
機器學(xué)習(xí)中XGBoost算法調(diào)參技巧
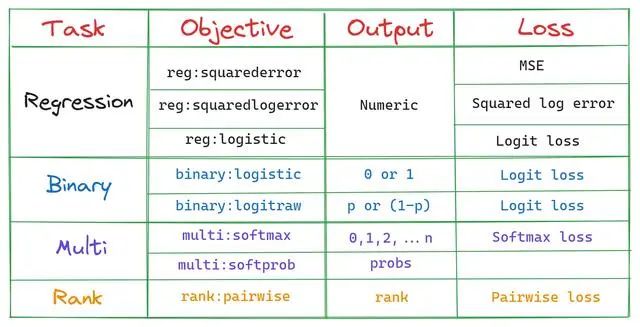 本文將詳細解釋XGBoost中十個最常用超參數(shù)的介紹,功能和值范圍,及如何使用Optuna進行超參數(shù)調(diào)優(yōu)。 對于XGBoost來說,默認的超參數(shù)是可以正常運行的,但是如果你想獲得最佳的效果,那么就需要自行調(diào)整一些超參數(shù)來匹配你的數(shù)據(jù),以下參數(shù)對于XGBoost非常重要:
本文將詳細解釋XGBoost中十個最常用超參數(shù)的介紹,功能和值范圍,及如何使用Optuna進行超參數(shù)調(diào)優(yōu)。 對于XGBoost來說,默認的超參數(shù)是可以正常運行的,但是如果你想獲得最佳的效果,那么就需要自行調(diào)整一些超參數(shù)來匹配你的數(shù)據(jù),以下參數(shù)對于XGBoost非常重要:
-
eta -
num_boost_round -
max_depth -
subsample -
colsample_bytree -
gamma -
min_child_weight -
lambda -
alpha
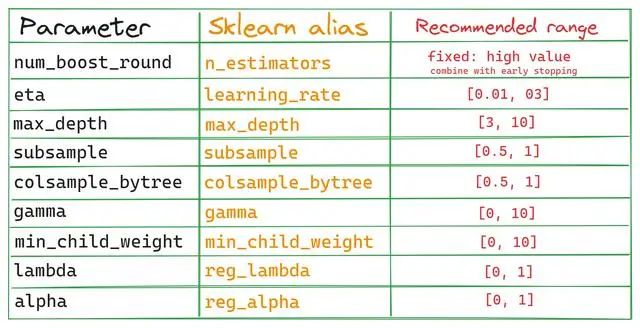 如果想使用Optuna以外的超參數(shù)調(diào)優(yōu)工具,可以參考該表。下圖是這些參數(shù)對之間的相互作用:
如果想使用Optuna以外的超參數(shù)調(diào)優(yōu)工具,可以參考該表。下圖是這些參數(shù)對之間的相互作用:
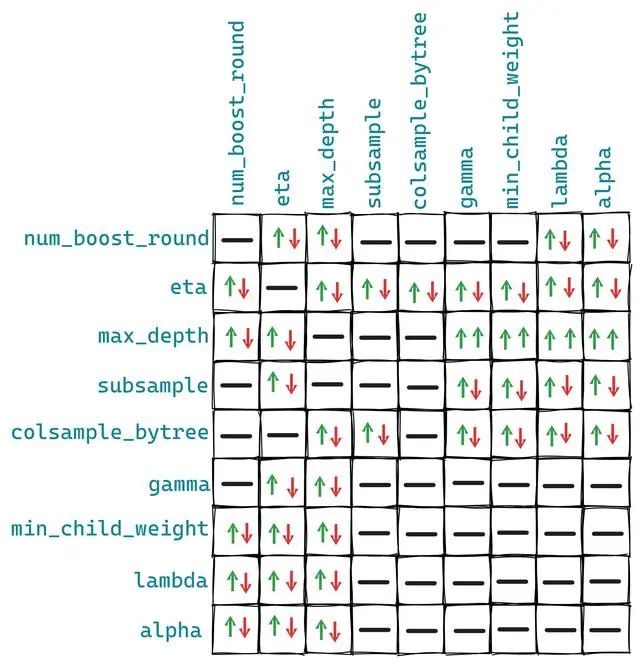 這些關(guān)系不是固定的,但是大概情況是上圖的樣子,因為有一些其他參數(shù)可能會對我們的者10個參數(shù)有額外的影響。 1、objective 這是我們模型的訓(xùn)練目標
最簡單的解釋是,這個參數(shù)指定我們模型要做的工作,也就是影響決策樹的種類和損失函數(shù)。 2、num_boost_round - n_estimators num_boost_round指定訓(xùn)練期間確定要生成的決策樹(在XGBoost中通常稱為基礎(chǔ)學(xué)習(xí)器)的數(shù)量。默認值是100,但對于今天的大型數(shù)據(jù)集來說,這還遠遠不夠。 增加參數(shù)可以生成更多的樹,但隨著模型變得更復(fù)雜,過度擬合的機會也會顯著增加。 從Kaggle中學(xué)到的一個技巧是為num_boost_round設(shè)置一個高數(shù)值,比如100,000,并利用早停獲得最佳版本。 在每個提升回合中,XGBoost會生成更多的決策樹來提高前一個決策樹的總體得分。這就是為什么它被稱為boost。這個過程一直持續(xù)到num_boost_round輪詢?yōu)橹梗还苁欠癖壬弦惠営兴倪M。 但是通過使用早停技術(shù),我們可以在驗證指標沒有提高時停止訓(xùn)練,不僅節(jié)省時間,還能防止過擬合 有了這個技巧,我們甚至不需要調(diào)優(yōu)num_boost_round。下面是它在代碼中的樣子:
這些關(guān)系不是固定的,但是大概情況是上圖的樣子,因為有一些其他參數(shù)可能會對我們的者10個參數(shù)有額外的影響。 1、objective 這是我們模型的訓(xùn)練目標
最簡單的解釋是,這個參數(shù)指定我們模型要做的工作,也就是影響決策樹的種類和損失函數(shù)。 2、num_boost_round - n_estimators num_boost_round指定訓(xùn)練期間確定要生成的決策樹(在XGBoost中通常稱為基礎(chǔ)學(xué)習(xí)器)的數(shù)量。默認值是100,但對于今天的大型數(shù)據(jù)集來說,這還遠遠不夠。 增加參數(shù)可以生成更多的樹,但隨著模型變得更復(fù)雜,過度擬合的機會也會顯著增加。 從Kaggle中學(xué)到的一個技巧是為num_boost_round設(shè)置一個高數(shù)值,比如100,000,并利用早停獲得最佳版本。 在每個提升回合中,XGBoost會生成更多的決策樹來提高前一個決策樹的總體得分。這就是為什么它被稱為boost。這個過程一直持續(xù)到num_boost_round輪詢?yōu)橹梗还苁欠癖壬弦惠営兴倪M。 但是通過使用早停技術(shù),我們可以在驗證指標沒有提高時停止訓(xùn)練,不僅節(jié)省時間,還能防止過擬合 有了這個技巧,我們甚至不需要調(diào)優(yōu)num_boost_round。下面是它在代碼中的樣子:
# Define the rest of the params上面的代碼使XGBoost生成100k決策樹,但是由于使用了早停,當(dāng)驗證分數(shù)在最后50輪中沒有提高時,它將停止。一般情況下樹的數(shù)量范圍在5000-10000即可。控制num_boost_round也是影響訓(xùn)練過程運行時間的最大因素之一,因為更多的樹需要更多的資源。 3、eta - learning_rate 在每一輪中,所有現(xiàn)有的樹都會對給定的輸入返回一個預(yù)測。例如,五棵樹可能會返回以下對樣本N的預(yù)測:
params = {...}
# Build the train/validation sets
dtrain_final = xgb.DMatrix(X_train, label=y_train)
dvalid_final = xgb.DMatrix(X_valid, label=y_valid)
bst_final = xgb.train(
params,
dtrain_final,
num_boost_round=100000 # Set a high number
evals=[(dvalid_final, "validation")],
early_stopping_rounds=50, # Enable early stopping
verbose_eval=False,
)
Tree 1: 0.57 Tree 2: 0.9 Tree 3: 4.25 Tree 4: 6.4 Tree 5: 2.1為了返回最終的預(yù)測,需要對這些輸出進行匯總,但在此之前XGBoost使用一個稱為eta或?qū)W習(xí)率的參數(shù)縮小或縮放它們。縮放后最終輸出為:
output = eta * (0.57 + 0.9 + 4.25 + 6.4 + 2.1)大的學(xué)習(xí)率給集合中每棵樹的貢獻賦予了更大的權(quán)重,但這可能會導(dǎo)致過擬合/不穩(wěn)定,會加快訓(xùn)練時間。而較低的學(xué)習(xí)率抑制了每棵樹的貢獻,使學(xué)習(xí)過程更慢但更健壯。這種學(xué)習(xí)率參數(shù)的正則化效應(yīng)對復(fù)雜和有噪聲的數(shù)據(jù)集特別有用。學(xué)習(xí)率與num_boost_round、max_depth、subsample和colsample_bytree等其他參數(shù)呈反比關(guān)系。較低的學(xué)習(xí)率需要較高的這些參數(shù)值,反之亦然。但是一般情況下不必擔(dān)心這些參數(shù)之間的相互作用,因為我們將使用自動調(diào)優(yōu)找到最佳組合。 4、subsample和colsample_bytree 子抽樣subsample它將更多的隨機性引入到訓(xùn)練中,從而有助于對抗過擬合。Subsample =0.7意味著集合中的每個決策樹將在隨機選擇的70%可用數(shù)據(jù)上進行訓(xùn)練。值1.0表示將使用所有行(不進行子抽樣)。與subsample類似,也有colsample_bytree。顧名思義,colsample_bytree控制每個決策樹將使用的特征的比例。Colsample_bytree =0.8使每個樹使用每個樹中隨機80%的可用特征(列)。調(diào)整這兩個參數(shù)可以控制偏差和方差之間的權(quán)衡。使用較小的值降低了樹之間的相關(guān)性,增加了集合中的多樣性,有助于提高泛化和減少過擬合。但是它們可能會引入更多的噪聲,增加模型的偏差。而使用較大的值會增加樹之間的相關(guān)性,降低多樣性并可能導(dǎo)致過擬合。 5、max_depth 最大深度max_depth控制決策樹在訓(xùn)練過程中可能達到的最大層次數(shù)。
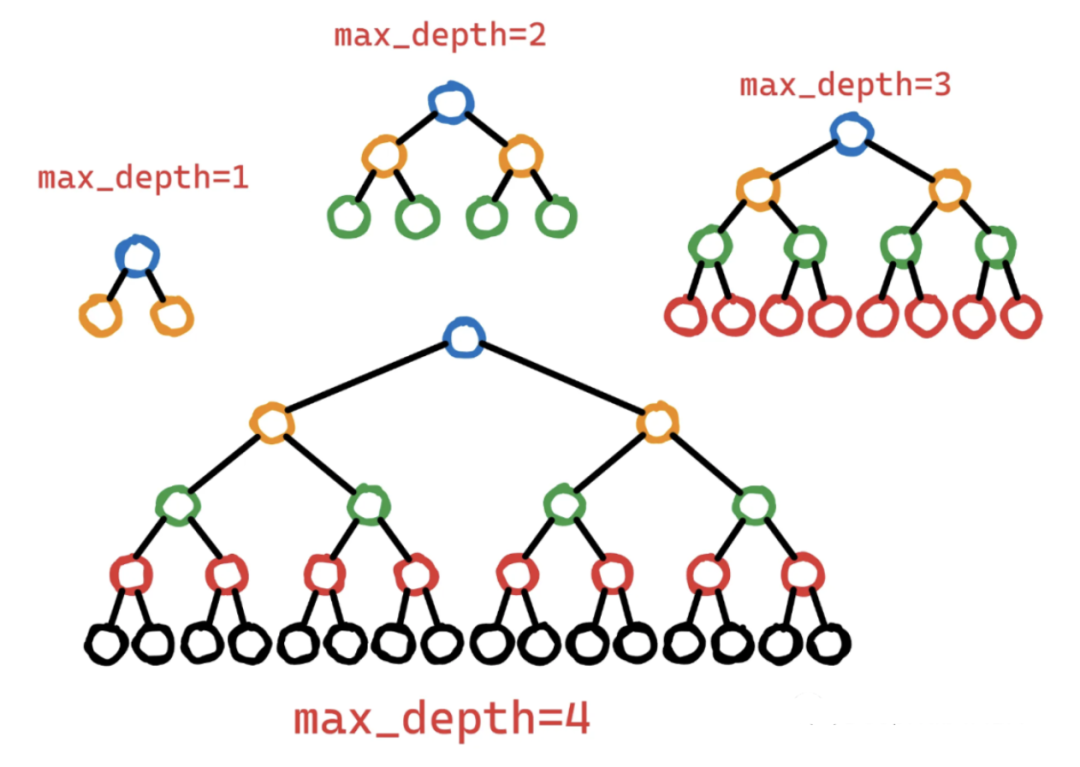 更深的樹可以捕獲特征之間更復(fù)雜的相互作用。但是更深的樹也有更高的過擬合風(fēng)險,因為它們可以記住訓(xùn)練數(shù)據(jù)中的噪聲或不相關(guān)的模式。為了控制這種復(fù)雜性,可以限制max_depth,從而生成更淺、更簡單的樹,并捕獲更通用的模式。Max_depth數(shù)值可以很好地平衡了復(fù)雜性和泛化。 6、7、alpha,lambda 這兩個參數(shù)一起說是因為alpha (L1)和lambda (L2)是兩個幫助過擬合的正則化參數(shù)。與其他正則化參數(shù)的區(qū)別在于,它們可以將不重要或不重要的特征的權(quán)重縮小到0(特別是alpha),從而獲得具有更少特征的模型,從而降低復(fù)雜性。alpha和lambda的效果可能受到max_depth、subsample和colsample_bytree等其他參數(shù)的影響。更高的alpha或lambda值可能需要調(diào)整其他參數(shù)來補償增加的正則化。例如,較高的alpha值可能受益于較大的subsample值,因為這樣可以保持模型多樣性并防止欠擬合。 8、gamma 如果你讀過XGBoost文檔,它說gamma是:在樹的葉節(jié)點上進行進一步分區(qū)所需的最小損失減少。英文原文:the minimum loss reduction required to make a further partition on a leaf node of the tree.我覺得除了寫這句話的人,其他人都看不懂。讓我們看看它到底是什么,下面是一個兩層決策樹:
更深的樹可以捕獲特征之間更復(fù)雜的相互作用。但是更深的樹也有更高的過擬合風(fēng)險,因為它們可以記住訓(xùn)練數(shù)據(jù)中的噪聲或不相關(guān)的模式。為了控制這種復(fù)雜性,可以限制max_depth,從而生成更淺、更簡單的樹,并捕獲更通用的模式。Max_depth數(shù)值可以很好地平衡了復(fù)雜性和泛化。 6、7、alpha,lambda 這兩個參數(shù)一起說是因為alpha (L1)和lambda (L2)是兩個幫助過擬合的正則化參數(shù)。與其他正則化參數(shù)的區(qū)別在于,它們可以將不重要或不重要的特征的權(quán)重縮小到0(特別是alpha),從而獲得具有更少特征的模型,從而降低復(fù)雜性。alpha和lambda的效果可能受到max_depth、subsample和colsample_bytree等其他參數(shù)的影響。更高的alpha或lambda值可能需要調(diào)整其他參數(shù)來補償增加的正則化。例如,較高的alpha值可能受益于較大的subsample值,因為這樣可以保持模型多樣性并防止欠擬合。 8、gamma 如果你讀過XGBoost文檔,它說gamma是:在樹的葉節(jié)點上進行進一步分區(qū)所需的最小損失減少。英文原文:the minimum loss reduction required to make a further partition on a leaf node of the tree.我覺得除了寫這句話的人,其他人都看不懂。讓我們看看它到底是什么,下面是一個兩層決策樹:
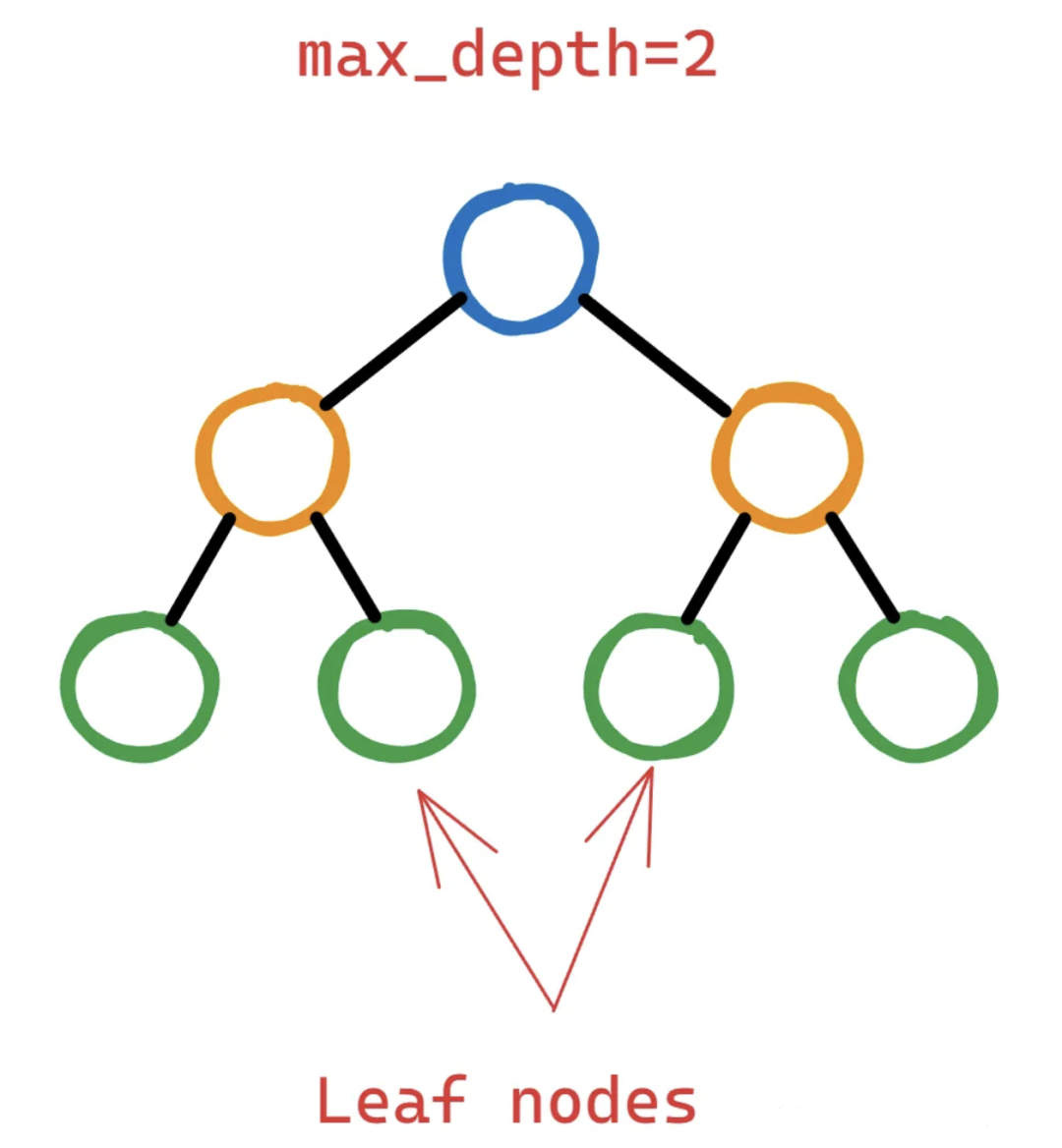 為了證明通過拆分葉節(jié)點向樹中添加更多層是合理的,XGBoost應(yīng)該計算出該操作能夠顯著降低損失函數(shù)。但“顯著是多少呢?”這就是gamma——它作為一個閾值來決定一個葉節(jié)點是否應(yīng)該進一步分割。如果損失函數(shù)的減少(通常稱為增益)在潛在分裂后小于選擇的伽馬,則不執(zhí)行分裂。這意味著葉節(jié)點將保持不變,并且樹不會從該點開始生長。所以調(diào)優(yōu)的目標是找到導(dǎo)致?lián)p失函數(shù)最大減少的最佳分割,這意味著改進的模型性能。 9、min_child_weight XGBoost從具有單個根節(jié)點的單個決策樹開始初始訓(xùn)練過程。該節(jié)點包含所有訓(xùn)練實例(行)。然后隨著 XGBoost 選擇潛在的特征和分割標準最大程度地減少損失,更深的節(jié)點將包含越來越少的實例。
為了證明通過拆分葉節(jié)點向樹中添加更多層是合理的,XGBoost應(yīng)該計算出該操作能夠顯著降低損失函數(shù)。但“顯著是多少呢?”這就是gamma——它作為一個閾值來決定一個葉節(jié)點是否應(yīng)該進一步分割。如果損失函數(shù)的減少(通常稱為增益)在潛在分裂后小于選擇的伽馬,則不執(zhí)行分裂。這意味著葉節(jié)點將保持不變,并且樹不會從該點開始生長。所以調(diào)優(yōu)的目標是找到導(dǎo)致?lián)p失函數(shù)最大減少的最佳分割,這意味著改進的模型性能。 9、min_child_weight XGBoost從具有單個根節(jié)點的單個決策樹開始初始訓(xùn)練過程。該節(jié)點包含所有訓(xùn)練實例(行)。然后隨著 XGBoost 選擇潛在的特征和分割標準最大程度地減少損失,更深的節(jié)點將包含越來越少的實例。
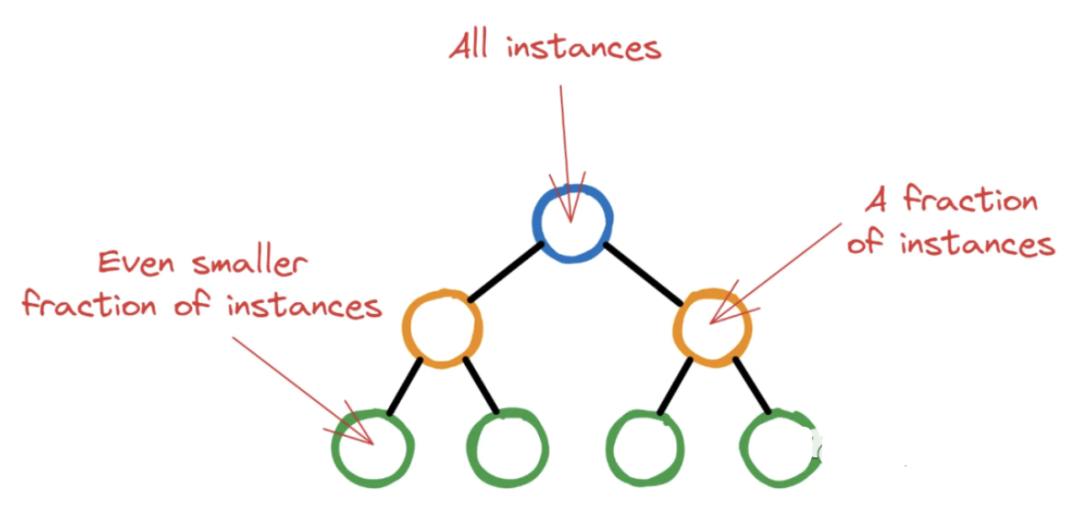 如果讓XGBoost任意運行,樹可能會長到最后節(jié)點中只有幾個無關(guān)緊要的實例。這種情況是非常不可取的,因為這正是過度擬合的定義。所以XGBoost為每個節(jié)點中繼續(xù)分割的最小實例數(shù)設(shè)置一個閾值。通過對節(jié)點中的所有實例進行加權(quán),并找到權(quán)重的總和,如果這個最終權(quán)重小于min_child_weight,則分裂停止,節(jié)點成為葉節(jié)點。上面解釋是對整個過程的最簡化的版本,因為我們主要介紹他的概念。 總結(jié) 以上就是我們對這 10個重要的超參數(shù)的解釋,如果你想更深入的了解仍有很多東西需要學(xué)習(xí)。所以建議給ChatGPT以下兩個提示:
如果讓XGBoost任意運行,樹可能會長到最后節(jié)點中只有幾個無關(guān)緊要的實例。這種情況是非常不可取的,因為這正是過度擬合的定義。所以XGBoost為每個節(jié)點中繼續(xù)分割的最小實例數(shù)設(shè)置一個閾值。通過對節(jié)點中的所有實例進行加權(quán),并找到權(quán)重的總和,如果這個最終權(quán)重小于min_child_weight,則分裂停止,節(jié)點成為葉節(jié)點。上面解釋是對整個過程的最簡化的版本,因為我們主要介紹他的概念。 總結(jié) 以上就是我們對這 10個重要的超參數(shù)的解釋,如果你想更深入的了解仍有很多東西需要學(xué)習(xí)。所以建議給ChatGPT以下兩個提示:
1) Explain the {parameter_name} XGBoost parameter in detail and how to choose values for it wisely.
2) Describe how {parameter_name} fits into the step-by-step tree-building process of XGBoost.
它肯定比我講的明白,對吧。最后如果你也用optuna進行調(diào)優(yōu),請參考以下的GIST:
https://gist.github.com/BexTuychiev/823df08d2e3760538e9b931d38439a68
作者:Bex T.
機器學(xué)習(xí)算法與Python實戰(zhàn)P1:搭建完美的環(huán)境
機器學(xué)習(xí)算法與Python實戰(zhàn)P2:Python基礎(chǔ)
機器學(xué)習(xí)算法與Python實戰(zhàn)P3:Numpy基礎(chǔ)
可能是全網(wǎng)最全的速查表:Python Numpy Pandas Matplotlib 機器學(xué)習(xí) ChatGPT等
評論
圖片
表情