大家下午好,我是來自阿里云可觀測團(tuán)隊(duì)的算法工程師陳昆儀。今天分享的主題是“和我交談并獲得您想要的PromQL”。今天我跟大家分享在將AIGC技術(shù)運(yùn)用到可觀測領(lǐng)域的探索。
-
為什么我們需要一個(gè)自然語言翻譯PromQL的機(jī)器人;
-
-
Demo及相關(guān)數(shù)據(jù)成果的展示;
-
-
為什么我們需要一個(gè)
自然語言翻譯 PromQL 的機(jī)器人?
先說說PromQL是什么,PromQL就是Prometheus的時(shí)序數(shù)據(jù)庫的專屬查詢語句。Prometheus是云原生領(lǐng)域數(shù)據(jù)存儲和查詢的“事實(shí)標(biāo)準(zhǔn)”(De facto standard,我也是第一次看到這個(gè)詞,“De facto ”居然還是拉丁文)。“事實(shí)標(biāo)準(zhǔn)”的意思就是“幾乎所有”。從K8s應(yīng)用中采集上來的指標(biāo)數(shù)據(jù)都會被存在Prometheus這種時(shí)序數(shù)據(jù)庫里,所有查詢、分析工作也是在Prometheus上執(zhí)行的。簡而言之,PromQL幾乎是所有K8s應(yīng)用的運(yùn)維工程師最經(jīng)常使用的查詢語句,沒有之一。
現(xiàn)在我們知道什么是PromQL了,所以為什么我們需要一個(gè)自然查詢語句轉(zhuǎn)PromQL的機(jī)器人。我們把這個(gè)答案概括成3個(gè)"C":
1. 第一個(gè)“C”是“Complex”,"Complex syntax"。
PromQL的語法其實(shí)是比較復(fù)雜的,其實(shí)讓它難學(xué)的根本在于它和我們熟悉的SQL語句有著本質(zhì)不同:
SQL是適用于【關(guān)系數(shù)據(jù)庫】的查詢語句,SQL里我們關(guān)注的是Tabel和Tabel不斷地做join,結(jié)合多個(gè)表的信息來得到我們最終想要的東西。但在PromQL里,我們處理的是【時(shí)序數(shù)據(jù)庫】里的數(shù)據(jù)向量。這里我們沒有Tabel了,全都是存在一些Label和指標(biāo)的Vector。Join也很少用了。
我們可以看一個(gè)例子,當(dāng)我們想查過去1 min 中響應(yīng)時(shí)間最高的前十個(gè)應(yīng)用,PromQL是這么寫的:
topk(10,sum by (service)(sum_over_time(arms_http_requests_seconds{}[1m]))/sum by (service)(sum_over_time(arms_http_requests_count{}[1m])))
對熟悉SQL的同學(xué)開始,tokk 和 sum by 還算直觀,sum_over_time 是啥,中間那個(gè)"/" 是什么意思?“arms_http_requests_seconds” 和 “arms_http_requests_count”是表名么?確實(shí)有一些學(xué)習(xí)成本。
2. 第二個(gè)"C"是"Confusing",“Confusing metric name”。
PromQL是由指標(biāo)名、算子和Label組成的,指標(biāo)名有時(shí)候會非常難懂。這主要是因?yàn)镵8s里面這些指標(biāo),是不同公司的Agent采集上來的,這種提供Agent的公司包括:Google、AWS、Datadog、Dynatrace、阿里云等等,每個(gè)公司都有自己的命名方式,甚至有一些指標(biāo)是用戶自定義的。加上監(jiān)控領(lǐng)域關(guān)注的指標(biāo)又多又雜,有時(shí)候看文檔都看不明白那些指標(biāo)到底什么意思,該怎么用。
3. 第三個(gè)"C"是“Commenly”,“Commenly used query”。
PromQL其實(shí)是一個(gè)非常常用的查詢語句,因?yàn)樗粌H能提供運(yùn)維相關(guān)的指標(biāo),CPU、rt、QPS、Error、404什么的,它也可以統(tǒng)計(jì)點(diǎn)擊率、轉(zhuǎn)換率、SLO、SLA、PV、UV,所以不僅僅是運(yùn)維工程師可以用它,開發(fā)工程師、產(chǎn)品經(jīng)理都可以用它。但現(xiàn)狀是大家都用SRE給我們配的盤,想要指標(biāo)選擇找人幫配,我們也經(jīng)常收到客戶的工單要幫寫PromQL。
綜上, PromQL的語法不好學(xué)、指標(biāo)名又復(fù)雜、日常工作中用得又多,為了減輕SRE的工作、降低工單,也為了Prometheus和K8s的推廣,我們需要一款自然語言轉(zhuǎn)PromQL的機(jī)器人。
現(xiàn)在我們來到本次分享的第二部分,我們做自然語言轉(zhuǎn)PromQL機(jī)器人走過的路(這里都是干貨)。

1. ChatGPT是不是就可以完成自然語言到PromQL的翻譯?
老板說我們要一個(gè)Text2PromQL的機(jī)器人,現(xiàn)在第一件事是要做什么呢?有的同學(xué)可能會說“買點(diǎn)GPU?”、“買個(gè)帶GPU的FC實(shí)例?”、“收集點(diǎn)語料?”,這幾件事都很重要,但不是我們第一步要做的事情。
我們第一步要做的事情是先看看ChatGPT自己,是不是就可以完成自然語言到PromQL的翻譯了。如果大模型本身就可以很好地完成這個(gè)任務(wù),那我們不用開發(fā)了。就等著通義千問做大做強(qiáng),我們直接調(diào)用他們的API就行。我們做了一些實(shí)驗(yàn),發(fā)現(xiàn)ChatGPT和通義千問都不能很好地完成這個(gè)工作。以ChatGPT為例,我問他“給我寫個(gè)PromQL,幫我查一下過去5min,平均響應(yīng)時(shí)間最長的10個(gè)應(yīng)用是啥”。它給我的回答是topk(10,avg_over_time(application_response_time_seconds[5m]))
我們看下它哪里錯(cuò)了,首先是指標(biāo)名的事情,在我們的系統(tǒng)中,根本沒有一個(gè)叫"application_response_time_seconds"的指標(biāo),且avg_over_time(application_response_time_seconds[5m]))的意思是,對指標(biāo)5min內(nèi)。
先算"application_response_time_seconds"指標(biāo)頭和尾的差值,比如它在10:05min的值-它在10:00的值,再除以5。這個(gè)在可觀測領(lǐng)域是沒有物理含義的。
我們說過去5min內(nèi),應(yīng)用平均響應(yīng)時(shí)間,是需要用過去5min內(nèi),應(yīng)用被調(diào)用的總耗時(shí),除以它被調(diào)用的總次數(shù),是每次調(diào)用的平均響應(yīng)時(shí)間,分母是調(diào)用次數(shù),不是5min。可以看看正確的例子:
topk(10,sum by (service)(sum_over_time(arms_http_requests_seconds{}[5m]))/sum by (service)(sum_over_time(arms_http_requests_count{}[5m])))
總結(jié)來看,如ChatGPT的通用LLM表現(xiàn):
-
-
但它對我們的系統(tǒng)一無所知,不知道我們的指標(biāo)名,對別的公司提供的監(jiān)控系統(tǒng)也不知道,它沒法知道我們的指標(biāo)名。
-
它其實(shí)不大了解用戶問這個(gè)問題真正的意圖,因?yàn)樗谶@里的背景知識太少了。
也就是說,LLM需要更多知識...
為了給LLM灌知識,我們也進(jìn)行了大量調(diào)研,總的來說有2種方案:
這兩種方案本身沒有優(yōu)劣之分,雖然Prompt Engineering聽起來會更簡單一些,但已在很多領(lǐng)域表現(xiàn)出比Fine turning更優(yōu)的性能。我們畫了一顆決策樹,希望能給想要做LLM-based 應(yīng)用的同行們一些經(jīng)驗(yàn):
如果你老板讓我們做一個(gè)LLM-based的應(yīng)用,我們要先問問自己:“我是不是一個(gè)經(jīng)驗(yàn)豐富的NLPer”,如果您不知道NLPer是啥?-- 誠摯推薦“Prompt Engineering”。
如果您是一位經(jīng)驗(yàn)豐富的NLPer,手握十幾篇A。好,第二個(gè)問題,“貴團(tuán)隊(duì)有沒有足夠的GPU?”如果貴團(tuán)隊(duì)有十幾張A100,那不用猶豫了,直接 Fine-tuining。可以搞一個(gè)大新聞,說不定能做一個(gè)比ChatGPT更強(qiáng)的領(lǐng)域?qū)俅竽P停?/span>
-
如果您不是經(jīng)驗(yàn)豐富的NLPer,那么第二個(gè)問題是“您或您的團(tuán)隊(duì)中,有沒有某個(gè)領(lǐng)域的專家”比如K8s領(lǐng)域,或者可觀測領(lǐng)域。如果您對這個(gè)問題的回答是“Yes”,那么Prompt Engineering是最優(yōu)的選擇。
在我們ARMS團(tuán)隊(duì)目前還沒有招攬垂直的NLP人才,但我們在可觀測領(lǐng)域有十余年實(shí)踐經(jīng)驗(yàn),所以我們選擇了Prompt Engineering。
這一頁P(yáng)PT至少對我來說,是今天最有價(jià)值的一頁。我希望幾個(gè)月前有人能夠把它分享給我,這樣我可以節(jié)約很多時(shí)間和精力(當(dāng)然還有我們團(tuán)隊(duì)經(jīng)費(fèi))。
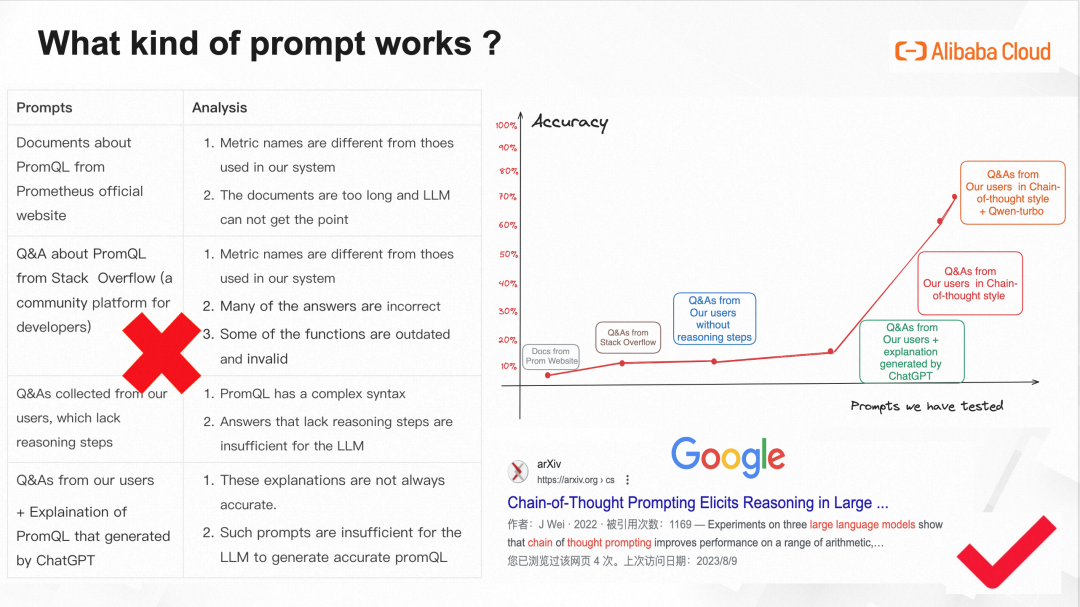
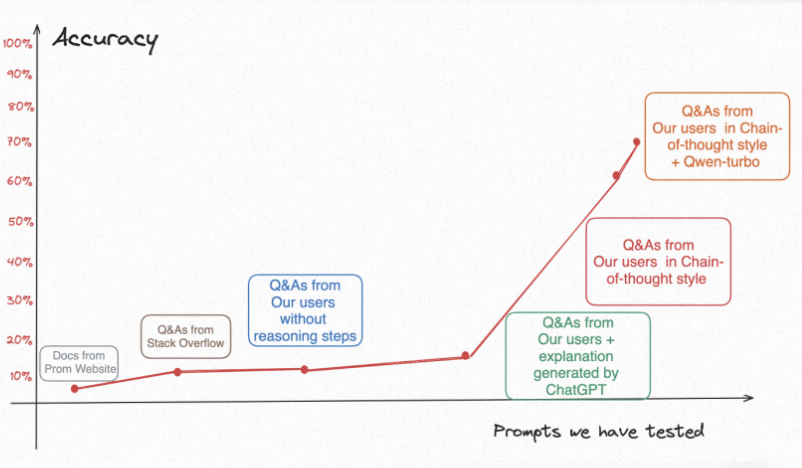
我們花了好幾個(gè)月時(shí)間嘗試了5種提示詞,終于把text2PromQL的準(zhǔn)確率從百分之5以下,提升到百分之70-80%,簡單復(fù)盤一下探索歷程:
?PromQL官方文檔
項(xiàng)目剛開始時(shí)候,第一個(gè)想到的可能有用的提示詞是Prometheus官網(wǎng)所提供關(guān)于PromQL的文檔,這個(gè)其實(shí)很直覺。然后試了一下,就用戶提問一個(gè)PromQL問題,系統(tǒng)自動地把整個(gè)PromQL的文檔當(dāng)做提示詞灌進(jìn)去。測試了幾十個(gè)Case,結(jié)果就是基本沒有對的。
我們分析:大模型寫出來的PromQL里面指標(biāo)名和我們系統(tǒng)的不一樣,也可以理解;意圖識別也不對,因?yàn)長LM其實(shí)沒那么聰明,它沒法從那么抽象、那么長的文檔里面找出比如“查前十個(gè)平均響應(yīng)時(shí)間最長的應(yīng)用”要有那些算子,怎么對指標(biāo)加減乘除得到“平均響應(yīng)時(shí)間”。
?社區(qū)問答示例
那既然文檔太長了,大模型學(xué)不會。我們做了一些調(diào)研發(fā)現(xiàn)說給大模型喂examples是有用的,就是常說的 “Few-shot”方式。然后就從Stack Overflow問答平臺上找了幾十個(gè)關(guān)于PromQL的問答。用戶提問時(shí)就給他匹配語料里最相似的Case。結(jié)果準(zhǔn)確率好了一點(diǎn)點(diǎn),但是還是10%以下。
我們分析:首先,還是指標(biāo)名問題,Q&A里的指標(biāo)名不是我們系統(tǒng)里用的那些;其次,這種社區(qū)的回答質(zhì)量其實(shí)參差不齊,他們給的答案也未必是對的。最后,一些回答里提到的函數(shù)和算子已被廢棄,現(xiàn)在執(zhí)行這種算子是無效的。
?ARMS內(nèi)部收集的PromQL問答示例
經(jīng)過前兩步嘗試,我們發(fā)現(xiàn)指標(biāo)名是繞不開的問題。所以我們的第三個(gè)PromQL方案是用ARMS系統(tǒng)自己收集的Q&A,這里的答案就包含了我們自己系統(tǒng)指標(biāo)名的信息。我們做了實(shí)驗(yàn)之后發(fā)現(xiàn),效果確實(shí)好了一點(diǎn),但不多。因?yàn)榍懊嬲f的PromQL確實(shí)比較復(fù)雜,有很多算子、很多指標(biāo)名。對大模型來說,還是太難了。
?ARMS內(nèi)部收集的PromQL問答示例+ChatGPT生產(chǎn)的對回復(fù)中的PromQL的解釋
那既然直接給PromQL不夠,我們就加一些對PromQL的說明,這里的說明我們是直接用ChatGPT生產(chǎn)的。做了實(shí)驗(yàn),發(fā)現(xiàn)這樣準(zhǔn)確率可以到20%左右,其實(shí)也沒啥用。
?Chain-of-Thought格式的PromQL問答示例
經(jīng)過一個(gè)非常長的探索,我們終于找到一種Prompt Engineering的算法,實(shí)驗(yàn)之后,即使基于ChatGLM-6B,準(zhǔn)確率也能到60-70%,終于迎來了第一個(gè)拐點(diǎn)。
?Chain-of-Thought格式的PromQL問答示例+通義千問
當(dāng)我們把大模型換成通義千問,其它配置一點(diǎn)沒改,準(zhǔn)確率原地漲了10%,到了80%左右。即使不完全正確的場景,也給了指標(biāo)名、該用的算子等非常有用的信息且語法基本不會錯(cuò)。通義千問確實(shí)很厲害!
Chain-of-Thought 是Google Brain實(shí)驗(yàn)室提出來算法,本來用來增強(qiáng)LLM推理能力的,本來也不是用來做Text2PromQL,而是用來教LLM解小學(xué)應(yīng)用題的。這篇論文甚至都沒有正式發(fā)表,只是掛在了arxiv上,一年的時(shí)間,引用量就1000+了,可能也有熟悉LLM的小伙伴聽說過它。
下面我們來介紹CoT是什么, 剛剛我們說了PromPT是給到大模型的知識,那么Chain-of-Thought PromPT就是給到大模型的帶推理步驟的知識。
舉個(gè)例子,現(xiàn)在我們希望LLM回答一個(gè)應(yīng)用題Q:餐廳有23個(gè)蘋果,如果他們用20個(gè)做午餐,然后又買了6個(gè),那它現(xiàn)在有幾個(gè)?由于GPT是個(gè)自然語言模型,它不大會算數(shù)。為了提升準(zhǔn)確率,我們給他一些提示PromPT提示詞給LLM一個(gè)例子。
?普通提示詞:
Q:Roger有5個(gè)羽毛球,他又買了2桶,每桶有3個(gè),那他現(xiàn)在有幾個(gè)。
理論上,LLM應(yīng)該能照葫蘆畫瓢回答出來,但他的答案是錯(cuò)誤的。
?Google 給的Chain-of-Thought提示詞:
Q:Roger有5個(gè)羽毛球,他又買了2桶,每桶有3個(gè),那他現(xiàn)在有幾個(gè)。
A:Roger本來有5個(gè)球,買了2桶,每桶3個(gè)的球,也就是6個(gè)球。5+6=11。所以答案是11。
這里就是給了例子中的推導(dǎo)過程。然后奇跡發(fā)生了,GPT居然就會了并給出正確答案。
下面我們來介紹CoT算法,在Text2PromQL場景下是怎么使用的。如果您比較熟悉PromQL,您應(yīng)該可以感覺到寫PromQL很像我們小學(xué)做的應(yīng)用題。
Q:“幫忙寫一個(gè)PromQL,我想查過去5min,平均響應(yīng)時(shí)間最長的前十個(gè)應(yīng)用是哪些?”
A:首先,我們算過去5min,每個(gè)應(yīng)用被調(diào)用的總時(shí)長,可以用下面的PromQL
然后,我們算過去5min,每個(gè)應(yīng)用一共被調(diào)用了多少次,可以用下面的PromQL
可以看到這倆PromQL只是指標(biāo)名不同,第一個(gè)是“arms_http_requests_seconds”記錄的是latency,第二個(gè)的指標(biāo)名是“arms_http_requests_count”記錄的是調(diào)用量
再然后,算平均響應(yīng)時(shí)間,那平均響應(yīng)時(shí)間=調(diào)用總時(shí)長/調(diào)用總次數(shù)。這個(gè)PromQL就是用第一步的PromQL除以第二步的PromQL,得到
最后,因?yàn)閱柕氖瞧骄憫?yīng)時(shí)間最高的前10個(gè)應(yīng)用,所以還需要調(diào)用一下Topk函數(shù),得到最終的PromQL
這就是CoT在Text2PromQL場景下的提示詞。下面介紹ARMS小機(jī)器人的系統(tǒng)架構(gòu)圖
我們擁有一個(gè)離線系統(tǒng)和一個(gè)在線系統(tǒng)。在離線系統(tǒng)中,我們將ARMS多年沉淀的大量用戶關(guān)于Text2Promql的問答示例,通過Chain-of-Chain Prompting算法轉(zhuǎn)換成Chain-of-thought格式的Q&A示例,然后進(jìn)行文本切割,得到一個(gè)Q&A示例,再通過embedding將文字轉(zhuǎn)換為數(shù)字組成的向量,再把這些向量存到數(shù)據(jù)庫中。
下面來看在線系統(tǒng),當(dāng)一個(gè)用戶提問,比如寫一個(gè)PromQL,查平均響應(yīng)時(shí)間最長的10個(gè)應(yīng)用,類似地,我們也會把這些文字,通過embedding,轉(zhuǎn)換成數(shù)字組成的向量。現(xiàn)在我們擁有了用戶問題轉(zhuǎn)換出來的向量,以及離線系統(tǒng)中,數(shù)據(jù)庫中一系列向量。那么,我們就可以在數(shù)據(jù)庫中檢索和當(dāng)前用戶問題最相似的topk個(gè)向量,把這個(gè)k+1個(gè)數(shù)字組成的向量還原為文字,然后把用戶的問題,以及k個(gè)最相似的歷史Q&A作為提示詞輸入到大模型中,就可以得到最終的PromQL。
可以看到,我們這個(gè)系統(tǒng)初始的輸入是用戶的PromQLl問答示例,所以當(dāng)用戶問得越多,我們能覆蓋的場景也越多,準(zhǔn)確率也會越高,總的來說,我們的機(jī)器人會越問越聰明。
-
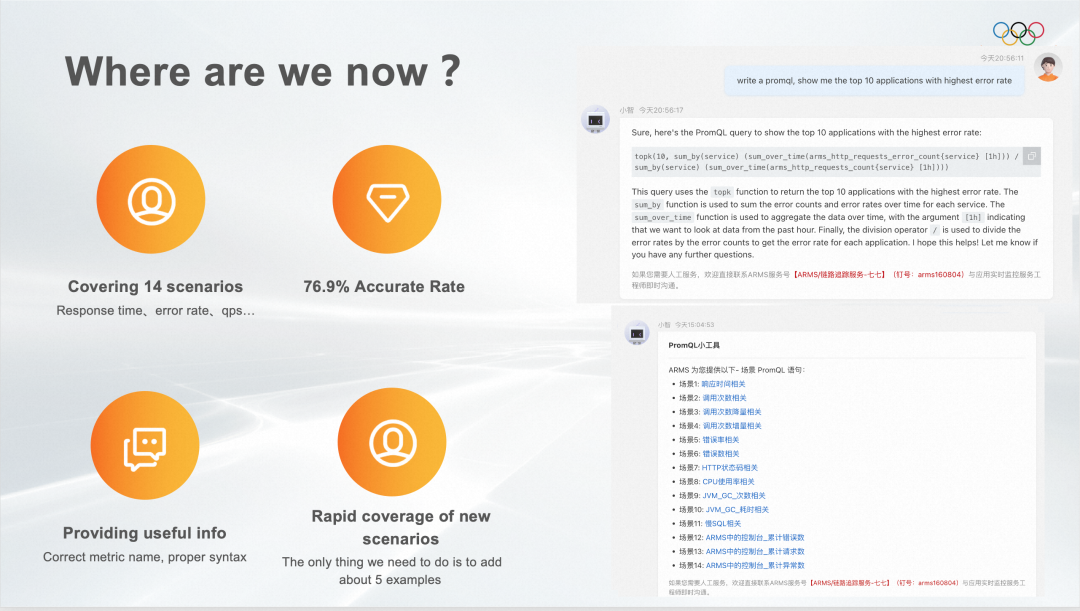
ARMS應(yīng)用性能監(jiān)控的14個(gè)場景,目前覆蓋的都是ARMS的指標(biāo),如果不是ARMS的用戶,可能需要根據(jù)指標(biāo)名進(jìn)行修改。
-
K8s相關(guān):(Container、Pod、Node維度)的CPU使用率、內(nèi)存使用率、磁盤使用率等
-
靈駿默認(rèn)大盤相關(guān):(節(jié)點(diǎn)和集群維度)的CPU使用率、GPU使用率和內(nèi)存使用率
-
Kafka相關(guān):(消息Topic、Group、instance維度)消息發(fā)送、消費(fèi)、堆積量、磁盤使用率等
-
Nacos相關(guān):Full GC、服務(wù)讀\寫接口rt等
-
MSE相關(guān):網(wǎng)絡(luò)流量、CPU、內(nèi)存、磁盤指標(biāo)。
在我們覆蓋的場景中,我們用100+個(gè)Case測試過,準(zhǔn)確率76.9%。即使在沒有覆蓋的場景下也能給出非常多有用信息。更重要的是基于PromPT Engineering,通過給提示詞增加模型的準(zhǔn)確率,所以覆蓋新場景非常快,只要給它生成CoT格式的提示詞就好。
產(chǎn)品體驗(yàn)入口:
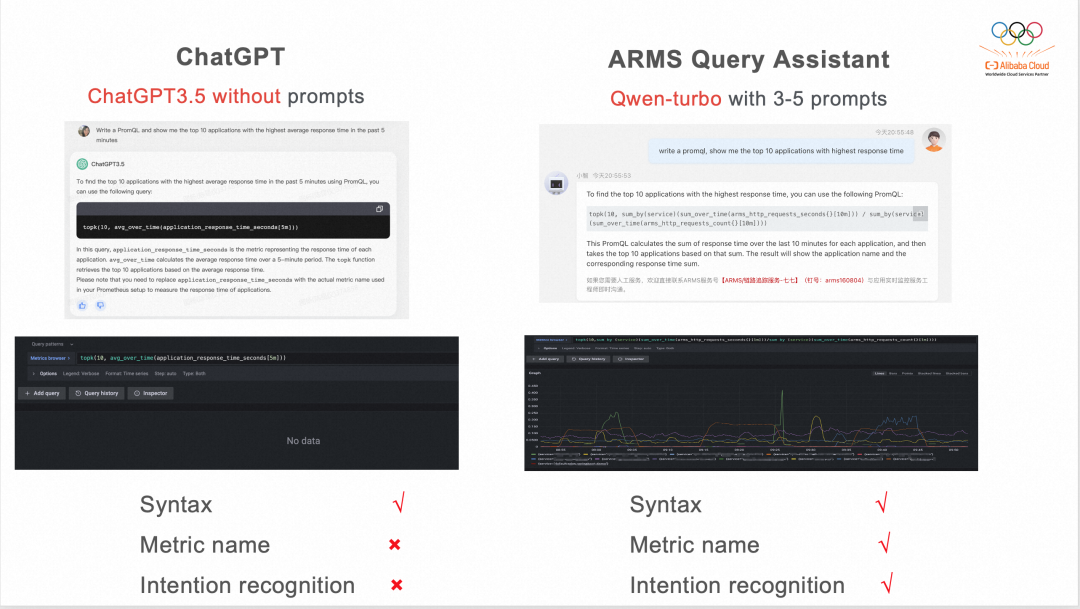
我們還做了一個(gè)對比實(shí)驗(yàn):問沒有提示詞的ChatGPT 3.5還是剛剛那個(gè)“幫忙寫一個(gè)PromQL,我想查過去5min,平均響應(yīng)時(shí)間最長的前十個(gè)應(yīng)用是哪些?” ,記過ChatGPT能寫對語法,但是指標(biāo)名和用戶意圖識別都是錯(cuò)的。然后問一下原生通義千問,發(fā)現(xiàn)它寫的是類SQL?
但問通義千問的 Qwen-turbo + 我們的CoT提示詞,結(jié)果語法、指標(biāo)名和用戶意圖識別都是對的,無可挑剔。
最后就是展望啦,自然語言轉(zhuǎn)查詢語句在數(shù)據(jù)庫和可觀測領(lǐng)域目前都是比較火熱的話題。可觀測領(lǐng)域的巨頭們,比如Google、DataDog、New Relic 都提供類似服務(wù)。其中Google和我們思路相似,也是自然語言轉(zhuǎn)PromQL,畢竟PromQL是云原生方向查詢語句的事實(shí)標(biāo)準(zhǔn)。
但即使Google背后的模型是ChatGPT4,也做不到100%的準(zhǔn)確率。因?yàn)樗麄儾桓易尨竽P椭苯映鰣D,或者說出大盤,還需要人工來點(diǎn)確認(rèn)。BTW,可觀測領(lǐng)域的新星HoneyComb倒是敢直接出圖,這里可以體驗(yàn):https://www.honeycomb.io/sandbox
To the best of my knowledge,基于我個(gè)人淺薄的認(rèn)知,這個(gè)方向后面還有很長很長的路要走。
1. 第一個(gè)里程碑可能是一個(gè)自然語言到圖表的機(jī)器人。
我們現(xiàn)在的topic是“Chat with me and get the PromQL you want”,那個(gè)時(shí)候的topic可能是“Chat with me and get the charts you want”,就直接出圖了,查詢語句接近100%準(zhǔn)確。到時(shí)候想要圖表、要數(shù)據(jù)就不用麻煩SRE大佬們了,直接和機(jī)器人說。
2. 第二個(gè)里程碑可能是一個(gè)可觀測領(lǐng)域更智能的機(jī)器人。
不僅能出圖,還能告訴你怎么配告警、怎么查問題,就像個(gè)經(jīng)驗(yàn)豐富的運(yùn)維工程師。但我們還是需要一個(gè)人類來點(diǎn)確定按鈕,來決定是否采納建議。那時(shí)候的topic是“Chat with me and get monitoring suggestions you want”。
3. 最后一個(gè)里程碑就是暢想已久的ChatOps。
真的可以通過對話來運(yùn)維,那時(shí)候機(jī)器人就像一個(gè)非常專業(yè)的、經(jīng)驗(yàn)豐富的、extremely hard-working的運(yùn)維工程師,這里我放的是祖師爺--圖靈。我們暢想的topic是“Chat with me and I will take care of your systems and applications”。這個(gè)崗位估計(jì)就不怎么需要人類了。
當(dāng)然第三個(gè)里程碑可能有點(diǎn)遠(yuǎn),我感覺前兩個(gè)應(yīng)該在不遠(yuǎn)的將來。
非常感謝大佬您看到了這里,這篇文章很長,但重點(diǎn)就兩句話:“CoT提示詞真的靠譜” “在text2PromQL場景下,實(shí)例Q&A + 一步一步的PromQL生成過程是我們實(shí)驗(yàn)過的最靠譜的PromPT。”
因?yàn)槲覀兘衲暌呀?jīng)沒有holiday了。
Q1:Prometheus 版本不斷再升級,同一家公司、不同團(tuán)隊(duì)用的版本可能也不大一樣,會對這個(gè)Text2PromQL準(zhǔn)確性有影響嗎?
A1:首先,雖然 Prometheus自己確實(shí)在不斷地升級,但對PromQL算子本身,其實(shí)這么久也沒有太多變化。那些常用的、基礎(chǔ)算子已經(jīng)很完備了。所以其實(shí)Prometheus版本更新對我們來說影響不大;其次,即使出現(xiàn)了新的常用算子,我們也只需要再對它進(jìn)行語料覆蓋就好。因?yàn)槲覀冏龅氖翘崾驹~工程嘛,所以只需要加一些語料,不用去調(diào)模型,訓(xùn)練它,幾天就能新覆蓋一個(gè)場景。
Q2:剛剛提到用ChatGPT3.5進(jìn)行了實(shí)驗(yàn),但在Text2PromQL場景下效果不好。那現(xiàn)在ChatGPT-4出來了,它比ChatGPT3.5強(qiáng)很多,有沒有在它上面做實(shí)驗(yàn)?zāi)兀?/span>
A2:這是一個(gè)非常好的問題。ChatGPT-4確實(shí)很厲害,我們也試了一下,但它依然不能很好地解決Text2PromQL的場景。首先,PromQL是算子+Label+指標(biāo)名。那指標(biāo)名是我們系統(tǒng)產(chǎn)生的,比如ARMS 應(yīng)用性能監(jiān)控的用戶,他指標(biāo)名是ARMS自定義的,也不是公開的數(shù)據(jù),ChatGPT-4就很難獲取到這部分的信息。然后,就是更聰明的模型,我們理解它只是泛化能力更強(qiáng),可能要覆蓋一個(gè)新場景,比如容器監(jiān)控,告訴它一點(diǎn)信息,給幾個(gè)例子他就能表現(xiàn)得很好啦。
Q3: 想問一下系統(tǒng)中有用開源的向量數(shù)據(jù)庫和開源大模型像ChatGLM什么的嗎?
A3:我們一開始探索時(shí),通義千問和阿里云的向量數(shù)據(jù)庫還沒有公布。當(dāng)時(shí)我們用的確實(shí)是開源向量數(shù)據(jù)庫和開源大模型ChatGLM-6B。后來上線時(shí),就換了阿里云的向量數(shù)據(jù)庫和通義千問。可以看這個(gè)圖,當(dāng)我們把大模型換成通義千問后,其它配置一點(diǎn)沒改,準(zhǔn)確率原地漲了10%,到了80%左右,即使不完全對的場景,也給了指標(biāo)名、該用的算子等非常有用的信息且語法基本不會錯(cuò)。通義千問確實(shí)很厲害!
Q4:embedding 用的是什么模型,有什么取舍?
A4:在Text2PromQL這塊兒,其實(shí)我找了一個(gè)可用的embedding模型就很靠譜了。因?yàn)閑mbedding這里就是決定了你一個(gè)用戶的問題會匹配到哪些相關(guān)語料嘛。我發(fā)現(xiàn)我們那個(gè)PromQL的語料,寫成Chain-of-Thought的格式后,就很長發(fā)現(xiàn)它基本都能匹配到和用戶問題相關(guān)的,后面這也是我們調(diào)優(yōu)方向.
Q5:問一下example的代表性,會不會對效果產(chǎn)生影響?
A5:會,所以我們先寫清楚了我們支持的場景。而且其實(shí)PromQL你匹配到它指標(biāo)名和算子,對用戶來說,他自己就能get到足夠的信息了。CoT足夠長,然后匹配到的概率已經(jīng)很高了。
Q6:這個(gè)項(xiàng)目中最難得部分是什么?因?yàn)槲覀冏约簢L試的過程中發(fā)現(xiàn)如果背后大模型不夠好,簡直是事倍功半,但你大模型比較聰明時(shí)候就很簡單。
A6:對,是這樣的。我覺得這個(gè)項(xiàng)目最難得部分有兩個(gè):都在這張圖上了。
-
第一個(gè)難的就是找合適的提示詞。CoT這種提示詞,給我們準(zhǔn)確率直接來了一個(gè)拐點(diǎn),從20%漲到60%-70%。
-
第二個(gè)是大模型本身,我們找到CoT這個(gè)算法之后,想把準(zhǔn)確率從60%-70%往上漲,也試了不少方法,但是收獲甚微。我們發(fā)現(xiàn)這個(gè)項(xiàng)目的瓶頸,就是當(dāng)時(shí)用的那個(gè)開源大模型。我們就想著,那也不是我能解決的問題,所以這個(gè)項(xiàng)目就pending了得有1個(gè)多月。后來到9月13日,通義千問對外開放了,給我們調(diào)了它的API,又給我漲了10%,其實(shí)這個(gè)10%是比較保守的,在很多場景下,example給夠,準(zhǔn)確率是非常非常高的。
Q7 :所以您這個(gè)項(xiàng)目本身沒有對通義千問做任何的fine-turn對吧?
A7:對,我們調(diào)用的就是那個(gè)商用的通義千問接口,一點(diǎn)都沒有改。