
干貨 | CV 面試問題詳解寶典--目標(biāo)檢測篇
1. 介紹YOLO,并且解釋一下YOLO為什么可以這么快?
yolo是單階段檢測算法的開山之作,最初的yolov1是在圖像分類網(wǎng)絡(luò)的基礎(chǔ)上直接進(jìn)行的改進(jìn),摒棄了二階段檢測算法中的RPN操作,直接對輸入圖像進(jìn)行分類預(yù)測和回歸,所以它相對于二階段的目標(biāo)檢測算法而言,速度非常的快,但是精度會(huì)低很多;但是在迭代到目前的V4、V5版本后,yolo的精度已經(jīng)可以媲美甚至超過二階段的目標(biāo)檢測算法,同時(shí)保持著非常快的速度,是目前工業(yè)界內(nèi)最受歡迎的算法之一。yolo的核心思想是將輸入的圖像經(jīng)過backbone特征提取后,將的到的特征圖劃分為S x S的網(wǎng)格,物體的中心落在哪一個(gè)網(wǎng)格內(nèi),這個(gè)網(wǎng)格就負(fù)責(zé)預(yù)測該物體的置信度、類別以及坐標(biāo)位置。
2. 介紹一下YOLOv3的原理?
yolov3采用了作者自己設(shè)計(jì)的darknet53作為主干網(wǎng)絡(luò),darknet53借鑒了殘差網(wǎng)絡(luò)的思想,與resnet101、resnet152相比,在精度上差不多的同時(shí),有著更快的速度,網(wǎng)絡(luò)里使用了大量的殘差跳層連接,并且拋棄了pooling池化操作,直接使用步長為2的卷積來實(shí)現(xiàn)下采樣。在特征融合方面,為了加強(qiáng)小目標(biāo)的檢測,引入了類似與FPN的多尺度特征融合,特征圖在經(jīng)過上采樣后與前面層的輸出進(jìn)行concat操作,淺層特征和深層特征的融合,使得yolov3在小目標(biāo)的精度上有了很大的提升。yolov3的輸出分為三個(gè)部分,首先是置信度、然后是坐標(biāo)信息,最后是分類信息。在推理的時(shí)候,特征圖會(huì)等分成S x S的網(wǎng)格,通過設(shè)置置信度閾值對格子進(jìn)行篩選,如果某個(gè)格子上存在目標(biāo),那么這個(gè)格子就負(fù)責(zé)預(yù)測該物體的置信度、坐標(biāo)和類別信息。
3. YOLO、SSD和Faster-RCNN的區(qū)別,他們各自的優(yōu)勢和不足分別是什么?
YOLO、SSD和Faster-RCNN都是目標(biāo)檢測領(lǐng)域里面非常經(jīng)典的算法,無論是在工業(yè)界還是學(xué)術(shù)界,都有著深遠(yuǎn)的影響;Faster-RCNN是基于候選區(qū)域的雙階段檢測器代表作,而YOLO和SSD則是單階段檢測器的代表;在速度上,單階段的YOLO和SSD要比雙階段的Faster-RCNN的快很多,而YOLO又比SSD要快,在精度上,F(xiàn)aster-RCNN精度要優(yōu)于單階段的YOLO和SSD;不過這也是在前幾年的情況下,目標(biāo)檢測發(fā)展到現(xiàn)在,單階段檢測器精度已經(jīng)不虛雙階段,并且保持著非常快的速度,現(xiàn)階段SSD和Faster-RCNN已經(jīng)不更了,但是YOLO仍在飛快的發(fā)展,目前已經(jīng)迭代到V4、V5,速度更快,精度更高,在COCO精度上雙雙破了50map,這是很多雙階段檢測器都達(dá)不到的精度,而最近的Scale yolov4更是取得了55map,成功登頂榜首。當(dāng)然雖然SSD和Faster-RCNN已經(jīng)不更了,但是有很多他們相關(guān)的變體,同樣有著不錯(cuò)的精度和性能,例如Cascade R-CNN、RefineDet等等。
4. 介紹一下CenterNet的原理,它與傳統(tǒng)的目標(biāo)檢測有什么不同點(diǎn)?
CenterNet是屬于anchor-free系列的目標(biāo)檢測算法的代表作之一,與它之前的目標(biāo)算法相比,速度和精度都有不小的提高,尤其是和yolov3相比,在速度相同的情況下,CenterNet精度要比yolov3高好幾個(gè)點(diǎn)。它的結(jié)構(gòu)非常的簡單,而且不需要太多了后處理,連NMS都省了,直接檢測目標(biāo)的中心點(diǎn)和大小,實(shí)現(xiàn)了真正的anchor-free。CenterNet論文中用到了三個(gè)主干網(wǎng)絡(luò):ResNet-18、DLA-34和Hourglass-104,實(shí)際應(yīng)用中,也可以使用resnet-50等網(wǎng)絡(luò)作為backbone;
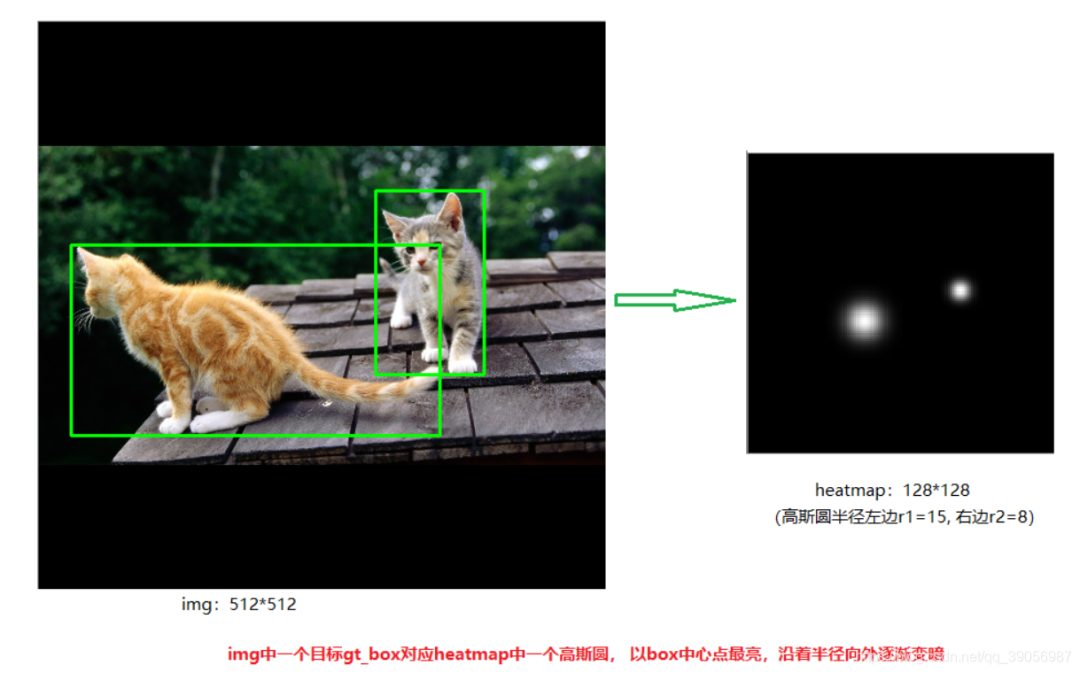
CenterNet的算法流程是:一張512512(1x3x512x512)的圖片輸入到網(wǎng)絡(luò)中,經(jīng)過backbone特征提取后得到下采樣32倍后的特征圖(1x2048x16x16),然后再經(jīng)過三層反卷積模塊上采樣到128128的尺寸,最后分別送入三個(gè)head分支進(jìn)行預(yù)測:分別預(yù)測物體的類別、長寬尺寸和中心點(diǎn)偏置。其中推理的核心是從headmap中提取需要的bounding box,通過使用3*3的最大池化,檢查當(dāng)前熱點(diǎn)的值是否比周圍的8個(gè)臨近點(diǎn)值都大,每個(gè)類別取100個(gè)這樣的點(diǎn),經(jīng)過box后處理后再進(jìn)行閾值篩選,得到最終的預(yù)測框。
5. CenterNet中heatmap(熱力圖)如何生成?
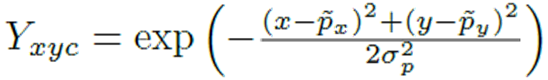
heatmap的生成可以通過高斯核公式來理解,其中(x,y)為待檢測圖像中枚舉的步長塊位置,(px,py)為低分辨率圖像中對應(yīng)于GT關(guān)鍵點(diǎn)的坐標(biāo)。可以看出,當(dāng)枚舉塊的位置和GT關(guān)鍵點(diǎn)坐標(biāo)接近重合的時(shí)候,高斯核輸出值接近為1;當(dāng)枚舉塊位置和GT關(guān)鍵點(diǎn)相差很大時(shí),高斯核輸出值接近為0.這樣一來經(jīng)過高斯核映射后的每個(gè)關(guān)鍵點(diǎn)(塊)高斯熱圖為:

每個(gè)點(diǎn)的范圍是0-1,而1則代表 這個(gè)目標(biāo)的中心點(diǎn),也就是要預(yù)測學(xué)習(xí)的點(diǎn),該點(diǎn)處為最大值,沿著半徑向外按高斯函數(shù)遞減 。一個(gè)類別對應(yīng)一張heatmap,80個(gè)類別則有80張heatmap,若還有一只狗,則狗的keypoint再另一張heatmap上。
6. 你知道哪些邊緣端部署的方案?
目前大多數(shù)深度學(xué)習(xí)算法模型要落地對算力要求還是比較高的,如果在服務(wù)器上,可以使用GPU進(jìn)行加速,但是在邊緣端或者算力匱乏的開發(fā)板子上,不得不對模型進(jìn)一步的壓縮或者改進(jìn),也可以針對特定的場景使用市面上現(xiàn)有的推理優(yōu)化加速框架進(jìn)行推理。目前來說比較常見的幾種部署方案為:
nvidia GPU:pytorch->onnx->TensorRT
intel CPU:pytorch->onnx->openvino
移動(dòng)端(手機(jī)、開發(fā)板等):pytorch->onnx->MNN、NCNN、TNN、TF-lite、Paddle-lite、RKNN等
7. 你最常用的幾種目標(biāo)檢測算法是什么?為什么選擇這些算法,你選擇它們的場景分別是什么?
在工作中,我通常會(huì)根據(jù)不同的任務(wù)選取不同的算法模型:
目標(biāo)檢測:yolov5、yolov3、CenterNet、SSD、Faster RCNN、EfficientDet;
圖像分類:mobileNetv2、mobileNetv3、ghostNet、ResNet系列、ShuffleNetV2、EfficientNet;
實(shí)例分割:mask-rcnn、yolact、solo;
語義分割:deeplabv3、deeplabv3+、UNet;
文本檢測:CTPN、PSENet、DBNet、YOLOV5;
文本識(shí)別:CRNN+CTC、CRNN+Attention;
通常,我比較喜歡性能好的模型,性能的指標(biāo)由兩部分,一個(gè)是精度,一個(gè)是速度。比如在目標(biāo)檢測中,用的比較多的是yolo系列,特別是v4、v5出來后。通常在圖像分類的任務(wù)上,分類并不困難的情況下會(huì)選擇一些輕量型的網(wǎng)絡(luò),能夠一定程度上節(jié)省算力資源。其他領(lǐng)域的任務(wù)算法抉擇也大同小異。
8. 介紹一下yolov5
yolov5和v4都是在v3基礎(chǔ)上改進(jìn)的,性能與v4基旗鼓相當(dāng),但是從用戶的角度來說,易用性和工程性要優(yōu)于v4,v5的原理可以分為四部分:輸入端、backbone、Neck、輸出端;
輸入端:針對小目標(biāo)的檢測,沿用了v4的mosaic增強(qiáng),當(dāng)然這個(gè)也是v5作者在他復(fù)現(xiàn)的v3上的原創(chuàng),對不同的圖片進(jìn)行隨機(jī)縮放、裁剪、排布后進(jìn)行拼接;二是自適應(yīng)錨框計(jì)算,在v3、v4中,初始化錨框是通過對coco數(shù)據(jù)集的進(jìn)行聚類得到,v5中將錨框的計(jì)算加入了訓(xùn)練的代碼中,每次訓(xùn)練時(shí),自適應(yīng)的計(jì)算不同訓(xùn)練集中的最佳錨框值;
backbone:沿用了V4的CSPDarkNet53結(jié)構(gòu),但是在圖片輸入前加入了Focus切片操作,CSP結(jié)構(gòu)實(shí)際上就是基于Densnet的思想,復(fù)制基礎(chǔ)層的特征映射圖,通過dense block發(fā)送到下一個(gè)階段,從而將基礎(chǔ)層的特征映射圖分離出來。這樣可以有效緩解梯度消失問題,支持特征傳播,鼓勵(lì)網(wǎng)絡(luò)重用特征,從而減少網(wǎng)絡(luò)參數(shù)數(shù)量。在V5中,提供了四種不同大小的網(wǎng)絡(luò)結(jié)構(gòu):s、m、l、x,通過depth(深度)和width(寬度)兩個(gè)參數(shù)控制。
Neck:采用了SPP+PAN多尺度特征融合,PAN是一種自下而上的特征金字塔結(jié)構(gòu),是在FPN的基礎(chǔ)上進(jìn)行的改進(jìn),相對于FPN有著更好的特征融合效果。
輸出端:沿用了V3的head,使用GIOU損失進(jìn)行邊框回歸,輸出還是三個(gè)部分:置信度、邊框信息、分類信息。
9. 在你的項(xiàng)目中為什么選用yolov5模型而不用v4?
yolov4和v5都是yolo系列性能非常優(yōu)秀的算法,性能上不分伯仲,而且最近出來的scale yolov4更是達(dá)到了55的map。在項(xiàng)目中選擇v5的原因是因?yàn)樵趘4、v5出來之前,就一直在用U版的yolov3,相對于原版的v3,做了很多改進(jìn),而V5是在這個(gè)hub的基礎(chǔ)上改進(jìn)的,用起來上手比較快,而且代碼和之前的v3相似度很高,可以無縫對接以前的項(xiàng)目。另一方面,v5可選的模型比較多,在速度和精度上對比v4有一定的優(yōu)勢,而且模型采用半精度存儲(chǔ),模型很小,訓(xùn)練和推理上都很友好。通常用s或者m版本的基本上都可以滿足項(xiàng)目需求。
比較官方一點(diǎn)的回答:
使用Pytorch框架,對用戶非常友好,能夠方便地訓(xùn)練自己的數(shù)據(jù)集,相對于YOLOV4采用的Darknet框架,Pytorch框架更容易投入生產(chǎn)。
代碼易讀,整合了大量的計(jì)算機(jī)視覺技術(shù),非常有利于學(xué)習(xí)和借鑒。
不僅易于配置環(huán)境,模型訓(xùn)練也非常快速,并且批處理推理產(chǎn)生實(shí)時(shí)結(jié)果。
能夠直接對單個(gè)圖像,批處理圖像,視頻甚至網(wǎng)絡(luò)攝像頭端口輸入進(jìn)行有效推理。
能夠輕松的將Pytorch權(quán)重文件轉(zhuǎn)化為安卓使用的ONXX格式,然后可以轉(zhuǎn)換為OPENCV的使用格式,或者通過CoreML轉(zhuǎn)化為IOS格式,直接部署到手機(jī)應(yīng)用端。
最后YOLO V5s高達(dá)140FPS的對象識(shí)別速度令人印象非常深刻,使用體驗(yàn)非常棒。
10. 介紹yolov5中Focus模塊的原理和作用
Focus模塊,將W、H信息集中到通道空間,輸入通道擴(kuò)充了4倍,作用是可以使信息不丟失的情況下提高計(jì)算力。具體操作為把一張圖片每隔一個(gè)像素拿到一個(gè)值,類似于鄰近下采樣,這樣我們就拿到了4張圖,4張圖片互補(bǔ),長的差不多,但信息沒有丟失,拼接起來相當(dāng)于RGB模式下變?yōu)?2個(gè)通道,通道多少對計(jì)算量影響不大,但圖像縮小,大大減少了計(jì)算量。
以Yolov5s的結(jié)構(gòu)為例,原始640×640×3的圖像輸入Focus結(jié)構(gòu),采用切片操作,先變成320×320×12的特征圖,再經(jīng)過一次32個(gè)卷積核的卷積操作,最終變成320×320×32的特征圖。
11.yolov4和v5均引入了CSP結(jié)構(gòu),介紹一下它的原理和作用;
CSP結(jié)構(gòu)是一種思想,它和ResNet、DenseNet類似,可以看作是DenseNet的升級版,它將feature map拆成兩個(gè)部分,一部分進(jìn)行卷積操作,另一部分和上一部分卷積操作的結(jié)果進(jìn)行concate。主要解決了三個(gè)問題:1. 增強(qiáng)CNN的學(xué)習(xí)能力,能夠在輕量化的同時(shí)保持著準(zhǔn)確性;2. 降低計(jì)算成本;3. 降低內(nèi)存開銷。CSPNet改進(jìn)了密集塊和過渡層的信息流,優(yōu)化了梯度反向傳播的路徑,提升了網(wǎng)絡(luò)的學(xué)習(xí)能力,同時(shí)在處理速度和內(nèi)存方面提升了不少。
12. 你還了解當(dāng)下哪些比較流行的目標(biāo)檢測算法?
目前比較流行的目標(biāo)檢測算法有以下幾種類型,不局限于這幾種:
anchor-based:yolov3、yolov4、yolov5、pp-yolo、SSD、Faster-R-CNN、Cascade R-CNN、EfficientDet,RetinaNet、MTCNN;
anchor-free:CornerNet、CenterNet、CornerNet-lite、FCOS;
transform:DETR;
mobile-detector:mobileNet-yolo、mobileNet-SSD、tiny-yolo、nanodet、yolo-fastest、YOLObile、mobilenet-retinaNet、MTCNN;
還有很多很多。。。mmdetection里面就實(shí)現(xiàn)了幾十種,可以去看一看,這里面最想總結(jié)的是移動(dòng)端的det,很多都是一些大佬在原生算法基礎(chǔ)上的改進(jìn)。
13. EfficentDet為什么可以做到速度兼精度并存 ?
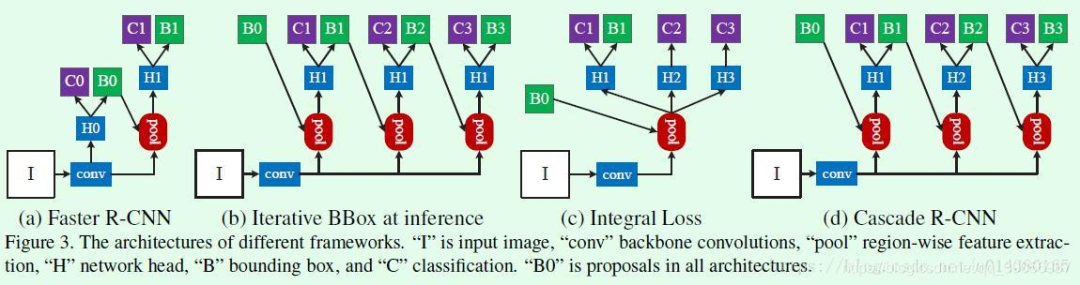
14. 介紹Faster R-CNN和Cascade R-CNN
Faster-RCNN是基于候選區(qū)域的雙階段檢測器代表作,總的來說可以分為四部分:首先是主干卷積網(wǎng)絡(luò)的特征提取,然后是RPN層,RPN層通過softmax判斷anchors屬于positive或者negative,再利用邊框回歸修正anchors獲得精確的候選區(qū)域,RPN生成了大量的候選區(qū)域,這些候選區(qū)域和feature maps一起送入ROI pooling中,得到了候選特征區(qū)域,最后送入分類層中進(jìn)行類別判斷和邊框回歸,得到最終的預(yù)測結(jié)果。
Cascade R-CNN算法是在Faster R-CNN上的改進(jìn),通過級聯(lián)幾個(gè)檢測網(wǎng)絡(luò)達(dá)到不斷優(yōu)化預(yù)測結(jié)果的目的,預(yù)普通的級聯(lián)不同,Cascade R-CNN的幾個(gè)檢測網(wǎng)絡(luò)是基于不同的IOU閾值確定的正負(fù)樣本上訓(xùn)練得到的。簡單來說cascade R-CNN是由一系列的檢測模型組成,每個(gè)檢測模型都基于不同IOU閾值的正負(fù)樣本訓(xùn)練得到,前一個(gè)檢測模型的輸出作為后一個(gè)檢測模型的輸入,因此是stage by stage的訓(xùn)練方式,而且越往后的檢測模型,其界定正負(fù)樣本的IOU閾值是不斷上升的。
15. SSD相比于YOLO做了哪些改進(jìn)?
這里說的是SSD相對于YOLOv1的改進(jìn),因?yàn)楝F(xiàn)在SSD已經(jīng)不更了,但是YOLO還如日中天,已經(jīng)發(fā)展到v5,性能在目標(biāo)檢測算法里一騎絕塵。那么最原始的SSD相對于YOLOv1做了哪些改進(jìn)呢?
SSD提取了不同尺度的特征圖來做檢測,而YOLO在檢測是只用了最高層的Feature maps;
SSD引入了Faster-RCNN的anchor機(jī)制,采用了不同尺度和長寬比的先驗(yàn)框;
SSD網(wǎng)絡(luò)結(jié)構(gòu)是全卷積,采用卷積做檢測,YOLO用到了FC(全連接)層;
16. 介紹SSD原理

SSD算法流程
輸入一幅圖,讓圖片經(jīng)過卷積神經(jīng)網(wǎng)絡(luò)(VGG)提取特征,生成feature map
抽取其中六層的feature map,然后分別在這些feature map層上面的每一個(gè)點(diǎn)構(gòu)造4、個(gè)不同尺度大小的default box,然后分別進(jìn)行檢測和分類(各層的個(gè)數(shù)不同,但每個(gè)點(diǎn)都有)
將生成的所有default box都集合起來,全部丟到NMS中,輸出篩選后的default box。
17. 了解哪些開源的移動(dòng)端輕量型目標(biāo)檢測?
輕量型的目標(biāo)檢測其實(shí)有很多,大多數(shù)都是基于yolo、SSD的改進(jìn),當(dāng)然也有基于其他算法改的;比較常用的改進(jìn)方法是使用輕量型的backbone替換原始的主干網(wǎng)絡(luò),例如mobilenet-ssd、mobilenet-yolov3、yolo-fastest、yolobile、yolo-nano、nanodet、tiny-yolo等等,在減少了計(jì)算量的同時(shí)保持著不錯(cuò)的精度,經(jīng)過移動(dòng)部署框架推理后,無論是在服務(wù)器還是移動(dòng)端都有著不錯(cuò)的精度和速度。
18. 對于小目標(biāo)檢測,你有什么好的方案或者技巧?
圖像金字塔和多尺度滑動(dòng)窗口檢測(MTCNN)
多尺度特征融合檢測(FPN、PAN、ASFF等)
增大訓(xùn)練、檢測圖像分辨率;
超分策略放大后檢測;
19. 介紹一下NMS和IOU的原理;
NMS全稱是非極大值抑制,顧名思義就是抑制不是極大值的元素。在目標(biāo)檢測任務(wù)中,通常在解析模型輸出的預(yù)測框時(shí),預(yù)測目標(biāo)框會(huì)非常的多,其中有很多重復(fù)的框定位到了同一個(gè)目標(biāo),NMS的作用就是用來除去這些重復(fù)框,從而獲得真正的目標(biāo)框。而NMS的過程則用到了IOU,IOU是一種用于衡量真實(shí)和預(yù)測之間相關(guān)度的標(biāo)準(zhǔn),相關(guān)度越高,該值就越高。IOU的計(jì)算是兩個(gè)區(qū)域重疊的部分除以兩個(gè)區(qū)域的集合部分,簡單的來說就是交集除以并集。
在NMS中,首先對預(yù)測框的置信度進(jìn)行排序,依次取置信度最大的預(yù)測框與后面的框進(jìn)行IOU比較,當(dāng)IOU大于某個(gè)閾值時(shí),可以認(rèn)為兩個(gè)預(yù)測框框到了同一個(gè)目標(biāo),而置信度較低的那個(gè)將會(huì)被剔除,依次進(jìn)行比較,最終得到所有的預(yù)測框。
20. 目標(biāo)檢測單階段和雙階段優(yōu)缺點(diǎn),雙階段的為什么比單階段的效果要好?
21. 目標(biāo)檢測中如何處理正負(fù)樣本不平衡的問題?
22. yolov3為什么這么快?
yolov3和SSD比網(wǎng)絡(luò)更加深了,雖然anchors比SSD少了許多,但是加深的網(wǎng)絡(luò)深度明顯會(huì)增加更多的計(jì)算量,那么為什么yolov3會(huì)比SSD快3倍?
SSD用的很老的VGG16,V3用的其最新原創(chuàng)的Darknet,darknet-53與resnet的網(wǎng)絡(luò)結(jié)構(gòu),darknet-53會(huì)先用1x1的卷積核對feature降維,隨后再利用3x3的卷積核升維,這個(gè)過程中,就會(huì)大大降低參數(shù)的計(jì)算量以及模型的大小,有點(diǎn)類似于低秩分解。究其原因是做了很多優(yōu)化,比如用卷積替代替代全連接,1X1卷積減小計(jì)算量等。
23. 你認(rèn)為當(dāng)前目標(biāo)檢測算法發(fā)展的趨勢是什么?現(xiàn)階段存在什么難點(diǎn)?
24. 你知道哪些模型壓縮和推理優(yōu)化的方案?
?------------------------------------------------
雙一流大學(xué)研究生團(tuán)隊(duì)創(chuàng)建,一個(gè)專注于目標(biāo)檢測與深度學(xué)習(xí)的組織,希望可以將分享變成一種習(xí)慣。
整理不易,點(diǎn)贊三連!