背景、壞疽(NET,non-enhancing tumor)、浮腫區(qū)域(ED,peritumoral edema)、增強腫瘤區(qū)域(ET,enhancing tumor),如下圖,它們的平均dice分數(shù)約為0.9994,0.8770,0.7780,0.8728

八、確定最佳U-Net配置
本文只說明了3d_fullres的訓(xùn)練,完整的nnUNet流程還需要跑2d和3d級聯(lián)的,然后進行三種的擇優(yōu)。不過從實際性能來說,一般3d級聯(lián)≥3d>2d,是否跑其他兩種需要自己考慮。
訓(xùn)練完所有模型后,使用以下命令自動確定用于測試集預(yù)測的U-Net配置:

所有指定配置都需要完成所有的5折訓(xùn)練!
對于未配置級聯(lián)的數(shù)據(jù)集,請改用“-m 2d 3d_fullres”。如果您只想探索配置的某些子集,可以使用“-m”命令指定。
所以說,如果你訓(xùn)練完所有模型,才可以使用這一步,如果沒有,那可以直接推理
九、運行推理
1.準備測試集
讓我們回到你剛剛做好數(shù)據(jù)集轉(zhuǎn)換的那個數(shù)據(jù)集:/home/work/nnUNet/nnUNetFrame/DATASET/nnUNet_raw/nnUNet_raw_data/Task001_BrainTumour,在里面創(chuàng)建inferTs這個文件夾,用于存放待推理測試集的推理結(jié)果。然后,我會選擇將原本的imagesTs重命名為imagesTs0,它是我們下載數(shù)據(jù)集時給我們的幾十個測試集,然后新建一個imagesTs,里面只放一個測試集。(解釋:這個道理其實很明顯,推理太多數(shù)據(jù)集太久了,先用一個試試)

這個時候我們在imagesTs里存放的待推理的測試集,它的格式應(yīng)該是經(jīng)過數(shù)據(jù)集轉(zhuǎn)換那一步的格式,忘記了的話可以翻上去看一下,如下圖所示,四個模態(tài)都要有,且重命名過:

2.運行推理的最簡單方法是簡單地使用下面這一條命令:


原文地址 https://blog.csdn.net/m0_68239345/article/details/128886376
機器學(xué)習(xí)算法AI大數(shù)據(jù)技術(shù)
搜索公眾號添加: datanlp
長按圖片,識別二維碼
閱讀過本文的人還看了以下文章:
TensorFlow 2.0深度學(xué)習(xí)案例實戰(zhàn)
基于40萬表格數(shù)據(jù)集TableBank,用MaskRCNN做表格檢測
《基于深度學(xué)習(xí)的自然語言處理》中/英PDF
《美團機器學(xué)習(xí)實踐》_美團算法團隊.pdf
《深度學(xué)習(xí)入門:基于Python的理論與實現(xiàn)》高清中文PDF+源碼
《深度學(xué)習(xí):基于Keras的Python實踐》PDF和代碼
python就業(yè)班學(xué)習(xí)視頻,從入門到實戰(zhàn)項目
2019最新《PyTorch自然語言處理》英、中文版PDF+源碼
《21個項目玩轉(zhuǎn)深度學(xué)習(xí):基于TensorFlow的實踐詳解》完整版PDF+附書代碼
《深度學(xué)習(xí)之pytorch》pdf+附書源碼
PyTorch深度學(xué)習(xí)快速實戰(zhàn)入門《pytorch-handbook》
【下載】豆瓣評分8.1,《機器學(xué)習(xí)實戰(zhàn):基于Scikit-Learn和TensorFlow》
《Python數(shù)據(jù)分析與挖掘?qū)崙?zhàn)》PDF+完整源碼
汽車行業(yè)完整知識圖譜項目實戰(zhàn)視頻(全23課)
李沐大神開源《動手學(xué)深度學(xué)習(xí)》,加州伯克利深度學(xué)習(xí)(2019春)教材
筆記、代碼清晰易懂!李航《統(tǒng)計學(xué)習(xí)方法》最新資源全套!
《神經(jīng)網(wǎng)絡(luò)與深度學(xué)習(xí)》最新2018版中英PDF+源碼
重要開源!CNN-RNN-CTC 實現(xiàn)手寫漢字識別
同樣是機器學(xué)習(xí)算法工程師,你的面試為什么過不了?
前海征信大數(shù)據(jù)算法:風(fēng)險概率預(yù)測
【Keras】完整實現(xiàn)‘交通標志’分類、‘票據(jù)’分類兩個項目,讓你掌握深度學(xué)習(xí)圖像分類
VGG16遷移學(xué)習(xí),實現(xiàn)醫(yī)學(xué)圖像識別分類工程項目
特征工程(二) :文本數(shù)據(jù)的展開、過濾和分塊
如何利用全新的決策樹集成級聯(lián)結(jié)構(gòu)gcForest做特征工程并打分?
Machine Learning Yearning 中文翻譯稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
python+flask搭建CNN在線識別手寫中文網(wǎng)站
中科院Kaggle全球文本匹配競賽華人第1名團隊-深度學(xué)習(xí)與特征工程
不斷更新資源
深度學(xué)習(xí)、機器學(xué)習(xí)、數(shù)據(jù)分析、python
搜索公眾號添加: datayx