
一文速覽機器學(xué)習(xí)的類別(Python代碼)
序列文章:上一篇 《白話機器學(xué)習(xí)概念》
一、 機器學(xué)習(xí)類別
機器學(xué)習(xí)按照學(xué)習(xí)數(shù)據(jù)經(jīng)驗的不同,即訓(xùn)練數(shù)據(jù)的標(biāo)簽信息的差異,可以分為監(jiān)督學(xué)習(xí)(supervised learning)、非監(jiān)督學(xué)習(xí)(unsupervised learning)、半監(jiān)督學(xué)習(xí)(semi- supervised learning)和強化學(xué)習(xí)(reinforcement learning)。
1.1 監(jiān)督學(xué)習(xí)
監(jiān)督學(xué)習(xí)是機器學(xué)習(xí)中應(yīng)用最廣泛及成熟的,它是從有標(biāo)簽的數(shù)據(jù)樣本(x,y)中,學(xué)習(xí)如何關(guān)聯(lián)x到正確的y。這過程就像是模型在給定題目的已知條件(特征x),參考著答案(標(biāo)簽y)學(xué)習(xí),借助標(biāo)簽y的監(jiān)督糾正,模型通過算法不斷調(diào)整自身參數(shù)以達到學(xué)習(xí)目標(biāo)。
監(jiān)督學(xué)習(xí)常用的模型有:線性回歸、樸素貝葉斯、K最近鄰、邏輯回歸、支持向量機、神經(jīng)網(wǎng)絡(luò)、決策樹、集成學(xué)習(xí)(如LightGBM)等。按照應(yīng)用場景,以模型預(yù)測結(jié)果Y的取值有限或者無限的,可再進一步分為分類或者回歸模型。
分類模型
分類模型是處理預(yù)測結(jié)果取值有限的分類任務(wù)。如下示例通過邏輯回歸分類模型,根據(jù)溫濕度、風(fēng)速等情況去預(yù)測是否會下雨。
邏輯回歸簡介
邏輯回歸雖然名字有帶“回歸”,但其實它是一種廣義線性的分類模型,由于模型簡單和高效,在實際中應(yīng)用非常廣泛。
邏輯回歸模型結(jié)構(gòu)可以視為雙層的神經(jīng)網(wǎng)絡(luò)(如圖4.5)。模型輸入x,通過神經(jīng)元激活函數(shù)f(f為sigmoid函數(shù))將輸入非線性轉(zhuǎn)換至0~1的取值輸出,最終學(xué)習(xí)的模型決策函數(shù)為Y=sigmoid(wx + b)
。其中模型參數(shù)w即對應(yīng)各特征(x1, x2, x3...)的權(quán)重(w1,w2,w3...),b模型參數(shù)代表著偏置項,Y為預(yù)測結(jié)果(0~1范圍)。
模型的學(xué)習(xí)目標(biāo)為極小化交叉熵損失函數(shù)。模型的優(yōu)化算法常用梯度下降算法去迭代求解損失函數(shù)的極小值,得到較優(yōu)的模型參數(shù)。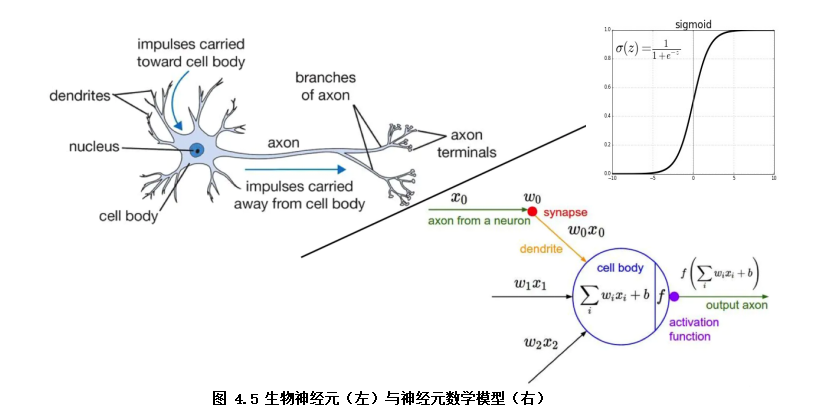
代碼示例 示例所用天氣數(shù)據(jù)集是簡單的天氣情況記錄數(shù)據(jù),包括室外溫濕度、風(fēng)速、是否下雨等,在分類任務(wù)中,我們以是否下雨作為標(biāo)簽,其他為特征(如圖4.6) 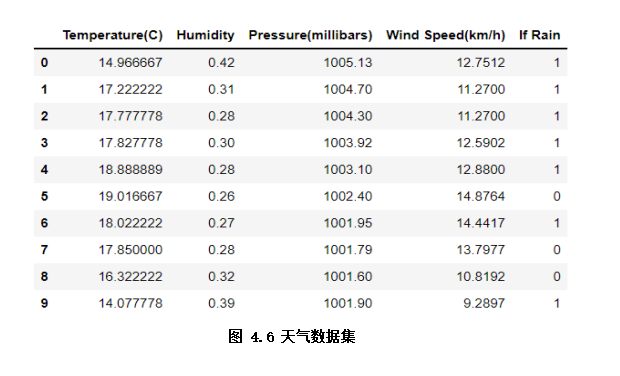
import pandas as pd # 導(dǎo)入pandas庫
weather_df = pd.read_csv('./data/weather.csv') # 加載天氣數(shù)據(jù)集
weather_df.head(10) # 顯示數(shù)據(jù)的前10行
from sklearn.linear_model import LogisticRegression # 導(dǎo)入邏輯回歸模型
x = weather_df.drop('If Rain', axis=1) # 特征x
y = weather_df['If Rain'] # 標(biāo)簽y
lr = LogisticRegression()
lr.fit(x, y) # 模型訓(xùn)練
print("前10個樣本預(yù)測結(jié)果:", lr.predict(x[0:10]) ) # 模型預(yù)測前10個樣本并輸出結(jié)果
以訓(xùn)練的模型輸出前10個樣本預(yù)測結(jié)果為:[1 1 1 1 1 1 0 1 1 1],對比實際前10個樣本的標(biāo)簽:[1 1 1 1 1 0 1 0 0 1],預(yù)測準(zhǔn)確率并不高。在后面章節(jié)我們會具體介紹如何評估模型的預(yù)測效果,以及進一步優(yōu)化模型效果。
回歸模型
回歸模型是處理預(yù)測結(jié)果取值無限的回歸任務(wù)。如下代碼示例通過線性回歸模型,以室外濕度為標(biāo)簽,根據(jù)溫度、風(fēng)力、下雨等情況預(yù)測室外濕度。
線性回歸簡介 線性回歸模型前提假設(shè)是y和x呈線性關(guān)系,輸入x,模型決策函數(shù)為Y=wx+b。模型的學(xué)習(xí)目標(biāo)為極小化均方誤差損失函數(shù)。模型的優(yōu)化算法常用最小二乘法求解最優(yōu)的模型參數(shù)。 代碼示例
from sklearn.linear_model import LinearRegression #導(dǎo)入線性回歸模型
x = weather_df.drop('Humidity', axis=1) # 特征x
y = weather_df['Humidity'] # 標(biāo)簽y
linear = LinearRegression()
linear.fit(x, y) # 模型訓(xùn)練
print("前10個樣本預(yù)測結(jié)果:", linear.predict(x[0:10]) ) # 模型預(yù)測前10個樣本并輸出結(jié)果
# 前10個樣本預(yù)測結(jié)果: [0.42053525 0.32811401 0.31466161 0.3238797 0.29984453 0.29880059
1.2 非監(jiān)督學(xué)習(xí)
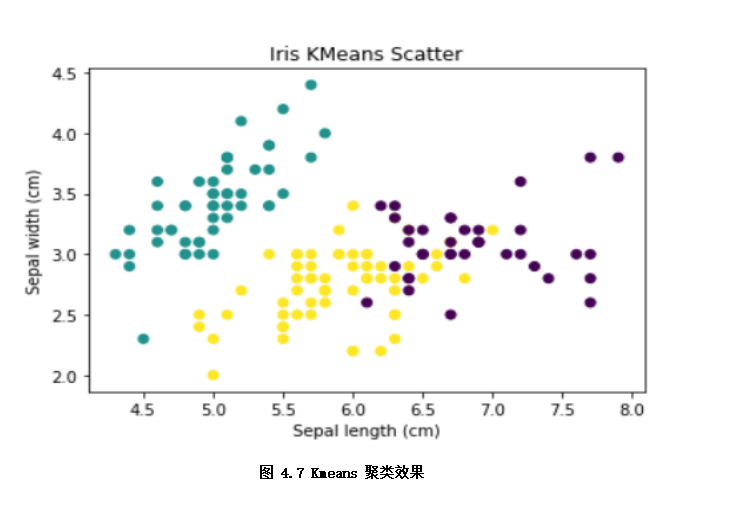
非監(jiān)督學(xué)習(xí)也是機器學(xué)習(xí)中應(yīng)用較廣泛的,是從無標(biāo)注的數(shù)據(jù)(x)中,學(xué)習(xí)數(shù)據(jù)的內(nèi)在規(guī)律。這個過程就像模型在沒有人提供參考答案(y),完全通過自己琢磨題目的知識點,對知識點進行歸納、總結(jié)。按照應(yīng)用場景,非監(jiān)督學(xué)習(xí)可以分為聚類,特征降維和關(guān)聯(lián)分析等方法。如下示例通過Kmeans聚類劃分出不同品種的iris鳶尾花樣本。
Kmeans聚類簡介 Kmeans聚類是非監(jiān)督學(xué)習(xí)常用的方法,其原理是先初始化k個簇類中心,通過迭代算法更新各簇類樣本,實現(xiàn)樣本與其歸屬的簇類中心的距離最小的目標(biāo)。其算法步驟為:1.初始化:隨機選擇 k 個樣本作為初始簇類中心(可以憑先驗知識、驗證法確定k的取值);2.針對數(shù)據(jù)集中每個樣本 計算它到 k 個簇類中心的距離,并將其歸屬到距離最小的簇類中心所對應(yīng)的類中;3.針對每個簇類 ,重新計算它的簇類中心位置;4.重復(fù)上面 2 、3 兩步操作,直到達到某個中止條件(如迭代次數(shù),簇類中心位置不變等)
代碼示例
from sklearn.datasets import load_iris # 數(shù)據(jù)集
from sklearn.cluster import KMeans # Kmeans模型
import matplotlib.pyplot as plt # plt畫圖
lris_df = datasets.load_iris() # 加載iris鳶尾花數(shù)據(jù)集,數(shù)據(jù)集有150條樣本,分三類的iris品種
x = lris_df.data
k = 3 # 聚類出k個簇類, 已知數(shù)據(jù)集有三類品種, 設(shè)定為3
model = KMeans(n_clusters=k)
model.fit(x) # 訓(xùn)練模型
print("前10個樣本聚類結(jié)果:",model.predict(x[0:10]) ) # 模型預(yù)測前10個樣本并輸出聚類結(jié)果:[1 1 1 1 1 1 1 1 1 1]
# 樣本的聚類效果以散點圖展示
x_axis = lris_df.data[:,0] # 以iris花的sepal length (cm)特征作為x軸
y_axis = lris_df.data[:,1] # 以iris花的sepal width (cm)特征作為y軸
plt.scatter(x_axis, y_axis, c=model.predict(x)) # 分標(biāo)簽顏色展示聚類效果
plt.xlabel('Sepal length (cm)')#設(shè)定x軸注釋
plt.ylabel('Sepal width (cm)')#設(shè)定y軸注釋
plt.title('Iris KMeans Scatter')
plt.show() # 如圖4.7聚類效果
1.3半監(jiān)督學(xué)習(xí)
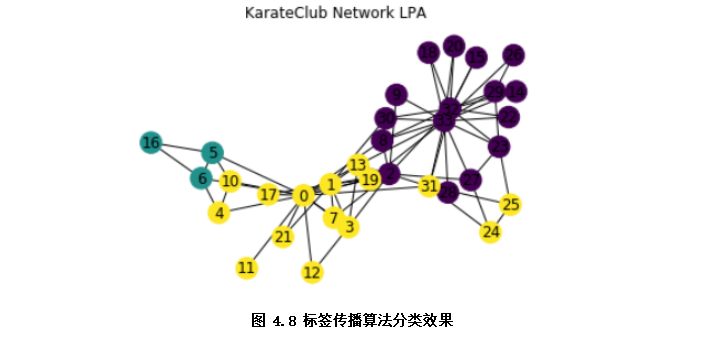
半監(jiān)督學(xué)習(xí)是介于傳統(tǒng)監(jiān)督學(xué)習(xí)和無監(jiān)督學(xué)習(xí)之間(如圖4.8),其思想是在有標(biāo)簽樣本數(shù)量較少的情況下,以一定的假設(shè)前提在模型訓(xùn)練中引入無標(biāo)簽樣本,以充分捕捉數(shù)據(jù)整體潛在分布,改善如傳統(tǒng)無監(jiān)督學(xué)習(xí)過程盲目性、監(jiān)督學(xué)習(xí)在訓(xùn)練樣本不足導(dǎo)致的學(xué)習(xí)效果不佳的問題。按照應(yīng)用場景,半監(jiān)督學(xué)習(xí)可以分為聚類,分類及回歸等方法。如下示例通過基于圖的半監(jiān)督算法——標(biāo)簽傳播算法分類俱樂部成員。

標(biāo)簽傳播算法簡介
標(biāo)簽傳播算法(LPA)是基于圖的半監(jiān)督學(xué)習(xí)分類算法,基本思路是在所有樣本組成的圖網(wǎng)絡(luò)中,從已標(biāo)記的節(jié)點標(biāo)簽信息來預(yù)測未標(biāo)記的節(jié)點標(biāo)簽。
首先利用樣本間的關(guān)系(可以是樣本客觀關(guān)系,或者利用相似度函數(shù)計算樣本間的關(guān)系)建立完全圖模型。
接著向圖中加入已標(biāo)記的標(biāo)簽信息(或無),無標(biāo)簽節(jié)點是用一個隨機的唯一的標(biāo)簽初始化。
將一個節(jié)點的標(biāo)簽設(shè)置為該節(jié)點的相鄰節(jié)點中出現(xiàn)頻率最高的標(biāo)簽,重復(fù)迭代,直到標(biāo)簽不變即算法收斂。
代碼示例該示例的數(shù)據(jù)集空手道俱樂部是一個被廣泛使用的社交網(wǎng)絡(luò),其中的節(jié)點代表空手道俱樂部的成員,邊代表成員之間的相互關(guān)系。
import networkx as nx # 導(dǎo)入networkx圖網(wǎng)絡(luò)庫
import matplotlib.pyplot as plt
from networkx.algorithms import community # 圖社區(qū)算法
G=nx.karate_club_graph() # 加載美國空手道俱樂部圖數(shù)據(jù)
#注: 本例未使用已標(biāo)記信息, 嚴(yán)格來說是半監(jiān)督算法的無監(jiān)督應(yīng)用案例
lpa = community.label_propagation_communities(G) # 運行標(biāo)簽傳播算法
community_index = {n: i for i, com in enumerate(lpa) for n in com} # 各標(biāo)簽對應(yīng)的節(jié)點
node_color = [community_index[n] for n in G] # 以標(biāo)簽作為節(jié)點顏色
pos = nx.spring_layout(G) # 節(jié)點的布局為spring型
nx.draw_networkx_labels(G, pos) # 節(jié)點序號
nx.draw(G, pos, node_color=node_color) # 分標(biāo)簽顏色展示圖網(wǎng)絡(luò)
plt.title(' Karate_club network LPA')
plt.show() #展示分類效果,不同顏色為不同類別
1.4 強化學(xué)習(xí)
強化學(xué)習(xí)從某種程度可以看作是有延遲標(biāo)簽信息的監(jiān)督學(xué)習(xí)(如圖4.9),是指智能體Agent在環(huán)境Environment中采取一種行為action,環(huán)境將其轉(zhuǎn)換為一次回報reward和一種狀態(tài)表示state,隨后反饋給智能體的學(xué)習(xí)過程。本書中對強化學(xué)習(xí)僅做簡單介紹,有興趣可以自行擴展。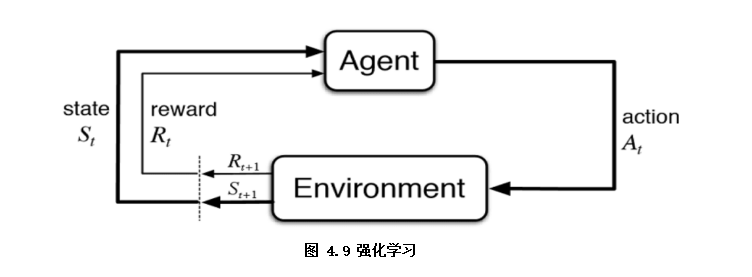
文章首發(fā)于算法進階,公眾號閱讀原文可訪問GitHub項目源碼