
一文全覽 | 模仿學習最新進展
點擊下方卡片,關注「集智書童」公眾號
來源丨專知編輯丨小書童

模仿學習是強化學習與監(jiān)督學習的結合,目標是通過觀察專家演示,學習專家策略,從而加速強化學習。通過引入 任務相關的額外信息,模仿學習相較于強化學習,可以更快地實現(xiàn)策略優(yōu)化,為緩解低樣本效率問題提供了解決方案。近年 來,模仿學習已成為解決強化學習問題的一種流行框架,涌現(xiàn)出多種提高學習性能的算法和技術。通過與圖形圖像學的最新 研究成果相結合,模仿學習已經在游戲 AI (artificial intelligence)、機器人控制、自動駕駛等領域發(fā)揮了重要作用。本綜述圍 繞模仿學習的年度發(fā)展,從行為克隆、逆強化學習、對抗式模仿學習、基于觀察量的模仿學習和跨領域模仿學習等多個角度 進行了深入探討。綜述介紹了模仿學習在實際應用上的最新情況,比較了國內外研究現(xiàn)狀,并展望了該領域未來的發(fā)展方向。報告旨在為研究人員和從業(yè)人員提供模仿學習的最新進展,從而為開展工作提供參考與便利。
http://www.cjig.cn/jig/ch/reader/view_abstract.aspx?flag=2&file_no=202301140000005&journal_id=jig
1. 引言
深度強化學習(deep reinforcement learning,DRL) 有著樣本效率低的問題,通常情況下,智能體為了 解決一個并不復雜的任務,需要遠遠超越人類進行 學習所需的樣本數(shù)。人類和動物天生就有著模仿其 它同類個體的能力,研究表明人類嬰兒在觀察父母 完成一項任務之后,可以更快地學會該項任務 (Meltzoff 等,1999)。基于神經元的研究也表明,一 類被稱為鏡像神經元的神經元,在動物執(zhí)行某一特 定任務和觀察另一個體執(zhí)行該任務的時候都會被激 活(Ferrari 等,2005)。這些現(xiàn)象都啟發(fā)了研究者希望 智能體能通過模仿其它個體的行為來學習策略,因 此模仿學(imitation learning,IL)的概念被提出。模仿 學習通過引入額外的信息,使用帶有傾向性的專家 示范,更快地實現(xiàn)策略優(yōu)化,為緩解樣本低效問題 提供了一種可行的解決途徑。
由于模仿學習較高的實用性,其從誕生以來一 直都是強化學習重要的研究方向。傳統(tǒng)模仿學習方 法主要包括行為克隆(Bain 和 Sammut,1995)、逆強 化學習(Ng 等,2000)、對抗式模仿學習(Ho 和 Ermon, 2016)等,這類方法技術路線相對簡單,框架相對單 一,通常在一些簡單任務上能取得較好效果 (Attia and Dayan,2018;Levine,2018)。隨著近年來計算 能力的大幅提高以及上游圖形圖像任務(如物體識 別、場景理解等)的快速發(fā)展,融合了多種技術的模 仿學習方法也不斷涌現(xiàn),被廣泛應用到了復雜任務, 相關領域的新進展主要包括基于觀察量的模仿學習 (Kidambi 等,2021)、跨領域模仿學習(Raychaudhuri 等,2021;Fickinger 等,2021)等。
基于觀察量的模仿學習(imitation learning from observation,ILfO)放松了對專家示范數(shù)據(jù)的要求, 僅從可被觀察到的專家示范信息(如汽車行駛的視 頻信息)進行模仿學習,而不需要獲得專家的具體 動作數(shù)據(jù)(如人開車的方向盤、油門控制數(shù)據(jù)) (Torabi 等,2019)。這一設定使模仿學習更貼近現(xiàn)實 情況,使相關算法更具備實際運用價值。根據(jù)是否 需要建模任務的環(huán)境狀態(tài)轉移動力學(又稱為“模 型”),ILfO 類算法可以被分為有模型和無模型兩類。其中,有模型方法依照對智能體與環(huán)境交互過程中 構建模型的方式,可以進一步被分為正向動態(tài)模型 (forward dynamics models)(Edwards 等 , 2019 ;Kidambi 等,2021)與逆向動態(tài)模型(inverse dynamics models)(Nair 等,2017;Torabi 等,2018;Guo 等,2019;Radosavovic 等,2021);無模型的方法主要包 括對抗式方法(Merel 等,2017;Stadie 等,2017;Henderson 等,2018) 與獎勵函數(shù)工程法(Gupta 等, 2017;Aytar 等,2018;Schmeckpeper 等,2021)。
跨領域模仿學習(cross domain imitation learning, CDIL)主要聚焦于研究智能體與專家處于不同領域 (例如不同的馬爾可夫決策過程)的模仿學習方法。當前的 CDIL 研究主要聚焦于以下三個方面的領域 差異性(Kim 等,2020):1)狀態(tài)轉移差異(Liu 等, 2019),即環(huán)境的狀態(tài)轉移不同;2)形態(tài)學差異(Gupta 等,2017),即專家與智能體的狀態(tài)、動作空間不同;3)視角差異(Stadie 等,2017;Sharma 等,2019;Zweig 和 Bruna,2020),即專家與智能體的觀察量不同。根據(jù)算法依賴的主要技術路徑,其解決方案主要可 以分為:1)直接法(Taylor 等,2007),該類方法關注 形態(tài)學差異來進行跨領域模仿,通常使用簡單關系 函數(shù)(如線性函數(shù))建立狀態(tài)到狀態(tài)之間的直接對 應關系;2)映射法(Gupta 等,2017;Sermanet 等, 2018;Liu 等,2018),該類方法尋求不同領域間的 深層相似性,利用復雜的非線性函數(shù)(如深度神經 網(wǎng)絡)完成不同任務空間中的信息轉移,實現(xiàn)跨領 域模仿;3)對抗式方法(Sharma 等,2019;Kim 等, 2020),該類方法通常包含專家行為判別器與跨領域 生成器,通過交替求解最小-最大化問題來訓練判別 器和生成器,實現(xiàn)領域信息傳遞;4)最優(yōu)傳輸法 (Papagiannis 和 Li,2020;Dadashi 等,2021;Nguyen 等,2021;Fickinger 等,2021),該類方法聚焦專家 領域專家策略占用測度(occupancy measure)與目標 領域智能體策略占用測度間的跨領域信息轉移,通 過最優(yōu)傳輸度量來構建策略遷移模型。
當前,模仿學習的應用主要集中在游戲 AI、機 器人控制、自動駕駛等智能體控制領域。圖形圖像 學方向的最新研究成果,如目標檢測(Feng 等,2021;Li 等,2022)、視頻理解(Lin 等,2019;Bertasius 等, 2021) 、視頻分類 (Tran 等 , 2019) 、視頻識別 (Feichtenhofer,2020)等,都極大地提升了智能體的 識別、感知能力,是模仿學習取得新進展與新應用 的重要基石。此外,近年來也有研究者開始探索直 接使用 IL 提高圖形/圖像任務的性能,如 3D/2D 模 型與圖像配準(Toth 等,2018)、醫(yī)學影像衰減校正 (Kl?ser 等,2021)、圖像顯著性預測(Xu 等,2021)等。總體來說,模仿學習與圖像處理的有機結合,極大 地拓展了相關領域的科研范圍,為許多困難問題的 解決提供了全新的可能性。
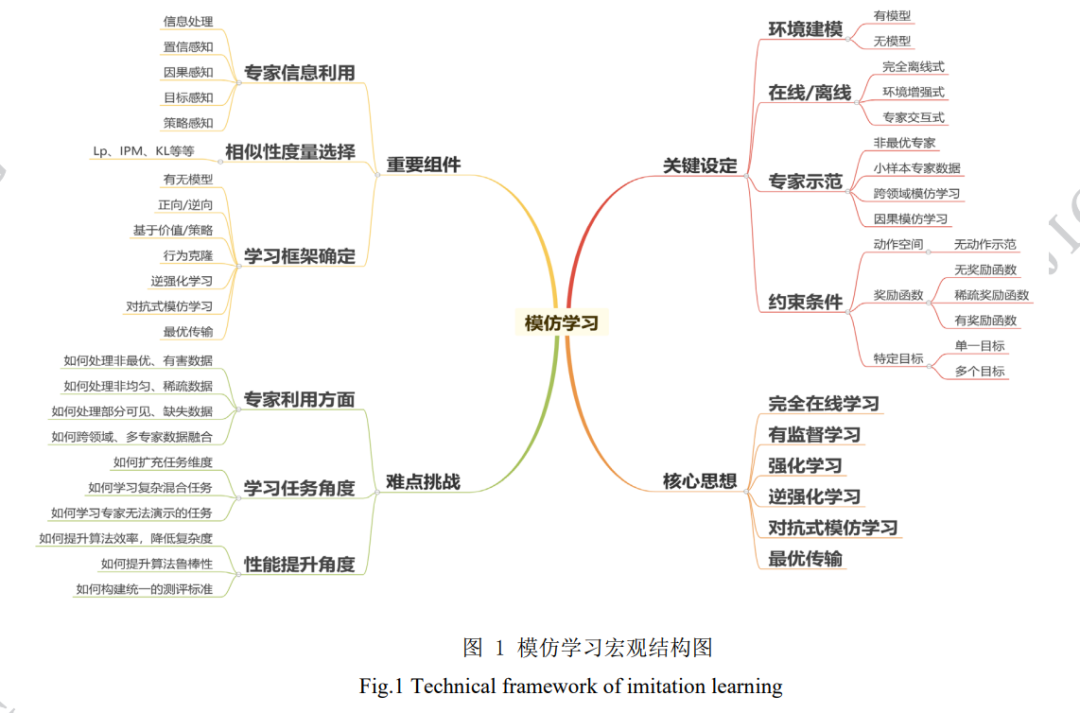
本文的主要內容如下:首先簡要介紹模仿學習 概念,同時回顧必要的基礎知識;然后選取模仿學 習在國際上的主要成果,介紹傳統(tǒng)模仿學習與模仿 學習最新進展,同時也將展現(xiàn)國外最新的研究現(xiàn)狀;接著選取國內高校與機構的研究成果,介紹模仿學 習的具體應用,同時也會比較國內外研究的現(xiàn)狀;最后將總結本文,并展望模仿學習的未來發(fā)展方向 與趨勢,為研究者提供潛在的研究思路。本文是第 一個對模仿學習最新進展(即基于觀察量的模仿學 習與跨領域模仿學習)進行詳細調研的綜述,除本 文以外,(Ghavamzadeh 等,2015;Osa,2018;Attia 和 Dayan,2018;Levine,2018;Arora 和 Doshi, 2021)等文章也對模仿學習的其它細分領域進行了 調研。
2 模仿學習新進展
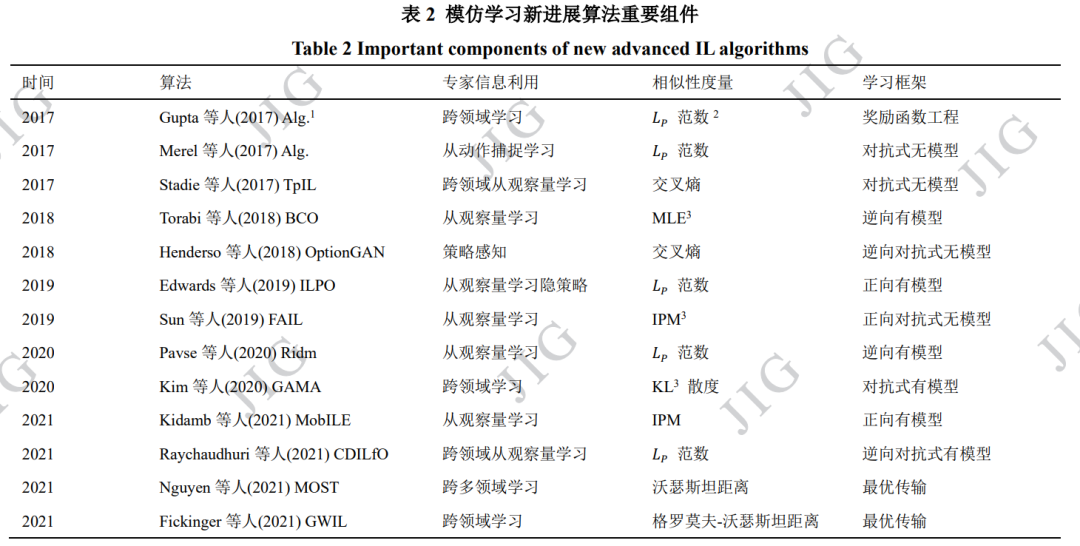
隨著強化學習與模仿學習領域研究的不斷深入, 近些年模仿學習領域的研究取得了一些矚目的新進 展,相關的研究不再局限于理論分析與模擬環(huán)境, 而是轉向更貼近實際的方向,例如:基于觀察量的 模仿學習(2.1 節(jié)),跨領域模仿學習(2.2 節(jié))。在 這些領域的許多工作,考慮了使用實際數(shù)據(jù)集進行 模仿學習訓練;同時其目標也并非局限于完成 Gym 等模擬環(huán)境上提供的標準任務,而是進一步轉向模 仿學習算法在機器人控制、自動駕駛等領域的實際 應用,為“模擬到現(xiàn)實”做出了堅實的推進。
2.1 基于觀察量的模仿學習
當智能體試圖僅通過“觀察”來模仿專家的策略 時,就會出現(xiàn)基于觀察量的模仿學習(Imitation Learning from Observation,ILfO)這一任務(Torabi 等, 2019)。所謂的“觀察”,指的是僅包含狀態(tài)信息而不 包含動作信息的專家示范,它可以是僅包含狀態(tài)信 息的軌跡???????? = {????????}????=1 ???? ,也可以是單純的圖片或視頻。相較于傳統(tǒng)模仿學習中既可以獲得專家所處的狀態(tài), 又可以獲得專家在當前狀態(tài)下的策略(動作)的設 定,ILfO 放松了對專家示范數(shù)據(jù)的要求,從而成為 了一種更貼近現(xiàn)實情況、更具備實際運用價值的設 定。值得注意的是,ILfO 可以直接使用專家行為的 圖片數(shù)據(jù)作為輸入(Liu 等,2018;Torabi 等,2019;Karnan 等,2022),這在引入海量數(shù)據(jù)集的同時,也 將模仿學習與圖像圖形學、計算機視覺等領域有機 地結合起來,從而極大地拓展了相關領域的潛在研 究方向,為相關領域的進一步發(fā)展開辟了新的土壤。
IL 的目標類似,ILfO 的目標是讓智能體通 過模仿僅包含狀態(tài)信息的專家示范數(shù)據(jù),輸出一個具有相同行為的策略。既然 ILfO 是一種更貼近現(xiàn)實 的設定,如何從現(xiàn)實的專家行為中獲得示范數(shù)據(jù)是 首先要解決的問題。一些早期的工作通過直接在專 家身上設置傳感器的方式記錄專家的行為數(shù)據(jù) (Ijspeert 等,2001;Calinon 和 Billard,2007)。上述 方法的升級版本是采用動作捕捉技術,專家需要佩 戴專業(yè)的動作捕捉設備,這樣做的好處是計算機系 統(tǒng)可以直接對專家的行為進行 3 維建模,從而轉換 成模擬系統(tǒng)易于識別的輸入(Field 等,2009;Merel 等,2017)。隨著前些年卷積神經網(wǎng)絡在處理圖像數(shù) 據(jù)上大放異彩,現(xiàn)在較為常見的是直接使用攝像頭 拍攝專家行為,進而直接使用圖像、視頻數(shù)據(jù)作為 輸入(Liu 等,2018;Sharma 等,2019;orabi 等,2019;Karnan 等,2022)。由于 ILfO 無法獲得專家動作,因此將專家動作 視為狀態(tài)標簽的方法將不再適用,這也使得 ILfO 變 成了更具挑戰(zhàn)的任務。一般來說,基于 ILfO 設定的 算法可以被分為有模型和無模型兩類。所謂的“模 型”,一般指的是環(huán)境的狀態(tài)轉移,通過對智能體與 環(huán)境交互過程中學習模型的方式作區(qū)分,可以進一 步將有模型的方法分為:正向動態(tài)模型(forward dynamics models)與逆向動態(tài)模型(inverse dynamics models);無模型的方法主要包括:對抗式方法與獎 勵函數(shù)工程法。
2.2 跨領域模仿學習
跨領域模仿學習(cross domain imitation learning, CDIL)相關領域的研究最早可以追溯到機器人控制 領域通過觀察來讓機器人學習策略(Kuniyoshi 等, 1994;Argall 等,2009)。后來隨著對 ILfO(章節(jié) 2.1) 研究的深入,CDIL 的相關研究也越來越受重視。與 傳統(tǒng)設定下的 IL 相比,跨領域模仿學習與現(xiàn)實世界 中的學習過程兼容性更好(Raychaudhuri 等,2021)。傳統(tǒng)的 IL 假設智能體和專家在完全相同的環(huán)境中 決策,而這一要求幾乎只可能在模擬系統(tǒng)(包括游戲) 中得到滿足。這一缺點嚴重地限制了傳統(tǒng) IL 在現(xiàn)實 生活中可能的應用場景,并且將研究者的工作的重心轉移到對場景的準確建模,而并非算法本身的性 能上。CDIL 的產生打破了這一枷鎖,因為智能體可 以使用不同于自身領域的專家示范來學習策略。當 前 CDIL 所研究的領域差異主要集中在以下三個方 面(Kim 等,2020):1)狀態(tài)轉移差異(Liu 等,2019);2)形態(tài)學差異(Gupta 等,2017);3)視角差異(Stadie 等,2017;Sharma 等,2019;Zweig 和 Bruna,2020)。這些差異也對應第 2.1 章中提及的 ILfO 所面臨的挑 戰(zhàn)。
在模仿學習變得為人熟知之前,這一研究領域 更廣泛地被稱為遷移學習(Taylor 等,2008)。例如, Konidaris 等人(2006)通過在任務之間共享的狀態(tài)表 示子集上學習價值函數(shù),來為目標任務提供塑性后 獎勵。Taylor 等人(2007)人工設計了一個可以將某一 MDP 對應的動作價值函數(shù)轉移到另一 MDP 中的映 射來實現(xiàn)知識遷移。直觀地說,為了克服智能體環(huán) 境和專家環(huán)境之間的差異,需要在它們之間建立一 個轉移或映射。Taylor 等人 (2008)介紹了一種“直接 映射”的方法,來直接學習狀態(tài)到狀態(tài)之間的映射關 系。然而,在不同領域中建立狀態(tài)之間的直接映射 只能提供有限的轉移,因為兩個形態(tài)學上不同的智 能體之間通常沒有完整的對應關系,但這種方法卻 不得不學習從一個狀態(tài)空間到另一個狀態(tài)空間的映 射(Gupta 等,2017),從而導致該映射關系是病態(tài)的。早期的這些方法,大多都需要特定領域的知識,或 是人工構建不同空間之間的映射,這通常會使研究 變得繁瑣且泛化性較差,因此必須借助更為先進的 算法來提升性能。隨著深度神經網(wǎng)絡的發(fā)展,更具表達性的神經 網(wǎng)絡被廣泛運用,CDIL 也迎來了較快的發(fā)展。(Gupta 等,2017;Sermanet 等,2018;Liu 等,2018) 等文章研究機器人從視頻觀察中學習策略,為了解 決專家示范與智能體所處領域不同的問題,他們的 方法借助不同領域間成對的、時間對齊的示范來獲 得狀態(tài)之間對應關系,并且這些方法通常涉及與環(huán) 境進行交互的 RL 步驟。相較于“直接映射”的方法, 這些方法學習的映射并不是簡單的狀態(tài)對之間的關 系,而更多利用了神經網(wǎng)絡強大的表達性能,從而 取得更好的實驗效果。但不幸的是,成對且時間對 齊的數(shù)據(jù)集很難獲得,從而降低了該種方法的可實現(xiàn)性(Kim 等,2020)。
3 模仿學習應用
隨著基于觀察量的模仿學習與跨領域模仿學習 的不斷發(fā)展,基于 IL 的算法也越來越符合現(xiàn)實場景 的應用要求,此外,圖形圖像學上的諸多最新研究 成果,也為 IL 的現(xiàn)實應用進一步賦能。模仿學習的 主要應用領域包括但不限于:1)游戲 AI;2)機器人 控制;3)自動駕駛;4)圖像圖形學等。本章節(jié)將列舉 有代表性的模仿學習應用類工作,同時由于現(xiàn)階段 國內關于模仿學習的研究主要集中在應用領域,因 此本章節(jié)將著重選取國內高校、機構的工作成果, 進而為國內該領域的研究者提供一些參考。Gym(Brockman 等,2016)與 Mujoco(Todorov 等, 2012)是強化學習領域被最廣泛使用的訓練環(huán)境,其 為強化學習領域的研究提供了標準環(huán)境與基準任務, 使得不同的算法能在相同的設定下比較性能的優(yōu)劣。模仿學習作為強化學習最為熱門的分支領域,也廣 泛使用 Gym 與 Mujoco 作為訓練/測試環(huán)境。Gym 包 含多個基礎游戲環(huán)境以及雅達利游戲環(huán)境,Mujoco 包含多個智能體控制環(huán)境同時支持自建任務。值得 注意的是,Gym 與 Mujoco 都包含大量的圖像環(huán)境, 即以圖像的形式承載環(huán)境的全部信息,這就使得圖 像圖形學的眾多最新成果,直接推動了模仿學習的 應用。考慮到 Gym 與 Mujoco 的虛擬仿真特性,可 將其歸類為游戲環(huán)境。這些使用 Gym 與 Mujoco 進 行訓練或驗證的模仿學習算法,都能在一定程度上 推廣到其他游戲領域的應用。國內的諸多高校都在 該方面做出了自己的貢獻,包括 清華大學的 Yang 等人(2019)探究了基于逆向動態(tài)模型的 IL 算法性能, Jing 等人(2021)驗證了分層模仿學習的性能;上海交 通大學的 M.Liu 等人(2020)探究基于能量的模仿學 習算法性能,Liu 等人(2021)探究離線模仿學習算法 COIL(curriculum offline imitation learning)的性能, Liu等人(2022)探究通過解耦策略優(yōu)化進行模仿學習。南京大學的 Zhang 等人(2022)探究生成式對抗模仿 學習的性能,Xu 等人(2020) 探究模仿策略的誤差界 限,Jiang 等人(2020) 探究帶誤差的模擬器中的離線 模仿學習。
Gym 與 Mujoco 環(huán)境之外,模仿學習也被廣 泛用于訓練棋類與即時戰(zhàn)略類游戲 AI。這類游戲任 務的難度顯著增加,且通常包含較大信息量的圖像數(shù)據(jù),因此也會更依賴于先進的圖像處理方法(例如 目標檢測)。對于這些復雜游戲環(huán)境,狀態(tài)動作空間 過于龐大,獎勵信息過于稀疏,智能體通常無法直 接通過強化學習獲得策略。進而,智能體首先通過 模仿人類選手的對局示范來學習較為基礎的策略, 然后使用強化學習與自我博弈等方式進一步提升策 略。其中最為代表的就是 Google 公司開發(fā)的圍棋游 戲 AI AlphaGo(Silver 等,2016)以及星際爭霸AI Alphastar(Vinyals 等,2019)。與國外的情況相似國內工業(yè)界也十分重視該類游戲 AI 的開發(fā),包括 騰 訊公司開發(fā)的王者榮耀(復雜的多智能體對抗環(huán)境) 游戲 AI(Ye 等,2020);華為公司基于多模式對抗模 仿學習開發(fā)的即時戰(zhàn)略游戲 AI(Fei 等,2020),如圖 3 所示。考慮到該類游戲的超高復雜性,人工智能在 如此復雜的任務中完勝人類對手,可以預見人工智 能在游戲領域完全超越人類已經只是時間問題。在機器人控制領域,由于機器人的價格昂貴, 部件易損且可能具備一定危險性,因此需要一種穩(wěn) 定的方式獲得策略,模仿學習讓機器人直接模仿專 家的行為,可以快速、穩(wěn)定地使其掌握技能,而不依 賴于過多的探索。斯坦福大學的 Abbeel 等人(2006), 早在 2006 年就將逆強化學習方法用在直升機控制 任務上(如圖 4 所示)。加州大學伯克利分校的 Nair 等人(2017),結合自監(jiān)督學習與模仿學習的方法,讓 機器人通過模仿專家行為的視頻數(shù)據(jù),學習完成簡 單的任務(如圖 5 所示)。國內高校也在該領域做出 了一定的貢獻,包括 清華大學的 Fang 等人(2019)調 研了模仿學習在機器人操控方面的研究。中國科學 院大學的 Jiayi Li 等人(2021)通過視頻數(shù)據(jù)進行元模 仿學習以控制機器(如圖 6 所示)。中科院自動化所 的 Y. Li 等人(2021)通過視頻數(shù)據(jù)進行模仿學習以精 確操控機器手臂的位置。
自動駕駛是當前人工智能最重要的應用領域 (Grigorescu 等,2020;Kiran 等,2021),模仿學習憑 借其優(yōu)秀的性能也在該領域占據(jù)一席之地,特別是 基于觀察量的模仿學習與跨領域模仿學習兼容自動 駕駛的絕大部分現(xiàn)實需求,從而使得 IL 在該領域大 放異彩(Codevilla 等,2018;Bhattacharyya 等,2018Liang 等,2018;Chen 等,2019;Kebria 等,2019;Pan 等,2020)。國內的高校與企業(yè)也十分重視模仿 學習在自動駕駛領域的研究,包括 清華大學的 Wu 等人(2018)結合模仿學習進行水下無人設備訓練。浙 江大學的 Li 等人(2020)探究了用于視覺導航的基于 無監(jiān)督強化學習的可轉移元技能;Wang 等人(2021) 探究從分層的駕駛模型中進行模仿學習(如圖 7 所 示);百度公司的 Zhou 等人(2021)使用模仿學習實現(xiàn) 自動駕駛。北京大學的 Zhu 等人(2021)關于深度強 化學習與模仿學習在自動駕駛領域的應用作了綜述。事實上,近年來模仿學習也被直接用于圖像處 理上,在圖形圖像領域發(fā)揮出獨特的價值。Toth 等 人(2018)探究模仿學習在心臟手術的 3D/2D 模型與 圖像配準上的應用。Kl?ser 等人(2021)研究模仿學習 在改進3D PET/MR(positron emission tomography and magnetic resonance)衰減校正上的應用。北京航天航 空大學的Xu等人(2021)探究了生成對抗模仿學習在 全景圖像顯著性預測上的應用。在其它領域,模仿學習也有著廣泛的應用,包 括電子有限集模型預測控制系統(tǒng) (Novak 和 Dragicevic,2021)、云機器人系統(tǒng)(B. Liu 等,2020)、 異構移動平臺的動態(tài)資源管理(Mandal 等,2019)、 多智能體合作環(huán)境中的應用(Hao 等,2019)、信息檢 索(Dai 等,2021)、移動通信信息時效性(Wang 等, 2022)、黎曼流形(Zeestraten 等,2017)、運籌學 (Ingimundardottir 和 Runarsson,2018)、緩存替換(Liu 等,2020)等。


掃碼加入??「集智書童」交流群
(備注:方向+學校/公司+昵稱)




前沿AI視覺感知全棧知識??「分類、檢測、分割、關鍵點、車道線檢測、3D視覺(分割、檢測)、多模態(tài)、目標跟蹤、NerF」
歡迎掃描上方二維碼,加入「集智書童-知識星球」,日常分享論文、學習筆記、問題解決方案、部署方案以及全棧式答疑,期待交流!