
CNN中神奇的1x1卷積
點擊上方“小白學視覺”,選擇加"星標"或“置頂”
重磅干貨,第一時間送達

我們知道在CNN網絡中,會有各種size的卷積層,比如常見的3x3,5x5等,卷積操作是卷積核在圖像上滑動相乘求和的過程,起到對圖像進行過濾特征提取的功能。但是我們也會遇見1x1的卷積層,比如在GoogleNet中的Inception模塊,如下圖:
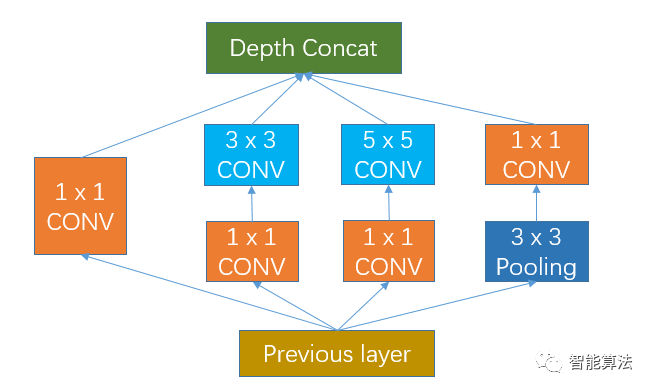
我們看到上圖中有4個1x1的卷積,那么他們起著什么作用呢?為什么要這樣做呢?
設計思路:考慮到有些物體比較大,有些物體比較小,所以用不同size的卷積核進行特征提取。其實最簡單的可以看做是全連接,它的計算方式跟全連接是一樣的。
?
增加非線性
1x1的卷積核的卷積過程相當于全鏈接層的計算過程,并且還加入了非線性激活函數,從而可以增加網絡的非線性,使得網絡可以表達更加復雜的特征。
特征降維
?
增加非線性好理解,通過控制卷積核的數量來達到通道數的縮放也好理解,那么怎么減少計算量和減少參數呢?我們從一個實例來看:假如前一層輸入大小為28 x 28 x 192,輸出大小為28 x 28 x 32,如下:
減少計算量:
不引入1x1卷積的卷積操作如下:
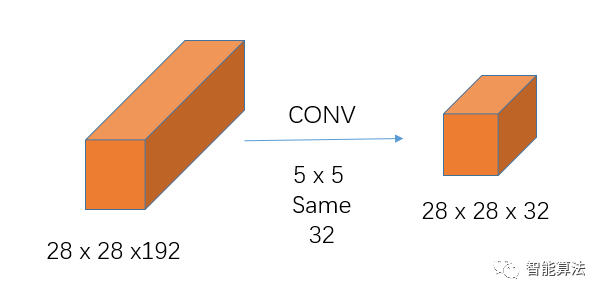
上圖計算量為:
28 x 28 x 192 x 5 x 5 x 32 = 120,422,400次
引入1x1卷積的卷積操作:
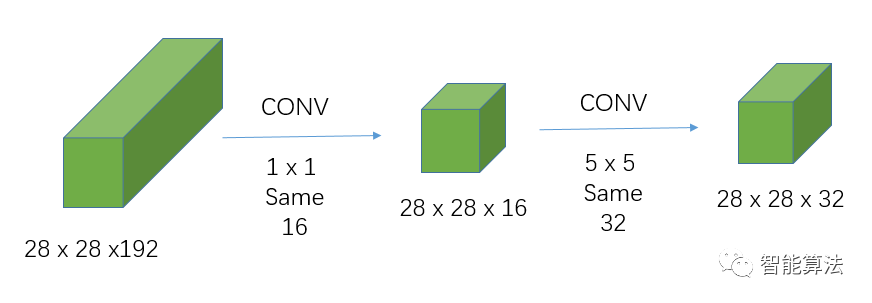
引入1x1卷積后的計算量為:
28 x 28 x 192 x 1 x 1 x 16 + 28 x 28 x 16 x 5 x 5 x 32 = 12,443,648次
從上面計算可以看出,相同的輸入,相同的輸出,引入1x1卷積后的計算量大約
是不引入的1/10。
Inception的初始版本就是沒有加入1x1卷積的網絡,如下圖:
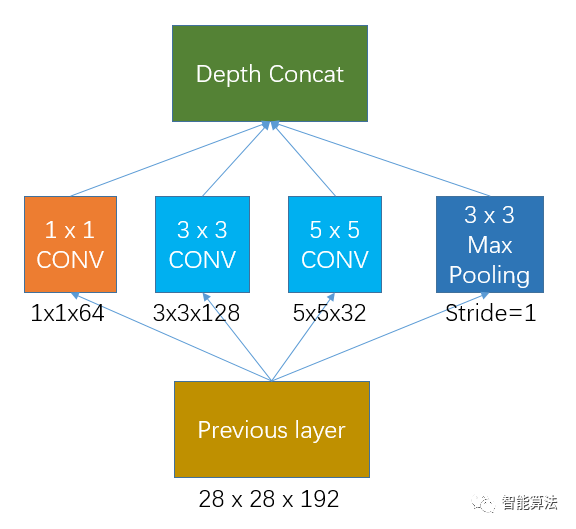
假如previous layer的大小為28x28x192,那么上面網絡的權重個數為:
1 x 1 x 192 x 64 + 3 x 3 x 192 x 128 + 5 x 5 x 192 x 32 = 387072個
其輸出的特征圖大小為:
28 x 28 x 64 + 28 x 28 x 128 + 28 x 28 x 32 + 28 x 28 x 192 = 28 x 28 x 416
加入1x1卷積的Inception網絡如下圖,那么該網絡的權重參數是多少呢?
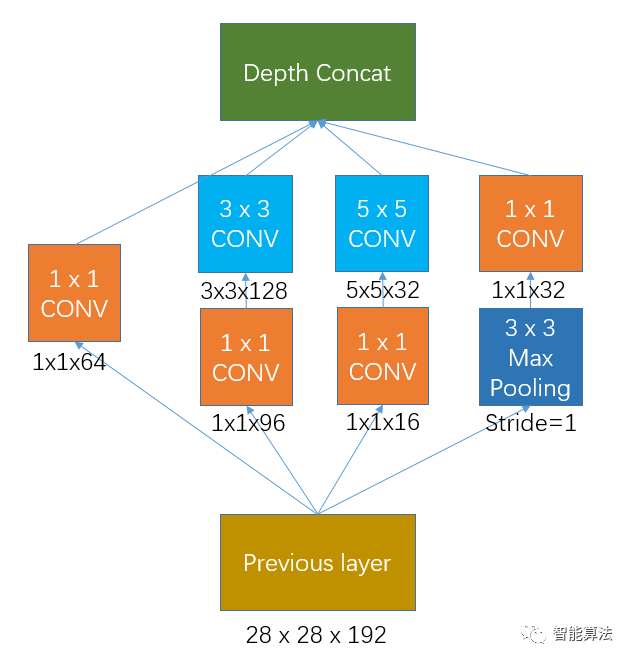
如果previous layer的大小為28x28x192,那么上面網絡的權重個數為:
1 x 1 x 192 x 64 + (1 x 1 x 192 x 96 + 3 x 3 x 96 x 128) + (1 x 1 x 192 x16 + 5 x 5 x 16 x 32) + 1 x 1 x 192 x 32 = 163328個
可見加上1x1卷積后,權重個數從38.7萬個左右降到16.3萬個左右,同時增加了網絡的非線性。
其輸出的特征圖大小為:
28 x 28 x 64 + 28 x 28 x 128 + 28 x 28 x 32 + 28 x 28 x 32 = 28 x 28 x 256
這樣,1x1卷積的增加在增加網絡非線性的同時,減少了網絡的計算量和權重個數。你Get到了嗎?
小白團隊出品:零基礎精通語義分割↓↓↓
下載1:OpenCV-Contrib擴展模塊中文版教程 在「小白學視覺」公眾號后臺回復:擴展模塊中文教程,即可下載全網第一份OpenCV擴展模塊教程中文版,涵蓋擴展模塊安裝、SFM算法、立體視覺、目標跟蹤、生物視覺、超分辨率處理等二十多章內容。 下載2:Python視覺實戰(zhàn)項目52講 在「小白學視覺」公眾號后臺回復:Python視覺實戰(zhàn)項目,即可下載包括圖像分割、口罩檢測、車道線檢測、車輛計數、添加眼線、車牌識別、字符識別、情緒檢測、文本內容提取、面部識別等31個視覺實戰(zhàn)項目,助力快速學校計算機視覺。 下載3:OpenCV實戰(zhàn)項目20講 在「小白學視覺」公眾號后臺回復:OpenCV實戰(zhàn)項目20講,即可下載含有20個基于OpenCV實現20個實戰(zhàn)項目,實現OpenCV學習進階。 交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動駕駛、計算攝影、檢測、分割、識別、醫(yī)學影像、GAN、算法競賽等微信群(以后會逐漸細分),請掃描下面微信號加群,備注:”昵稱+學校/公司+研究方向“,例如:”張三?+?上海交大?+?視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會根據研究方向邀請進入相關微信群。請勿在群內發(fā)送廣告,否則會請出群,謝謝理解~
