
基于how-to-optimize-gemm初探矩陣乘法優(yōu)化
1. 前言
這次,我們來(lái)聊一個(gè)輕松一點(diǎn)的話題,那就是給你一個(gè)矩陣A和一個(gè)矩陣B,使用矩陣乘法獲得目標(biāo)矩陣C,相信大家都不難寫(xiě)出下面的代碼:
#define?A(?i,?j?)?a[?(i)*lda?+?(j)?]
#define?B(?i,?j?)?b[?(i)*ldb?+?(j)?]
#define?C(?i,?j?)?c[?(i)*ldc?+?(j)?]
//?gemm?C?=?A?*?B?+?C
void?MatrixMultiply(int?m,?int?n,?int?k,?float?*a,?int?lda,?float?*b,?int?ldb,?float?*c,?int?ldc)
{
????for(int?i?=?0;?i?????????for?(int?j=0;?j????????????for?(int?p=0;?p????????????????C(i,?j)?=?C(i,?j)?+?A(i,?p)?*?B(p,?j);
????????????}
????????}
????}
}
然后,上篇文章如何判斷算法是否有可優(yōu)化空間?已經(jīng)測(cè)了這段代碼在單核A53(上篇文章錯(cuò)寫(xiě)為A17,十分抱歉)上的gflops表現(xiàn),這種實(shí)現(xiàn)的gflops只有硬件的2%-3%,是十分低效的,因此這篇文章就是基于https://github.com/flame/how-to-optimize-gemm這個(gè)工程,給大家介紹一下矩陣乘法有哪些可以優(yōu)化的方法。
需要注意的是,這個(gè)工程是針對(duì)X86上的列主序程序,我這里主要是在移動(dòng)端A53上進(jìn)行測(cè)試,所以將代碼對(duì)應(yīng)修改成了arm指令集,并且修改為更加常見(jiàn)的行主序進(jìn)行測(cè)試。
原始版本的gFlops測(cè)試結(jié)果如下圖所示:
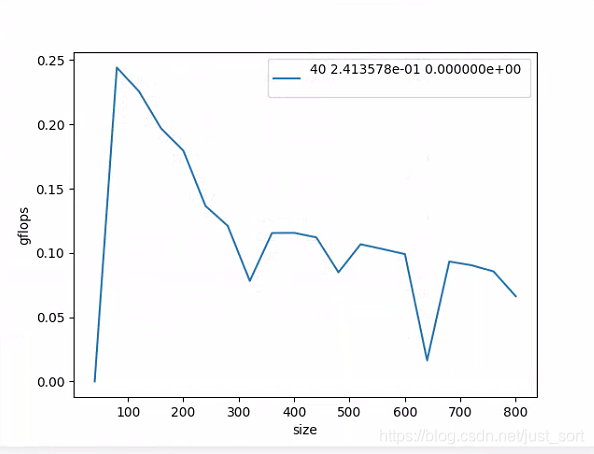
2. 優(yōu)化之前的工作
在談到優(yōu)化之前,我們需要將前言中的那部分代碼改成https://github.com/flame/how-to-optimize-gemm中類似的風(fēng)格,這樣便于對(duì)后面各種優(yōu)化技巧代碼的理解。改寫(xiě)風(fēng)格后的代碼如下:
#include?
#define?A(?i,?j?)?a[?(i)*lda?+?(j)?]
#define?B(?i,?j?)?b[?(i)*ldb?+?(j)?]
#define?C(?i,?j?)?c[?(i)*ldc?+?(j)?]
/*?Routine?for?computing?C?=?A?*?B?+?C?*/
/*?Create?macro?to?let?X(?i?)?equal?the?ith?element?of?x?*/
#define?Y(i)?y[?(i)*incx?]
void?AddDot(?int?k,?float?*x,?int?incx,??float?*y,?float?*gamma?)
{
??/*?compute?gamma?:=?x'?*?y?+?gamma?with?vectors?x?and?y?of?length?n.
?????Here?x?starts?at?location?x?with?increment?(stride)?incx?and?y?starts?at?location?y?and?has?(implicit)?stride?of?1.
??*/
?
??int?p;
??for?(?p=0;?p????*gamma?+=?x[p]?*?Y(p);?????
??}
}
void?MY_MMult1(?int?m,?int?n,?int?k,?float?*a,?int?lda,?
????????????????????????????????????float?*b,?int?ldb,
????????????????????????????????????float?*c,?int?ldc?)
{
??int?i,?j;
??for?(?j=0;?j1?){????????/*?Loop?over?the?columns?of?C?*/
????for?(?i=0;?i1?){????????/*?Loop?over?the?rows?of?C?*/
??????/*?Update?the?C(?i,j?)?with?the?inner?product?of?the?ith?row?of?A
??and?the?jth?column?of?B?*/
????//?for?(int?p=0;?p
????//?????????????C(i,?j)?=?C(i,?j)?+?A(i,?p)?*?B(p,?j);
????//?????????}
??????AddDot(?k,?&A(?i,0?),?lda,?&B(?0,j?),?&C(?i,j?)?);
????}
??}
}
考慮到排版和篇幅的原因,后面的優(yōu)化部分只貼最核心的代碼,完整代碼請(qǐng)到https://github.com/BBuf/ArmNeonOptimization查看,也歡迎Star這本項(xiàng)目。
3. 內(nèi)存對(duì)齊
這里設(shè)計(jì)到Cache的概念,我嘗試簡(jiǎn)短的描述一下,為什么內(nèi)存對(duì)齊是對(duì)Cache命中有好處的。注意,內(nèi)存對(duì)齊的原則是:任何K字節(jié)的基本對(duì)象的地址必須都是K的倍數(shù)。
Cache,譯為高速緩沖存儲(chǔ)器,它可以更好的利用局部性原理,減少CPU訪問(wèn)主存的次數(shù)。這里需要再簡(jiǎn)單描述一下計(jì)算機(jī)的存儲(chǔ)體系,在當(dāng)代計(jì)算中存儲(chǔ)器是分為不同層次的,越靠近CPU的存儲(chǔ)器速度越快,制造成本也就越高,同時(shí)容量也越小。最靠近CPU的存儲(chǔ)器是寄存器,它的制造成本最高,所以個(gè)數(shù)也很有限。第二靠近的是緩存(Cache),同時(shí)緩存也是有分級(jí)的,有L1,L2,L3...等多個(gè)級(jí)別。再然后就是主存,即普通的內(nèi)存。最后是本地磁盤(pán)。它們的容量以及訪問(wèn)時(shí)間如下圖所示:
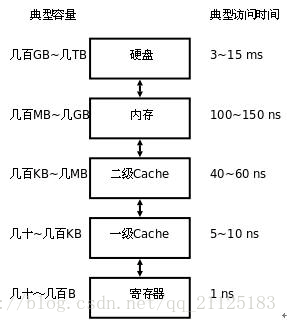
上面說(shuō)Cache可以更好的利用局部性原理,所謂局部性原理就是優(yōu)先從留CPU近的存儲(chǔ)結(jié)構(gòu)中去尋找當(dāng)前需要查找的數(shù)據(jù),加快數(shù)據(jù)訪問(wèn)速度從而減少程序中各個(gè)變量的存取時(shí)間。
關(guān)于Cache更多的概念可以參考一下文末的資料1,寫(xiě)得非常好。
“假設(shè) cache line 為 32B。待訪問(wèn)數(shù)據(jù)大小為 64B,地址在 0x80000001,則需要占用 3 條 cache 映射表項(xiàng);若地址在 0x80000000 則只需要 2 條。內(nèi)存對(duì)齊變相地提高了 cache 命中率。” 假定kernel一次計(jì)算執(zhí)行 大小的block, 根據(jù)MMult_4x4_7.c (https://github.com/flame/how-to-optimize-gemm/blob/master/src/MMult_4x4_7.c)和 MMult_4x4_8.c (https://github.com/flame/how-to-optimize-gemm/blob/master/src/MMult_4x4_8.c)代碼,可以看出MMult_4x4_8.c使用了偏移量完成內(nèi)存對(duì)齊。
這樣我們就可以參考工程的MMult_1x4_3.c改寫(xiě)出一個(gè)FLOPs還不錯(cuò)的分塊的矩陣乘法,代碼實(shí)現(xiàn)如下,為了縮短代碼長(zhǎng)度,隱去了注釋,如果有什么疑問(wèn)歡迎留言區(qū)討論:
void?AddDot1x4(?int?k,?float?*a,?int?lda,??float?*b,?int?ldb,?float?*c,?int?ldc?)
{
??int?p;
??register?float??c_00_reg,???c_01_reg,???c_02_reg,???c_03_reg,?b_0p_reg;
??float??*ap0_pntr,?*ap1_pntr,?*ap2_pntr,?*ap3_pntr;?
????
??ap0_pntr?=?&A(?0,?0?);
??ap1_pntr?=?&A(?1,?0?);
??ap2_pntr?=?&A(?2,?0?);
??ap3_pntr?=?&A(?3,?0?);
??c_00_reg?=?0.0;?
??c_01_reg?=?0.0;?
??c_02_reg?=?0.0;?
??c_03_reg?=?0.0;
?
??for?(?p=0;?p4?){
????b_0p_reg?=?B(?p,?0?);
????c_00_reg?+=?b_0p_reg?*?*ap0_pntr++;
????c_01_reg?+=?b_0p_reg?*?*ap1_pntr++;
????c_02_reg?+=?b_0p_reg?*?*ap2_pntr++;
????c_03_reg?+=?b_0p_reg?*?*ap3_pntr++;
????b_0p_reg?=?B(?p+1,?0?);
????c_00_reg?+=?b_0p_reg?*?*ap0_pntr++;
????c_01_reg?+=?b_0p_reg?*?*ap1_pntr++;
????c_02_reg?+=?b_0p_reg?*?*ap2_pntr++;
????c_03_reg?+=?b_0p_reg?*?*ap3_pntr++;
????b_0p_reg?=?B(?p+2,?0?);
????c_00_reg?+=?b_0p_reg?*?*ap0_pntr++;
????c_01_reg?+=?b_0p_reg?*?*ap1_pntr++;
????c_02_reg?+=?b_0p_reg?*?*ap2_pntr++;
????c_03_reg?+=?b_0p_reg?*?*ap3_pntr++;
????b_0p_reg?=?B(?p+3,?0?);
????c_00_reg?+=?b_0p_reg?*?*ap0_pntr++;
????c_01_reg?+=?b_0p_reg?*?*ap1_pntr++;
????c_02_reg?+=?b_0p_reg?*?*ap2_pntr++;
????c_03_reg?+=?b_0p_reg?*?*ap3_pntr++;
??}
??C(?0,?0?)?+=?c_00_reg;?
??C(?1,?0?)?+=?c_01_reg;?
??C(?2,?0?)?+=?c_02_reg;?
??C(?3,?0?)?+=?c_03_reg;
}
void?MY_MMult_1x4_8(?int?m,?int?n,?int?k,?float?*a,?int?lda,?
????????????????????????????????????float?*b,?int?ldb,
????????????????????????????????????float?*c,?int?ldc?)
{
??int?i,?j;
??for?(?j=0;?j1?){??????
????for?(?i=0;?i4?){????
??????AddDot1x4(?k,?&A(?i,0?),?lda,?&B(?0,j?),?ldb,?&C(?i,j?),?ldc?);
????}
??}
}
那么這個(gè)版本的gflops效果如何呢?單核A53測(cè)試結(jié)果如下:

可以看到最高的浮點(diǎn)峰值是原始版本的4倍,說(shuō)明上面的優(yōu)化是行之有效的。
接下來(lái),我們將分塊的策略從擴(kuò)展到,代碼實(shí)現(xiàn)如下:
void?AddDot4x4(?int?k,?float?*a,?int?lda,??float?*b,?int?ldb,?float?*c,?int?ldc?)
{
??int?p;
??register?float?
???????c_00_reg,???c_01_reg,???c_02_reg,???c_03_reg,??
???????c_10_reg,???c_11_reg,???c_12_reg,???c_13_reg,??
???????c_20_reg,???c_21_reg,???c_22_reg,???c_23_reg,??
???????c_30_reg,???c_31_reg,???c_32_reg,???c_33_reg,
???????a_0p_reg,
???????a_1p_reg,
???????a_2p_reg,
???????a_3p_reg,
???????b_p0_reg,
???????b_p1_reg,
???????b_p2_reg,
???????b_p3_reg;
??float?
????/*?Point?to?the?current?elements?in?the?four?rows?of?A?*/
????*a_0p_pntr,?*a_1p_pntr,?*a_2p_pntr,?*a_3p_pntr;
??
??a_0p_pntr?=?&A(?0,?0);
??a_1p_pntr?=?&A(?1,?0);
??a_2p_pntr?=?&A(?2,?0);
??a_3p_pntr?=?&A(?3,?0);
??c_00_reg?=?0.0;???c_01_reg?=?0.0;???c_02_reg?=?0.0;???c_03_reg?=?0.0;
??c_10_reg?=?0.0;???c_11_reg?=?0.0;???c_12_reg?=?0.0;???c_13_reg?=?0.0;
??c_20_reg?=?0.0;???c_21_reg?=?0.0;???c_22_reg?=?0.0;???c_23_reg?=?0.0;
??c_30_reg?=?0.0;???c_31_reg?=?0.0;???c_32_reg?=?0.0;???c_33_reg?=?0.0;
??for?(?p=0;?p????a_0p_reg?=?*a_0p_pntr++;
????a_1p_reg?=?*a_1p_pntr++;
????a_2p_reg?=?*a_2p_pntr++;
????a_3p_reg?=?*a_3p_pntr++;
????b_p0_reg?=?B(?p,?0);
????b_p1_reg?=?B(?p,?1);
????b_p2_reg?=?B(?p,?2);
????b_p3_reg?=?B(?p,?3);
????/*?First?row?*/
????c_00_reg?+=?a_0p_reg?*?b_p0_reg;
????c_01_reg?+=?a_0p_reg?*?b_p1_reg;
????c_02_reg?+=?a_0p_reg?*?b_p2_reg;
????c_03_reg?+=?a_0p_reg?*?b_p3_reg;
????/*?Second?row?*/
????c_10_reg?+=?a_1p_reg?*?b_p0_reg;
????c_11_reg?+=?a_1p_reg?*?b_p1_reg;
????c_12_reg?+=?a_1p_reg?*?b_p2_reg;
????c_13_reg?+=?a_1p_reg?*?b_p3_reg;
????/*?Third?row?*/
????c_20_reg?+=?a_2p_reg?*?b_p0_reg;
????c_21_reg?+=?a_2p_reg?*?b_p1_reg;
????c_22_reg?+=?a_2p_reg?*?b_p2_reg;
????c_23_reg?+=?a_2p_reg?*?b_p3_reg;
????/*?Four?row?*/
????c_30_reg?+=?a_3p_reg?*?b_p0_reg;
????c_31_reg?+=?a_3p_reg?*?b_p1_reg;
????c_32_reg?+=?a_3p_reg?*?b_p2_reg;
????c_33_reg?+=?a_3p_reg?*?b_p3_reg;
??}
??C(?0,?0?)?+=?c_00_reg;???C(?0,?1?)?+=?c_01_reg;???C(?0,?2?)?+=?c_02_reg;???C(?0,?3?)?+=?c_03_reg;
??C(?1,?0?)?+=?c_10_reg;???C(?1,?1?)?+=?c_11_reg;???C(?1,?2?)?+=?c_12_reg;???C(?1,?3?)?+=?c_13_reg;
??C(?2,?0?)?+=?c_20_reg;???C(?2,?1?)?+=?c_21_reg;???C(?2,?2?)?+=?c_22_reg;???C(?2,?3?)?+=?c_23_reg;
??C(?3,?0?)?+=?c_30_reg;???C(?3,?1?)?+=?c_31_reg;???C(?3,?2?)?+=?c_32_reg;???C(?3,?3?)?+=?c_33_reg;
}
然后再測(cè)一下gflops的表現(xiàn):
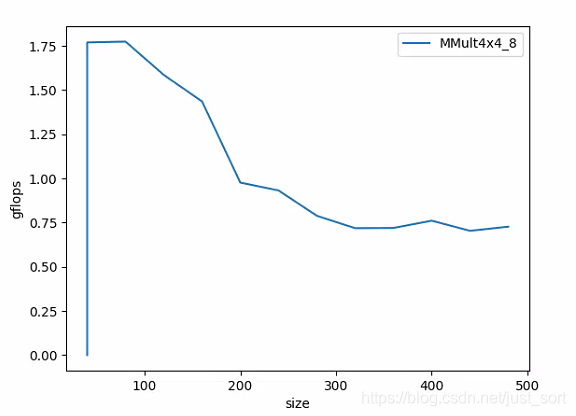
現(xiàn)在gflops提升到了1.75gflops,性能看起來(lái)好了不少,但是仍然存在隨著矩陣尺寸快速變大性能衰減的問(wèn)題,這個(gè)問(wèn)題請(qǐng)看第六節(jié)。
4. 向量化SIMD
一個(gè)比較顯然的優(yōu)化是在k維度計(jì)算的時(shí)候可以使用Neon指令集進(jìn)行優(yōu)化,由于之前這個(gè)專欄中的文章已經(jīng)講得非常多了,這里不再贅述,貼一下在MMult_4x4_8版本基礎(chǔ)上的核心修改部分:
void?AddDot4x4(?int?k,?float?*a,?int?lda,??float?*b,?int?ldb,?float?*c,?int?ldc?)
{
??float?
????*a_0p_pntr,?*a_1p_pntr,?*a_2p_pntr,?*a_3p_pntr;
??a_0p_pntr?=?&A(0,?0);
??a_1p_pntr?=?&A(1,?0);
??a_2p_pntr?=?&A(2,?0);
??a_3p_pntr?=?&A(3,?0);
??float32x4_t?c_p0_sum?=?{0};
??float32x4_t?c_p1_sum?=?{0};
??float32x4_t?c_p2_sum?=?{0};
??float32x4_t?c_p3_sum?=?{0};
??register?float
????a_0p_reg,
????a_1p_reg,???
????a_2p_reg,
????a_3p_reg;
??for?(int?p?=?0;?p?????float32x4_t?b_reg?=?vld1q_f32(&B(p,?0));
????a_0p_reg?=?*a_0p_pntr++;
????a_1p_reg?=?*a_1p_pntr++;
????a_2p_reg?=?*a_2p_pntr++;
????a_3p_reg?=?*a_3p_pntr++;
????c_p0_sum?=?vmlaq_n_f32(c_p0_sum,?b_reg,?a_0p_reg);
????c_p1_sum?=?vmlaq_n_f32(c_p1_sum,?b_reg,?a_1p_reg);
????c_p2_sum?=?vmlaq_n_f32(c_p2_sum,?b_reg,?a_2p_reg);
????c_p3_sum?=?vmlaq_n_f32(c_p3_sum,?b_reg,?a_3p_reg);
??}
??float?*c_pntr?=?0;
??c_pntr?=?&C(0,?0);
??float32x4_t?c_reg?=?vld1q_f32(c_pntr);
??c_reg?=?vaddq_f32(c_reg,?c_p0_sum);
??vst1q_f32(c_pntr,?c_reg);
??c_pntr?=?&C(1,?0);
??c_reg?=?vld1q_f32(c_pntr);
??c_reg?=?vaddq_f32(c_reg,?c_p1_sum);
??vst1q_f32(c_pntr,?c_reg);
??c_pntr?=?&C(2,?0);
??c_reg?=?vld1q_f32(c_pntr);
??c_reg?=?vaddq_f32(c_reg,?c_p2_sum);
??vst1q_f32(c_pntr,?c_reg);
??c_pntr?=?&C(3,?0);
??c_reg?=?vld1q_f32(c_pntr);
??c_reg?=?vaddq_f32(c_reg,?c_p3_sum);
??vst1q_f32(c_pntr,?c_reg);
}
經(jīng)過(guò)這個(gè)優(yōu)化我們?cè)贉y(cè)試一下當(dāng)前版本(MMult_4x4_10)的gflops表現(xiàn):

在矩陣長(zhǎng)寬小于200時(shí)是有明顯提升的,且最高的浮點(diǎn)峰值提升到了2.5gflops,說(shuō)明這個(gè)優(yōu)化在矩陣規(guī)模不大時(shí)是比較有用的。
5. 為什么需要分塊&以及什么是分塊?
前面的兩個(gè)關(guān)鍵的優(yōu)化在矩陣規(guī)模變大之后gflops就快速衰減,這是為什么呢?

這就和第3節(jié)講到的計(jì)算機(jī)存儲(chǔ)體系結(jié)構(gòu)有關(guān)了,如Fig6所示。當(dāng)我們的AB矩陣的大小比L2 Cache小時(shí),我們的程序只需要從RAM中讀取一次AB大小的內(nèi)存,然后A,B矩陣的數(shù)據(jù)都可以被塞進(jìn)Cache中。但是隨著矩陣的大小增大,當(dāng)AB矩陣的大小超過(guò)了L2 Cache時(shí),由于行主序情況下的B矩陣或者列主序下的A矩陣不是內(nèi)存連續(xù)的,那么程序就要從RAM讀取多次AB矩陣的數(shù)據(jù),這樣數(shù)據(jù)存取將成為整個(gè)程序gflops上升的瓶頸。
因此,為了解決上一問(wèn)題,gemm論文提出了矩陣分塊的做法,直擊核心,這篇論文針對(duì)矩陣乘法主要提出了下面6種不同的分塊計(jì)算方法,如下圖所示:

這個(gè)圖中透漏了兩個(gè)非常重要的點(diǎn)。
第一個(gè)是行主序下的A的一行乘以一列獲得C的元素這個(gè)過(guò)程(A*B=C,其中A矩陣大小為,B矩陣大小為,C矩陣大小為)可以等價(jià)為A 的一列和 B 的一行操作得到 大小的一個(gè) C 的“扇面”,多個(gè)“扇面”疊加就是完整的 C。所以這里的分塊策略指的并不是在原始矩陣的長(zhǎng)寬維度上分段計(jì)算,而是類似于一個(gè)z軸上拆分的思路,比較巧妙,所謂z軸就是垂直于矩陣長(zhǎng)寬的維度。可以參考MMult_4x4_10的代碼進(jìn)行理解。
從MMult_4x4_10的結(jié)果來(lái)看,這個(gè)改進(jìn)后的版本在矩陣規(guī)模變大時(shí)gflops也要好于之前的各個(gè)版本。另外為了驗(yàn)證上面的想法(當(dāng)AB矩陣的大小超過(guò)了L2 Cache時(shí),由于行主序情況下的B矩陣或者列主序下的A矩陣不是內(nèi)存連續(xù)的,那么程序就要從RAM讀取多次AB矩陣的數(shù)據(jù),這樣數(shù)據(jù)存取將成為整個(gè)程序gflops上升的瓶頸),我又做了一個(gè)對(duì)比試驗(yàn),即在上面的z軸分塊的版本下進(jìn)一步對(duì)行列兩個(gè)方向也進(jìn)行分塊,設(shè)置的步長(zhǎng)和how-to-optimize-gemm一致,即:
#define?mc?256?
#define?kc?128
void?InnerKernel(?int?m,?int?n,?int?k,?float?*a,?int?lda,?
???????????????????????????????????????float?*b,?int?ldb,
???????????????????????????????????????float?*c,?int?ldc?)
{
??int?i,?j;
??for?(?j=0;?j4?){????????/*?Loop?over?the?columns?of?C,?unrolled?by?4?*/
????for?(?i=0;?i4?){????????/*?Loop?over?the?rows?of?C?*/
??????/*?Update?C(?i,j?),?C(?i,j+1?),?C(?i,j+2?),?and?C(?i,j+3?)?in
??one?routine?(four?inner?products)?*/
??????AddDot4x4(?k,?&A(?i,0?),?lda,?&B(0,?j),?ldb,?&C(?i,j?),?ldc?);
????}
??}
}
void?MY_MMult_4x4_11(?int?m,?int?n,?int?k,?float?*a,?int?lda,?
????????????????????????????????????float?*b,?int?ldb,
????????????????????????????????????float?*c,?int?ldc?)?
{
??int?i,?p,?pb,?ib;?
??for?(p?=?0;?p?????pb?=?min(k?-?p,?kc);
????for?(i?=?0;?i???????ib?=?min(m?-?i,?mc);
??????InnerKernel(ib,?n,?pb,?&A(i,?p),?lda,?&B(p,?0),?ldb,?&C(i,?0),?ldc);
????}
??}
}
然后我們?cè)贉y(cè)一下這個(gè)版本(MMult_4x4_11)的gflops:

對(duì)比一下4x4_10的結(jié)果可以發(fā)現(xiàn),在矩陣規(guī)模變大時(shí),這個(gè)版本的gflops又好了不少,說(shuō)明分塊的確是利用Cache的一個(gè)好辦法,畢竟Cache的容量是非常有限的。
在Figure4中透漏的第二個(gè)非常重要的點(diǎn)就是數(shù)據(jù)重排,也即數(shù)據(jù)Pack,之前我已經(jīng)講到2次這個(gè)技巧了,在這個(gè)矩陣乘法優(yōu)化中同樣適用。因?yàn)槲覀兎謮K后的AB仍然是內(nèi)存不連續(xù)的,為了提高內(nèi)存的連續(xù)性,在做矩陣乘法之前先對(duì)A,B做了數(shù)據(jù)重排,將第二行要操作的數(shù)放在第一行的末尾,這樣Neon中的數(shù)據(jù)預(yù)取指令將會(huì)生效,極大提高數(shù)據(jù)存取效率。基于這個(gè)想法獲得了改進(jìn)后的版本MMult_4x4_13.c,代碼實(shí)現(xiàn)見(jiàn):https://github.com/BBuf/ArmNeonOptimization/blob/master/optimize_gemm/MMult_4x4_13.h
測(cè)一下gflops:

可以看到相對(duì)于MMult_4x4_11 在矩陣規(guī)模變大時(shí),這個(gè)版本的gflops提升明顯,已經(jīng)不會(huì)比這個(gè)版本的最高浮點(diǎn)峰值低太多了,說(shuō)明這個(gè)優(yōu)化是十分有效果的。
6. 總結(jié)
這篇文章講到的優(yōu)化方法都是有理論支撐的,也就是第5節(jié)展示的gemm論文中的那個(gè)Figure4。gemm論文我打算放到我后面的文章中進(jìn)行解讀,另外會(huì)再分享一些優(yōu)化程度更大的算法,感興趣的請(qǐng)關(guān)注一下我們的公眾號(hào),謝謝。
為了感謝讀者朋友們的長(zhǎng)期支持,我們今天將送出 3 本由北京大學(xué)出版社提供的《Python最優(yōu)化算法實(shí)戰(zhàn)》書(shū)籍,對(duì)本書(shū)感興趣的可以在上方的留言區(qū)留言,我們將抽取其中三位讀者送出一本正版書(shū)籍。

7. 參考
https://blog.csdn.net/qq_21125183/article/details/80590934 https://zhuanlan.zhihu.com/p/65436463 https://www.cs.utexas.edu/users/pingali/CS378/2008sp/papers/gotoPaper.pdf https://github.com/flame/how-to-optimize-gemm https://github.com/tpoisonooo/how-to-optimize-gemm
歡迎關(guān)注GiantPandaCV, 在這里你將看到獨(dú)家的深度學(xué)習(xí)分享,堅(jiān)持原創(chuàng),每天分享我們學(xué)習(xí)到的新鮮知識(shí)。( ? ?ω?? )?
有對(duì)文章相關(guān)的問(wèn)題,或者想要加入交流群,歡迎添加BBuf微信:
為了方便讀者獲取資料以及我們公眾號(hào)的作者發(fā)布一些Github工程的更新,我們成立了一個(gè)QQ群,二維碼如下,感興趣可以加入。