
梯度提升樹算法原理小結(jié)
點(diǎn)擊上方“小白學(xué)視覺(jué)”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)

本文轉(zhuǎn)自|機(jī)器學(xué)習(xí)算法那些事
前言
本文介紹了boosting族的提升樹算法和梯度提升(GBDT)算法,GBDT算法常用來(lái)解決回歸和分類問(wèn)題,且泛化能力很強(qiáng),本文深入淺出的總結(jié)了GBDT算法 。
目錄
1. 單決策樹與提升樹算法的不同
3. 提升樹算法
4. GBDT算法
5. GBDT常用損失函數(shù)
6. GBDT的正則化
7. GBDT與AdaBoost的模型比較
8. 總結(jié)
決策樹與提升樹的不同
決策樹是單一學(xué)習(xí)器,提升樹是以CART決策樹為基本學(xué)習(xí)器的提升方法。本節(jié)從結(jié)果評(píng)價(jià)角度和損失函數(shù)角度去描述兩者的不同。假設(shè)決策樹的學(xué)習(xí)器模型是 f(x),提升樹共有K個(gè)弱學(xué)習(xí)器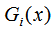 ,其中 i=1,2,...,K。
,其中 i=1,2,...,K。
1.結(jié)果評(píng)價(jià)方法:
對(duì)某一個(gè)輸入數(shù)據(jù)xi
決策樹模型的輸出結(jié)果 yi:
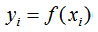
提升樹模型的輸出結(jié)果 yi:
若是回歸:
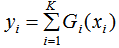
若是分類:
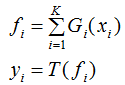
其中,i 表示某一個(gè)弱學(xué)習(xí)器,T代表分類模型(如邏輯線性回歸,或sign函數(shù))
2. 模型構(gòu)建方法
(1)決策樹模型構(gòu)建方法
決策樹運(yùn)用基尼指數(shù)來(lái)計(jì)算模型的損失函數(shù),決策樹生成階段是最小化模型的損失函數(shù),最大化決策樹的深度;決策樹剪枝階段是采用正則化的損失函數(shù)來(lái)完成,最后通過(guò)交叉驗(yàn)證法選擇最佳子樹;
(2)提升樹模型構(gòu)建方法
提升樹是多個(gè)決策樹組合為強(qiáng)學(xué)習(xí)器的提升方法,每個(gè)決策樹的復(fù)雜度比單一決策樹低得多,因此不能像單一決策樹那樣最大化決策樹深度來(lái)最小化損失函數(shù)。決策樹是boosting族的成員,弱學(xué)習(xí)器是串行迭代生成的,通過(guò)最小化每一步的弱學(xué)習(xí)器損失函數(shù)來(lái)構(gòu)建提升樹模型。
提升樹算法
提升樹算法的基本學(xué)習(xí)器是決策樹,且提升樹算法是加法模型,因此,提升樹模型可以表示為:
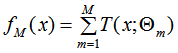
其中,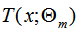 表示決策樹,
表示決策樹,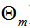 表示決策樹的參數(shù),M為樹的個(gè)數(shù)。
表示決策樹的參數(shù),M為樹的個(gè)數(shù)。
提升樹算法:
提升樹算法采用前向分布算法,假設(shè)初始提升樹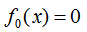 ,第m步的模型是:
,第m步的模型是:
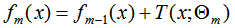
其中,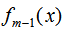 為上一個(gè)模型,通過(guò)經(jīng)驗(yàn)風(fēng)險(xiǎn)極小化確定當(dāng)前模型的參數(shù)
為上一個(gè)模型,通過(guò)經(jīng)驗(yàn)風(fēng)險(xiǎn)極小化確定當(dāng)前模型的參數(shù)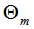 ,
,
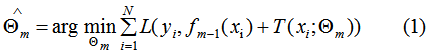
其中L表示損失函數(shù),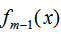 和
和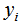 為常數(shù),由(1)式可知,我們只要知道損失函數(shù)L,我們就能得到每一輪的模型參數(shù),也可以理解為用當(dāng)前模型
為常數(shù),由(1)式可知,我們只要知道損失函數(shù)L,我們就能得到每一輪的模型參數(shù),也可以理解為用當(dāng)前模型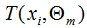 去擬合上一輪模型的殘差。因此,提升樹算法原理是用當(dāng)前的決策樹去擬合上一輪的模型殘差,使當(dāng)前的損失函數(shù)值最小。
去擬合上一輪模型的殘差。因此,提升樹算法原理是用當(dāng)前的決策樹去擬合上一輪的模型殘差,使當(dāng)前的損失函數(shù)值最小。
【例】假如有個(gè)人30歲,我們首先用20歲去擬合發(fā)現(xiàn)損失有10歲,這時(shí)我們用6歲去擬合,這樣迭代下去,直到損失函數(shù)達(dá)到我們的要求,這就是提升樹的思想。
大家有沒(méi)有想過(guò),為什么我們不直接去用30歲去擬合,這么做的步驟相當(dāng)于最大化該決策樹的深度,得到的模型不是一個(gè)弱分類器,導(dǎo)致過(guò)擬合問(wèn)題的出現(xiàn)。
GBDT算法
我們?cè)俅位仡櫳弦还?jié)例題,如果我們首先用10歲去擬合發(fā)現(xiàn)損失有20歲,然后再用8歲去擬合損失有12歲,這樣迭代下去,與上節(jié)達(dá)到相同的損失函數(shù)值則需要更多的迭代次數(shù),這就是GBDT算法思想:用損失函數(shù)負(fù)梯度近似殘差,回歸樹擬合負(fù)梯度得到本輪的最小損失函數(shù)。因?yàn)樘嵘龢涫侵苯訑M合殘差,所以達(dá)到相同的損失函數(shù)值時(shí),提升樹需要的迭代步驟要小得多。
步驟:
(1)用損失函數(shù)的負(fù)梯度近似殘差,表示為:
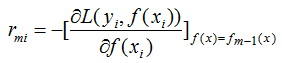
(2) 回歸樹擬合負(fù)梯度,得到葉節(jié)點(diǎn)區(qū)域Rmj,j=1,2,...,J。其中J為葉節(jié)點(diǎn)個(gè)數(shù),m為第m顆回歸樹。
(3) 針對(duì)每一個(gè)葉子節(jié)點(diǎn)里的樣本,我們求出使損失函數(shù)最小,得到擬合葉子節(jié)點(diǎn)最好的輸出值Cmj,如下:
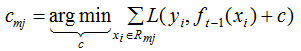
(4)更新回歸樹模型:
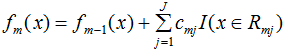
(5)得到最終的回歸樹模型:
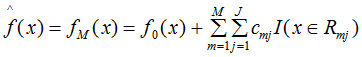
可能最難理解的是第三步,我們可以理解為在負(fù)梯度方向上去求模型最小化。負(fù)梯度方向理解成損失函數(shù)負(fù)梯度的回歸樹劃分規(guī)則,用該規(guī)則去求損失函數(shù)最小化。
假設(shè)損失函數(shù)曲線如下圖:
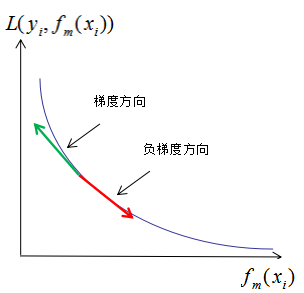
其中,m表示迭代次數(shù),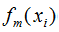 表示共迭代m輪后的學(xué)習(xí)模型,
表示共迭代m輪后的學(xué)習(xí)模型,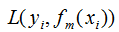 表示模型的損失函數(shù),由提升樹的原理可知,模型的損失函數(shù)隨著迭代次數(shù)的增加而降低。如上圖,梯度和負(fù)梯度分別為綠色線和紅色線,當(dāng)我們用當(dāng)前的學(xué)習(xí)模型沿著負(fù)梯度方向增加時(shí),損失函數(shù)是下降最快的,因此,GBDT算法思想是可行的。
表示模型的損失函數(shù),由提升樹的原理可知,模型的損失函數(shù)隨著迭代次數(shù)的增加而降低。如上圖,梯度和負(fù)梯度分別為綠色線和紅色線,當(dāng)我們用當(dāng)前的學(xué)習(xí)模型沿著負(fù)梯度方向增加時(shí),損失函數(shù)是下降最快的,因此,GBDT算法思想是可行的。
PS:李航老師《統(tǒng)計(jì)學(xué)習(xí)方法》P152的GBDT算法表達(dá)式:
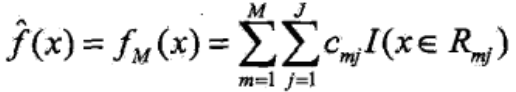
個(gè)人覺(jué)得下式的模型表示法可能會(huì)更好:
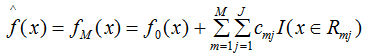
GBDT常用損失函數(shù)
由上面兩節(jié)可知,提升樹是用決策樹去擬合上一輪的損失函數(shù),GBDT是用決策樹去擬合上一輪損失函數(shù)的梯度。因此,只要知道模型的損失函數(shù),就能通過(guò)前向分布算法計(jì)算每輪弱學(xué)習(xí)器模型的參數(shù),本節(jié)總結(jié)了GBDT常用的損失函數(shù)。
(1)分類算法
a) 指數(shù)損失函數(shù):
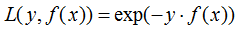
對(duì)應(yīng)負(fù)梯度:
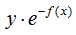
b) 對(duì)數(shù)損失函數(shù)
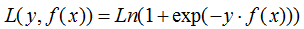
對(duì)應(yīng)負(fù)梯度:
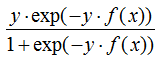
(2)回歸算法
這里不討論最常用的損失函數(shù),如均方差和絕對(duì)損失函數(shù)。本節(jié)介紹對(duì)異常點(diǎn)有較好魯棒性的Huber損失和分位數(shù)損失。
a) Huber損失函數(shù):它是均方差和絕對(duì)損失的折衷產(chǎn)物,對(duì)于遠(yuǎn)離中心的異常點(diǎn),采用絕對(duì)損失,而中心附近的點(diǎn)采用均方差。這個(gè)界限一般用分位數(shù)點(diǎn)度量。損失函數(shù)如下:
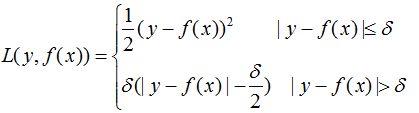
對(duì)應(yīng)的負(fù)梯度:
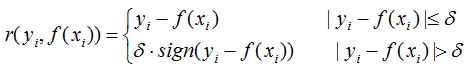
b) 分位數(shù)損失。它對(duì)應(yīng)的是分位數(shù)回歸的損失函數(shù),表達(dá)式為
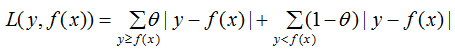
其中,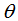 為分位數(shù),需要在回歸前設(shè)置,對(duì)應(yīng)的負(fù)梯度:
為分位數(shù),需要在回歸前設(shè)置,對(duì)應(yīng)的負(fù)梯度:
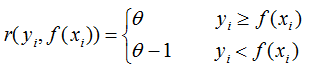
GBDT正則化
正則化是為了防止模型處于過(guò)擬合,GBDT的正則化主要有三種方式:
(1)GBDT是加法模型,因此,模型可表示為:
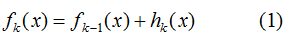
加上正則化項(xiàng)v,則有:
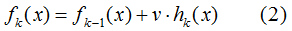
v的取值范圍為:0< v ≤ 1。達(dá)到同樣的訓(xùn)練集學(xué)習(xí)效果,(2)式需要更多的迭代次數(shù),即(2)式模型的復(fù)雜度較小。
(2) 對(duì)訓(xùn)練集進(jìn)行無(wú)放回抽樣,抽樣比例為 v(0 < v ≤ 1)。取部分樣本去做GBDT決策樹的擬合可以降低方差,但是會(huì)增加偏差。
(3) 對(duì)每輪擬合的損失函數(shù)梯度的回歸樹進(jìn)行剪枝,剪枝算法參考CART剪枝過(guò)程。
GBDT與AdaBoost的模型比較
假設(shè)初始化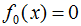
AdaBoost模型表示為:
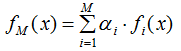
GBDT模型表示為:
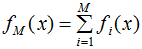
比較這兩式,你會(huì)發(fā)現(xiàn)GBDT模型沒(méi)有權(quán)值 αi,原因是:AdaBoost每次都是對(duì)不同分布(權(quán)值)的原始數(shù)據(jù)集進(jìn)行訓(xùn)練,得到一系列弱學(xué)習(xí)器,然后結(jié)合權(quán)值得到最終模型;GBDT模型沒(méi)有權(quán)值是因?yàn)槿鯇W(xué)習(xí)器是擬合上一輪的殘差,隨著回歸樹個(gè)數(shù)的增加,殘差越來(lái)越小,因此弱學(xué)習(xí)器不需要權(quán)值。
總結(jié)
本文介紹了boosting族的提升樹算法和GBDT算法,提升樹算法的每輪弱學(xué)習(xí)器是擬合上一輪的殘差生成的,GBDT算法的每輪弱學(xué)習(xí)器是擬合上一輪損失函數(shù)的負(fù)梯度生成的。提升樹算法和GBDT算法都是用CART回歸樹作為弱學(xué)習(xí)器,只要確定模型的損失函數(shù),提升樹和GBDT就可以通過(guò)前向分布算法進(jìn)行構(gòu)建。
參考:
https://www.cnblogs.com/pinard/p/6140514.html

-END-
交流群
歡迎加入公眾號(hào)讀者群一起和同行交流,目前有SLAM、三維視覺(jué)、傳感器、自動(dòng)駕駛、計(jì)算攝影、檢測(cè)、分割、識(shí)別、醫(yī)學(xué)影像、GAN、算法競(jìng)賽等微信群(以后會(huì)逐漸細(xì)分),請(qǐng)掃描下面微信號(hào)加群,備注:”昵稱+學(xué)校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺(jué)SLAM“。請(qǐng)按照格式備注,否則不予通過(guò)。添加成功后會(huì)根據(jù)研究方向邀請(qǐng)進(jìn)入相關(guān)微信群。請(qǐng)勿在群內(nèi)發(fā)送廣告,否則會(huì)請(qǐng)出群,謝謝理解~