Flink 在有贊的實(shí)踐和應(yīng)用
Flink 的容器化改造和實(shí)踐
Flink SQL 的實(shí)踐和應(yīng)用
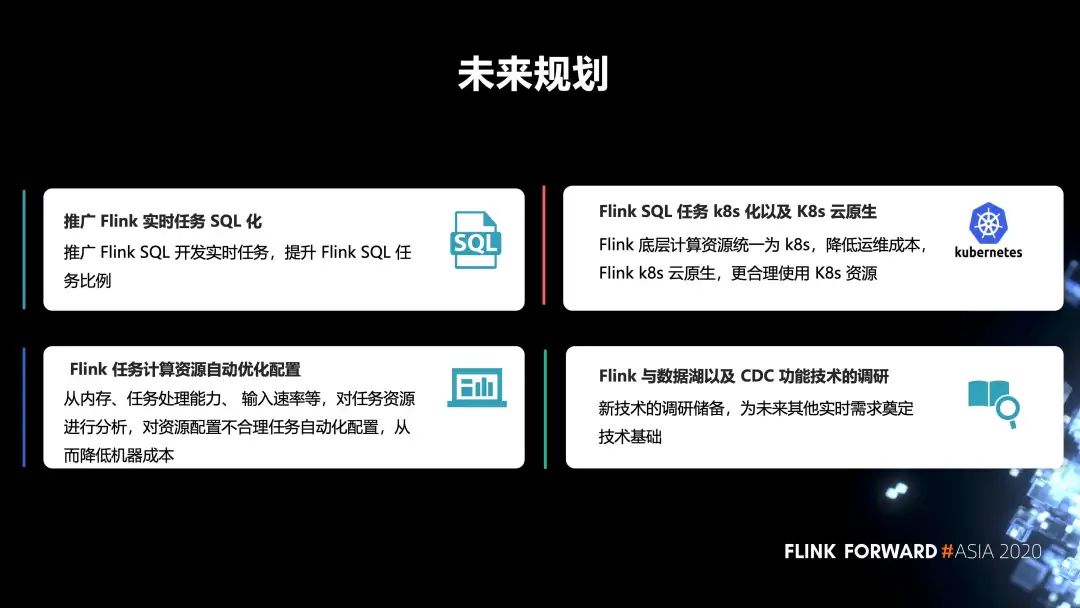
未來(lái)規(guī)劃
一、Flink 的容器化改造和實(shí)踐
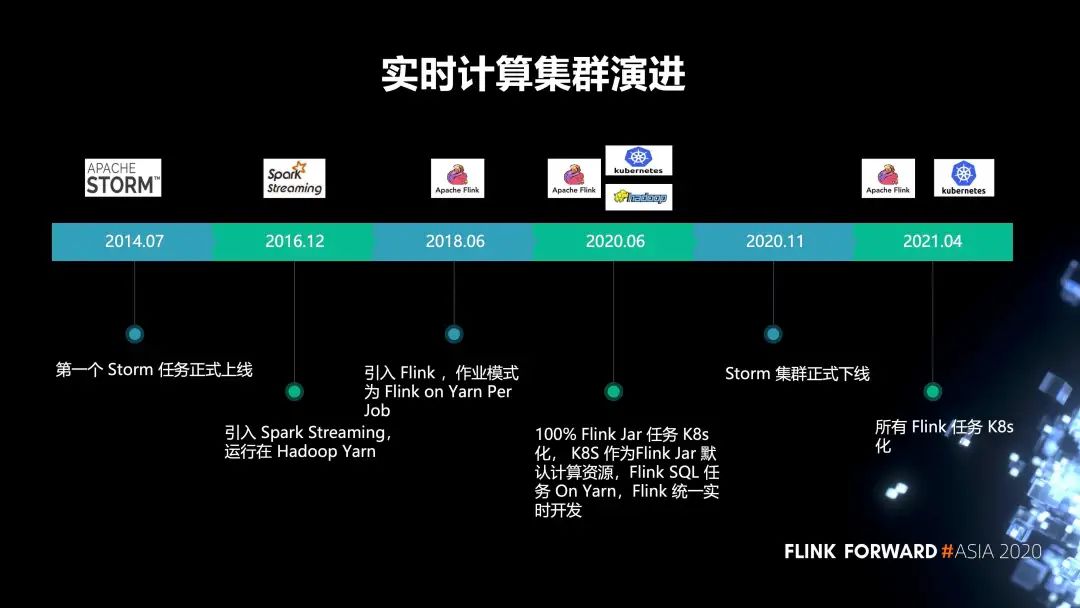
1. 有贊的集群演進(jìn)歷史
2014 年 7 月,第一個(gè) Storm 任務(wù)正式上線;
2016 年,引入 Spark Streaming, 運(yùn)行在 Hadoop Yarn;
2018 年,引入了 Flink,作業(yè)模式為 Flink on Yarn Per Job;
2020 年 6 月,實(shí)現(xiàn)了 100% Flink Jar 任務(wù) K8s 化, K8s 作為 Flink Jar 默認(rèn)計(jì)算資源,F(xiàn)link SQL 任務(wù) On Yarn,F(xiàn)link 統(tǒng)一實(shí)時(shí)開發(fā);
2020 年 11 月,Storm 集群正式下線。原先的 storm 任務(wù)全部都遷移到了 Flink;
2021 年,我們打算把所有的 Flink 任務(wù) K8s 化。
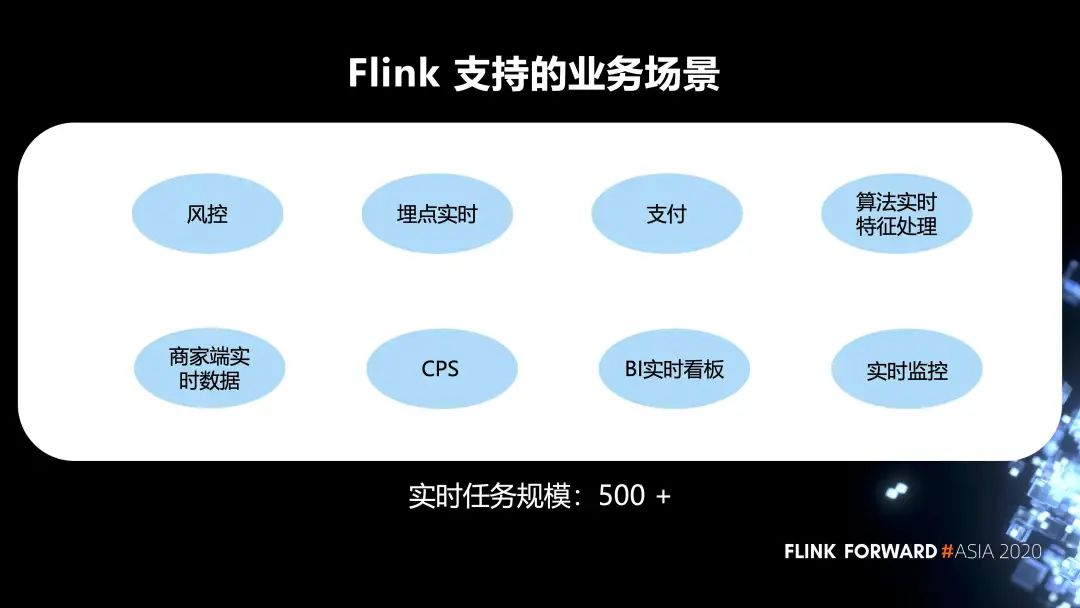
2. Flink 在內(nèi)部支持的業(yè)務(wù)場(chǎng)景
3. 有贊在 Flink on Yarn 的痛點(diǎn)
第一,CPU 沒有隔離。Flink On Yarn 模式,CPU 沒有隔離,某個(gè)實(shí)時(shí)任務(wù)造成某臺(tái)機(jī)器 CPU 使用過(guò)高時(shí), 會(huì)對(duì)該機(jī)器其他實(shí)時(shí)任務(wù)造成影響;
第二,大促擴(kuò)縮容成本高。Yarn 和 HDFS 服務(wù)使用物理機(jī),物理機(jī)在大促期間擴(kuò)縮容不靈活,同時(shí)需要投入一定的人力和物力;
第三,需要投入人力運(yùn)維。公司底層應(yīng)用資源統(tǒng)一為 K8S,單獨(dú)再對(duì) Yarn 集群運(yùn)維,會(huì)再多一類集群的人力運(yùn)維成本。

4. Flink on k8s 相對(duì)于 Yarn 的優(yōu)勢(shì)
第一,統(tǒng)一運(yùn)維。公司統(tǒng)一化運(yùn)維,有專門的部門運(yùn)維 K8S;
第二,CPU 隔離。K8S Pod 之間 CPU 隔離,實(shí)時(shí)任務(wù)不相互影響,更加穩(wěn)定;
第三,存儲(chǔ)計(jì)算分離。Flink 計(jì)算資源和狀態(tài)存儲(chǔ)分離,計(jì)算資源能夠和其他組件資源進(jìn)行 混部,提升機(jī)器使用率;
第四,彈性擴(kuò)縮容。大促期間能夠彈性擴(kuò)縮容,更好的節(jié)省人力和物力成本。

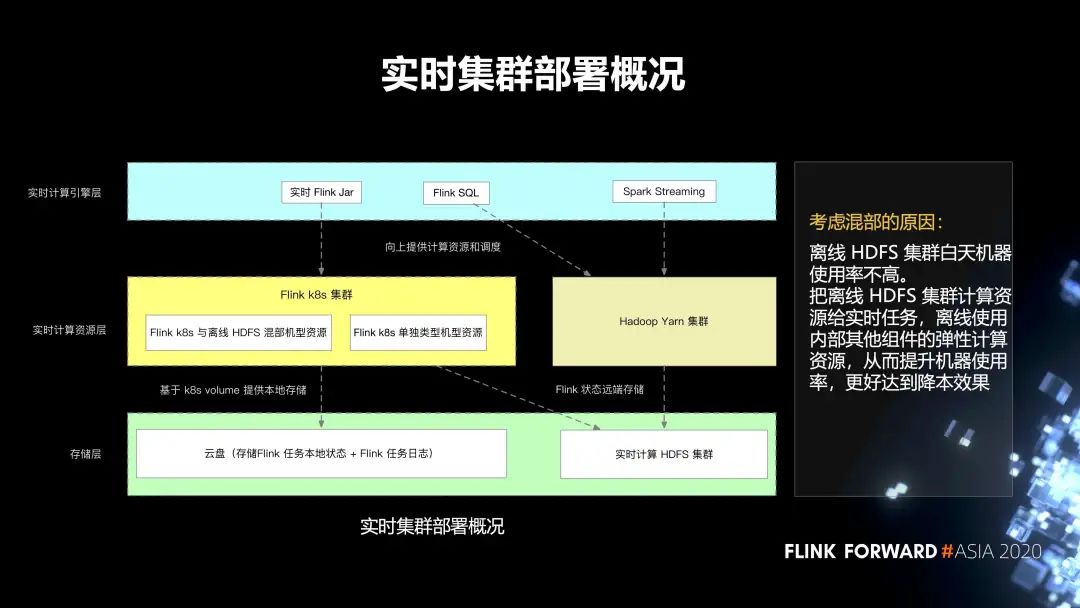
5. 實(shí)時(shí)集群的部署情況
存儲(chǔ)層主要分為兩部分:
第一個(gè)就是云盤,它主要存儲(chǔ) Flink 任務(wù)本地的狀態(tài),以及 Flink 任務(wù)的日志; 第二部分是實(shí)時(shí)計(jì)算 HDFS 集群,它主要存儲(chǔ) Flink 任務(wù)的遠(yuǎn)端狀態(tài)。
第二層是實(shí)時(shí)計(jì)算的資源層,分為兩部分:
一個(gè)是 Hadoop Yarn 集群; 另一個(gè)是 Flink k8s 集群,再往下細(xì)分,會(huì)有 Flink k8s 和離線的 HDFS 混部集群的資源,還有 Flink k8s 單獨(dú)類型的集群資源。
最上層有一些實(shí)時(shí) Flink Jar,spark streaming 任務(wù),以及 Flink SQL 任務(wù)。
我們考慮混部的原因是,離線 HDFS 集群白天機(jī)器使用率不高。把離線 HDFS 集群計(jì)算資源給實(shí)時(shí)任務(wù),離線使用內(nèi)部其他組件的彈性計(jì)算資源,從而提升機(jī)器使用率,更好的達(dá)到降本效果。
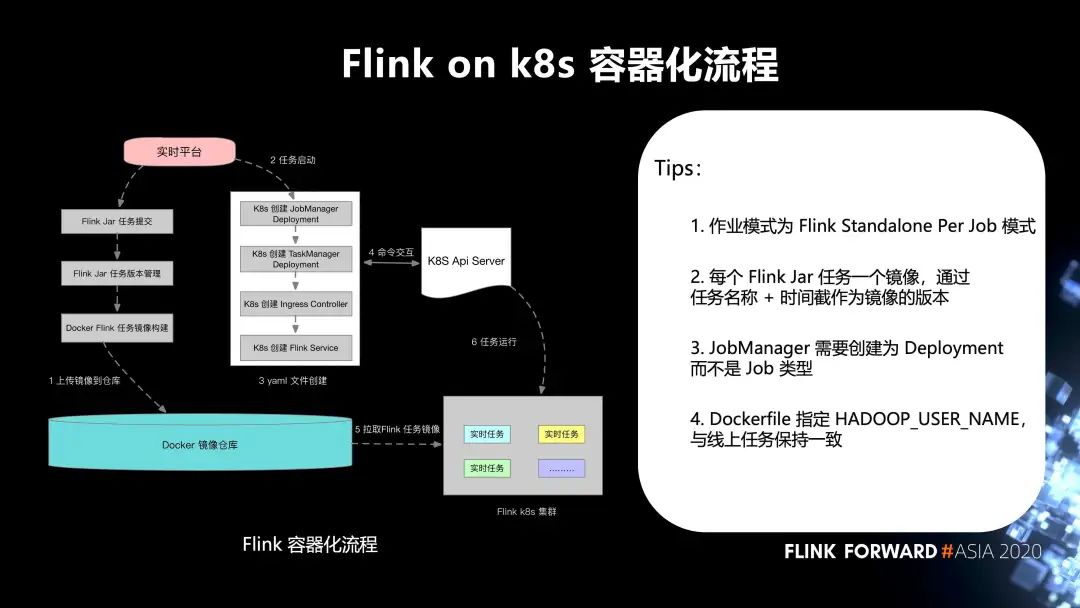
6. Flink on k8s 的容器化流程
第一步,實(shí)時(shí)平臺(tái)的 Flink Jar 任務(wù)提交,F(xiàn)link Jar 任務(wù)版本管理,Docker Flink 任務(wù)鏡像構(gòu)建,上傳鏡像到 Docker 鏡像倉(cāng)庫(kù);
第二步,任務(wù)啟動(dòng);
第三步,yaml 文件創(chuàng)建;
第四步,和 k8s Api Server 之間進(jìn)行命令交互;
第五步,從 Docker 鏡像倉(cāng)庫(kù)拉取 Flink 任務(wù)鏡像到 Flink k8s 集群;
最后,任務(wù)運(yùn)行。這邊有幾個(gè) tips:
作業(yè)模式為 Flink Standalone Per Job 模式;
每個(gè) Flink Jar 任務(wù)一個(gè)鏡像,通過(guò)任務(wù)名稱 + 時(shí)間截作為鏡像的版本;
JobManager 需要?jiǎng)?chuàng)建為 Deployment 而不是 Job 類型;
Dockerfile 指定 HADOOP_USER_NAME,與線上任務(wù)保持一致。
7. 在 Flink on k8s 的一些實(shí)踐
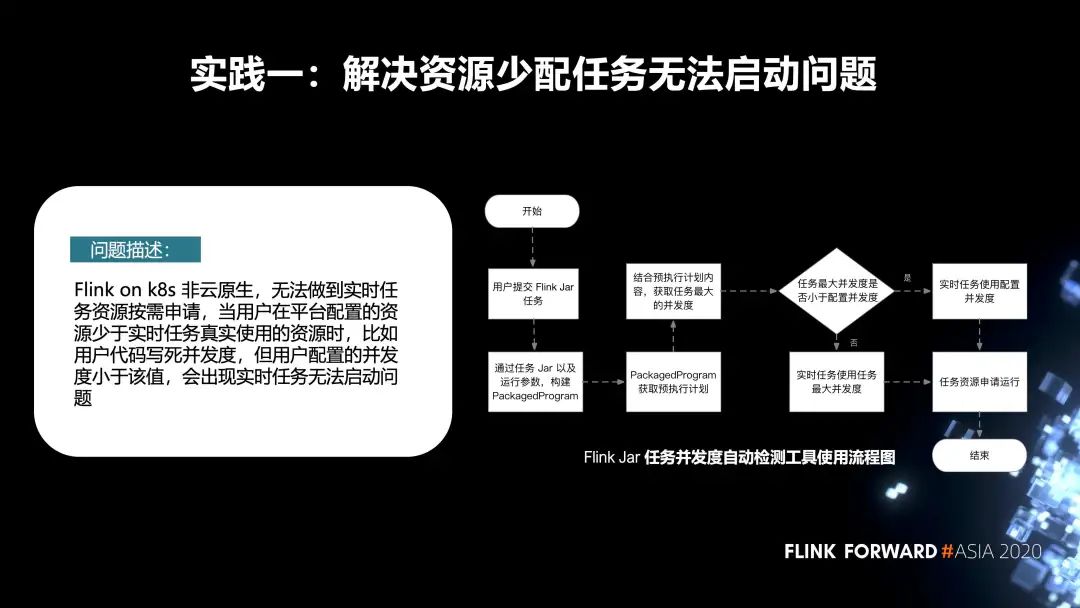
第一個(gè)實(shí)踐是解決資源少配任務(wù)無(wú)法啟動(dòng)這個(gè)問題。
先來(lái)描述一下問題,F(xiàn)link on k8s 非云原生,無(wú)法做到實(shí)時(shí)任務(wù)資源按需申請(qǐng)。當(dāng)用戶在平臺(tái)配置的資源少于實(shí)時(shí)任務(wù)真實(shí)使用的資源時(shí)(比如用戶代碼寫死并發(fā)度,但用戶配置的并發(fā)度小于該值),會(huì)出現(xiàn)實(shí)時(shí)任務(wù)無(wú)法啟動(dòng)的問題。針對(duì)這個(gè)問題,我們內(nèi)部增加了一種 Flink Jar 任務(wù)并發(fā)度的自動(dòng)檢測(cè)機(jī)制。它的主要流程如下圖所示。
首先,用戶會(huì)在我們平臺(tái)去提交 Flink Jar 作業(yè),當(dāng)他提交完成之后,在后臺(tái)會(huì)把 Jar 作業(yè)以及運(yùn)行參數(shù),構(gòu)建 PackagedProgram。通過(guò) PackagedProgram 獲取到任務(wù)的預(yù)執(zhí)行計(jì)劃。再通過(guò)它獲取到任務(wù)真實(shí)的并發(fā)度。
如果用戶在代碼里配置的并發(fā)度小于平臺(tái)端配置的資源,我們會(huì)使用在平臺(tái)端的配置去申請(qǐng)資源,然后進(jìn)行啟動(dòng);
反之,我們會(huì)使用它真實(shí)的任務(wù)并發(fā)度去申請(qǐng)資源,啟動(dòng)任務(wù)。
第二個(gè)實(shí)踐是 Flink on k8s 任務(wù)的資源分析工具。
首先來(lái)說(shuō)一下背景,F(xiàn)link k8s 任務(wù)資源是用戶自行配置,當(dāng)配置的并發(fā)度或者內(nèi)存過(guò)大時(shí),存在計(jì)算資源浪費(fèi)的問題,從而會(huì)增加底層機(jī)器成本。怎么樣去解決這個(gè)問題,我們做了一個(gè)平臺(tái)管理員的工具。對(duì)于管理員來(lái)說(shuō),他可以從兩種視角去看這個(gè)任務(wù)的資源是否進(jìn)行了一個(gè)超配:
第一個(gè)是任務(wù)內(nèi)存的視角。我們根據(jù)任務(wù)的 GC 日志,通過(guò)一個(gè)開源工具 GC Viewer,拿到這一個(gè)實(shí)時(shí)任務(wù)的內(nèi)存使用指標(biāo);
第二個(gè)是消息處理能力的視角。我們?cè)?Flink 源碼層增加了數(shù)據(jù)源輸入 record/s 和任務(wù)消息處理時(shí)間 Metric。根據(jù) metric 找到消息處理最慢的 task 或者 operator,從而判斷并發(fā)度配置是否合理。
管理員根據(jù)內(nèi)存分析指標(biāo)以及并發(fā)度合理性,結(jié)合優(yōu)化規(guī)則,預(yù)設(shè)置 Flink 資源。然后我們會(huì)和業(yè)務(wù)方溝通與調(diào)整。右圖是兩種分析結(jié)果,上面是 Flink on K8S pod 內(nèi)存分析結(jié)果。下面是 Flink K8S 任務(wù)處理能力的分析結(jié)果。最終,我們根據(jù)這些指標(biāo)就可以對(duì)任務(wù)進(jìn)行一個(gè)資源的重新調(diào)整,降低資源浪費(fèi)。目前我們打算把它做成一個(gè)自動(dòng)化的分析調(diào)整工具。

接下來(lái)是 Flink on K8s 其他的相關(guān)實(shí)踐:
第一,基于 Ingress Flink Web UI 和 Rest API 的使用。每個(gè)任務(wù)有一個(gè) Ingress 域名,始終通過(guò)域名訪問 Flink Web UI 以及 Resti API 使用; 第二,掛載多個(gè) hostpath volume,解決單塊云盤 IO 限制。單塊云盤的寫入帶寬以及 IO 能力有瓶頸,使用多塊云盤,降低云盤 Checkpoint 狀態(tài)和本地寫入的壓力; 第三,F(xiàn)link 相關(guān)通用配置 ConfigMap 化、Flink 鏡像上傳成功的檢測(cè)。為 Filebeat、Flink 作業(yè)通用配置,創(chuàng)建 configmap,然后掛載到實(shí)時(shí)任務(wù)中,確保每個(gè) Flink 任務(wù)鏡像都成功上傳到鏡像倉(cāng)庫(kù); 第四,HDFS 磁盤 SSD 以及基于 Filebeat 日志采集。SSD 磁盤主要是為了降低磁盤的 IO Wait 時(shí) 間,調(diào)整 dfs.block.invalidate.limit,降低 HDFS Pending delete block 數(shù)。任務(wù)日志使用 Filebeat 采集,輸出到 kafka,后面通過(guò)自定義 LogServer 和離線公用 LogServer 查看。

8. Flink on K8s 當(dāng)前面臨的痛點(diǎn)
第一,JobManager HA 問題。JobManager Pod 如果掛掉,借助于 k8s Deployment 能力,JobManager 會(huì)根據(jù) yaml 文件重啟,狀態(tài)可能會(huì)丟失。而如果 yaml 配置 Savepoint 恢復(fù),則消息可能大量重復(fù)。我們希望后續(xù)借助于 ZK 或者 etcd 支持 Jobmanager HA;
第二,修改代碼,再次上傳時(shí)間久。一旦代碼修改邏輯,F(xiàn)link Jar 任務(wù)上傳時(shí)間加上打鏡像時(shí)間可能是分鐘級(jí)別,對(duì)實(shí)時(shí)性要求比較高的業(yè)務(wù)或許有影響。我們希望后續(xù)可以參考社區(qū)的實(shí)現(xiàn)方式,從 HDFS 上面拉取任務(wù) Jar 運(yùn)行;
第三,K8S Node Down 機(jī), JobManager 恢復(fù)慢。一旦 K8S Node down 機(jī)后, Jobmanager Pod 恢復(fù)運(yùn)行需要 8分鐘左右,主要是 k8s 內(nèi)部異常發(fā)現(xiàn)時(shí)間以及作業(yè)啟動(dòng)時(shí)間,對(duì)部分業(yè)務(wù)有影響,比如CPS實(shí)時(shí)任務(wù)。如何解決,平臺(tái)端定時(shí)檢測(cè) K8s node 狀態(tài),一旦檢測(cè)到 down 機(jī)狀態(tài),將 node 上面有 JobManager 所屬的任務(wù)停止掉,然后從其之前 checkpoint 恢復(fù);
第四,F(xiàn)link on k8s 非云原生。當(dāng)前通過(guò) Flink Jar 任務(wù)并發(fā)度自動(dòng)檢測(cè)工具解決資源少配無(wú)法啟動(dòng)問題,但是如果任務(wù)的預(yù)執(zhí)行計(jì)劃無(wú)法獲取,就無(wú)法獲取到代碼配置的并發(fā)度。我們的思考是:Flink on k8s 云原生功能以及前面的 1、2 問題,如果社區(qū)支持的比較快速的話,后面可能會(huì)考慮將 Flink 版本與社區(qū)版本對(duì)齊。

9. Flink on K8s的一些方案推薦
第一種方案,是平臺(tái)自己去構(gòu)建和管理任務(wù)的鏡像。
優(yōu)點(diǎn)是:平臺(tái)方對(duì)于構(gòu)建鏡像,以及運(yùn)行實(shí)時(shí)任務(wù)整體流程自我掌控,具體問題能夠及時(shí)修正。
缺點(diǎn)是:需要對(duì) Docker 以及 K8S 相關(guān)技術(shù)要有一定了解,門檻使用比較高,同時(shí)需要考慮非云原生相關(guān)問題。它的適用版本為 Flink 1.6 以上。
第二種方案,F(xiàn)link k8s Operator。
優(yōu)點(diǎn)是:對(duì)用戶整體封裝了很多底層細(xì)節(jié),使用門檻相對(duì)降低一些。 缺點(diǎn)是:整體使用沒有第一種方案那么靈活,一旦有問題,由于底層使用的是其封裝的功能,底層不好修改。它的適用版本為Flink 1.7 以上。 最后一種方案是,基于社區(qū) Flink K8s 功能。
優(yōu)點(diǎn)是:云原生,對(duì)于資源的申請(qǐng)方面更加友好。同時(shí),用戶使用會(huì)更加方便,屏蔽很多底層實(shí)現(xiàn)。 缺點(diǎn)是:K8s 云原生功能還是實(shí)驗(yàn)中的功能,相關(guān)功能還在開發(fā)中,比如 k8s Per job 模式。它的適用版本為Flink 1.10 以上。

二、Flink SQL 實(shí)踐和應(yīng)用
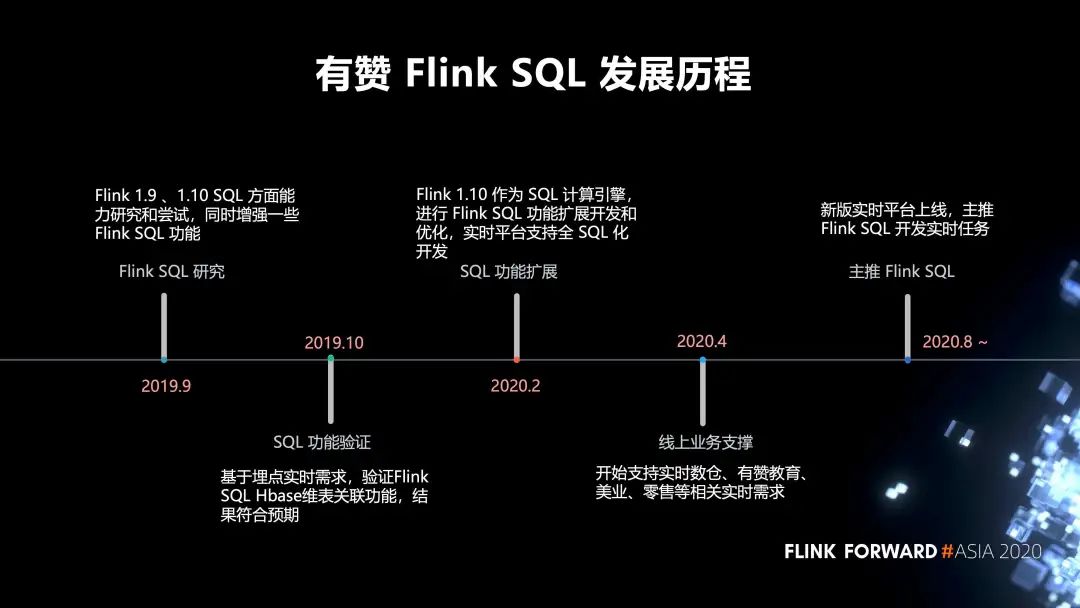
1. 有贊 Flink SQL 的發(fā)展歷程
2019 年 9 月,我們對(duì) Flink 1.9 、1.10 SQL 方面的能力進(jìn)行研究和嘗試,同時(shí)增強(qiáng)了一些 Flink SQL 功能。
2019 年 10 月,我們進(jìn)行了 SQL 功能驗(yàn)證,基于埋點(diǎn)實(shí)時(shí)需求,驗(yàn)證 Flink SQL Hbase 維表關(guān)聯(lián)功能,結(jié)果符合預(yù)期。
2020 年 2 月,我們對(duì) SQL 的功能進(jìn)行了擴(kuò)展,以 Flink 1.10 作為 SQL 計(jì)算引擎,進(jìn)行 Flink SQL 功能擴(kuò)展開發(fā)和優(yōu)化,實(shí)時(shí)平臺(tái)支持全 SQL 化開發(fā)。
2020 年 4 月,開始支持實(shí)時(shí)數(shù)倉(cāng)、有贊教育、美業(yè)、零售等相關(guān)實(shí)時(shí)需求。
2020 年 8 月,新版的實(shí)時(shí)平臺(tái)才開始正式上線,目前主推 Flink SQL 開發(fā)我們的實(shí)時(shí)任務(wù)。
2. 在 Flink SQL 方面的一些實(shí)踐
第一,F(xiàn)link Connector 的實(shí)踐包括:Flink SQL 支持 Flink NSQ Connector、Flink SQL 支持 Flink HA Hbase Sink 和維表、Flink SQL 支持無(wú)密 Mysql Connector、Flink SQL 支持標(biāo)準(zhǔn)輸出(社區(qū)已經(jīng)支持)、Flink SQL 支持 Clickhouse Sink;
第二,平臺(tái)層的實(shí)踐包括:Flink SQL 支持 UDF 以及 UDF 管理、支持任務(wù)從 Checkpoint 恢復(fù)、支持冪等函數(shù)、支持 Json 相關(guān)函數(shù)等、支持 Flink 運(yùn)行相關(guān)參數(shù)配置,比如狀態(tài)時(shí)間設(shè)置,聚合優(yōu)化參數(shù)等等、Flink 實(shí)時(shí)任務(wù)血緣數(shù)據(jù)自動(dòng)化采集、Flink 語(yǔ)法正確性檢測(cè)功能;
第三,F(xiàn)link Runtime的實(shí)踐包括:Flink 源碼增加單個(gè)Task 以及 Operator 單條記錄處理時(shí)間指標(biāo);修復(fù) Flink SQL 可撤回流 TOP N 的BUG。

3. 業(yè)務(wù)實(shí)踐
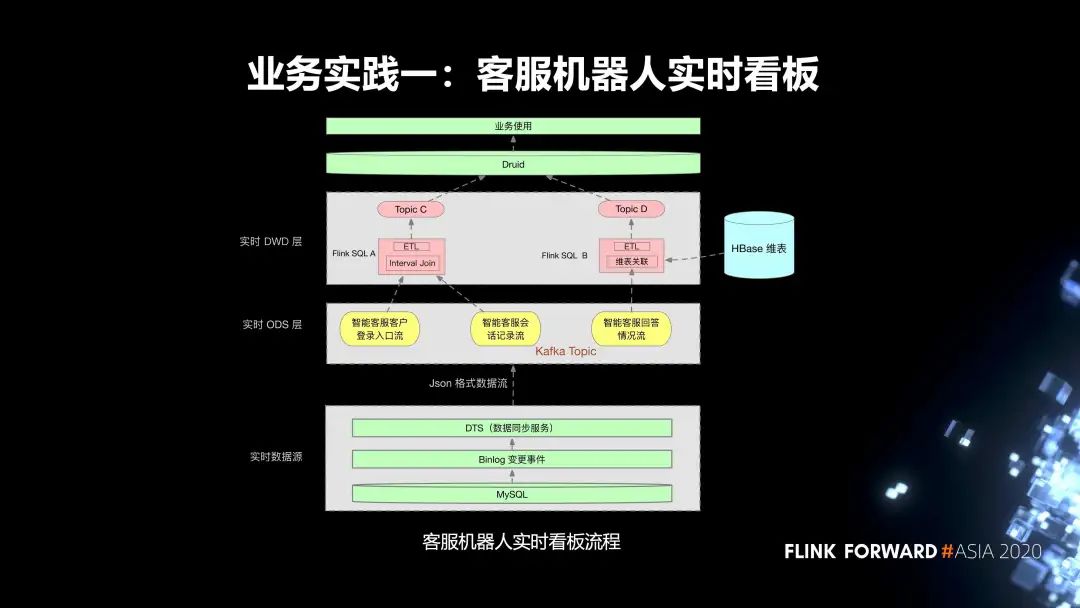
第一個(gè)實(shí)踐是我們內(nèi)部的客服機(jī)器人實(shí)時(shí)看板。流程分為三層:
第一層是實(shí)時(shí)數(shù)據(jù)源,首先是線上的 MySQL 業(yè)務(wù)表,我們會(huì)把它的 Binlog 通過(guò) DTS 服務(wù)同步到相應(yīng)的 Kafka Topic; 實(shí)時(shí)任務(wù)的 ODS 層有三個(gè) Kafka Topic; 在實(shí)時(shí) DWD 層,有兩個(gè) Flink SQL 任務(wù): Flink SQL A 消費(fèi)兩個(gè) topic,然后把這兩個(gè) topic 里面的數(shù)據(jù)去通過(guò) Interval Join,根據(jù)一些窗口的作用關(guān)聯(lián)到對(duì)應(yīng)的數(shù)據(jù)。同時(shí),會(huì)對(duì)這個(gè)實(shí)時(shí)任務(wù)設(shè)置狀態(tài)的保留時(shí)間。Join 之后,會(huì)去進(jìn)行一些 ETL 的加工處理,最終會(huì)把它的數(shù)據(jù)輸入到一個(gè) topic C。 另外一個(gè)實(shí)時(shí)任務(wù) Flink SQL B 消費(fèi)一個(gè) topic,然后會(huì)對(duì) topic 里面的數(shù)據(jù)進(jìn)行清洗,然后到 HBase 里面去進(jìn)行一個(gè)維表的關(guān)聯(lián),去關(guān)聯(lián)它所需要的一些額外的數(shù)據(jù),關(guān)聯(lián)的數(shù)據(jù)最終會(huì)輸入到 topic D。
在上游,Druid 會(huì)消費(fèi)這兩個(gè) topic 的數(shù)據(jù),去進(jìn)行一些指標(biāo)的查詢,最終提供給業(yè)務(wù)方使用。
第二個(gè)實(shí)踐是實(shí)時(shí)用戶行為中間層。用戶在我們平臺(tái)上面會(huì)去搜索、瀏覽、加入購(gòu)物車等等,都會(huì)產(chǎn)生相應(yīng)的事件。原先的方案是基于離線來(lái)做的。我們會(huì)把數(shù)據(jù)落庫(kù)到 Hive 表,然后算法那邊的同學(xué)會(huì)結(jié)合用戶特征、機(jī)器學(xué)習(xí)的模型、離線的數(shù)據(jù)去生成一些用戶評(píng)分預(yù)估,再把它輸入到 HBase。
在這樣的背景下面,會(huì)有如下訴求:當(dāng)前的用戶評(píng)分主要是基于離線任務(wù),而算法同學(xué)希望結(jié)合實(shí)時(shí)的用戶特征,更加及時(shí)、準(zhǔn)確的提高推薦精準(zhǔn)度。這其實(shí)就需要構(gòu)建一個(gè)實(shí)時(shí)的用戶行為中間層,把用戶產(chǎn)生的事件輸入到 Kafka 里面,通過(guò) Flink SQL 作業(yè)對(duì)這些數(shù)據(jù)進(jìn)行處理,然后把相應(yīng)的結(jié)果輸出到 HBase 里面。算法的同學(xué)再結(jié)合算法模型,實(shí)時(shí)的更新模型里面的一些參數(shù),最終實(shí)時(shí)的進(jìn)行用戶的評(píng)分預(yù)估,也會(huì)落庫(kù)到 HBase,然后到線上使用。
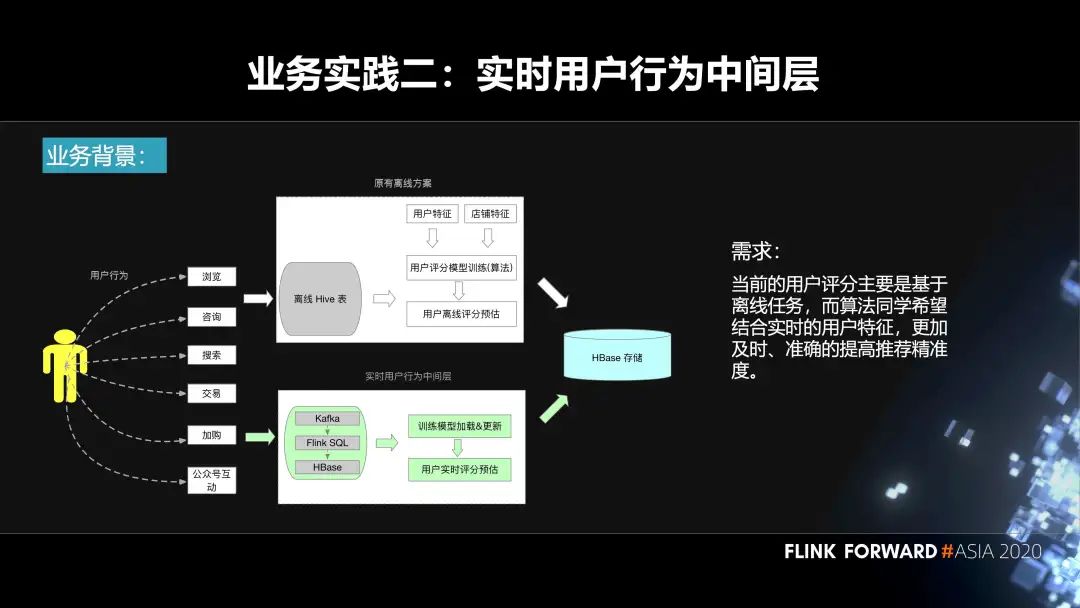
用戶行為中間層的構(gòu)建流程分為三個(gè)步驟:
第一層,我們的數(shù)據(jù)源在 Kafka 里面;
第二層是 ODS 層,在 Flink SQL 作業(yè)里面會(huì)有一些流表的定義,一些 ETL 邏輯的處理。然后去定義相關(guān)的 sink 表、維表等等。這里面也會(huì)有一些聚合的操作,然后輸入到 Kafka;
在 DWS 層,同樣有用戶的 Flink SQL 作業(yè),會(huì)涉及到用戶自己的 UDF Jar,多流 Join,UDF 的使用。然后去讀取 ODS 層的一些數(shù)據(jù),落庫(kù)到 HBase 里面,最終給算法團(tuán)隊(duì)使用。
第一,Kafka Topic、Flink 任務(wù)名稱,F(xiàn)link SQL Table 名稱,按照數(shù)倉(cāng)命名規(guī)范。
第二,指標(biāo)聚合類計(jì)算,F(xiàn)link SQL 任務(wù)要設(shè)置空閑狀態(tài)保留時(shí)間,防止任務(wù)狀態(tài)無(wú)限增大。
第三,如果存在數(shù)據(jù)傾斜或者讀狀態(tài)壓力較大等情況,需要配置 Flink SQL 優(yōu)化參數(shù)。

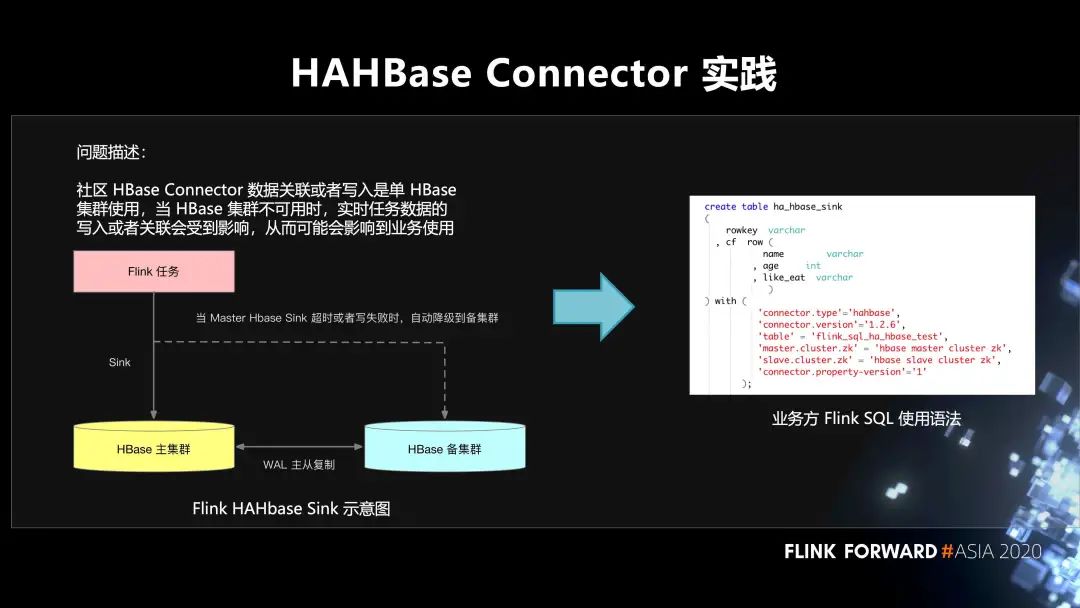
4. 在 HAHBase Connector 的實(shí)踐
5. 無(wú)密 Mysql Connector 和指標(biāo)擴(kuò)展實(shí)踐
第一,Mysql 數(shù)據(jù)庫(kù)用戶名和密碼不以明文方式向外進(jìn)行暴露和存儲(chǔ);
第二,支持 Mysql 用戶名和密碼周期性更新;
第三,內(nèi)部自動(dòng)根據(jù)用戶名鑒定表權(quán)限使用。這樣做最主要的目的還是保證實(shí)時(shí)任務(wù)數(shù)據(jù)庫(kù)使用更安全。

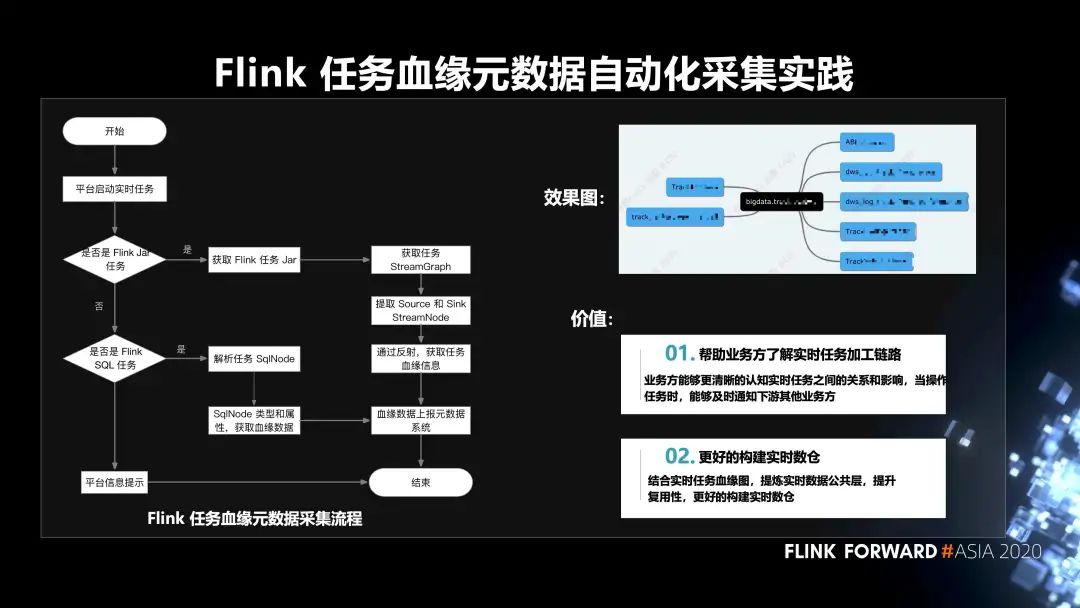
6. Flink 任務(wù)血緣元數(shù)據(jù)自動(dòng)化采集的實(shí)踐
第一,幫助業(yè)務(wù)方了解實(shí)時(shí)任務(wù)加工鏈路。業(yè)務(wù)方能夠更清晰的認(rèn)知實(shí)時(shí)任務(wù)之間的關(guān)系和影響,當(dāng)操作任務(wù)時(shí),能夠及時(shí)通知下游其他業(yè)務(wù)方;
第二,更好的構(gòu)建實(shí)時(shí)數(shù)倉(cāng)。結(jié)合實(shí)時(shí)任務(wù)血緣圖,提煉實(shí)時(shí)數(shù)據(jù)公共層,提升復(fù)用性,更好的構(gòu)建實(shí)時(shí)數(shù)倉(cāng)。
三、未來(lái)規(guī)劃
第一,推廣 Flink 實(shí)時(shí)任務(wù) SQL 化。推廣 Flink SQL 開發(fā)實(shí)時(shí)任務(wù),提升 Flink SQL 任務(wù)比例。
第二,F(xiàn)link 任務(wù)計(jì)算資源自動(dòng)優(yōu)化配置。從內(nèi)存、任務(wù)處理能力、輸入速率等,對(duì)任務(wù)資源進(jìn)行分析,對(duì)資源配置不合理任務(wù)自動(dòng)化配置,從而降低機(jī)器成本。
第三,F(xiàn)link SQL 任務(wù) k8s 化以及 K8s 云原生。Flink 底層計(jì)算資源統(tǒng)一為 k8s,降低運(yùn)維成本,F(xiàn)link k8s 云原生,更合理使用 K8s 資源。
第四,F(xiàn)link 與數(shù)據(jù)湖以及 CDC 功能技術(shù)的調(diào)研。新技術(shù)的調(diào)研儲(chǔ)備,為未來(lái)其他實(shí)時(shí)需求奠定技術(shù)基礎(chǔ)。