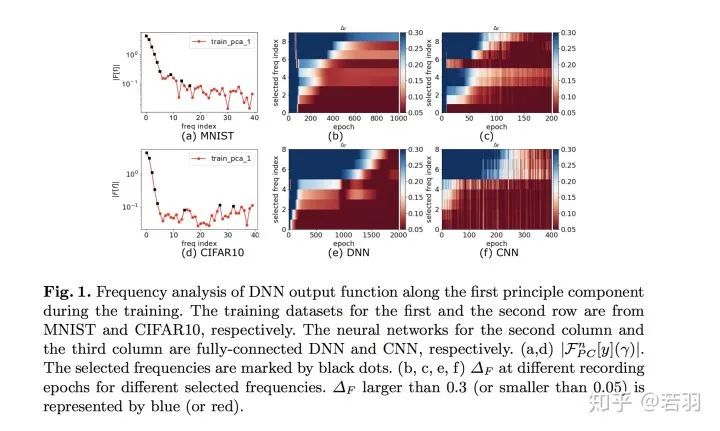
↑ 點(diǎn)擊藍(lán)字?關(guān)注極市平臺(tái)本文授權(quán)自知乎問(wèn)答,轉(zhuǎn)載需獲得原作者授權(quán)。我覺(jué)得這個(gè)對(duì)我啟發(fā)最大的是上海交大許志欽的工作。https://ins.sjtu.edu.cn/people/xuzhiqin/fprinciple/index.htmlhttps://www.bilibili.com/video/av94808183?p=2另外,我大概線下聽(tīng)過(guò)他兩次演講,幾乎都是關(guān)于神經(jīng)網(wǎng)絡(luò)與傅立葉變換、傅里葉分析方面的工作。Training behavior of deep neural network in frequency domainhttps://arxiv.org/pdf/1807.01251.pdf這篇論文,開(kāi)宗明義就是神經(jīng)網(wǎng)絡(luò)的泛化性能來(lái)源于它在訓(xùn)練過(guò)程,會(huì)更多關(guān)注低頻分量。CIFAR-10、MNIST的神經(jīng)網(wǎng)絡(luò)的擬合過(guò)程,藍(lán)色代表低頻、紅色代表高頻,越到后面,接近于收斂的情況下,需要學(xué)習(xí)的低頻分量越少。
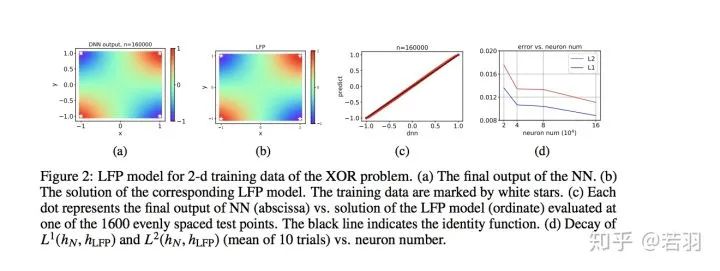
Theory of the frequency principle for general deep neural networkshttps://arxiv.org/pdf/1906.09235v2.pdf做了大量的數(shù)學(xué)推導(dǎo)證明F-Principle,分成訓(xùn)練的初始階段、中間階段、收尾階段分別證明,對(duì)于非數(shù)學(xué)專(zhuān)業(yè)的人,有點(diǎn)繁瑣。Explicitizing an Implicit Bias of the Frequency Principle in Two-layer Neural Networkshttps://arxiv.org/pdf/1905.10264.pdf為什么參數(shù)比樣本多的深層神經(jīng)網(wǎng)絡(luò)(DNNs)通常能很好地泛化,這仍然是個(gè)謎。理解這一難題的一個(gè)嘗試是發(fā)現(xiàn)DNNs訓(xùn)練過(guò)程中的隱含偏差,例如頻率原理(F-Principle),即DNNs通常從低頻到高頻擬合目標(biāo)函數(shù)。受F-Principle的啟發(fā),該論文提出了一個(gè)有效的線性F-Principle動(dòng)力學(xué)模型,該模型能準(zhǔn)確預(yù)測(cè)大寬度的兩層ReLU神經(jīng)網(wǎng)絡(luò)(NNs)的學(xué)習(xí)結(jié)果。這種Linear FP動(dòng)力學(xué)被NNs的線性化Mean Field剩余動(dòng)力學(xué)合理化。重要的是,這種LFP動(dòng)力學(xué)的長(zhǎng)時(shí)間極限解等價(jià)于顯式最小化FP范數(shù)的約束優(yōu)化問(wèn)題的解,其中可行解的高頻率受到更嚴(yán)重的懲罰。利用該優(yōu)化公式,給出了泛化誤差界的先驗(yàn)估計(jì),表明目標(biāo)函數(shù)的FP范數(shù)越高,泛化誤差越大。總的來(lái)說(shuō),通過(guò)將F-Principle的隱式偏差解釋為兩層NNs的顯式懲罰,這個(gè)工作朝著定量理解一般DNNs的學(xué)習(xí)和泛化邁出了一步。這個(gè)是圖像類(lèi)的二維數(shù)據(jù)的LFP模型示意圖。
LFP 模型為神經(jīng)網(wǎng)絡(luò)的定量理解提供了全新的思路。首先,LFP 模型用一個(gè)簡(jiǎn)單的微分方程有效地刻畫(huà)了神經(jīng)網(wǎng)絡(luò)這樣一個(gè)參數(shù)極多的系統(tǒng)其訓(xùn)練過(guò)程的關(guān)鍵特征,并且能夠精確地預(yù)測(cè)神經(jīng)網(wǎng)絡(luò)的學(xué)習(xí)結(jié)果。因此該模型從一個(gè)新的角度建立了微分方程和神經(jīng)網(wǎng)絡(luò)的關(guān)系。由于微分方程是一個(gè)非常成熟的研究領(lǐng)域,我們相信該領(lǐng)域的工具可以幫助我們進(jìn)一步分析神經(jīng)網(wǎng)絡(luò)的訓(xùn)練行為。
其次,與統(tǒng)計(jì)物理類(lèi)似,LFP 模型只與網(wǎng)絡(luò)參數(shù)的一些宏觀統(tǒng)計(jì)量有關(guān),而與單個(gè)參數(shù)的具體行為無(wú)關(guān)。這種統(tǒng)計(jì)刻畫(huà)可以幫助我們準(zhǔn)確理解在參數(shù)極多的情況下 DNN 的學(xué)習(xí)過(guò)程,從而解釋 DNN 在參數(shù)遠(yuǎn)多于訓(xùn)練樣本數(shù)時(shí)較好的泛化能力。
在該工作中,我們通過(guò)一個(gè)等價(jià)的優(yōu)化問(wèn)題來(lái)分析該 LFP 動(dòng)力學(xué)的演化結(jié)果,并且給出了網(wǎng)絡(luò)泛化誤差的一個(gè)先驗(yàn)估計(jì)。我們發(fā)現(xiàn)網(wǎng)絡(luò)的泛化誤差能夠被目標(biāo)函數(shù)f本身的一種 F-principle 范數(shù)(定義為  ,γ(ξ) 是一個(gè)隨頻率衰減的權(quán)重函數(shù))所控制。
,γ(ξ) 是一個(gè)隨頻率衰減的權(quán)重函數(shù))所控制。
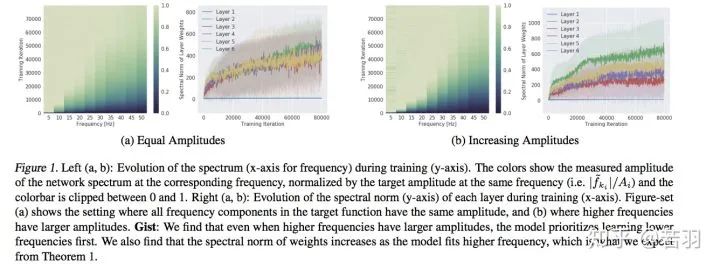
值得注意的是, 我們的誤差估計(jì)針對(duì)神經(jīng)網(wǎng)絡(luò)本身的學(xué)習(xí)過(guò)程,并不需要在損失函數(shù)中添加額外的正則項(xiàng)。關(guān)于該誤差估計(jì)我們將在之后的介紹文章中作進(jìn)一步說(shuō)明。FREQUENCY PRINCIPLE: FOURIER ANALYSIS SHEDS LIGHT ON DEEP NEURAL NETWORKShttps://arxiv.org/pdf/1901.06523.pdf這表明,對(duì)于任意兩個(gè)非收斂頻率,在較小的權(quán)重下,低頻梯度指數(shù)性地優(yōu)于高頻梯度。根據(jù)Parseval定理,空間域中的MSE損失與Fourier域中的L2損失等效。為了更直觀地理解低頻損耗函數(shù)的高衰減率,我們考慮了在只有兩個(gè)非零頻率的損失函數(shù)的Fourier域中的訓(xùn)練。解釋了ReLU函數(shù)為什么Work,因?yàn)閠anh函數(shù)在空間域是光滑的,其導(dǎo)數(shù)在傅里葉區(qū)域隨頻率呈指數(shù)衰減。許教授關(guān)于F-Principle的幾篇科普文:https://zhuanlan.zhihu.com/p/42847582https://zhuanlan.zhihu.com/p/72018102https://zhuanlan.zhihu.com/p/56077603https://zhuanlan.zhihu.com/p/57906094On the Spectral Bias of Deep Neural NetworksBengio組的工作,之前寫(xiě)過(guò)一個(gè)比較粗糙的分析札記:https://zhuanlan.zhihu.com/p/1608062291、利用連續(xù)分段線性結(jié)構(gòu)對(duì)ReLU網(wǎng)絡(luò)的傅里葉譜分量進(jìn)行分析。2、發(fā)現(xiàn)了譜分量偏差(Spectrum bias)的經(jīng)驗(yàn)證據(jù),來(lái)源于低頻分量,然而對(duì)低頻分量的學(xué)習(xí),有助于網(wǎng)絡(luò)在對(duì)抗干擾過(guò)程中的魯棒性。3、通過(guò)流形理論,給予學(xué)習(xí)理論框架分析。
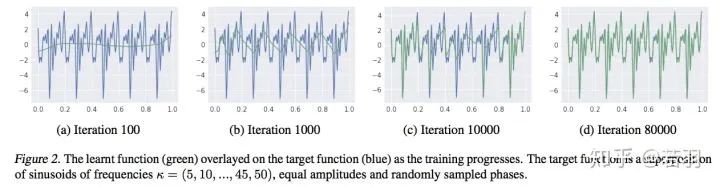
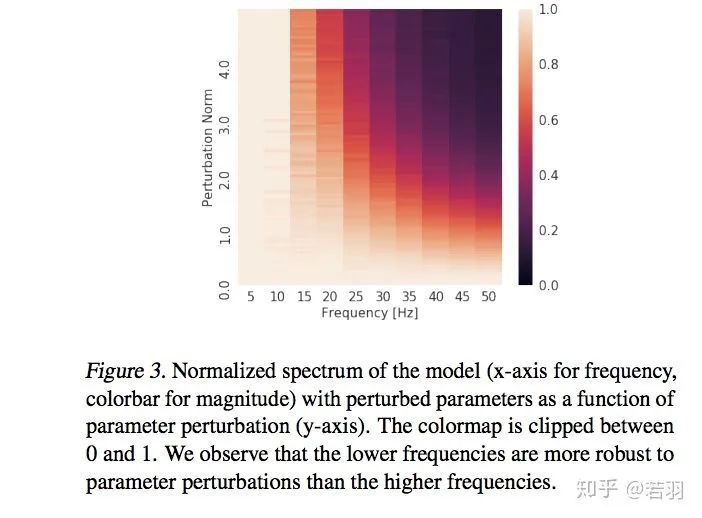
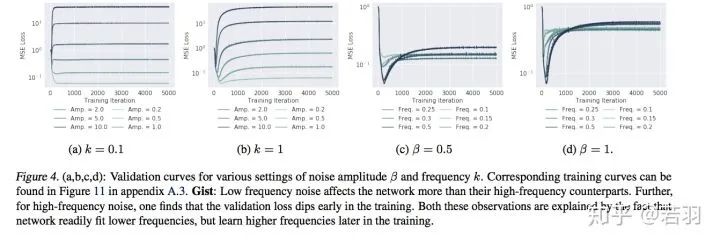
根據(jù)拓?fù)鋵W(xué)的Storkes定理,證明ReLU函數(shù)緊湊、光滑,有助于訓(xùn)練的收斂,之后的Swish和Mish呢?(狗頭)。這樣,在高維空間中,ReLU函數(shù)的譜衰減具有強(qiáng)烈的各向異性,ReLU傅立葉變換幅度的上限滿足李普希茨約束。中心點(diǎn):低頻分量學(xué)習(xí)優(yōu)先級(jí)高- 對(duì)函數(shù)做實(shí)驗(yàn):

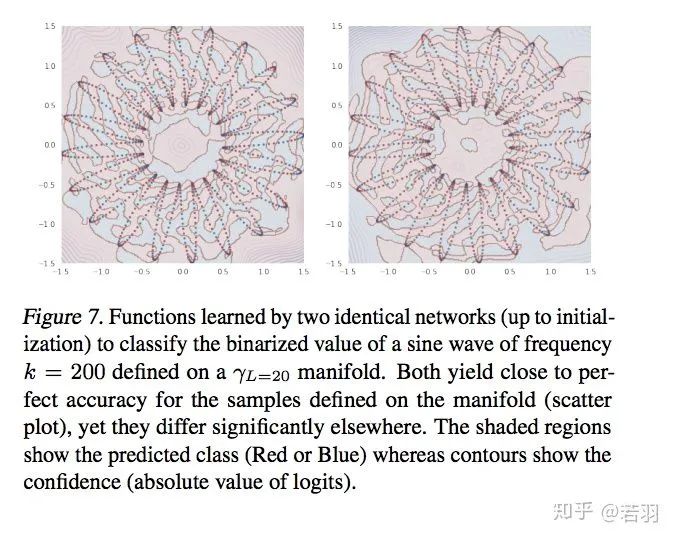
迭代過(guò)程對(duì)函數(shù)的學(xué)習(xí)
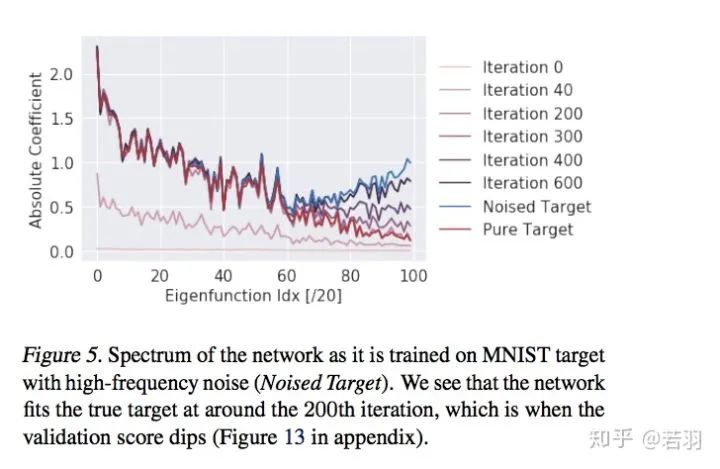
2. 帶噪環(huán)境學(xué)習(xí)MNIST數(shù)據(jù)
神經(jīng)網(wǎng)絡(luò)可以近似任意值功能,但研究人員發(fā)現(xiàn)他們更喜歡低頻的分量,也因此,它們表現(xiàn)出對(duì)平滑函數(shù)的偏倚——被稱(chēng)之為譜偏移(spectral bias)的現(xiàn)象。
流形越復(fù)雜,然后學(xué)習(xí)過(guò)程越容易,這個(gè)假設(shè)會(huì)Break“結(jié)構(gòu)風(fēng)險(xiǎn)最小化”假設(shè),有可能會(huì)出現(xiàn)“過(guò)擬合”。
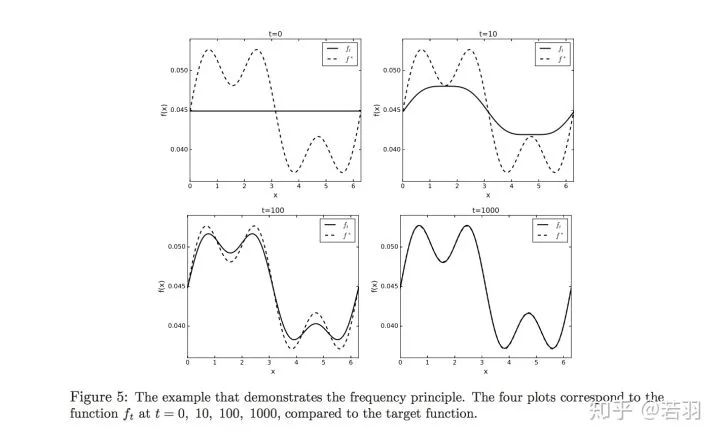
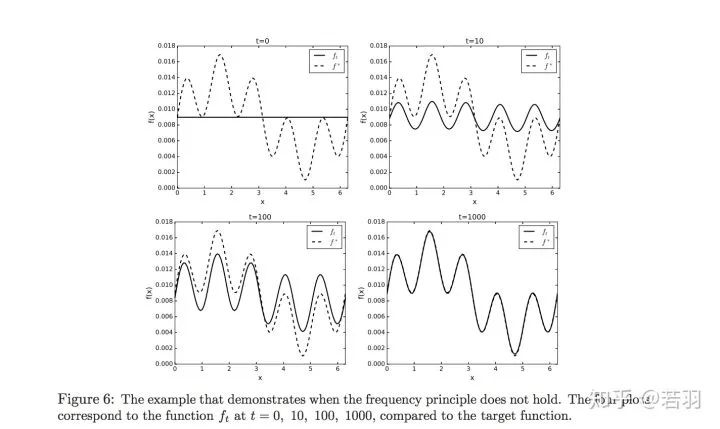
如果有復(fù)雜的數(shù)據(jù)集(ImageNet),搜索空間比較大,也要通過(guò)一定的方法,使其“work in harmony”,調(diào)諧地工作。感覺(jué)Bengio認(rèn)為其對(duì)深度學(xué)習(xí)的正則化有啟發(fā)意義。Machine Learning from a Continuous Viewpointhttps://arxiv.org/pdf/1912.12777.pdf數(shù)學(xué)家Wienan.E的爭(zhēng)鳴,頻率原則并不總是Work的。

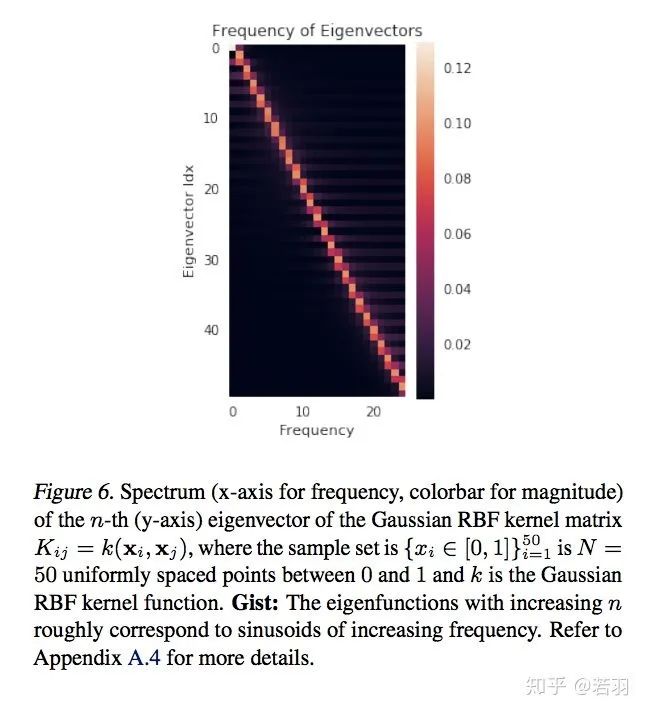
 概率測(cè)度基于核函數(shù)對(duì)其求導(dǎo):
概率測(cè)度基于核函數(shù)對(duì)其求導(dǎo):
如果說(shuō)Wienan. E是從數(shù)學(xué)家的角度給出了Frequency Principle的邊界的話,那么做工程的小伙伴一定要看看這篇論文:A Fourier Perspective on Model Robustness in Computer Visionhttps://arxiv.org/pdf/1906.08988.pdfhttps://github.com/google-research/google-research/tree/master/frequency_analysis作者的意思是關(guān)注魯棒性,不能完全丟掉高頻特征。
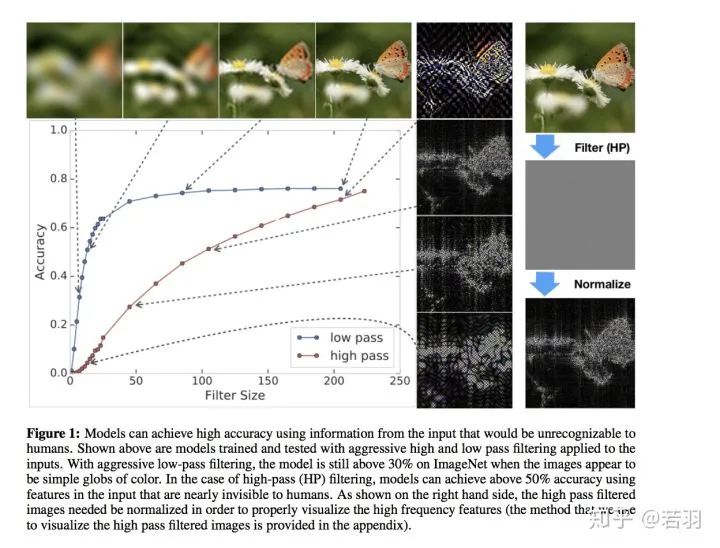
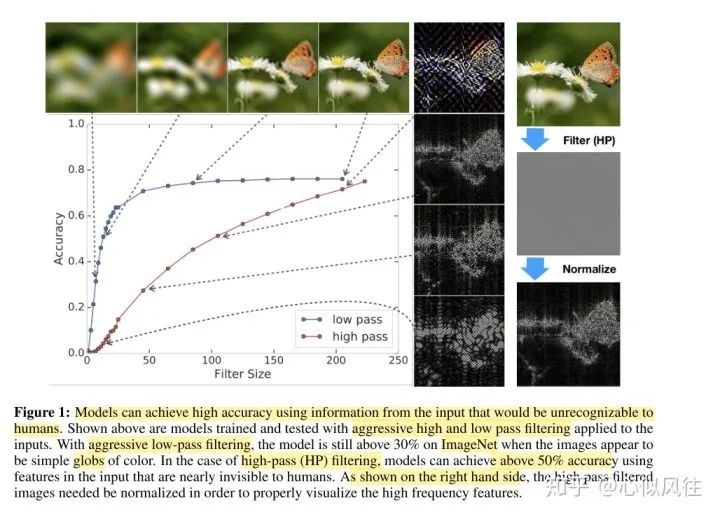
圖片說(shuō)明翻譯:使用人類(lèi)無(wú)法識(shí)別的輸入信息,模型可以實(shí)現(xiàn)高精度。上面顯示的是經(jīng)過(guò)訓(xùn)練和測(cè)試的模型,這些模型在輸入端應(yīng)用了嚴(yán)格的高通和低通濾波。通過(guò)積極的低通濾波,當(dāng)圖像看起來(lái)是簡(jiǎn)單的彩色球體時(shí),該模型在ImageNet上仍然高于30%。在高通(HP)過(guò)濾的情況下,使用人類(lèi)幾乎看不見(jiàn)的輸入特征,模型可以達(dá)到50%以上的精度。如右圖所示,需要對(duì)高通濾波圖像進(jìn)行歸一化處理,以便正確地可視化高頻特征(我們用附錄中提供的可視化高通濾波圖像的方法)。
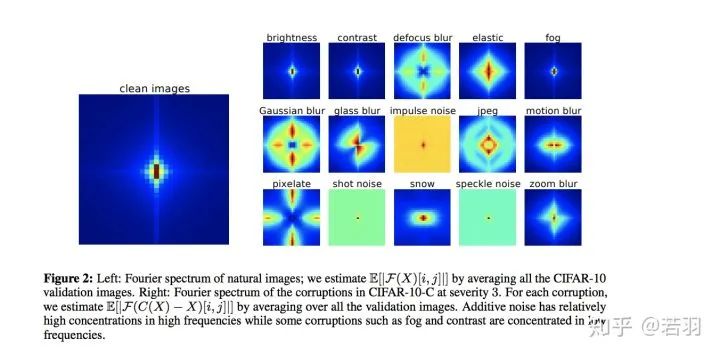
圖片說(shuō)明翻譯:左:自然圖像的傅里葉譜;我們通過(guò)平均所有CIFAR-10驗(yàn)證圖像來(lái)估計(jì)E[|F(X)[i,j]|]。右:CIFAR-10-C中嚴(yán)重程度為3的腐敗的傅里葉譜。對(duì)于每個(gè)腐敗,我們通過(guò)平均所有驗(yàn)證圖像來(lái)估計(jì)E[|F(C(X)?X)[i,j]|]。加性噪聲在高頻段具有較高的濃度,而霧、對(duì)比度等污染集中在低頻段。
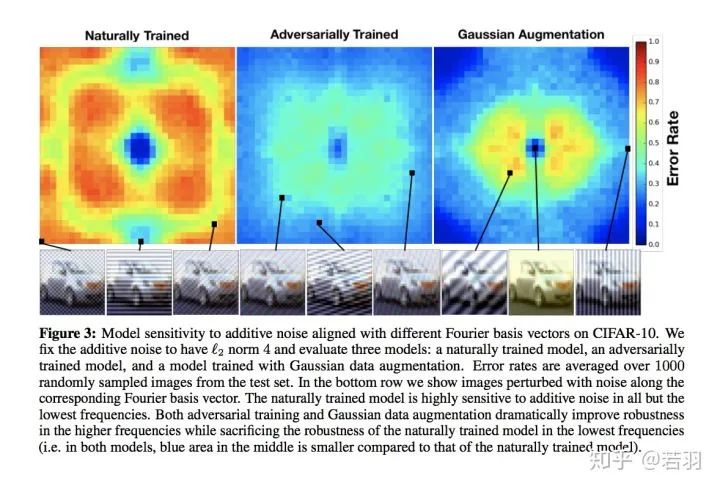
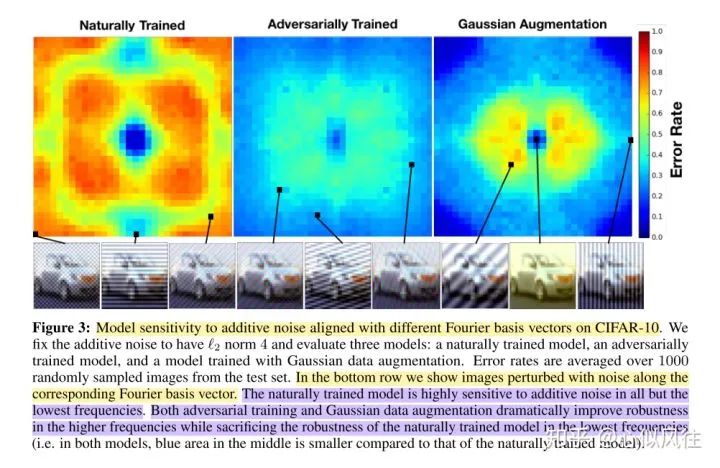
圖片翻譯說(shuō)明:CIFAR-10上不同傅立葉基向量對(duì)加性噪聲的模型靈敏度。我們將加性噪聲固定為“L2范數(shù)為4”,并評(píng)估了三個(gè)模型:自然訓(xùn)練模型、對(duì)抗訓(xùn)練模型和高斯數(shù)據(jù)增強(qiáng)訓(xùn)練模型。對(duì)來(lái)自測(cè)試集中的1000個(gè)隨機(jī)采樣的圖像進(jìn)行平均錯(cuò)誤率。在最下面的一行中,我們顯示了沿著相應(yīng)的傅立葉基向量受到噪聲干擾的圖像。自然訓(xùn)練的模型對(duì)除最低頻率以外的所有加性噪聲都高度敏感。對(duì)抗性訓(xùn)練和高斯數(shù)據(jù)增強(qiáng)都極大地提高了高頻下的魯棒性,而犧牲了自然訓(xùn)練模型在低頻率下的魯棒性(即,在這兩個(gè)模型中,中間的藍(lán)色區(qū)域比自然訓(xùn)練模型的小)。
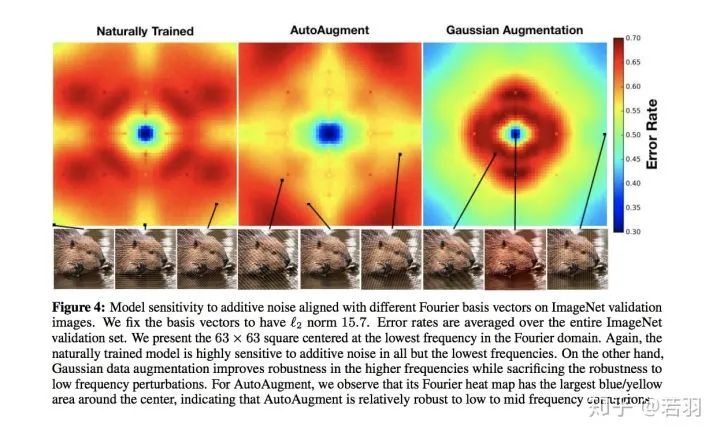
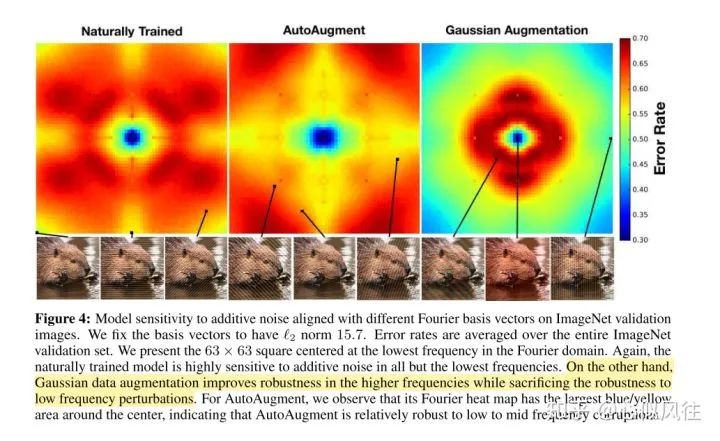
圖片翻譯說(shuō)明:ImageNet驗(yàn)證圖像上的不同傅立葉基向量對(duì)加性噪聲的模型敏感度。我們將基向量固定為L(zhǎng)2范數(shù)的值等于15.7。錯(cuò)誤率是整個(gè)ImageNet驗(yàn)證集的平均錯(cuò)誤率。給出了以傅里葉域最低頻率為中心的63×63平方。同樣,自然訓(xùn)練的模型對(duì)除最低頻率之外的所有加性噪聲都高度敏感。另一方面,高斯數(shù)據(jù)增強(qiáng)提高了高頻下的魯棒性,同時(shí)犧牲了對(duì)低頻擾動(dòng)的魯棒性。對(duì)于AutoAugment,我們觀察到它的傅立葉熱圖在中心周?chē)凶畲蟮乃{(lán)色/黃色區(qū)域,這表明AutoAugment對(duì)低頻到中頻的破壞是相對(duì)健壯的。
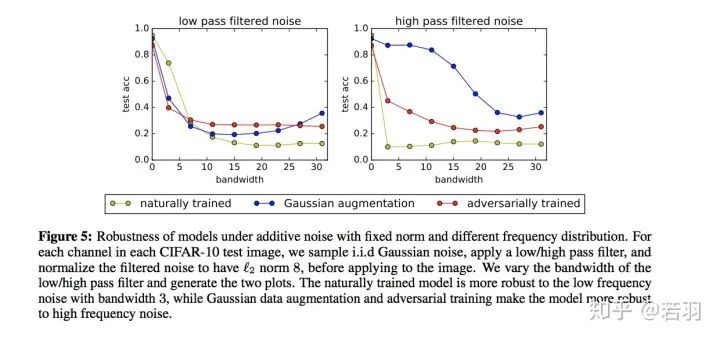
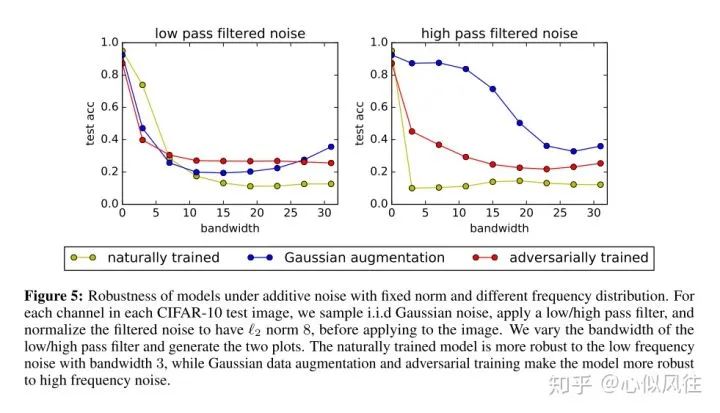
圖片翻譯說(shuō)明:固定范數(shù)和不同頻率分布的加性噪聲下模型的穩(wěn)健性。對(duì)于每個(gè)CIFAR-10測(cè)試圖像中的每個(gè)通道,在應(yīng)用到圖像之前,我們對(duì)獨(dú)立同分布高斯噪聲進(jìn)行采樣,應(yīng)用低/高通濾波器,并將濾波后的噪聲歸一化為L(zhǎng)2范數(shù)值為8。我們改變低/高通濾波器的帶寬,生成兩個(gè)曲線圖。自然訓(xùn)練的模型對(duì)帶寬為3的低頻噪聲具有更強(qiáng)的魯棒性,而高斯數(shù)據(jù)增強(qiáng)和對(duì)抗性訓(xùn)練使模型對(duì)高頻噪聲具有更強(qiáng)的魯棒性。
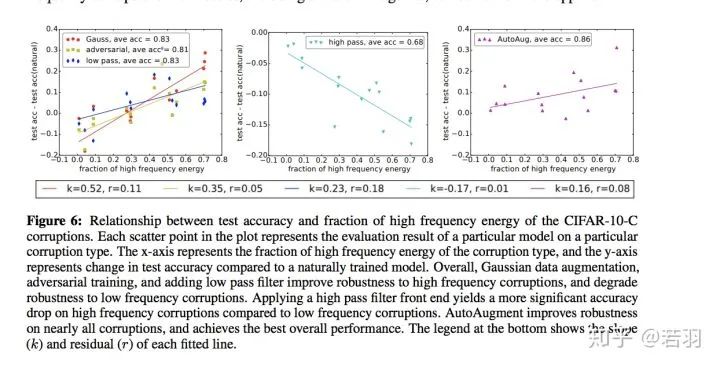
圖片翻譯說(shuō)明:CIFAR-10-C腐蝕高頻能量分?jǐn)?shù)與測(cè)試精度的關(guān)系。繪圖中的每個(gè)散布點(diǎn)代表特定模型對(duì)特定損壞類(lèi)型的評(píng)估結(jié)果。X軸表示損壞類(lèi)型的高頻能量的分?jǐn)?shù),y軸表示與自然訓(xùn)練的模型相比測(cè)試精度的變化。總體而言,高斯數(shù)據(jù)增強(qiáng)、對(duì)抗性訓(xùn)練和添加低通濾波器提高了對(duì)高頻破壞的魯棒性,降低了對(duì)低頻破壞的魯棒性。與低頻損壞相比,應(yīng)用高通濾波器前端對(duì)高頻損壞產(chǎn)生更顯著的精度下降。AutoAugment提高了對(duì)幾乎所有損壞的健壯性,并實(shí)現(xiàn)了最佳的整體性能。底部的圖例顯示了每條擬合線的斜率(K)和殘差(r)。
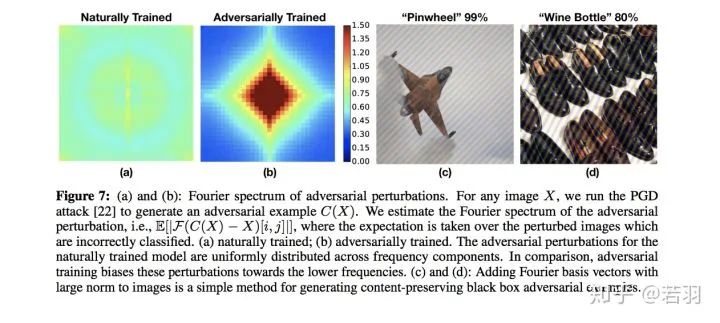
圖片翻譯說(shuō)明:(a)和(b):對(duì)抗擾動(dòng)的傅立葉頻譜,給定圖片X,發(fā)起PGD攻擊,得到對(duì)抗樣本C(X),估算對(duì)抗擾動(dòng)的傅立葉頻譜,會(huì)使得圖片錯(cuò)誤分類(lèi);(a) 是自然訓(xùn)練得到的頻譜;(b)是對(duì)抗訓(xùn)練得到的頻譜。自然訓(xùn)練模型的對(duì)抗性擾動(dòng)均勻分布在頻率分量上。相比之下,對(duì)抗性的訓(xùn)練使這些擾動(dòng)偏向較低的頻率。(C)和(D):將范數(shù)大的傅立葉基向量加到圖像上是一種生成內(nèi)容保持黑盒對(duì)抗性示例的簡(jiǎn)單方法。1) 對(duì)抗訓(xùn)練會(huì)關(guān)注到一些高頻分量,而非一味執(zhí)迷于低頻分量。開(kāi)源代碼主要教人畫(huà)出論文中類(lèi)似的示意圖。另外一篇論文Eric Xing組里的,知乎的自媒體之前發(fā)過(guò)了:High-frequency Component Helps Explain the Generalization of Convolutional Neural Networkshttps://arxiv.org/pdf/1905.13545.pdf自然訓(xùn)練的卷積的可視化與對(duì)抗訓(xùn)練的卷積的可視化該論文實(shí)驗(yàn)了幾個(gè)方法:對(duì)于一個(gè)訓(xùn)練好的模型,我們調(diào)整其權(quán)重,使卷積核變得更加平滑;
直接在訓(xùn)練好的卷積核上將高頻信息過(guò)濾掉;
在訓(xùn)練卷積神經(jīng)網(wǎng)絡(luò)的過(guò)程中增加正則化,使得相鄰位置的權(quán)重更加接近。
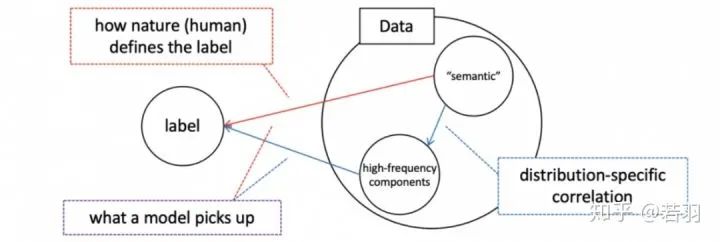
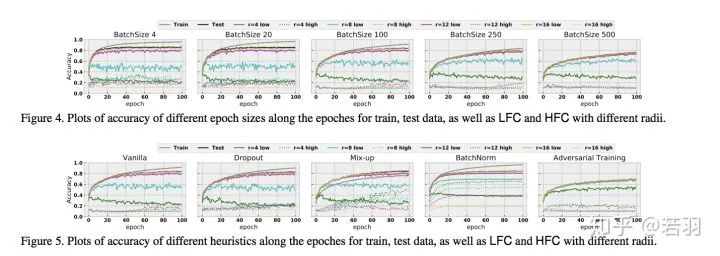
關(guān)注低頻信息,有助于提高泛化性,高頻分量可能與對(duì)抗攻擊有聯(lián)系,但不能太武斷。Contribution是用詳細(xì)的實(shí)驗(yàn)證明Batch Normalization對(duì)于擬合高頻分量,提高泛化性是有用的。
這邊廂,許教授證明ReLU的光滑性有助于函數(shù)優(yōu)化;那邊廂,近期的一個(gè)工作叫Bandlimiting Neural networks against adversarial attackshttps://arxiv.org/pdf/1905.12797.pdfReLU函數(shù)得到一種piecewise的linear function
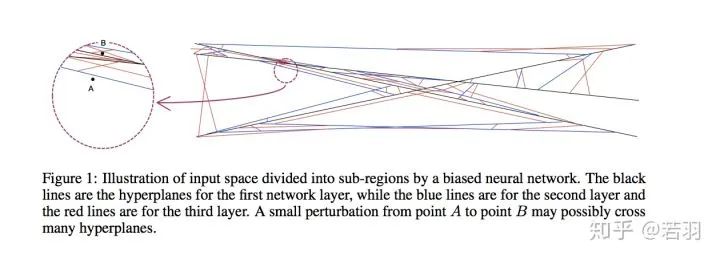
對(duì)于N=1000個(gè)節(jié)點(diǎn)的隱藏層,并且輸入維度為n=200時(shí),區(qū)域的最大數(shù)目大致等于10^200。換言之,即使是一個(gè)中等規(guī)模的神經(jīng)網(wǎng)絡(luò)也可以將輸入空間劃分為大量的子區(qū)域,這很容易超過(guò)宇宙中的原子總數(shù)。當(dāng)我們學(xué)習(xí)神經(jīng)網(wǎng)絡(luò)時(shí),我們不能期望每個(gè)區(qū)域內(nèi)至少有一個(gè)樣本。對(duì)于那些沒(méi)有任何訓(xùn)練樣本的區(qū)域,其中的結(jié)果線性函數(shù)可以是任意的,因?yàn)樗鼈兏静粚?duì)訓(xùn)練目標(biāo)函數(shù)有貢獻(xiàn)。當(dāng)然,這些地區(qū)中的大多數(shù)都非常小。當(dāng)我們測(cè)量整個(gè)空間的預(yù)期損失函數(shù)時(shí),它們的貢獻(xiàn)可以忽略不計(jì),因?yàn)殡S機(jī)抽樣點(diǎn)落入這些微小區(qū)域的機(jī)會(huì)非常小。然而,對(duì)抗性攻擊帶來(lái)了新的挑戰(zhàn),因?yàn)閷?duì)抗性樣本不是自然抽樣的。考慮到區(qū)域的總數(shù)是巨大的,那么這些微小的區(qū)域在輸入空間中幾乎無(wú)處不在。對(duì)于輸入空間中的任何一個(gè)數(shù)據(jù)點(diǎn),我們幾乎肯定可以找到這樣一個(gè)微小的區(qū)域,其中線性函數(shù)是任意的。如果選擇了這個(gè)微小區(qū)域內(nèi)的一個(gè)點(diǎn),神經(jīng)網(wǎng)絡(luò)的輸出可能會(huì)出乎意料。這些微小的區(qū)域是神經(jīng)網(wǎng)絡(luò)易受敵意攻擊的根本原因。然后,提出了一種對(duì)抗防御的方法,表示沒(méi)看懂,看官自己讀論文,歡迎讀完在評(píng)論區(qū)點(diǎn)撥我。
雖然有拖延癥,但其他一些相關(guān)的、有趣的論文,我看到后也會(huì)在這個(gè)區(qū)分享的。https://www.zhihu.com/question/59532432/answer/1510340606收到邀請(qǐng)后,就關(guān)注了這個(gè)問(wèn)題一段時(shí)間,想著等一個(gè)有緣人回答這個(gè)問(wèn)題,我就能不費(fèi)時(shí)間的白嫖答案了,心中暗暗竊喜。然而,等了很長(zhǎng)時(shí)間,都沒(méi)有一個(gè)認(rèn)認(rèn)真真仔仔細(xì)細(xì)的回答。就只能自己出來(lái)拋磚引玉了。很神奇,正好讀過(guò)一篇文章是關(guān)于從頻域去理解和分析模型robustness,這篇文章部分內(nèi)容正好也分析了這個(gè)問(wèn)題,而且,非常巧的是:實(shí)驗(yàn)也是用的 ResNet。這不巧了么這不!A Fourier Perspective on Model Robustness in Computer Vision [1]首先,論文深度學(xué)習(xí)的模型取得了空前成功,但是有一個(gè)很大的問(wèn)題,這就是它的robustness很差,即對(duì)某些測(cè)試的圖片加一點(diǎn)corruption,圖片就會(huì)被分類(lèi)錯(cuò)誤。增強(qiáng)robustness的一個(gè)方法就是對(duì)training set 的圖片做data augmentation,讓訓(xùn)練出來(lái)的模型具有抵抗corruption的robustness。但是作者發(fā)現(xiàn),同樣的data augmentation方法如Gaussian augmentation和adversarial training,并非對(duì)所有的corruption情況都能提高robustness。那作者提出了一個(gè)問(wèn)題:為什么同樣的augmentation 的方法,對(duì)有些corruption是提升性能,而有些是降低性能的呢?然后,作者提出了一個(gè)假設(shè):莫非是不一樣的corruption提供的頻率信息不一樣?對(duì)于CIFAR-10,作者使用了 Wide ResNet-28-10;對(duì)于ImageNet,作者使用了 ResNet-50。作者分析了圖像不同頻率的信息對(duì)自然訓(xùn)練出的模型預(yù)測(cè)準(zhǔn)確性的影響。如上圖所示,作者用ImageNet訓(xùn)練的模型 ResNet-50做了實(shí)驗(yàn)。對(duì)于低頻信息,作者直接在測(cè)試圖像的頻域加了低通濾波器,不同濾波器的大小讓不同量的低通信號(hào)通過(guò),四個(gè)典型的濾波后的圖顯示在圖標(biāo)的上方。對(duì)高頻信息,作者在圖像的頻域加了高通濾波器,并且做了normalization。不同濾波器的大小讓不同量的高頻信號(hào)通過(guò),四個(gè)典型的濾波后的圖顯示在圖標(biāo)的右方。圖標(biāo)的x軸是濾波器的大小,y軸是分類(lèi)的準(zhǔn)確性。上面的圖表說(shuō)明:即使低通濾波器的大小非常小,圖像看起來(lái)就像色塊一樣,人眼根本分不清是什么,模型依然取得了超過(guò)30%的準(zhǔn)確性(低通濾波器得出的第一張圖)。而對(duì)于高通濾波的部分(從上往下第二張圖),即使人眼根本分不出這張圖里是什么東西,模型依然取得了50%準(zhǔn)確性。而且在低頻信息少時(shí),增加低頻信息能快速提高準(zhǔn)確性,當(dāng)?shù)竭_(dá)一定量時(shí)就不再影響了;高頻信息對(duì)準(zhǔn)確性的影響是逐漸提升的,沒(méi)有低頻快。訓(xùn)練集為CIFAR-10,作者分析了模型 Wide ResNet-28-10對(duì)additive noise的敏感性。圖中中間是低頻信號(hào)區(qū),越往邊緣頻率越高訓(xùn)練集為CIFAR-10,訓(xùn)練的模型是 Wide ResNet-28-10自然訓(xùn)練出來(lái)的模型對(duì)除了低頻corruption噪聲之外的其他頻率都很敏感,adversarial training 和Gaussian augmentation 提高了模型對(duì)高頻corruption 的robustness (錯(cuò)誤率低)。訓(xùn)練集為ImageNet,作者分析了模型 ResNet-50 對(duì)additive noise的敏感性。自然訓(xùn)練出來(lái)的模型對(duì)除了低頻corruption噪聲之外的其他頻率都很敏感,Gaussian augmentation 犧牲了對(duì)于低頻的perturbation 的robustness ,但是提高了高頻的。對(duì)AutoAugment,低頻、中頻、高頻的robustness逐漸降低。bandwidth增加時(shí),高頻信號(hào)和低頻信號(hào)對(duì)test accuracy的影響。訓(xùn)練集為CIFAR-10,模型為 Wide ResNet-28-10。相對(duì)于自然訓(xùn)練出的模型,隨著噪聲濾波器bandwidth的增加,testaccuracy都在降低,同時(shí)我們發(fā)現(xiàn),Gaussian augmentation和adversarial trainning得出的模型的accuracy都比自然訓(xùn)練得出的模型的accuracy高。補(bǔ)充1:根據(jù)本問(wèn)題下 @Lost 的回答,也建議大家去看一下他說(shuō)的那篇論文 Frequency Principle: Fourier Analysis Sheds Light on Deep Neural Networks[2]https://arxiv.org/pdf/1901.06523.pdf補(bǔ)充2:同樣建議大家讀下面這篇論文High-frequency Component Helps Explain the Generalization of Convolutional Neural Network[3]https://openaccess.thecvf.com/content_CVPR_2020/papers/Wang_High-Frequency_Component_Helps_Explain_the_Generalization_of_Convolutional_Neural_Networks_CVPR_2020_paper.pdf[1] A Fourier Perspective on Model Robustness in Computer Vision?[2] Frequency Principle: Fourier Analysis Sheds Light on Deep Neural Networks?[3] High-frequency Component Helps Explain the Generalization of Convolutional Neural Network?https://www.zhihu.com/question/59532432/answer/1447173834推薦閱讀
ACCV 2020國(guó)際細(xì)粒度網(wǎng)絡(luò)圖像識(shí)別競(jìng)賽正式開(kāi)賽!
添加極市小助手微信(ID : cvmart2),備注:姓名-學(xué)校/公司-研究方向-城市(如:小極-北大-目標(biāo)檢測(cè)-深圳),即可申請(qǐng)加入極市目標(biāo)檢測(cè)/圖像分割/工業(yè)檢測(cè)/人臉/醫(yī)學(xué)影像/3D/SLAM/自動(dòng)駕駛/超分辨率/姿態(tài)估計(jì)/ReID/GAN/圖像增強(qiáng)/OCR/視頻理解等技術(shù)交流群:每月大咖直播分享、真實(shí)項(xiàng)目需求對(duì)接、求職內(nèi)推、算法競(jìng)賽、干貨資訊匯總、與?10000+來(lái)自港科大、北大、清華、中科院、CMU、騰訊、百度等名校名企視覺(jué)開(kāi)發(fā)者互動(dòng)交流~
△長(zhǎng)按關(guān)注極市平臺(tái),獲取最新CV干貨覺(jué)得有用麻煩給個(gè)在看啦~??