
ShiftViT:Swin Transformer的成功不在注意力!

注意力機(jī)制被廣泛認(rèn)為是Vision Transformer(ViT)成功的關(guān)鍵,因為它提供了一種靈活和強大的方法來建模空間關(guān)系。然而,注意力機(jī)制真的是ViT不可或缺的組成部分嗎?它能被一些其他的替代品所取代嗎?為了揭開注意力機(jī)制的作用,作者將其簡化為一個非常簡單的情況:ZERO FLOP和ZERO parameter。
具體地說,作者重新審視了Shift操作。它不包含任何參數(shù)或算術(shù)計算。唯一的操作是在相鄰的特征之間交換一小部分通道。基于這個簡單的操作,作者構(gòu)建了一個新的Backbone,即ShiftViT,其中ViT中的注意力層被shift操作所取代。
令人驚訝的是,ShiftViT在幾個主流任務(wù)中工作得很好,比如分類、檢測和分割。性能甚至比Swin Transformer更好。這些結(jié)果表明,注意力機(jī)制可能不是使ViT成功的關(guān)鍵因素。它甚至可以被一個為零參數(shù)的操作所取代。在今后的工作中,應(yīng)該更加重視ViT的其余部分。
1簡介
Backbone的設(shè)計在計算機(jī)視覺中起著至關(guān)重要的作用。自從AlexNet的革命性進(jìn)步以來,卷積神經(jīng)網(wǎng)絡(luò)(CNNs)已經(jīng)主導(dǎo)了這個鄰域近10年。然而,最近的ViTs已經(jīng)顯示出了挑戰(zhàn)這個寶座的潛力。ViT的優(yōu)勢首先在圖像分類任務(wù)中得到了證明,在該任務(wù)中,ViT的Backbone顯著優(yōu)于CNN的Backbone。由于ViT優(yōu)秀的性能使得,ViT的變體蓬勃發(fā)展迅速應(yīng)用到許多其他計算機(jī)視覺任務(wù),如目標(biāo)檢測、語義分割和動作識別。
盡管最近ViT變體的表現(xiàn)令人印象深刻,但依舊不清楚是什么使ViT有利于視覺任務(wù)。一些工作傾向于將成功歸功于注意力機(jī)制,因為它提供了一種靈活而強大的方式來建模空間關(guān)系。具體來說,注意力機(jī)制利用自注意力矩陣來聚集來自任意位置的特征。與CNN中的卷積運算相比,它有兩個顯著的優(yōu)點。首先,這種機(jī)制提供了同時捕獲短期和長期依賴的可能性,并擺脫了卷積的局部限制。其次,兩個空間位置之間的相互作用動態(tài)地依賴于各自的特征,而不是一個固定的卷積核。由于這些優(yōu)良的特性,一些作品認(rèn)為是注意力機(jī)制促成了ViT強大的表達(dá)能力。
然而,這兩個優(yōu)勢真的是成功的關(guān)鍵嗎?答案可能不是。一些現(xiàn)有的工作證明,即使沒有這些屬性,ViT變體仍然可以很好地工作。對于第一個,全局的依賴可能并非不可避免。越來越多的ViT引入了一種局部注意力機(jī)制,將其注意力范圍限制在一個小的局部區(qū)域內(nèi),如Swin-Transformer和Local ViT。實驗結(jié)果表明,該系統(tǒng)的性能并沒有由于局部限制而下降。此外,另一條研究探討了動態(tài)聚合的必要性。MLP-Mixer提出用線性投影層代替注意力層,其中線性權(quán)值不是動態(tài)生成的。在這種情況下,它仍然可以在ImageNet數(shù)據(jù)集上達(dá)到領(lǐng)先的性能。
既然全局特性和動態(tài)特性可能對ViT框架都不重要,那么ViT成功的根本原因是什么呢?為了解決清楚,作者進(jìn)一步將注意力層進(jìn)一步簡化為一個非常簡單的情況:沒有全局范圍,沒有動態(tài),甚至沒有參數(shù),沒有算術(shù)計算。作者想知道ViT在這種極端情況下是否能保持良好的性能。
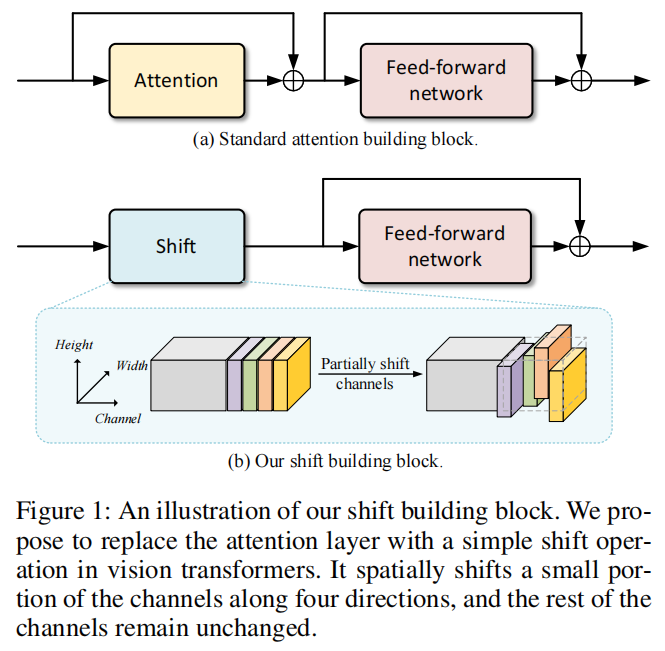
從概念上講,這種零參數(shù)的替代方案必須依賴于手工制作的規(guī)則來建模空間關(guān)系。在這項工作中,重新討論了Shift操作,作者認(rèn)為這是最簡單的空間建模模塊之一。如圖1所示,標(biāo)準(zhǔn)的ViT構(gòu)建塊包括2個部分:注意力層和前饋網(wǎng)絡(luò)(FFN)。
作者用Shift操作取代前一個注意力層,同時保持后一個FFN部分的不變。給定一個輸入特征,建議的構(gòu)建塊將首先沿著4個空間方向移動一小部分通道,即左、右、上和下。因此,相鄰特征的信息被通道的Shift混合在一起。然后,隨后的FFN進(jìn)行通道混合,以進(jìn)一步融合來自相鄰?fù)ǖ赖男畔ⅰ?/p>
基于這個shift building block構(gòu)建了一個類似ViT的Backbone,即ShiftViT。令人驚訝的是,這個Backbone也可以很好地用于主流的視覺識別任務(wù)。性能與Swin Transformer相當(dāng),甚至更好。具體地說,在與Swin-T模型相同的計算預(yù)算內(nèi),ShiftViT在ImageNet數(shù)據(jù)集上達(dá)到了81.7%(相對于Swin-T的81.3%)。對于密集預(yù)測任務(wù),在COCO檢測數(shù)據(jù)集上平均精度(mAP)為45.7%(Swin-T的43.7%),在ADE20k分割數(shù)據(jù)集上平均精度(mIoU)為46.3%(Swin-T的44.5%)。
由于Shift操作已經(jīng)是最簡單的空間建模模塊,因此優(yōu)秀的性能必須來自于剩余的組件,如FFN中的線性層和激活函數(shù)。這些組件在現(xiàn)有的工作中研究較少,因為它們看起來微不足道。然而,為了進(jìn)一步揭開ViT工作的原因的神秘面紗,作者認(rèn)為應(yīng)該更多地關(guān)注這些組成部分,而不是僅僅關(guān)注注意力機(jī)制。
綜上所述,本工作的貢獻(xiàn)有兩方面:
提出了一個類似ViT的Backbone,其中普通的注意力層被一個非常簡單的Shift操作所取代。該模型可以獲得比Swin Transformer更好的性能
分析了ViT成功背后的原因。這暗示了注意力機(jī)制可能不是使ViT工作的關(guān)鍵因素。在今后的ViT研究中,應(yīng)該認(rèn)真對待其余的組成部分
2相關(guān)工作
2.1 Attention and Vision Transformers
Transformer首次被引入到自然語言處理(NLP)領(lǐng)域。它僅采用注意力機(jī)制來建立不同語言Token之間的聯(lián)系。由于出色的性能,Transformer已經(jīng)迅速主導(dǎo)了NLP領(lǐng)域,并成為事實上的標(biāo)準(zhǔn)。
受自然語言處理成功應(yīng)用的啟發(fā),注意力機(jī)制也受到了計算機(jī)視覺界越來越多的興趣。早期的勘探大致可分為兩類。一方面,一些文獻(xiàn)認(rèn)為注意力是一個即插即用的模塊,它可以無縫地集成到現(xiàn)有的CNN架構(gòu)中。具有代表性的工作包括non-local網(wǎng)絡(luò)、Relation網(wǎng)絡(luò)和CCNet。另一方面,一些工作的目標(biāo)是用注意力機(jī)制替代所有的卷積操作,如Local Relation網(wǎng)絡(luò)和Self-Attention。
雖然這兩種工作已經(jīng)顯示出了很有希望的結(jié)果,但它們?nèi)匀皇墙⒃贑NN架構(gòu)的基礎(chǔ)上的。ViT是利用純Transformer架構(gòu)進(jìn)行視覺識別任務(wù)的開創(chuàng)性工作。由于其令人印象深刻的表現(xiàn),該領(lǐng)域最近爆發(fā)了一波不斷上升的關(guān)于視覺Transformer的研究浪潮。
沿著這一研究方向,主要研究重點是改進(jìn)注意力機(jī)制,使其能夠滿足視覺信號的內(nèi)在特性。例如,MSViT構(gòu)建層次注意力層以獲得多尺度特征。Swin-Transformer在其注意力機(jī)制中引入了一種局部性約束。相關(guān)的工作還包括pyramid attention、local-global attention、cross attention等等。
與對注意力機(jī)制的特殊興趣不同,ViT的其余組成部分的研究較少。DeiT為視覺Transformer建立了一個標(biāo)準(zhǔn)的訓(xùn)練管道。大多數(shù)后續(xù)工作都繼承了它的配置,只對注意力機(jī)制做了一些修改。本文的工作也遵循了這種范式。然而,這項工作的目的并不是復(fù)雜注意力的設(shè)計。相反,本文的目的是表明,注意力機(jī)制可能不是使ViTs工作的關(guān)鍵部分。它甚至可以被一個非常簡單的Shift操作所取代。作者希望這些結(jié)果能夠激勵研究者重新思考注意力機(jī)制的作用。
2.2 MLP Variants
本文的工作與最近的多層感知器(MLP)變體有關(guān)。具體來說,MLP的變體提出通過一個純的類似MLP的架構(gòu)來提取圖像特征。跳出了ViT中基于注意力的框架。例如,MLP-Mixer引入了一個Token混合MLP,以直接連接所有空間位置。它消除了ViT的動態(tài)特性,但不失去準(zhǔn)確性。后續(xù)工作研究了更多的MLP設(shè)計,如空間門控單元或循環(huán)連接。
ShiftViT也可以歸類為純MLP架構(gòu),其中Shift操作被視為一個特殊的Token混合層。與現(xiàn)有的MLP工作相比,Shift操作更簡單,因為它不包含參數(shù),也沒有FLOP。此外,由于具有固定的線性權(quán)值,普通的MLP變體不能處理可變的輸入大小。Shift操作克服了這一障礙,因此使Backbone用于更多的視覺任務(wù),如目標(biāo)檢測和語義分割。
2.3 Shift Operation
Shift操作在計算機(jī)視覺中并不是什么新鮮事。早在2017年,它就被認(rèn)為是空間卷積操作的一種有效的替代方案。具體地說,它使用了一個類似三明治的體系結(jié)構(gòu),2個1×1卷積和一個Shift操作,來近似一個K×K卷積。在后續(xù)工作中,Shift操作進(jìn)一步擴(kuò)展到不同的變體,如active Shift、sparse Shift和partial Shift。
3Shift-ViT
3.1 架構(gòu)概覽
為了進(jìn)行公平的比較,作者遵循了Swin Transformer的體系結(jié)構(gòu)。體系結(jié)構(gòu)概述如圖2(a)。
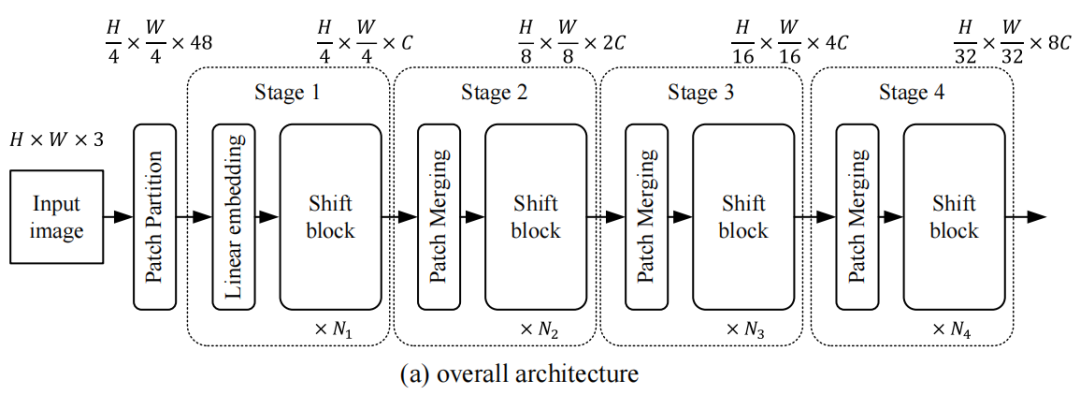
所示具體來說,給定一個形狀為H×W×3的輸入圖像,它首先將圖像分割成不重疊的patches。patch-size為4×4像素。因此,patch partition的輸出值為H/4×W/4 token,其中每個token的通道大小為48。
接下來的模塊可以分為4個階段。每個階段包括2個部分:嵌入生成和堆疊shift塊。對于第一階段的嵌入生成,使用一個線性投影層將每個token映射成一個通道大小為c的嵌入。對于其余的階段,通過核大小為2×2的卷積來合并相鄰的patch。patch合并后,輸出的空間大小是下采樣的一半,而通道大小是輸入的2倍,即從C到2C。
堆疊的shift塊是由一些重復(fù)的基本單元組成的。每個shift塊的詳細(xì)設(shè)計如圖2(b)。所示它由shift操作、層標(biāo)準(zhǔn)化和MLP網(wǎng)絡(luò)組成。這種設(shè)計幾乎與標(biāo)準(zhǔn)的Transformer組塊相同。唯一的區(qū)別是,使用的是一個shift操作,而不是一個注意力層。對于每個階段,shift塊的數(shù)量可以是不同的,分別記為、、、。在out實現(xiàn)中,仔細(xì)選擇了的值,從而使整個模型與 Baseline Swin Transformer模型共享相似數(shù)量的參數(shù)。
3.2 Shift Block
Shift Block的詳細(xì)體系結(jié)構(gòu)如圖2(b)。
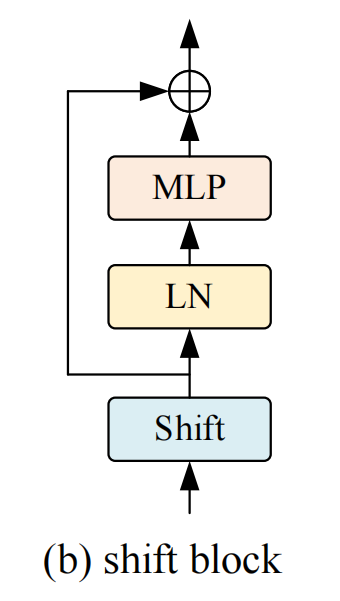
所示具體來說,該塊由3個順序堆疊的組件組成:Shift操作、層歸一化和MLP網(wǎng)絡(luò)。
Shift操作在cnn中已經(jīng)得到了很好的研究。它可以有許多設(shè)計選擇,如active Shift和sparse Shift。在本工作中遵循TSM中的partial Shift操作。如圖1(b)所示。給定一個輸入張量,一小部分的通道會沿著空間的4個方向移動,即左、右、上、下,而其余的通道保持不變。在Shift之后,超出范圍的像素被簡單地刪除,空白像素被填充為零。在本工作中,Shift步長設(shè)置為1像素。
形式上,假設(shè)輸入特征z的形狀為H×W×C,其中C為通道數(shù),H和W分別為空間高度和寬度。輸出特性z與輸入特征具有相同的形狀。它可以寫成:
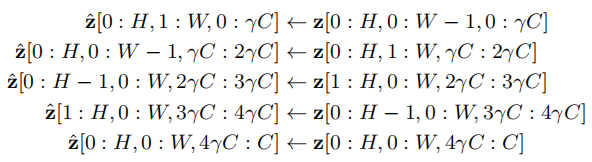
其中是一個比率因子來控制通道的百分比。在大多數(shù)實驗中,的值被設(shè)置為1/12。

值得注意的是,Shift操作不包含任何參數(shù)或算術(shù)計算。唯一的實現(xiàn)是內(nèi)存復(fù)制。因此,Shift操作效率高,易于實現(xiàn)。該偽代碼在算法1中提出。與自注意力機(jī)制相比,Shift操作對TensorRT等深度學(xué)習(xí)推理庫更干凈、整潔、更友好。
Shift塊的其余部分與ViT的標(biāo)準(zhǔn)構(gòu)建塊相同。MLP網(wǎng)絡(luò)有2個線性層。第一個方法將輸入特征的通道增加到一個更高的維度,例如,從C到τC。然后,第2個線性層將高維特征投影到c的原始通道大小中。在這兩層之間,采用GELU作為非線性激活函數(shù)。
3.3 架構(gòu)變體
為了與Baseline Swin Transformer進(jìn)行比較,作者還構(gòu)建了多個具有不同數(shù)量參數(shù)和計算復(fù)雜度的模型。具體來說,引入了Shift-T(iny)、Shift-S(mall)、Shift-B(ase)變種,分別對應(yīng)于swin-t、swin-s和swin-b。Shift-T是最小的,它與Swin-T和ResNet-50的大小相似。另外兩種變體,Shift-S和Shift-B,大約比shiftvit復(fù)雜2倍和4倍。基本嵌入通道C的詳細(xì)配置和塊數(shù){}如下:
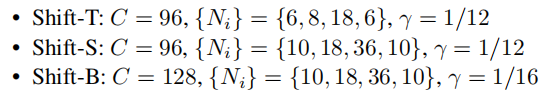
除了模型尺寸之外,作者還仔細(xì)觀察了模型的深度。在提出的模型中,幾乎所有的參數(shù)都集中在MLP部分。因此,可以控制MLP τ的擴(kuò)展比來獲得更深的網(wǎng)絡(luò)深度。如果未指定,則將展開比率τ設(shè)置為2。消融分析表明,更深層次的模型獲得了更好的性能。
4實現(xiàn)
4.1 消融實驗
1、Expand ratio of MLP
之前的實驗證明了本文的設(shè)計原則,即大的模型深度可以彌補每個構(gòu)件的不足。通常,在模型深度和構(gòu)建塊的復(fù)雜性之間存在一種權(quán)衡。有了固定的計算預(yù)算,輕量級的構(gòu)建塊可以享受更深層次的網(wǎng)絡(luò)工作架構(gòu)。
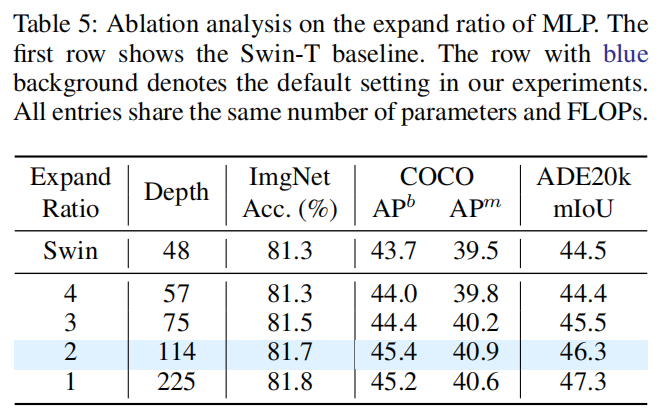
為了進(jìn)一步研究這種權(quán)衡,作者提供了一些具有不同深度的ShiftViT模型。對于ShiftViT,大多數(shù)參數(shù)存在于MLP部分。作者可以通過改變MLP τ的擴(kuò)展比來控制模型深度。如表5所示,選擇Shift-T作為基線模型。研究了在1到4范圍內(nèi)的擴(kuò)張比τ。值得注意的是,不同條目的參數(shù)和FLOPs幾乎是相同的。
從表5中,可以觀察到一個趨勢,即模型越深入,性能越好。當(dāng)ShiftViT的深度增加到225時,在分類、檢測和分割上分別比57層的分類、檢測和分割的絕對增益提高了0.5%、1.2%和2.9%。這種趨勢支持了猜想,即強大而沉重的模塊,如attention,可能不是Backbone的最佳選擇。
2、Percentage of shifted channels
Shift操作只有一個超參數(shù),即移位信道的百分比。缺省情況下,設(shè)置為33%。在本節(jié)中探討其他一些設(shè)置。具體來說,將移動通道的比例分別設(shè)置為20%、25%、33%和50%。結(jié)果如圖3所示。這表明最終性能對這個超參數(shù)不是很敏感。與最佳設(shè)置相比,移動25%的通道只會導(dǎo)致0.3%的絕對損失。在合理的范圍內(nèi)(25%-50%),所有的設(shè)置都達(dá)到了比Swin-T Baseline更好的精度。
3、Shifted pixels
在Shift操作中,一小部分通道沿4個方向移動一個像素。為了進(jìn)行全面的探索,還嘗試了不同的移動像素。當(dāng)偏移的像素為0,即沒有發(fā)生偏移時,ImageNet數(shù)據(jù)集的Top-1精度僅為72.9%,明顯低于本文的Baseline(81.7%)。這并不奇怪,因為沒有移動意味著不同的空間位置之間沒有相互作用。此外,如果在shift操作中移動兩個像素,模型在ImageNet上達(dá)到80.2%的top-1精度,這也比默認(rèn)設(shè)置略差。
4、ViT-style training scheme
Shift操作在cnn中已經(jīng)得到了很好的研究。然而,以往的工作并沒有像該工作那樣令人印象深刻。Shift-ResNet-50在ImageNet上的準(zhǔn)確率僅為75.6%,遠(yuǎn)低于81.7%的準(zhǔn)確率。這一差距引發(fā)了一種自然的擔(dān)憂,即什么對ViT有利。
作者懷疑原因可能在于虛擬現(xiàn)實式的訓(xùn)練計劃。具體來說,大多數(shù)現(xiàn)有的ViT變體遵循DeiT中的設(shè)置,這與訓(xùn)練cnn的標(biāo)準(zhǔn)管道有很大不同。例如,ViT-style方案采用AdamW優(yōu)化器,在ImageNet上訓(xùn)練時長為300 epoch。相比之下,cnn風(fēng)格的方案更傾向于SGD優(yōu)化器,訓(xùn)練計劃通常只有90 epoch。由于本文的模型繼承了ViT-style訓(xùn)練方案,觀察這些差異如何影響性能是很有趣的。
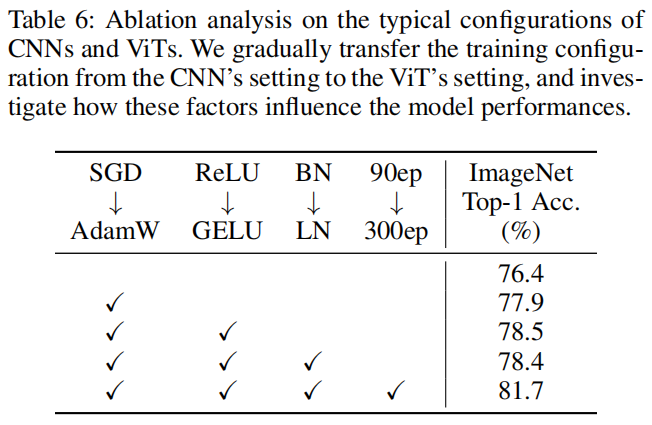
由于資源限制,不能完全對齊所有設(shè)置之間的ViT-style和CNN-style。因此,選擇了4個認(rèn)為可以帶來啟示的重要因素,即優(yōu)化器、激活函數(shù)、規(guī)范化層和訓(xùn)練計劃。從表6可以看出,這些因素可以顯著影響準(zhǔn)確性,尤其是訓(xùn)練進(jìn)度。這些結(jié)果表明,ShiftViT良好的性能部分是由ViT-style訓(xùn)練方案帶來的。同樣,ViT的成功也可能與其特殊的訓(xùn)練計劃有關(guān)。在今后的ViT研究中應(yīng)該認(rèn)真對待這一問題。
4.2 ImageNet and COCO
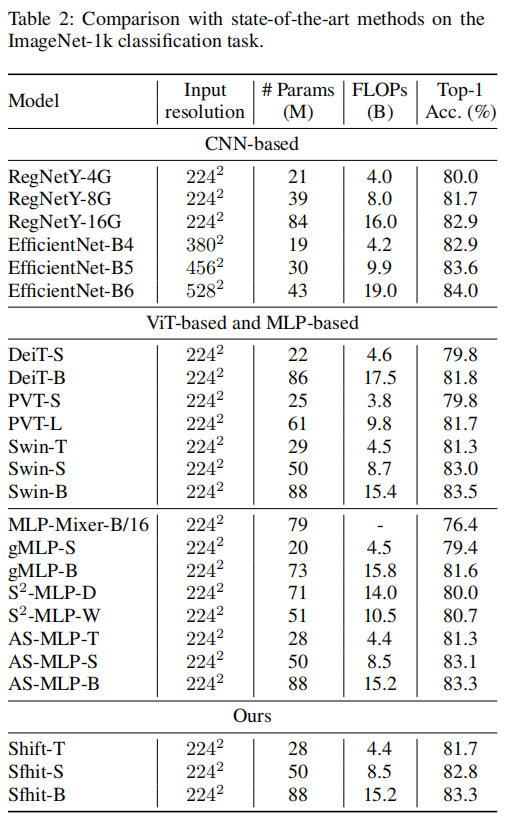
總的來說,本文的方法可以實現(xiàn)與最先進(jìn)技術(shù)相媲美的性能。對于基于ViT和基于mlp的方法,其最佳性能約為83.5%,而本文的模型達(dá)到了83.3%的精度。對于基于CNN的方法,本文的模型略差于但是比較并不完全公平,因為EfficientNet采用更大的輸入大小。
另一件有趣的事情是與2個工作S^2-MLP和AS-MLP。這兩部分的工作在移Shift操作上有相似的想法,但是它們在構(gòu)建塊中引入了一些輔助模塊,例如投影前層和投影后層。在表2中,本文的表現(xiàn)略好于這兩項工作。這證明了設(shè)計選擇,僅僅用一個簡單的Shift操作就可以很好的搭建Backbone。
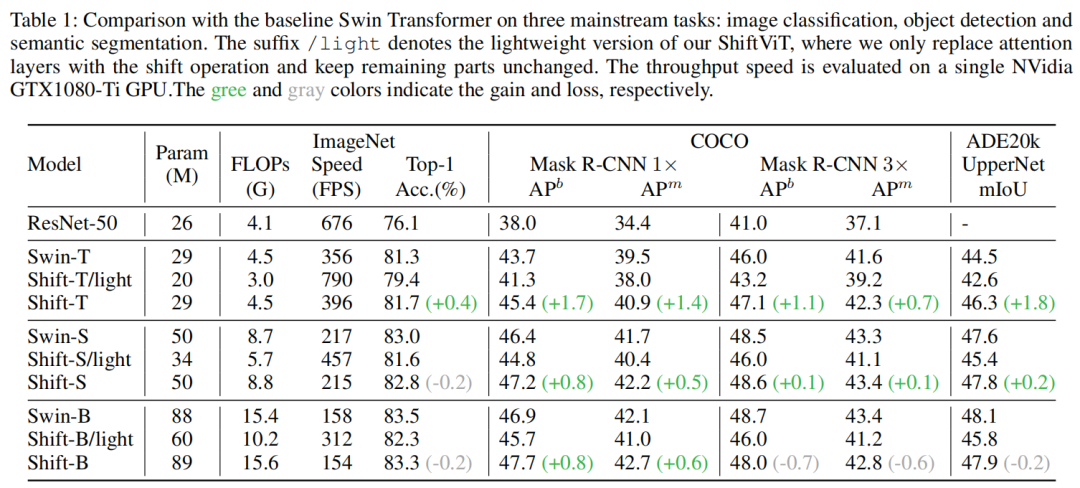
除了分類任務(wù)外,目標(biāo)檢測任務(wù)和語義分割任務(wù)也可以觀察到相似的性能軌跡。值得注意的是,一些基于ViT和基于mlp的方法不容易擴(kuò)展到如此密集的預(yù)測任務(wù),因為高分辨率的輸入產(chǎn)生了難以負(fù)擔(dān)的計算負(fù)擔(dān)。由于Shift操作的高效率,本文的方法不存在這種障礙。
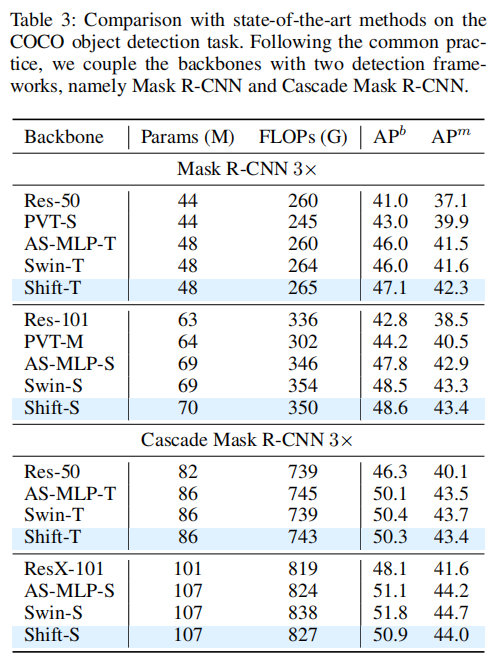
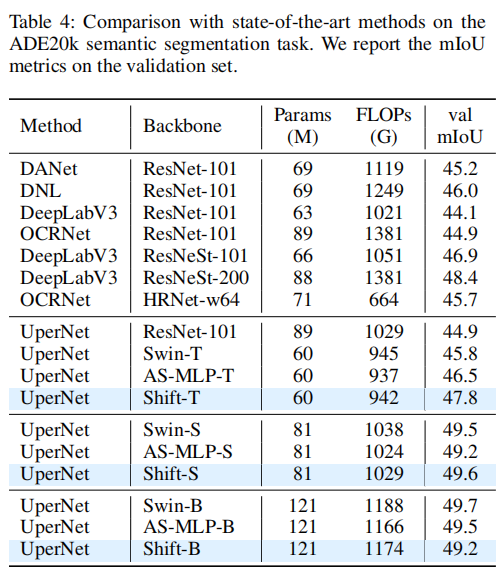
如表3和表4所示,ShiftViT的優(yōu)勢是顯而易見的。ShiftT在目標(biāo)檢測上的mAP得分為47.1分,在語義分割上的mIoU得分為47.8分,明顯優(yōu)于其他方法。
5參考
[1].When Shift Operation Meets Vision Transformer:An Extremely Simple Alternative to Attention Mechanism
推薦閱讀
輔助模塊加速收斂,精度大幅提升!移動端實時的NanoDet-Plus來了!
機(jī)器學(xué)習(xí)算法工程師
? ??? ? ? ? ? ? ? ? ? ? ????????? ??一個用心的公眾號
