
阿里一面:SQL 優(yōu)化有哪些技巧?
Hollis的新書限時折扣中,一本深入講解Java基礎(chǔ)的干貨筆記!
MySQL 相信大家一定都不陌生,但是不陌生不一定會用!
會用不一定能用好!

今天,Tom哥就帶大家復(fù)習(xí)一個高頻面試考點(diǎn),SQL 優(yōu)化有哪些技巧?
當(dāng)然這個還是非常有實(shí)用價值的,工作中你也一定用的上。如果應(yīng)用得當(dāng),升職加薪,指日可待
1、創(chuàng)建索引
一定要記得創(chuàng)建索引,創(chuàng)建索引,創(chuàng)建索引
重要的事說三遍!
執(zhí)行沒有索引的 SQL 語句,肯定要走全表掃描,慢是肯定的。
這種查詢毫無疑問是一個慢 SQL 查詢。
那么問題來了,是不是要收集所有的 where 查詢條件,然后針對所有的組合都創(chuàng)建索引呢?
答案肯定是否定的。
MySQL 為了提升數(shù)據(jù)查詢速率,采用 B+ 樹結(jié)構(gòu),通過空間換時間?設(shè)計思想。另外每次對表數(shù)據(jù)做更新操作時,都要調(diào)整對應(yīng)的?索引樹?,執(zhí)行效率肯定會受影響。
本著二八原則,互聯(lián)網(wǎng)請求讀多寫少的特點(diǎn),我們一定要找到一個平衡點(diǎn)。
阿里巴巴的開發(fā)者手冊建議,單表索引數(shù)量控制在5個以內(nèi),組合索引字段數(shù)不允許超過5個
其他建議:
禁止給表中的每一列都建立單獨(dú)的索引 每個Innodb表必須有個主鍵 要注意組合索引的字段的順序 優(yōu)先考慮覆蓋索引 避免使用外鍵約束
2、避免索引失效
不要以為有了索引,就萬事大吉。
殊不知,索引失效?也是慢查詢的主要原因之一。
常見的索引失效的場景有哪些?
以 % 開頭的 LIKE 查詢 創(chuàng)建了組合索引,但查詢條件不滿足 '最左匹配原則'。如:創(chuàng)建索引 idx_type_status_uid(type,status,uid),但是使用 status 和 uid 作為查詢條件。 查詢條件中使用 or,且 or 的前后條件中有一個列沒有索引,涉及的索引都不會被使用到 在索引列上的操作,函數(shù) upper()等,or、!= (<>),not in 等
3、鎖粒度
MySQL 的存儲引擎分為兩大類:MyISAM ?和 InnoDB 。
MyISAM 支持表鎖;InnoDB 支持行鎖和表鎖
更新操作時,為了保證表數(shù)據(jù)的準(zhǔn)確性,通常會加鎖,為了提高系統(tǒng)的高并發(fā)能力,我們通常建議采用?行鎖,減少鎖沖突、鎖等待?的時間。所以,存儲引擎通常會選擇?InnoDB

行鎖可能會升級為表鎖,有哪些場景呢?
如果一個表批量更新,大量使用行鎖,可能導(dǎo)致其他事務(wù)長時間等待,嚴(yán)重影響事務(wù)的執(zhí)行效率。此時,MySQL會將?
行鎖?升級為?表鎖行鎖是針對索引加的鎖,如果?
條件索引失效,那么?行鎖?也會升級為?表鎖
注意:行鎖將鎖的粒度縮小了,進(jìn)而提高了系統(tǒng)的并發(fā)能力。但是也有個弊端,可能會產(chǎn)生死鎖,需要特別關(guān)注。
4、分頁查詢優(yōu)化
如果要開發(fā)一個列表展示頁面并支持翻頁時,我們通常會這樣寫 SQL
select?*?from?表??limit?#{start},?#{pageSize};
隨著翻頁的深度加大,?start?值越來越大,比如:limit 10000 ,10
看似只返回了 10 條數(shù)據(jù),但數(shù)據(jù)庫引擎需要查詢 10010 條記錄,然后將前面的 10000 條丟棄,最終只返回最后的 10 條記錄,性能可想而知
針對這個問題,我們通常有另一種解決方案:
先定位到上一次分頁的最大 id,然后對 id 做條件索引查詢。由于數(shù)據(jù)庫的索引采用 B+ 樹結(jié)構(gòu),這樣可以一步到位
select?*?from?表?where?id?>?#{id}??limit??#{pageSize};
任何事情,有利就有弊
這種翻頁方式只支持?上一頁、下一頁?,不支持跨越式直梯翻頁
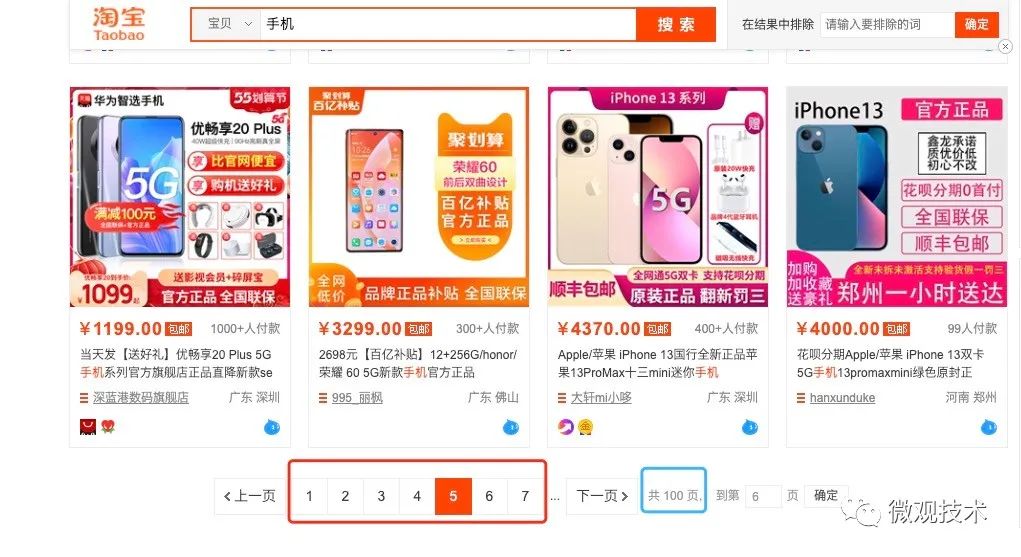
上圖是淘寶的商品搜索列表,為了用戶體驗(yàn)更好,采用的也是?直梯式翻頁。
為了避免翻頁過深,影響性能,產(chǎn)品交互上做了一些取舍,對總頁數(shù)做了限制,最多支持 100 頁。
方案二:采用子查詢
select?*?from?表?where?id?>?(?select?id?from?表?order?by?id?limit?10000?1)?limit?20;
將原來的單 SQL 查詢拆成兩步:
首先,查詢出 一頁數(shù)據(jù)中的最小 id 然后,通過 B+ 樹,精確定位到? 最小id的索引樹節(jié)點(diǎn)位置,通過?偏移量?讀取后面的 20條 數(shù)據(jù)
阿里的規(guī)約手冊也有對應(yīng)描述:

5、避免 select ?*
反面案例:
select??*?from?表?where?buyer_id?=?#{buyer_id}?
我們知道,MySQL 創(chuàng)建表后,具體的行數(shù)據(jù)存儲在主鍵索引(屬于聚簇索引)的葉子節(jié)點(diǎn)。
二級索引屬于非聚簇索引,其葉子節(jié)點(diǎn)存儲的是主鍵值
select * 的查詢過程:
先在? buyer_id?的二級索引 B+ 樹,查出對應(yīng)的 主鍵 id 列表然后進(jìn)行? 回表?操作,在 主鍵索引中 查詢 id 對應(yīng)的行數(shù)據(jù)
所以,我們需要羅列清楚必須的查詢字段,且字段盡量在?覆蓋索引?中,從而減少?回表?操作。
6、EXPLAIN 分析 SQL 執(zhí)行計劃
授人以魚不如授人以漁
除了知曉常見的不規(guī)范 SQL 寫法,在開發(fā)過程中,避免踩坑
我們還應(yīng)知道,出現(xiàn)了慢 SQL 該如何排查、優(yōu)化

實(shí)驗(yàn)安排起來
創(chuàng)建表
CREATE?TABLE?`user`?(
??`id`?bigint(20)?unsigned?NOT?NULL?AUTO_INCREMENT?COMMENT?'自增主鍵',
??`income`?bigint(20)?NOT?NULL?COMMENT?'收入',
??`expend`?bigint(20)?NOT?NULL?COMMENT?'支出',
??PRIMARY?KEY?(`id`),
??KEY?`idx_income`?(`income`)
)?ENGINE=InnoDB?AUTO_INCREMENT=1?DEFAULT?CHARSET=utf8?COMMENT='用戶表';
CREATE?TABLE?`biz_order`?(
??`id`?bigint(20)?unsigned?NOT?NULL?AUTO_INCREMENT?COMMENT?'自增主鍵',
??`user_id`?bigint(20)?NOT?NULL?COMMENT?'用戶id',
??`money`?bigint(20)?NOT?NULL?COMMENT?'金額',
??PRIMARY?KEY?(`id`),
??KEY?`idx_user_id`?(`user_id`)
)?ENGINE=InnoDB?AUTO_INCREMENT=1?DEFAULT?CHARSET=utf8?COMMENT='訂單表';
插入記錄:
insert?into?user?values(10,100,100);
insert?into?user?values(20,200,200);
insert?into?user?values(30,300,300);
insert?into?user?values(40,400,400);
insert?into?biz_order?values(1,10,30);
insert?into?biz_order?values(2,10,40);
insert?into?biz_order?values(3,10,50);
insert?into?biz_order?values(4,20,10);
比如下面的語句,我們看是否使用了索引,可以通過?explain?分析相應(yīng)的執(zhí)行計劃
explain?select?*?from?user?where??id<20;

接下來,我們來逐一來說明每個字段的含義
id:每一次 select 查詢都會生成一個 id,值越大,優(yōu)先級越高,會被優(yōu)先執(zhí)行 select_type:查詢類型,SIMPLE(普通查詢,即沒有聯(lián)合查詢、子查詢)、PRIMARY(主查詢)、UNION(UNION 中后面的查詢)、SUBQUERY(子查詢)等 table:查詢哪張表 partitions:分區(qū),如果對應(yīng)的表存在分區(qū)表,那么這里就會顯示具體的分區(qū)信息 type:執(zhí)行方式,是 SQL 優(yōu)化中一個很重要的指標(biāo),結(jié)果值從好到差依次是:system > const > eq_ref > ref > range > index > ALL
system/const:表中只有一行數(shù)據(jù)匹配,此時根據(jù)索引查詢一次就能找到對應(yīng)的數(shù)據(jù)
eq_ref:使用唯一索引掃描,常見于多表連接中使用主鍵和唯一索引作為關(guān)聯(lián)條件
ref:非唯一索引掃描,還可見于唯一索引最左原則匹配掃描
range:索引范圍掃描,比如,<,>,between 等操作
index:索引全表掃描,此時遍歷整個索引樹
ALL:表示全表掃描,需要遍歷全表來找到對應(yīng)的行
possible_keys:可能用到的索引 key:實(shí)際用到的索引 key_len:索引長度 ref:關(guān)聯(lián) id 等信息 rows:查找到記錄所掃描的行數(shù),SQL 優(yōu)化重要指標(biāo),掃描的行數(shù)越少,性能越高 filtered:查找到所需記錄占總掃描記錄數(shù)的比例 Extra:額外的信息
explain?select?*?from?user?u?,?biz_order?b?where?u.id=b.user_id?and?u.id<20;

7、Show Profile 分析 SQL 執(zhí)行性能
Show Profile 與 EXPLAIN 的區(qū)別是,前者主要是在外圍分析;后者則是深入到 MySQL 內(nèi)核,從執(zhí)行線程的狀態(tài)和時間來分析。
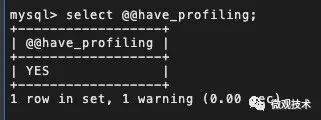
MySQL 是在 5.0.37 版本之后才支持 Show Profile ,select @@have_profiling?返回?YES?表示功能已開啟。
mysql>?show?profiles;
Empty?set,?1?warning?(0.00?sec)
顯示為空,說明profiles功能是關(guān)閉的。
通過下面命令開啟
mysql>?set?profiling=1;
Query?OK,?0?rows?affected,?1?warning?(0.00?sec)

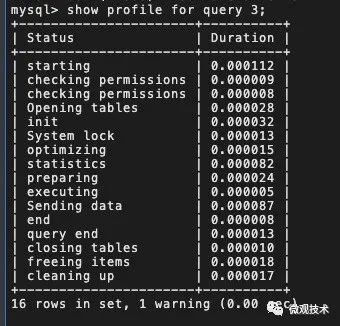
獲取?Query_ID?之后,通過?show profile for query ID?,查看 SQL 語句在執(zhí)行過程中線程的每個狀態(tài)所消耗的時間
完
往期推薦

100 行代碼透徹解析 RPC 原理

北大數(shù)學(xué)天才“韋神”上熱搜,隨手幫6個博士解決困擾4個月的難題

各大框架都在使用的Unsafe類,到底有多神奇?
有道無術(shù),術(shù)可成;有術(shù)無道,止于術(shù)
歡迎大家關(guān)注Java之道公眾號
好文章,我在看??