
(附代碼)實(shí)戰(zhàn) | 基于 CNN 的驗(yàn)證碼破解項(xiàng)目
點(diǎn)擊左上方藍(lán)字關(guān)注我們

轉(zhuǎn)載自 | 小白學(xué)視覺(jué)

已有的工作中基于機(jī)器學(xué)習(xí)和深度學(xué)習(xí)都有很多的工作開(kāi)展出來(lái),效果也都不錯(cuò),今天本文的主要內(nèi)容就是基于卷積神經(jīng)網(wǎng)絡(luò)CNN模型來(lái)構(gòu)建驗(yàn)證碼圖片識(shí)別模型。
整體流程示意圖如下圖所示:
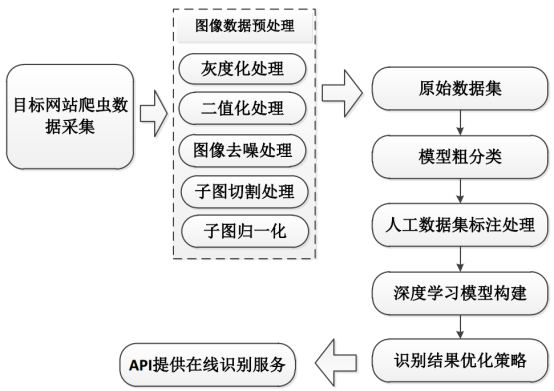
其中,主要的工作分為三個(gè)部分:數(shù)據(jù)采集、數(shù)據(jù)預(yù)處理和模型構(gòu)建與測(cè)試。上述是之前一個(gè)實(shí)際完成的項(xiàng)目流程示意圖,本文主要是實(shí)踐基于CNN來(lái)構(gòu)建識(shí)別模型,對(duì)于數(shù)據(jù)采集和預(yù)處理部分不作為講解的內(nèi)容,感興趣可以親身實(shí)踐一下,都是圖像處理領(lǐng)域內(nèi)的比較基礎(chǔ)的內(nèi)容。
經(jīng)過(guò)處理后我們將原始的驗(yàn)證碼圖片均進(jìn)行了基本的去噪、二值化以及歸一化等處理得到了可用于模型直接訓(xùn)練使用的特征向量數(shù)據(jù),原始的驗(yàn)證碼圖像數(shù)據(jù)如下所示:
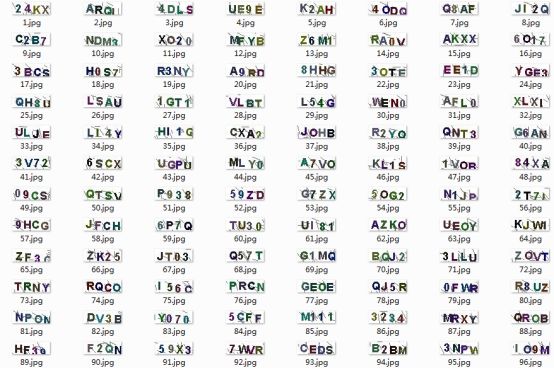
處理后生成的特征向量文件如下所示:
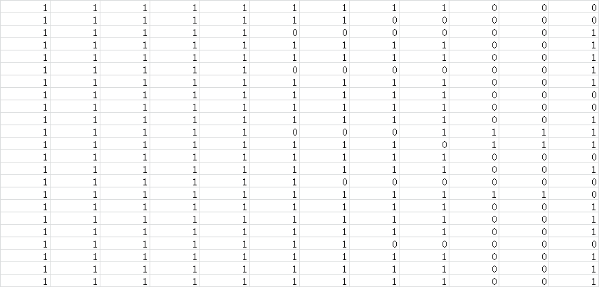
上圖中,每一行表示一個(gè)字符子圖,每一列表示字符子圖的一維數(shù)據(jù),向量的維數(shù)就是經(jīng)過(guò)歸一化處理后的字符子圖【寬x高】的值,即:將二維的矩陣數(shù)據(jù)轉(zhuǎn)化為了一維的向量數(shù)據(jù),這一步不是必須的,只是我這里采用了這種處理方式。
生成得到原始驗(yàn)證碼圖片數(shù)據(jù)的特征向量后就可以搭建訓(xùn)練模型了,具體的代碼實(shí)現(xiàn)如下所示:
keys = ['1','2','3','4','5','6','7','8','9','A','B','C','D','E','F','G','H','J','K','L','N','P','Q','R','S','T','U','V','X','Y','Z']
def trainModel(feature='data.csv',batch_size=128,nepochs=50,ES=False,n_classes=31,model_path='vcModel.h5'):
'''
模型訓(xùn)練
'''
df = pd.read_csv(feature)
vals = range(31)
label_dict = dict(zip(keys, vals))
x_data = df[['v'+str(i+1) for i in range(320)]]
y_data = pd.DataFrame({'label':df['label']})
y_data['class'] = y_data['label'].apply(lambda x: label_dict[x])
#數(shù)據(jù)集劃分
X_train, X_test, Y_train, Y_test = train_test_split(x_data, y_data['class'], test_size=0.3, random_state=42)
x_train = np.array(X_train).reshape((1167, 20, 16, 1))
x_test = np.array(X_test).reshape((501, 20, 16, 1))
# label編碼處理
y_train = np_utils.to_categorical(Y_train, n_classes)
y_val = np_utils.to_categorical(Y_test, n_classes)
input_shape = x_train[0].shape
#CNN模型搭建開(kāi)始 【可以根據(jù)自己的實(shí)際情況進(jìn)行增刪和調(diào)整】
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3), input_shape=input_shape, padding='same'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2), padding='same'))
model.add(Dropout(0.4))
model.add(Conv2D(64, kernel_size=(3, 3), padding='same'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2), padding='same'))
model.add(Dropout(0.4))
model.add(Conv2D(128, kernel_size=(3, 3), padding='same'))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2), padding='same'))
model.add(Dropout(0.4))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(128, activation='relu'))
model.add(Dense(n_classes, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
plot_model(model, to_file='vcModel.png', show_shapes=True)
if ES:
callbacks = [EarlyStopping(monitor='val_acc', patience=10, verbose=1)] #提前終止策略
history = model.fit(x_train, y_train, batch_size=batch_size, epochs=nepochs, \
verbose=1, validation_data=(x_test, y_val), callbacks=callbacks)
else:
history = model.fit(x_train, y_train, batch_size=batch_size, epochs=nepochs, verbose=1, validation_data=(x_test, y_val))
model.save(model_path)
#模型準(zhǔn)確度、損失函數(shù)曲線繪制
plt.clf()
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('Model Accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epochs')
plt.legend(['train','test'], loc='upper left')
plt.savefig('train_validation_acc.png')
plt.clf()
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model Loss')
plt.ylabel('Loss')
plt.xlabel('Epochs')
plt.legend(['train', 'test'], loc='upper left')
plt.savefig('train_validation_loss.png')
if __name__=='__main__':
trainModel(feature='data.csv',batch_size=128,nepochs=100,ES=False,n_classes=31,model_path='vcModel.h5')
默認(rèn)設(shè)置了100次的迭代,不開(kāi)啟提前終止策略,訓(xùn)練完成后截圖如下所示:
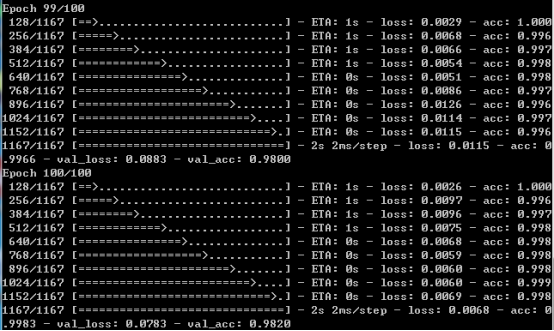
訓(xùn)練完成后就得到了離線的識(shí)別模型文件,可重復(fù)加載使用,我們?cè)谟?xùn)練結(jié)束后繪制了模型的準(zhǔn)確度和損失值對(duì)比曲線,如下所示:
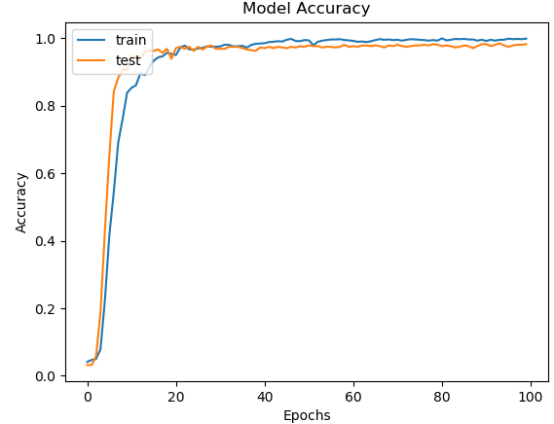
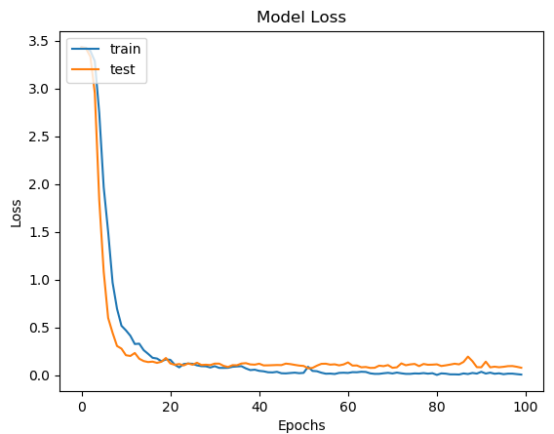
從準(zhǔn)確度和損失值對(duì)比曲線綜合來(lái)看可以發(fā)現(xiàn):模型在20次迭代計(jì)算后就趨近于平穩(wěn),之后保持一個(gè)比較穩(wěn)定的狀態(tài)。
之后對(duì)模型的識(shí)別能力進(jìn)行測(cè)試分析,測(cè)試代碼實(shí)現(xiàn)如下:
def predict(pic_path,pdir='test_verifycode/chars/',saveDir='test_verifycode/predict/'):
'''
預(yù)測(cè)識(shí)別
'''
pic_list = os.listdir(pdir)
if pic_list:
for File in pic_list:
os.remove(pdir+ File)
splitImage(pic_path)
pic_list = os.listdir(pdir)
if pic_list:
for File in pic_list:
remove_edge_picture(pdir+ File)
for File in os.listdir(pdir):
resplit(pdir+ File)
for File in os.listdir(pdir):
picConvert(pdir, File)
pic_list = sorted(os.listdir(pdir), key=lambda x: x[0])
table = np.array([loadImage(pdir, File) for File in pic_list]).reshape(-1,20,16,1)
cnn = load_model('vcModel.h5')
y_pred = cnn.predict(table)
predictions = np.argmax(y_pred, axis=1)
keys = range(31)
vals = ['1', '2', '3', '4', '5', '6', '7', '8', '9', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'J', 'K', 'L', 'N', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'X', 'Y', 'Z']
label_dict = dict(zip(keys, vals))
predict_label=''.join([label_dict[pred] for pred in predictions])
moveFile(pdir,saveDir+predict_label+'/')
return predict_label
def mainFunc(picDir='VerifyCode/'):
'''
主模塊
'''
count=0
pic_list=os.listdir(picDir)
total=len(pic_list)
for one_pic in pic_list:
true_label=one_pic.split('.')[0].strip()
one_pic_path=picDir+one_pic
predict_label=predict(one_pic_path)
print('True Label: {0}, Predict Label: {1}.'.format(true_label,predict_label))
if true_label==predict_label:
count+=1
print('Accuracy: ',count/total)
測(cè)試結(jié)果截圖如下所示:
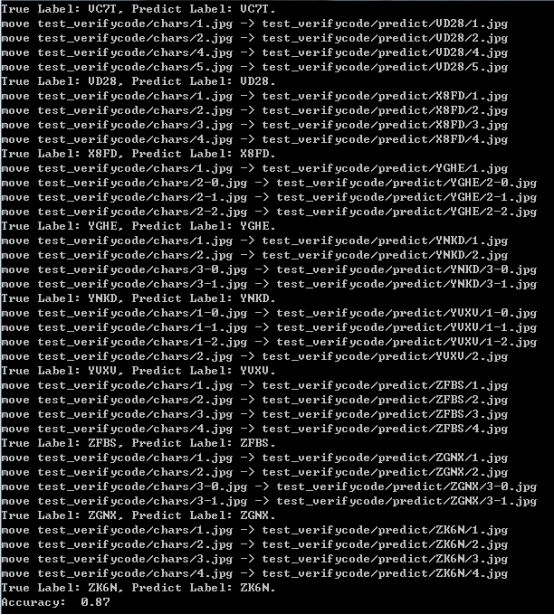
使用了200張的驗(yàn)證碼測(cè)試集來(lái)測(cè)試模型的識(shí)別能力,最終的準(zhǔn)確度為87%,感覺(jué)還是不錯(cuò)的,畢竟我只使用了不到2000的訓(xùn)練數(shù)據(jù)來(lái)訓(xùn)練CNN模型。
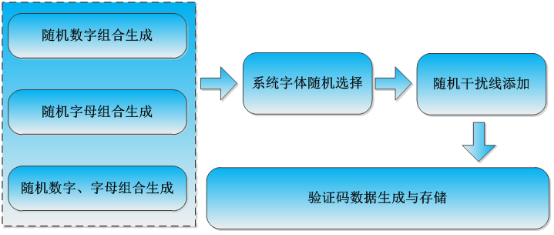
如果有數(shù)據(jù)集需求的可以聯(lián)系我,或者是去隨機(jī)生成一些驗(yàn)證碼數(shù)據(jù)集也是可以的,一個(gè)簡(jiǎn)單的驗(yàn)證碼數(shù)據(jù)集生成流程如下所示:
到這里本文的工作就結(jié)束了,很高興在自己溫習(xí)回顧知識(shí)的同時(shí)能寫下點(diǎn)分享的東西出來(lái),如果說(shuō)您覺(jué)得我的內(nèi)容還可以或者是對(duì)您有所啟發(fā)、幫助,還希望得到您的鼓勵(lì)支持,謝謝!
END
整理不易,點(diǎn)贊三連↓