
ge-to-Image Translat卡內(nèi)基梅隆大學新作!基于MLP架構(gòu)的Imaion
點擊下方“AI算法與圖像處理”,關(guān)注一下
重磅干貨,第一時間送達

CVPR2021 很多成果基于之前大火的transformer,但是由于transformer的計算量太大了,最近基于 MLP 架構(gòu)的模型又重新進入大眾的視野,后續(xù)可能會有更多相關(guān)研究。后續(xù)會繼續(xù)分享相關(guān)內(nèi)容,歡迎持續(xù)關(guān)注哈!
CVPR2021論文下載鏈接:
CVPR 2021 全部論文鏈接公布!最新1660篇論文合集!附下載鏈接
論文鏈接:https://arxiv.org/pdf/2105.14110.pdf
摘要
雖然基于注意的 transformer 網(wǎng)絡(luò)在幾乎所有語言任務(wù)中都取得了無與倫比的成功,但是大量的標記加上二次激活記憶的使用使得它們對于視覺任務(wù)來說是望而卻步的。因此,雖然語言到語言的轉(zhuǎn)換因transformer模式而發(fā)生了革命性的變化,卷積網(wǎng)絡(luò)仍然是圖像到圖像轉(zhuǎn)換的事實上的解決方案。最近提出的 MLP-Mixer 架構(gòu)緩解了一些與基于注意的網(wǎng)絡(luò)相關(guān)的速度和內(nèi)存問題,同時仍然保留了使transformer模型成為理想的遠程連接。利用這種有效的替代自我注意的方法,我們提出了一種新的非配對圖像到圖像的轉(zhuǎn)換模型MixerGAN:一種更簡單的基于MLP的體系結(jié)構(gòu),它考慮了像素之間的遠距離關(guān)系,而不需要昂貴的注意機制。定量和定性分析表明,MixerGAN實現(xiàn)了競爭的結(jié)果相比,以前的卷積為基礎(chǔ)的方法。
主要貢獻
表明MLP-Mixer 體系結(jié)構(gòu)可以適應(yīng)于有效地執(zhí)行未配對圖像到圖像的轉(zhuǎn)換,同時以比transformer模型低得多的成本考慮長范圍的依賴性。

MixerGAN
我們表明,MLP-Mixer 塊提供了一種執(zhí)行未配對圖像到圖像轉(zhuǎn)換的替代方法,該方法考慮了普通卷積塊不可能實現(xiàn)的全局關(guān)系,并且在計算上比transformer塊少。
形式上,我們的目標是訓練兩個基于 Mixer 的生成器G:X→ Y 和 F: Y→X, 在兩個之間“轉(zhuǎn)換”圖像。我們通過同時訓練兩個判別器Dx和Dy來區(qū)分真實圖像和生成圖像,從而實現(xiàn)了與原始CycleGAN相同的方法。
訓練目標
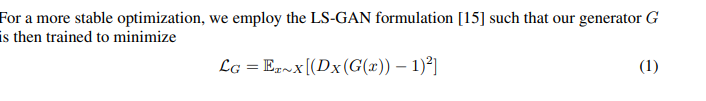
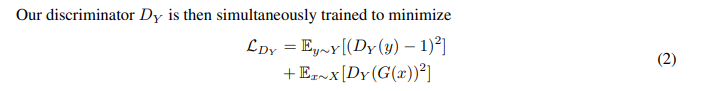

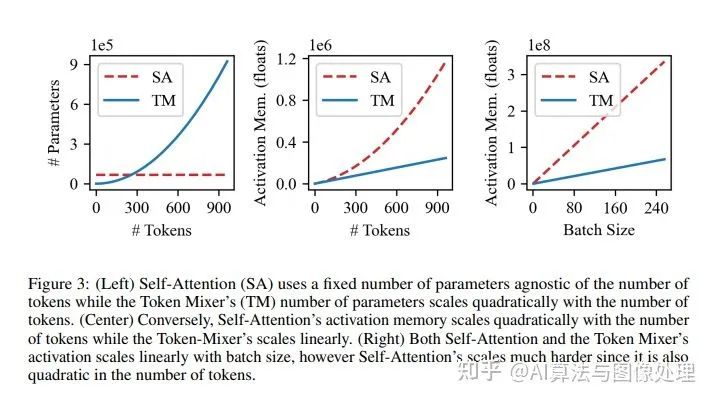
計算上的優(yōu)勢
1、如開創(chuàng)性論文[24]所述,MLP-Mixer的核心是一個具有非常具體的結(jié)構(gòu)參數(shù)。因此,MLP-Mixer 可以利用現(xiàn)有的GPU 允許以極高效率執(zhí)行卷積運算的體系結(jié)構(gòu)和實現(xiàn),而基于注意的網(wǎng)絡(luò)目前受到gpu執(zhí)行未優(yōu)化注意運算的速度的限制
2、MLP Mixer和transformer塊的內(nèi)存使用情況不同
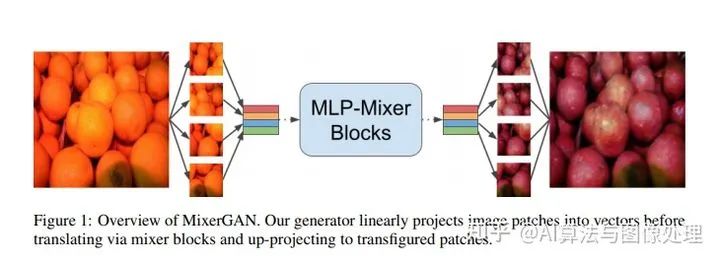
模型架構(gòu)
網(wǎng)絡(luò)與原始 CycleGAN 又相似的大小。雖然 mixer 模塊比卷積模塊有更多的參數(shù),但我們的mixer模型仍然具有相同數(shù)量的非線性,并且即使不是低維的潛在空間,也具有可比性。
根據(jù)最初的CycleGAN,我們基于mixer的生成器由單層卷積干和兩個階梯卷積層組成,用于學習下采樣。生成器的變換部分由9個各向同性混合塊組成。最后,變換部分之后是兩個上采樣轉(zhuǎn)置卷積和一個最終卷積,以將表示重新映射到源維度。對于我們的鑒別器,我們用vanilla PatchGAN[9]和mixer 增強網(wǎng)絡(luò)進行了實驗。
mixer 塊本身直接遵循MLP-mixer 論文[24]中給出的公式。在patch projection步驟之后,標記被堆疊為列,使得表示X現(xiàn)在僅是二維的。mixer塊本身由兩個多層感知器組成:一個用于token mixing,另一個用于channel mixing。token mixing MLP作用于表示的列,而channel mixing MLP作用于其通道。注意,典型的transformer架構(gòu)包含channel mixing MLP,但是執(zhí)行自注意操作來代替令牌混合MLP。MLP-mixer 塊的總體架構(gòu)如圖1所示。
實驗部分
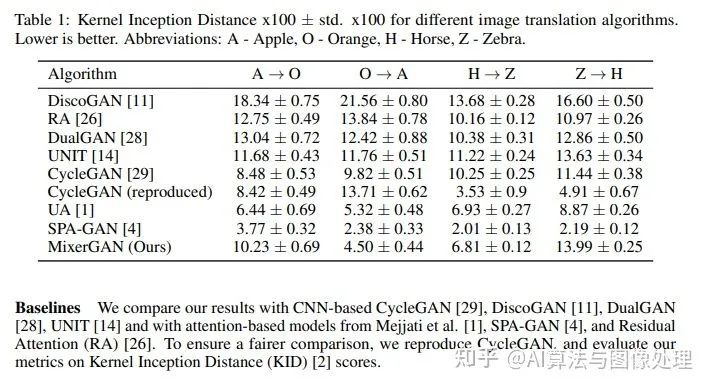
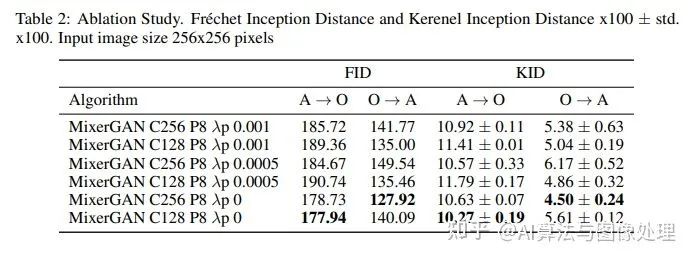
結(jié)果

Failure Modes and Limitations
MixerGAN模型的最大限制因素似乎來自于 patch projection 步驟。
考慮到patch projection步驟的局限性,我們有時會在生成的圖像中發(fā)現(xiàn)“patch”偽影,如圖6所示。我們假設(shè),在patch projection步驟之后,更多的通道將有助于通過阻止此時的信息丟失來緩解這種偽影問題。在轉(zhuǎn)換階段,一個不太完整的表達在理想情況下會導致更少的壓縮和更具表現(xiàn)力的模型。不幸的是,由于我們有限的計算能力,我們無法在這個時候試驗更廣泛的網(wǎng)絡(luò)。
結(jié)論
在這項工作中,我們已經(jīng)證明了MLP混合器也是一種有效的生成模型體系結(jié)構(gòu),特別是非配對圖像到圖像的轉(zhuǎn)換。我們假設(shè)增加潛在空間中的通道數(shù)將減少任何補丁偽影,并希望在未來獲得計算資源來評估這一點。
像所有的圖像合成應(yīng)用程序一樣,MixerGAN有可能被用于潛在的惡意目的,比如deepfakes[18]。因此,合成圖像檢測仍然是其自身的一個重要領(lǐng)域。然而,這不應(yīng)阻止我們繼續(xù)研究圖像合成,因為打擊威脅的最佳方法是徹底了解它。
經(jīng)過幾十年的卷積神經(jīng)網(wǎng)絡(luò)(以及最近的transformer網(wǎng)絡(luò))主導了計算機視覺領(lǐng)域,一個簡單的加權(quán)mlp序列可以有效地執(zhí)行相同的任務(wù),這是值得注意的。既然我們已經(jīng)證明MLP-mixer器在生成目標上取得了成功,那么改進這種技術(shù)并將基于MLP的體系結(jié)構(gòu)擴展到進一步的圖像合成任務(wù)的大門就敞開了。
努力分享優(yōu)質(zhì)的計算機視覺相關(guān)內(nèi)容,歡迎關(guān)注:
個人微信(如果沒有備注不拉群!) 請注明:地區(qū)+學校/企業(yè)+研究方向+昵稱
下載1:何愷明頂會分享
在「AI算法與圖像處理」公眾號后臺回復:何愷明,即可下載。總共有6份PDF,涉及 ResNet、Mask RCNN等經(jīng)典工作的總結(jié)分析
下載2:終身受益的編程指南:Google編程風格指南
在「AI算法與圖像處理」公眾號后臺回復:c++,即可下載。歷經(jīng)十年考驗,最權(quán)威的編程規(guī)范!
下載3 CVPR2021
在「AI算法與圖像處理」公眾號后臺回復:CVPR,即可下載1467篇CVPR 2020論文 和 CVPR 2021 最新論文
點亮  ,告訴大家你也在看
,告訴大家你也在看