
Airbnb 在搜索中應用深度學習的經(jīng)驗
關于這篇論文有趣的地方在于,并不是提出一個新穎的算法或模型,而是介紹了愛彼迎在應用深度學習的過程中,發(fā)現(xiàn)了哪些有趣且有用的點,進而分享給大家。在此之前,作者表示一直使用 GBDT 進行搜索排序,然而已經(jīng)陷入了一個瓶頸期,需要深度學習來幫助打破這個瓶頸。
接下來我們一起看看,愛彼迎在應用深度學習的過程中遇到了哪些困難和收獲吧。
背景
在愛彼迎的場景中,是作為一個雙邊市場的交易平臺:為房東出租房屋,并且為潛在的租客提供房屋。而大多數(shù)情況下,一次訂房行為都是從搜索開始的。
搜索排序的第一版往往是手工構建一個打分函數(shù),對愛彼迎而言,在此之后的下一個里程碑就是 GBDT,當 GBDT 的收益難以再進一步時,愛彼迎開始投入了深度學習的懷抱。
除了排序,對整個搜索系統(tǒng)而言,模型需要預測房東愿意接受租客訂房的概率,需要預測租客會給 5 星好評的概率等等。
在愛彼迎中,用戶往往是搜索->瀏覽->搜索...->訂房,通過多次的搜索與瀏覽最終實現(xiàn)訂房的操作,而這些行為會用來訓練數(shù)據(jù)。訓練好的模型再開始進行線上 A/B。
這篇文章的整體結(jié)構就是先介紹愛彼迎搜索模型的進化過程,然后是特征工程和系統(tǒng)工程,最后是一些工具和超參的探索。
我個人喜好這篇文章的地方也在于,不同于其它常見的 paper,都是努力講明自己提出了一個新穎的模型,然后結(jié)構是如何,最后實驗驗證它很優(yōu)秀。這篇文章重點是告訴大家愛彼迎在搜索上的一些探索與進步,從宏觀的角度來為大家展示如何將一個工程逐漸深度化,并且這其中有哪些需要關注的細節(jié)。
模型進化
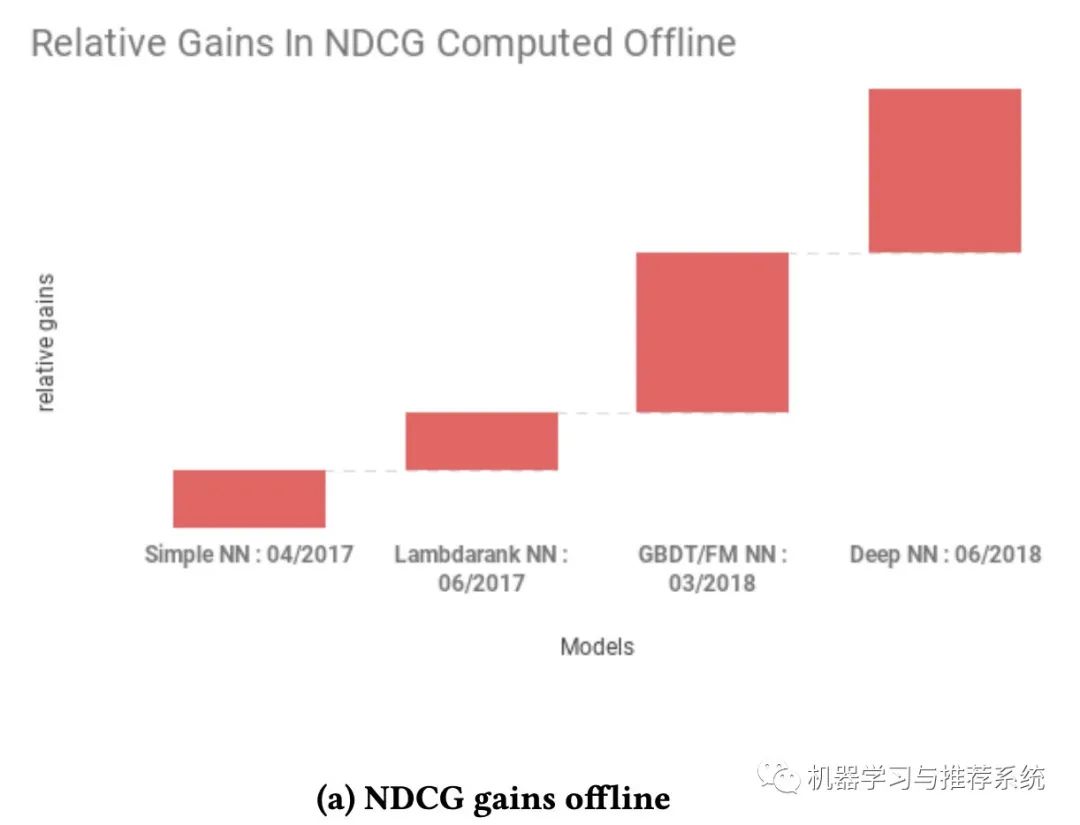
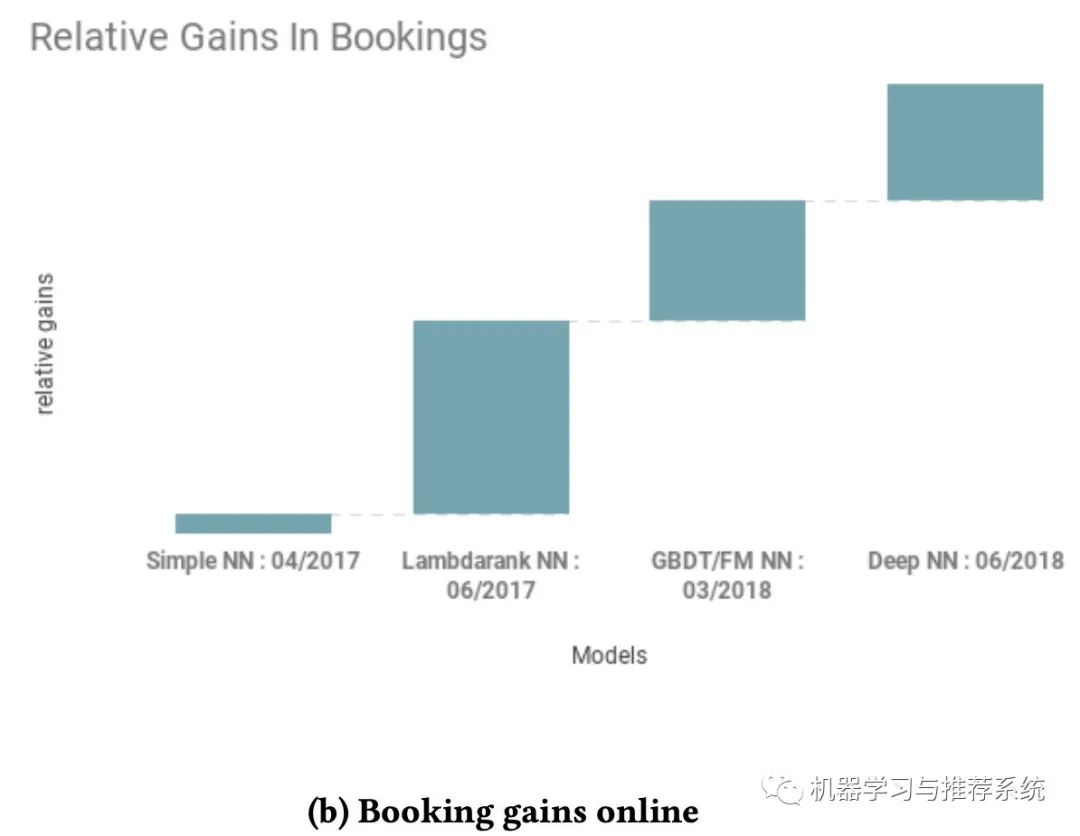
這兩幅圖分別展示了愛彼迎在搜索中嘗試的不同模型,一個是在離線的 NDCG 表現(xiàn),另外一個則是在線訂房的收益。
初步的時候是一個簡單的單層 NN 網(wǎng)絡,主要是為了跑通整個 pipeline(這和我上篇文章的年度總結(jié)中提到的不謀而合)。當完成一個單層網(wǎng)絡時,愛彼迎開始逐步優(yōu)化他們的網(wǎng)絡。因為離線指標是 NDCG,所以選擇了 lambdarank。
作者在這里給出了一段簡要的代碼來展示他們的思路:

「Decision Tree/Factorization Machine NN」:除了 lambdaRank,作者表示他們進行了一個模型融合的嘗試,將 GBDT,F(xiàn)M 和 NN 結(jié)合起來,結(jié)構也很直接:
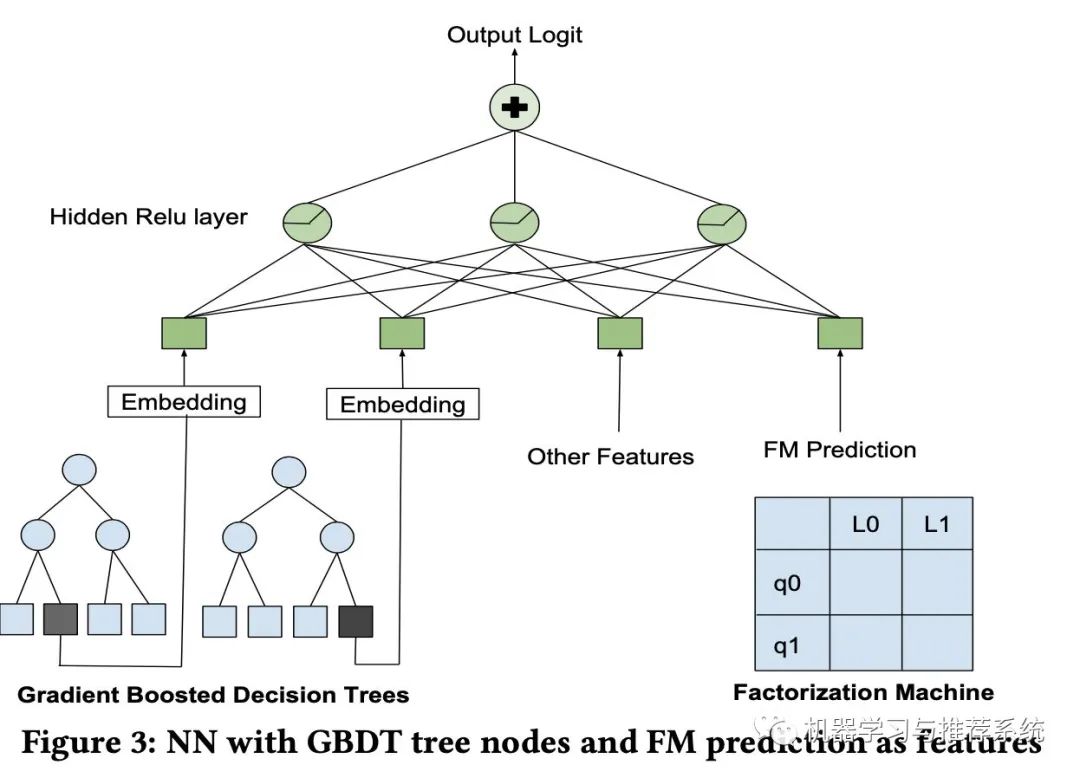
作者表示,雖然將三個模型結(jié)合在測試集的指標表現(xiàn)與直接使用神經(jīng)網(wǎng)絡差不多,但是最終列表的頭部順序卻大不相同,因此,作者認為模型的融合結(jié)合了三類模型的各自優(yōu)點,但是這里文章中并沒有給出進一步的闡述。倒是給了一個參考文獻,[我會展示在后面](Ruoxi Wang, Bin Fu, Gang Fu, and Mingliang Wang. 2017. Deep & Cross Network for Ad Click Predictions. In Proceedings of the ADKDD'17 (ADKDD'17). ACM, New York, NY, USA, Article 12, 7 pages.)。
「Deep NN」:接下來就是進入 DNN 時代,作者表示 DNN 就是好使喚。沒啥好說的,就是牛逼。作者說他們的初始數(shù)據(jù)特征都是一些簡單的東西,什么價格,設備情況,歷史訂閱數(shù)等,另外還用了兩個模型的輸出也作為特征喂了進去。
如下圖,隨著訓練數(shù)據(jù)的增多,訓練集和測試集之間的 gap 也逐漸消失:
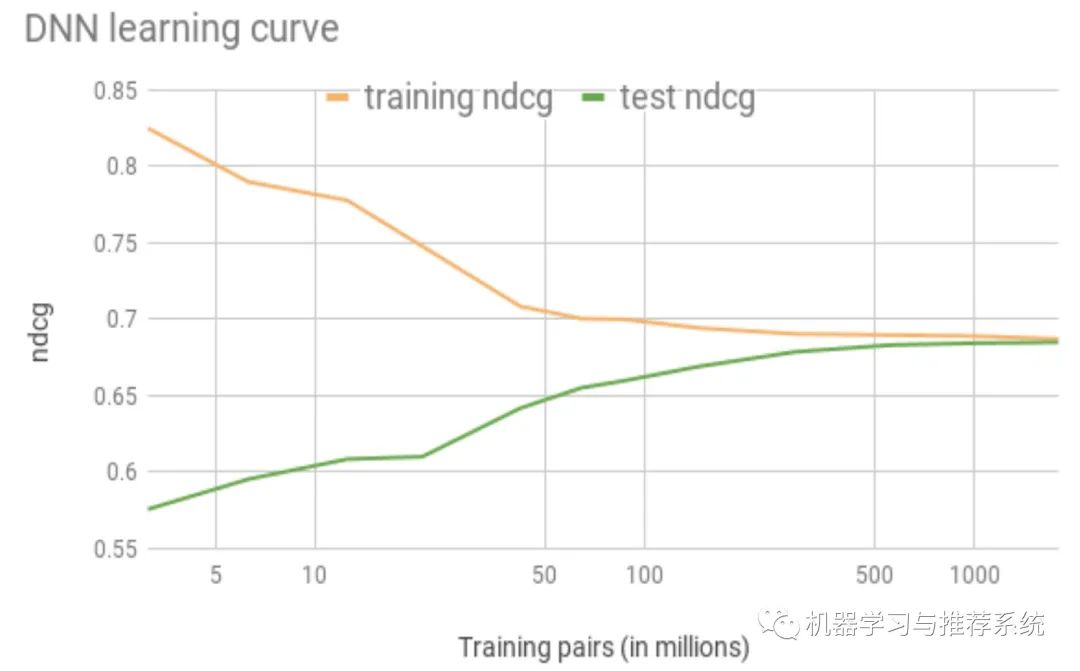
但是作者表示,不想 DNN 在 CV 領域取得的巨大成功一樣(機器和人類的準確度差不多),在當前場景中,人類也無法判斷哪些內(nèi)容是應該正確展示的:畢竟搜索了以后,訂不訂房子還主要取決于用戶的預算和品位風格。
在這里作者表示,要介紹一些其它時候很少有人介紹的東西:一些失敗的嘗試
失敗的模型
成功者千篇一律,失敗者卻各有千秋。對模型也是有幾分相似,作者表示失敗的嘗試太多了,挑兩個經(jīng)典的聊聊:
listing ID
將 item 的交互 ID list 作為特征,直接喂進模型,在搜索,推薦,nlp 等領域都是常見操作,也往往會非常有效,愛彼迎在開始前也是充滿了希望。但能寫到這里,可見結(jié)果肯定是大失所望。
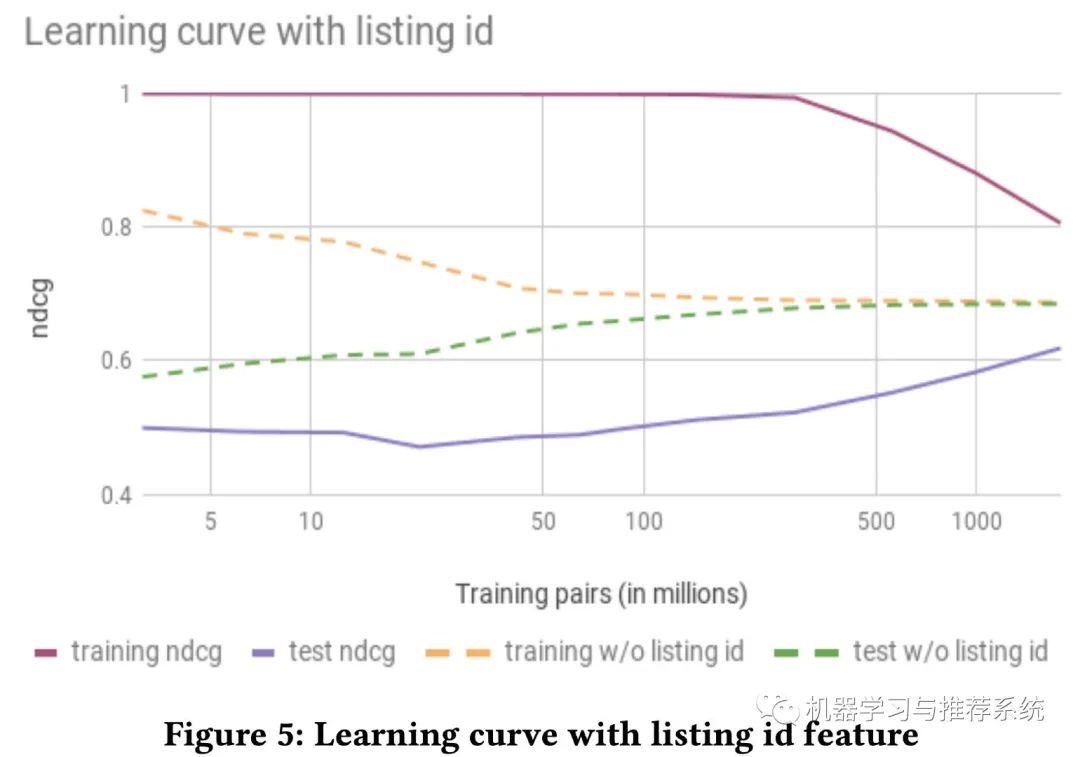
如上圖所示,加了 ID 特征和不加 ID 特征,收斂速度以及程度都有很大差異,可見帶了 ID 特征的,往往會陷入過擬合。
作者分析了這種現(xiàn)象的可能原因:由于愛彼迎特殊的業(yè)務性質(zhì)導致。
因為在其它領域,比如抖音這種,一個短視頻被觀看的次數(shù)是不受限制;比如在淘寶,一個商品被購買的次數(shù)也是不受限制的。而將 ID 的交互記錄作為一條特征,本身就需要這樣大量的行為記錄。但是在愛彼迎,即使最熱門的房間,一年也最多被訂 365 次。
所以這一條也表明,我們在選擇特征時需要充分考慮自己的業(yè)務場景,而這是建立在對自己當前業(yè)務 sense 的基礎上。
多任務學習
考慮到訂房這一行為的限制,愛彼迎就開始考慮瀏覽行為是不受限制的,能不能從瀏覽行為入手呢?
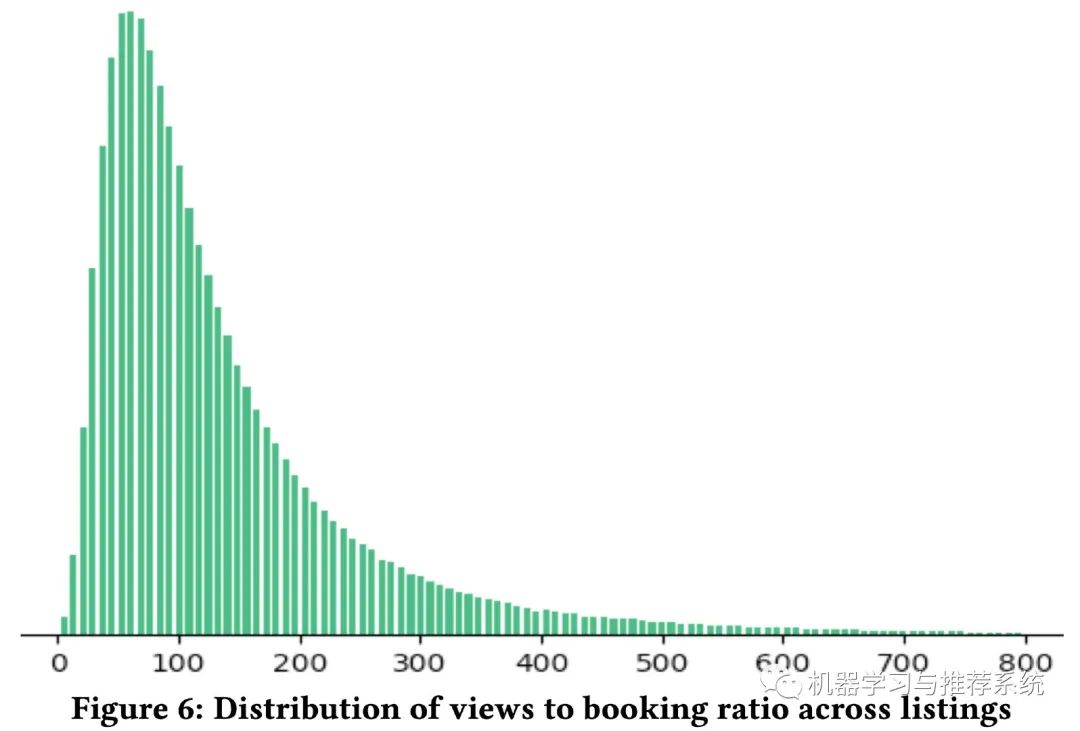
上圖展示了瀏覽和訂閱之間的比例分布,看得出訂閱相比于瀏覽記錄要稀疏很多。另一方面,越多的瀏覽量一般越容易帶來訂房行為。因此愛彼迎進行了一個多任務學習模型,將訂房和瀏覽時長都作為優(yōu)化目標。
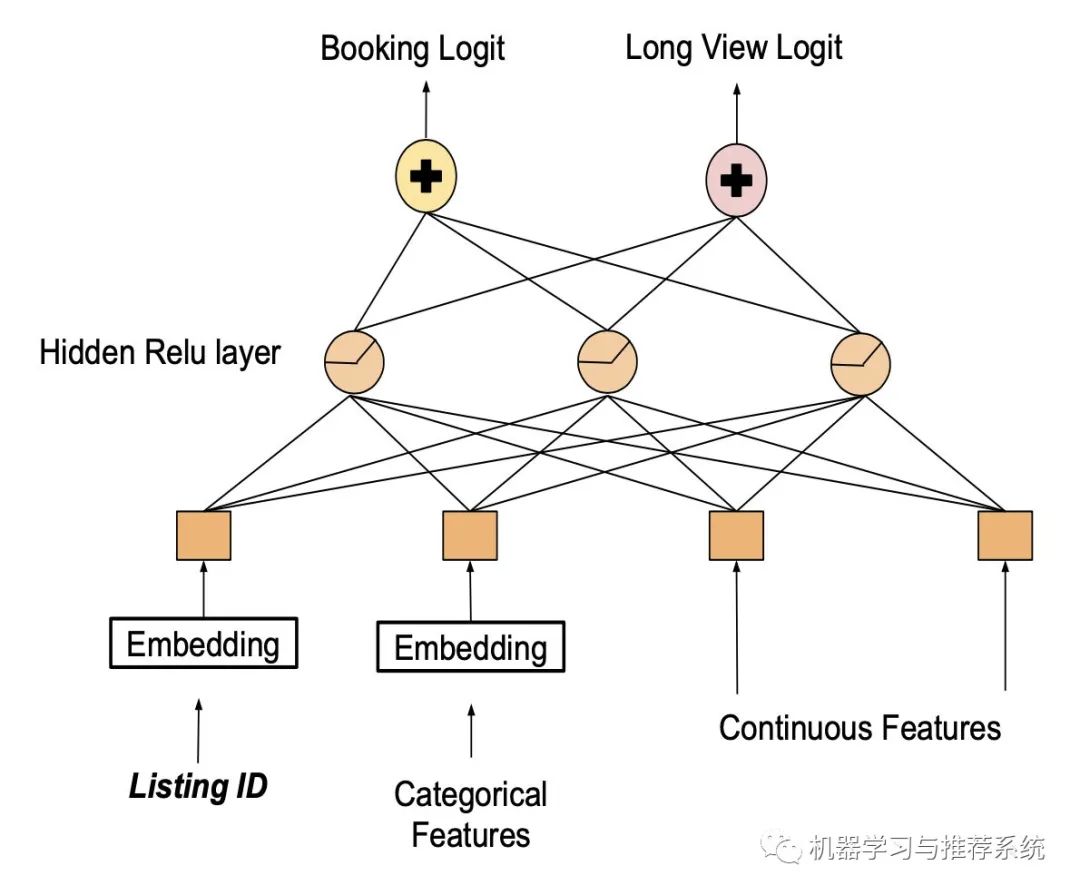
設計好模型以后,哎,現(xiàn)在可以用 listing ID 了吧。
最后一看,結(jié)果不妙,好家伙,這模型凈給人展示那些特別貴,或者特個性的房間了,用戶的確愛看,瀏覽時長也的確增加,但是對訂房本身的指標沒太大幫助呀。
特征工程
這里愛彼迎提出了一些思路,對特征進行處理使其滿足某些屬性,幫助神經(jīng)網(wǎng)絡可以有效的進行數(shù)學運算。
特征正則化
在一開始,作者直接使用了他們以前在 GBDT 中的特征,但是效果不好。追述原因后發(fā)現(xiàn),GBDT 對特征的具體數(shù)值不是很關心,主要是關心特征數(shù)值之間的相對順序。但是神經(jīng)網(wǎng)絡對數(shù)值是很敏感的。
如果不是同一類的特征,數(shù)值范圍差異很大,會導致梯度傳播誤差過大。比如某些太大的值直接使得 ReLU 函數(shù)失效,產(chǎn)生梯度消失。
所以對輸入的特征,最理想的就是讓他們的范圍集中在 -1 到 1 之間,且均值為 0。
為此,作者提出了兩個正則化的方法:
對服從正態(tài)分布的特征,通過 (feature_val ? μ)/σ 來轉(zhuǎn)換其分布; 對服從冪律分布的特征,通過 log((1+feature_val) / (1+median)) 來轉(zhuǎn)換其分布。
特征分布
通過上一步可以將特征的分布平滑,可是為什么要做平滑這件事呢?
排查 bug
首先就是樣本中的異常特征值,通常是很難直接觀察出來的。但是如果樣本的特征是平滑的,這個時候做一個分布圖出來,就可以很容易看到那些異常的樣本特征值。
比如某個地區(qū)的房價作為一個特征,如果某條樣本誤將過去一個月的訂房價當做了一天的訂房間,那么在特征的分布圖中,這個值就會很明顯的突起。
有利于模型的泛化能力
神經(jīng)網(wǎng)絡相比于其它機器學習方法,優(yōu)勢之一就是出色的泛化能力,從這個角度,作者進行了分析,提出了特征分布平滑的作用。
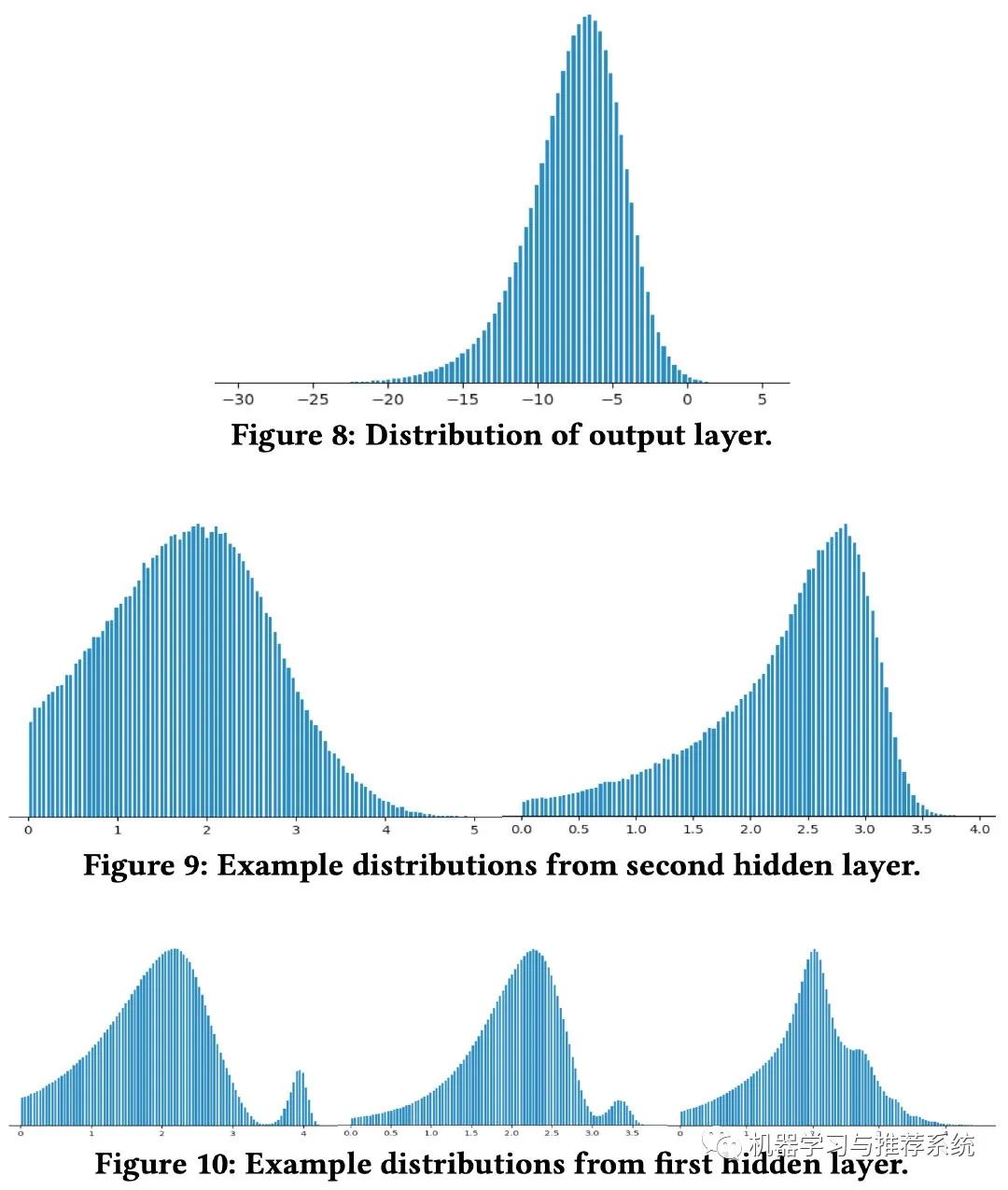
上面這幅圖分別展示了神經(jīng)網(wǎng)絡的每一層輸出的分布情況,可以觀察到,最終的輸出層分布最為平滑。而且是從輸入層開始逐漸越來越平滑。這是不是神經(jīng)網(wǎng)絡具有優(yōu)秀泛化能力的原因呢?
作者表示,在實際應用中,模型都是通過訓練數(shù)據(jù)來學習一個高維特征空間中的分布。但是在訓練的時候,不可能所有的特征組合都被觀察到,所以模型訓練的過程就是從不平滑的分布中去逐漸插值學習。
這樣也可以理解,下層分布越平滑,上層就越可能對看不到的特征進行插值。而最底層自然就是輸入層。
另一方面為了驗證泛化能力,作者嘗試了將所有的價格都 x2,x3,x4等等,結(jié)果最終的 NDCG 都是出奇的穩(wěn)定。
一般來講,特征平滑是很容易做到的。稍微進行處理就可以輕松的將特征分布遷移到合適且平滑的形式,但是有時候針對某些特征,愛彼迎還是做了一些專門的特征工程去讓它們的分布平滑起來。
其中一個例子就是針對用戶搜索后展示房子的地理位置,下面這幅圖記錄了整個過程:一開始是經(jīng)緯度的分布,明顯很不平滑;后面改為距離用戶搜索地圖中心的距離,再后來又加上了對數(shù)函數(shù);最終就得到了一個滿足要求的特征分布。
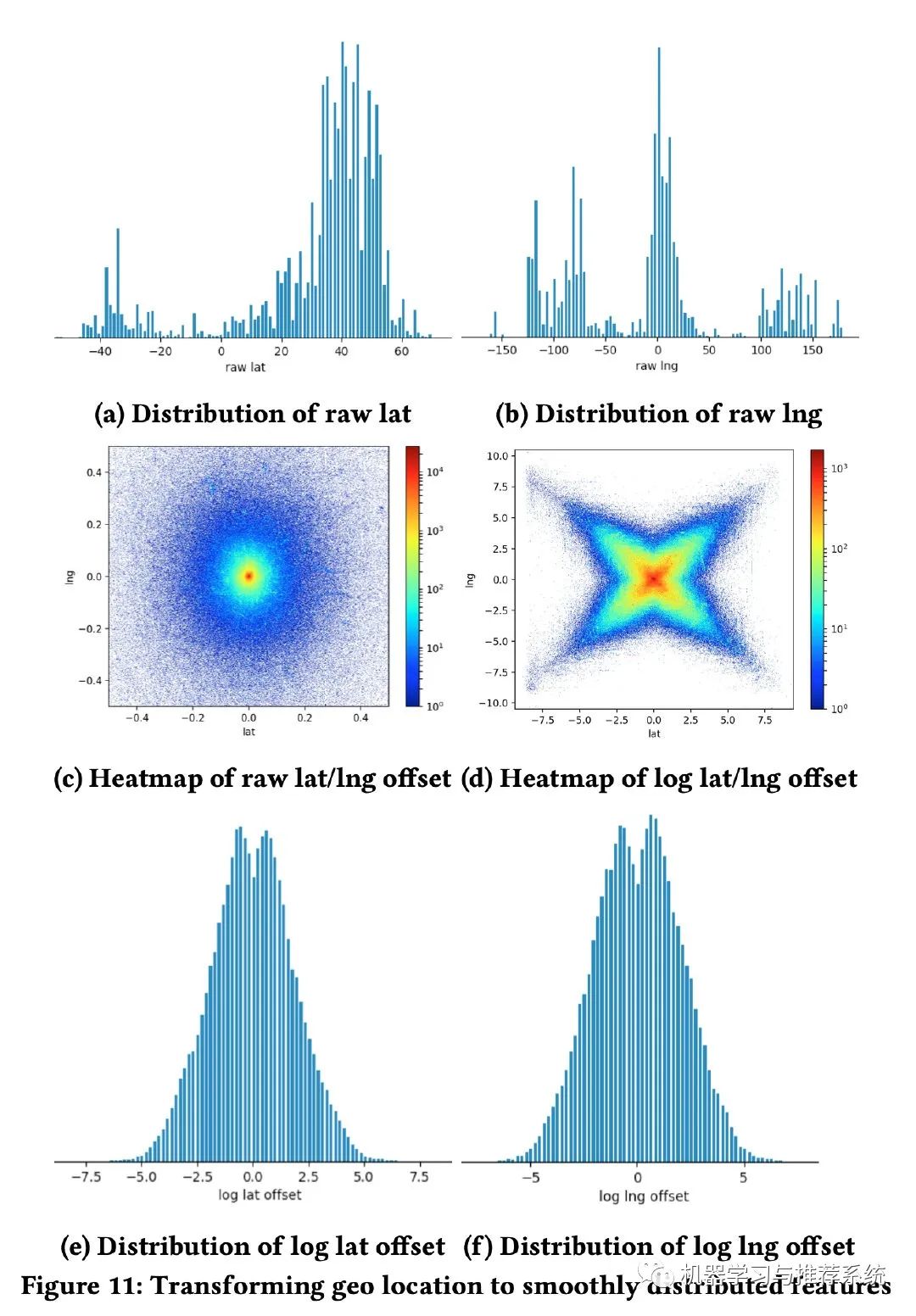
檢查特征的完整性
特征的分布如果不平滑,有可能會幫助我們檢查特征的完整性(其實某種程度上,我覺得也可以和前面的排查 bug 有些類似)。
作者在這里舉了一個例子是用房子的入住天數(shù)作為特征,結(jié)果發(fā)現(xiàn)分布不平滑,如下左圖。究其原因是部分房源要求入住的最短時長不同,有的甚至要求最少幾個月。
所以作者利用平均入住天數(shù)做了一個平滑,就形成了右圖的冪律分布。

高基特征
前面嘗試過 listing ID,但是效果不好。那么愛彼迎還在哪些方面嘗試過高基分類特征呢?
這里舉了一個例子,就是地理位置,直接利用了谷歌的 s2 地圖庫。通過將地名和 s2 地圖庫結(jié)合起來,做一個哈希函數(shù),然后得到的哈希值作為一個特征向量,喂進神經(jīng)網(wǎng)絡進行學習。
例如 {”San Francisco”, 539058204} → 71829521
最終的一個應用例子如下:
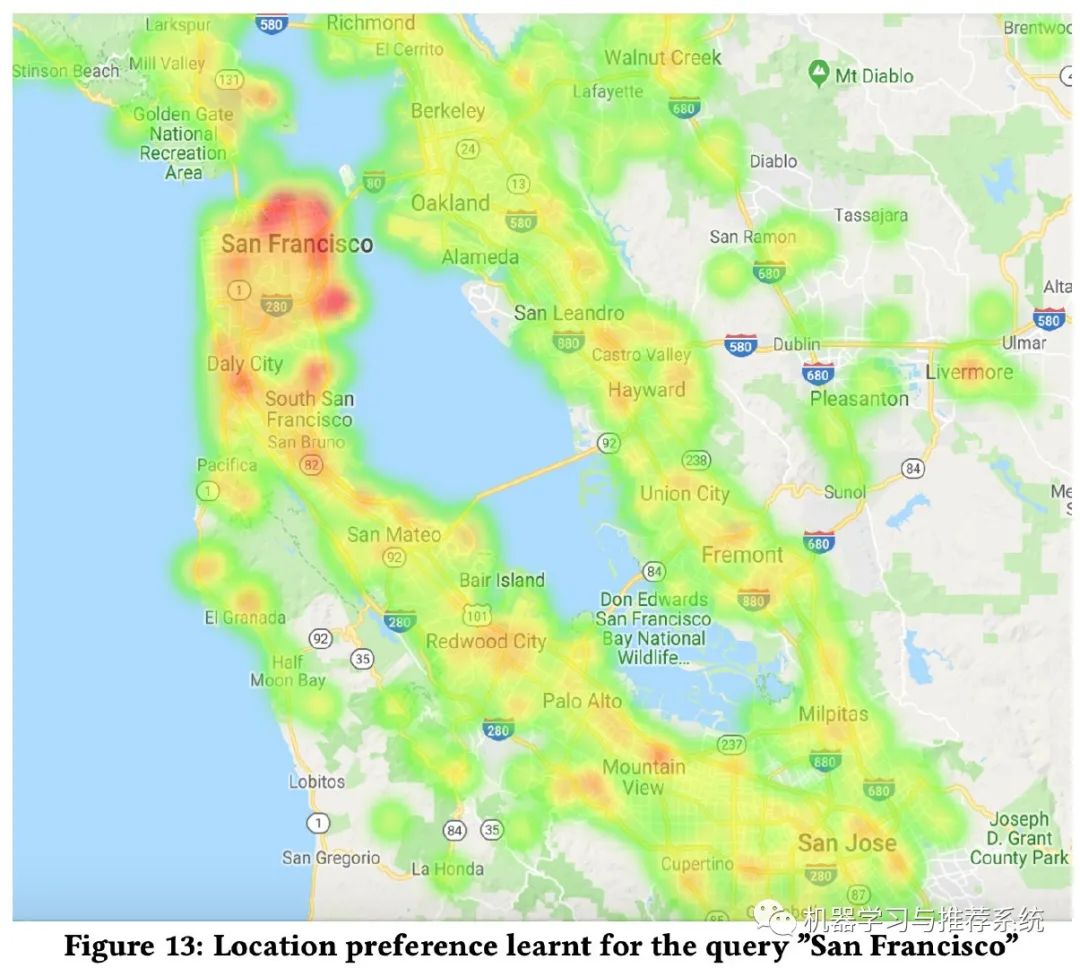
可以看到這個熱力圖,當搜索 San Francisco 時,并不是單純的以這里為熱力圖中心,直接線性距離發(fā)散熱度。明顯 San Francisco 下方的陸地比旁邊的水域鄰居更具有熱度。
系統(tǒng)工程
這里整體流程可能和大家是比較相似的,線上服務是一個 Java 服務。處理數(shù)據(jù)用 spark,訓練模型用 TensorFlow,數(shù)據(jù)分析用 Scala 和 Java 等。
這里作者提到幾個 trick,可能會對我們有幫助:
protobufs 和數(shù)據(jù)集
在之前他們用的是 GBDT,數(shù)據(jù)是 CSV 文件,開始神經(jīng)網(wǎng)絡以后,他們沿用了這套數(shù)據(jù)格式,將 CSV 轉(zhuǎn)化成 feed_dict 喂進網(wǎng)絡。但是發(fā)現(xiàn) GPU 利用率只有 25%。
后來他們使用 protobufs 和數(shù)據(jù)集,避免了訓練時對數(shù)據(jù)的格式轉(zhuǎn)換,這一步大約帶來 17X 的訓練加速,并且 GPU 利用率達到 90%。
靜態(tài)特征
對愛彼迎這種業(yè)務而言,一套房子的硬性特征是不會改變的(至少輕易不會改變),比如房子的地理位置,房子的結(jié)構,公共設施等。每條訓練數(shù)據(jù)的這些特征不斷的加載,是很大的 IO 消耗。
所以愛彼迎直接使用房子的 ID 作為特征,來取代掉這些靜態(tài)特征,只有當這些信息發(fā)生變化時,才會加載進訓練。
Java 神經(jīng)網(wǎng)絡庫
這里就是簡單介紹了一下,他們自己開發(fā)了一個 Java 神經(jīng)網(wǎng)絡庫。
超參
這一部分也沒啥內(nèi)容 ==!
愛彼迎的結(jié)果就是 dropout 效果不明顯,作者覺得原因是 dropout 適合那些數(shù)據(jù)噪音比較大的情況。
再就是初始化權重,他們覺得在 -1 到 1 之間隨機,比全部設 0 好。
學習率和 batch size 沒調(diào)出來啥東西~~~
特征的重要性
這里作者也做了一些分析,我們簡單的概括出來就是:
得分拆解
如何知道哪些特征比較重要,哪些特征可以省略呢?作者想到了從最后的得分進行拆解,但是后來得出一個結(jié)論,凡是經(jīng)過了非線性激活函數(shù)的特征,根本無法分離出其對最終得分的真正影響,所以這樣的拆解都是沒有意義的~~
AB 測試
這個顯然易見,每次少一個特征,然后去觀察性能變化。但是作者說,每次去掉一個特征的影響,甚至都無法和訓練中的數(shù)據(jù)噪音區(qū)分出來。
重新排列一部分特征
另外一個思路就是將某類特征的值全部隨機化,再來判斷性能。這樣子這些特征依然生效,但是打亂值后看看它是否會對模型構成影響。這樣子的確可以觀察到一些特征的重要性。
但是作者提出了幾點需要注意的地方:第一,觀察的特征需要與其它特征獨立,這往往是很難實現(xiàn)的;第二,由于打亂了特征值,所以可能會對模型最終的結(jié)果構成影響(比如構建出一些現(xiàn)實生活中不存在的特征組合),進而誤導我們的方向。
####結(jié)果的特征分析
這里的思路是利用測試集上的結(jié)果,將結(jié)果排序,分析頭部和尾部的特征分布,就可以知道模型在不同的取值范圍如何應用這些特征。
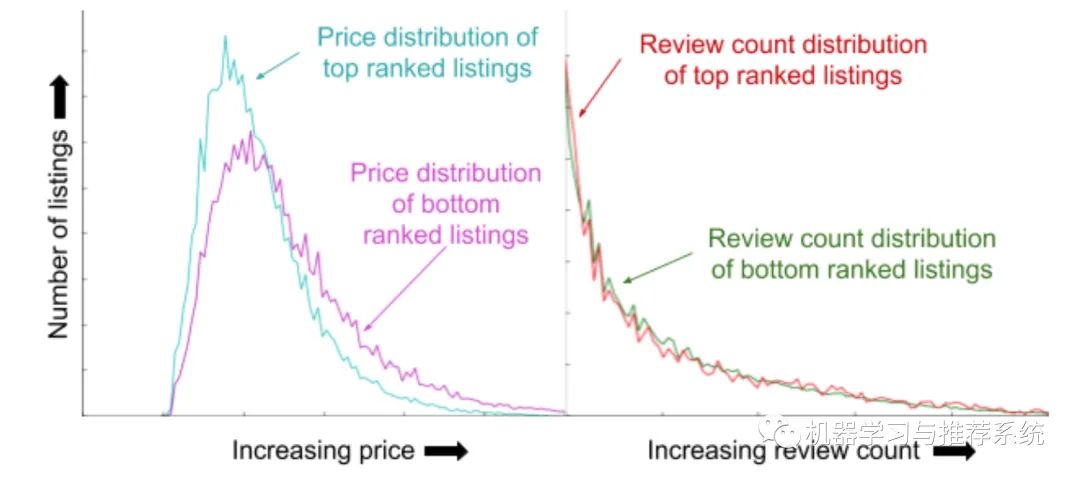
考慮了價錢所以頭部和尾部的結(jié)果對價錢的分布就有所不同,但是瀏覽時長的特征沒有被考慮,分布就很接近。這也是一個去分析特征重要性的方法。
總結(jié)
正如文章最后說的一樣,他們感覺自己對深度學習在搜索的應用才剛剛開始。
將某項業(yè)務從非深度學習模式切換到神經(jīng)網(wǎng)絡上來,并不是直接喂到模型里就完事兒的,需要前期逐步的穩(wěn)扎穩(wěn)打,當整個 pipeline 打通,數(shù)據(jù),特征工程,系統(tǒng)工程等等都完備了,才是你開始探索模型的時候。
而這個探索的過程,本質(zhì)上其實考驗的還是你對業(yè)務的熟悉和理解。
我自己最近也在遷移一項搜索工程,準備將其整個 NN 的鏈路打通,這篇文章帶給我的啟發(fā)還是多的。不過最主要的核心,其實還是對業(yè)務的理解,可以看到上面很多內(nèi)容,都是可以從愛彼迎本身的業(yè)務角度闡釋的。
更多閱讀
特別推薦

點擊下方閱讀原文加入社區(qū)會員