Youtube的value-based強化學習推薦系統(tǒng)
| 研究方向:推薦系統(tǒng)、強化學習
本文介紹Youtube在2019年放出的兩篇強化學習推薦系統(tǒng)中基于value-based的一篇,論文標題:SLATEQ: A Tractable Decomposition for Reinforcement Learning with Recommendation Sets (IJCAI 2019)

原文地址:
https://arxiv.org/pdf/1905.12767.pdf
https://www.ijcai.org/Proceedings/2019/0360.pdf
強化學習推薦系統(tǒng)快速入門
強化學習算法可以大體分為value-based和policy-based,value-based方法在訓練階段的學習目標是學到一個函數(shù),知道當前狀態(tài)和動作之后,這個函數(shù)可以輸出狀態(tài)下這個動作所能帶來的期望的長期價值,記為Q值,或者狀態(tài)動作值函數(shù);在決策階段,在一個新的狀態(tài)下,我們可以根據(jù)訓練好的函數(shù),嘗試可選動作集合中的每一個動作,最終采取Q值最大的動作,這樣就可以帶來最大的長期收益。本文主要討論value-based的強化學習推薦系統(tǒng)。
上面的介紹中涉及到的強化學習中的主要元素及其在推薦系統(tǒng)中的對應部分:
動作(action):推薦內(nèi)容,如抖音中的一條視頻,或淘寶中的一個商品頁(包含多個物品) 獎勵(reward):用戶的即時反饋,如用戶是否點擊,或者瀏覽時間 狀態(tài)(state):強化學習推薦系統(tǒng)的agent的狀態(tài)是對環(huán)境以及自身所處情況的刻畫,可以簡單理解為用戶歷史行為日志
論文要點
強化學習的推薦系統(tǒng)主要優(yōu)勢在于可以考慮長期收益,如用戶的長期參與度。但是在一些需要推薦多個物品的場景下,例如youtube的網(wǎng)站首頁,會一次放出幾十個視頻,此時模型需要考慮不同視頻的組合,而一個物品的排列組合就是一個動作,這時待選動作的數(shù)目就會十分巨大。而Youtube的這篇論文主要考慮如何對原始的value-based方法的Q函數(shù)進行分解,來更好的處理這種一個動作就是一個物品組合的推薦場景。在實驗階段,youtube考慮使用離線的模擬實驗(訓練用戶模擬器)和youtube的在線實驗,發(fā)現(xiàn)用戶參與度相對于傳統(tǒng)的短期推薦系統(tǒng)有明顯增益。
問題分析
在動作空間中,包含k個物品的推薦列表就有種可能,這個運算符在youtube這種k值一般在幾十(剛才去數(shù)了一下,首頁50+)的網(wǎng)站就很離譜,更不要提前面的了。
動作空間這么大,就會帶來一些問題:
很難進行充分的探索;另外,如果想要在大量的推薦列表之間進行泛化,就需要有這些推薦列表的稠密表示,但是很多列表并不會在現(xiàn)實中出現(xiàn),我們并不知道這些沒出現(xiàn)過的列表會得到怎樣的獎勵,也就是說,我們沒有關于這些列表的轉移元組。 如何找到Q最大的物品組合,這是一個組合優(yōu)化問題。如果不另加結構性的假設或近似,這個問題會難以求解,無法滿足線上服務時延要求。
解決方案
為此,文中提出了兩個關鍵假設,基于這兩個假設,就可以把Q值分解為兩部分:item-wise的Q值部分,和關于所有item的整體Q值部分,從而降低求解最優(yōu)推薦列表的時間復雜度。兩個假設分別是:
Single choice(SC): 即假設用戶每次只選擇一個物品,或者不選擇。 Reward/transition dependence on selection (RTDS): 獎勵和狀態(tài)的轉移只依賴于用戶選擇的物品。
直觀上兩個假設看起來都比較符合直覺,沒有對現(xiàn)實場景做太大的簡化。
基于RTDS假設,獎勵的分布和狀態(tài)的轉移分布就可表示為:
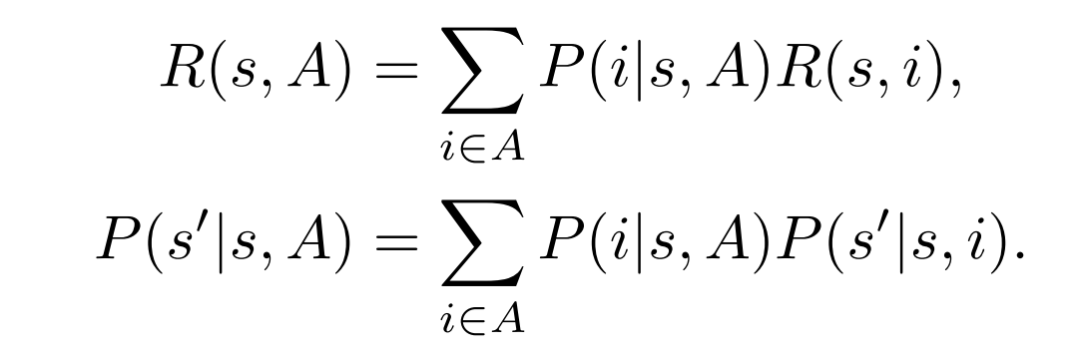
進一步就可以定義出item-wise的Q函數(shù):
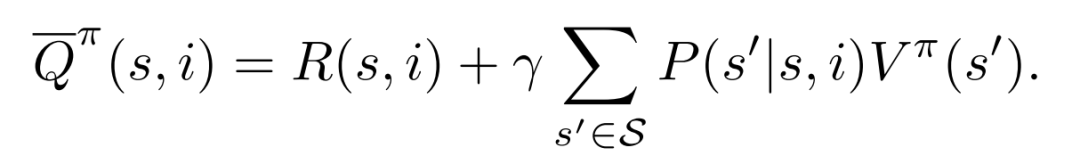
如果用item-wise的Q函數(shù)來表示,就得到了:
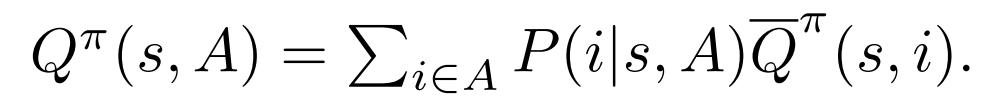
推導過程用到了SC與RTDS假設,主要是從11式到12式的推導需要用這兩個假設:
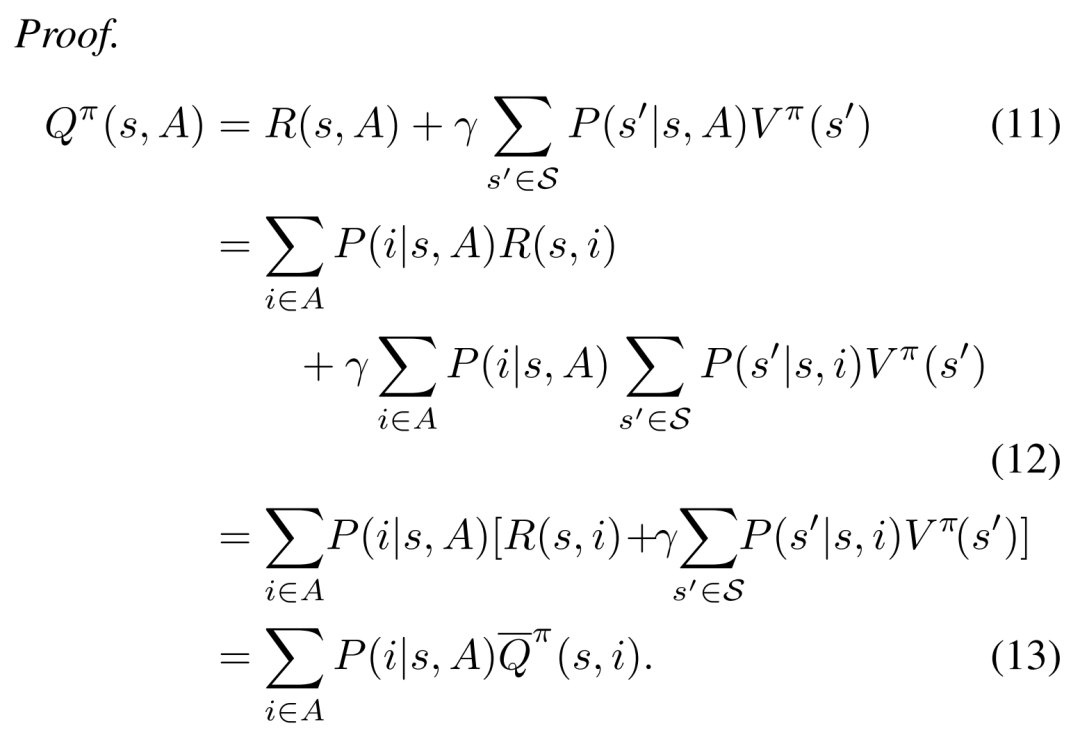
看了這個推導,給人的感覺就是作者在思考問題并寫這些11式的公式時發(fā)現(xiàn)時間復雜度太大,然后順其自然的想到了這兩條假設。
最終的結果只依賴于,其中的只是一個物品而已,而非一個組合,用傳統(tǒng)的TD error就可以訓練出;最終結果還包括,也就是預測狀態(tài)下,給定列表用戶選擇各個物品的概率,這就是一個pctr預測問題了,有很多成熟的解決方案。
在訓練時,為了得到最優(yōu)的策略,我們也要訓練最優(yōu)策略對應的Q函數(shù),而這只需要在訓練過程中,依據(jù)Q最大的就是最好的的準則,來貪心的選擇即可。
最終的長期收益優(yōu)化目標:
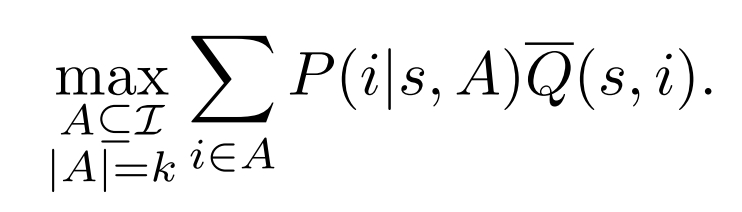
最終這樣一個優(yōu)化目標可以被看做一個分數(shù)線性規(guī)劃問題,并且可以在多項式時間內(nèi)解決:
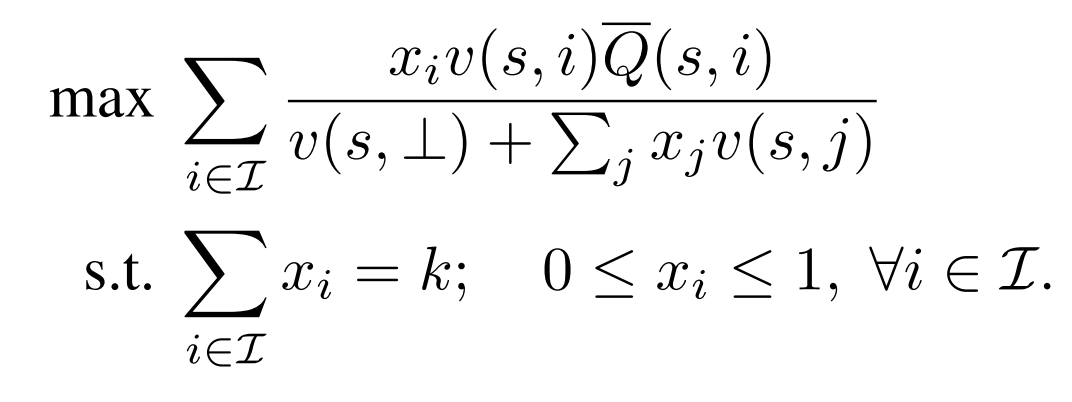
這里代表用戶對一個物品的未正則化的點擊概率。
雖然這里物品的集合數(shù)目巨大,但是現(xiàn)實中這里的物品集合應該是粗排并且被一些產(chǎn)品策略過濾之后的結果,因此數(shù)目會比總物品數(shù)少很多。關于優(yōu)化問題的簡化過程,細節(jié)請參考原文。
在線上服務時,為了避免每次請求都有接一個多項式時間復雜度的線性規(guī)劃問題,文章還提出了兩種近似的方法:
Top-K: 計算每個物品的期望獎勵,選擇倒序排序最大的k個作為最終的推薦列表。在選擇物品列表的第L個物品并需要計算物品獎勵時,不會考慮前L-1個物品。 Greedy: 考慮物品列表的第L個時,考慮其邊際收益,邊際收益會考慮前L-1個物品計算得到:
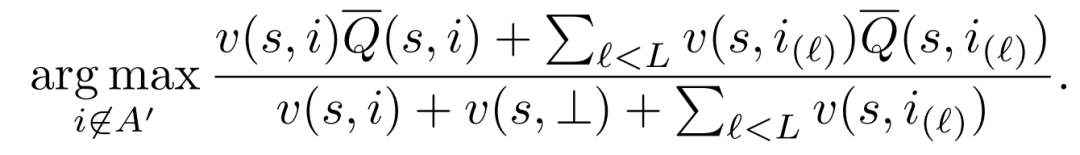
實驗效果
實驗包括兩部分,離線部分與在線部分:離線部分構建了一個用戶模擬器來模擬用戶行為,在線部分是在youtube網(wǎng)站上線來取得效果的。用戶模擬器是根據(jù)用戶的歷史行為數(shù)據(jù)通過簡單訓練的方式訓練方式得到的,此前也介紹過一篇類似的文章,這里不再過多介紹。
離線實驗
這里對比了隨機模型,近視模型(MYOP,把獎勵的折扣因子設置為0,這樣模型就不會考慮長期獎勵),SARSA以及Q-Learning在訓練階段就使用不同的決策方式,和使用不同的線上服務方式(第一個字母,T: top-K; G: greedy; O: Optimal; 第二個字母,T: traing; S: serving)的對比實驗:
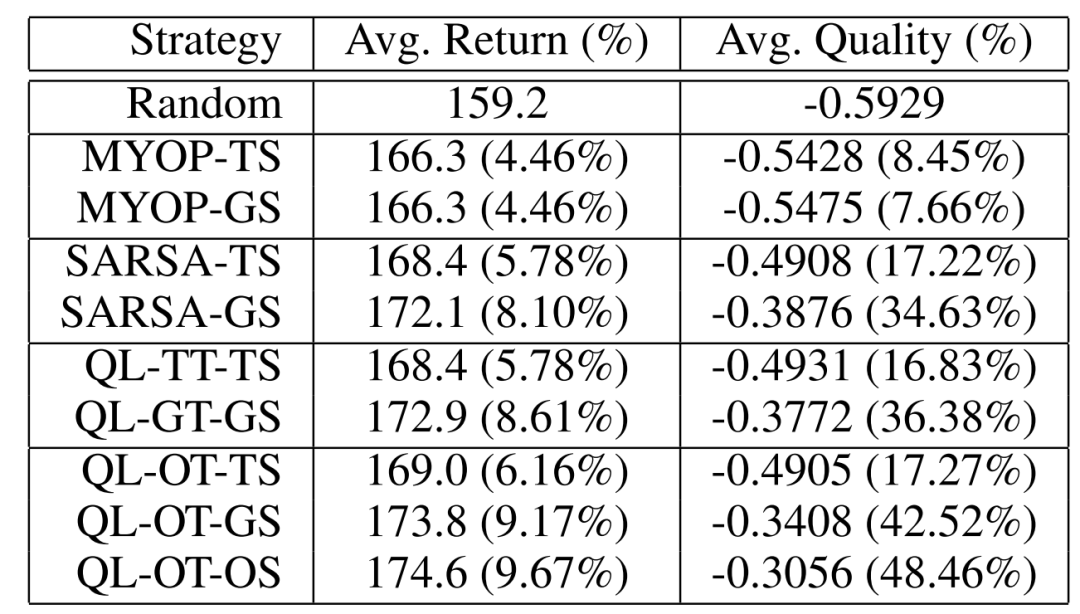
可以看到,greedy的線上服務方式相比于優(yōu)化的方式,性能損失不大;而top-k的方式損失很大。
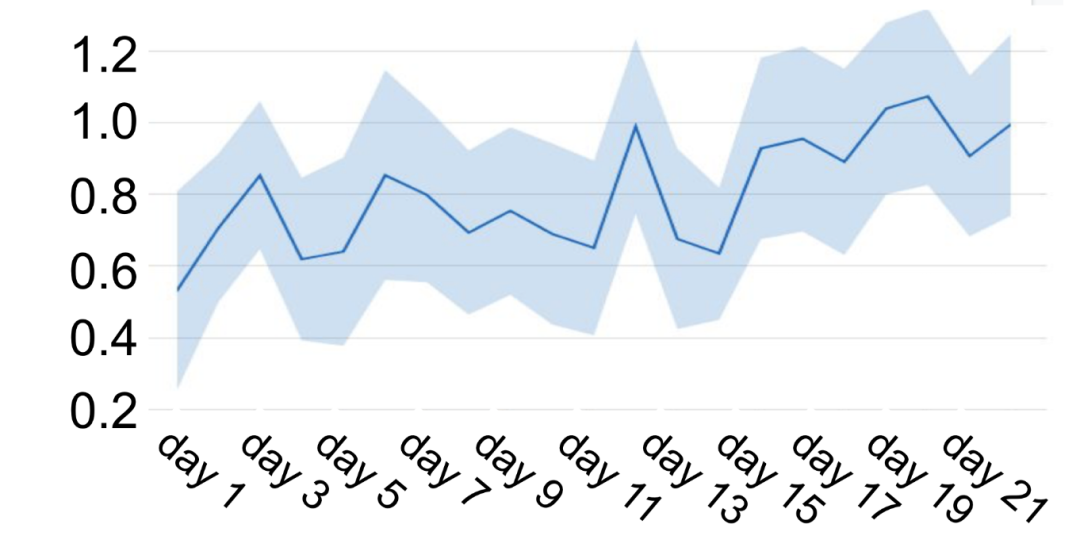
在線實驗
對比的指標是用戶參與度,baseline是youtube當前的監(jiān)督模型,可以看到性能提升還是十分顯著的,也證明了強化學習在推薦系統(tǒng)上落地是可以帶來收益的: