
【深度學(xué)習(xí)】循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)簡(jiǎn)易教程
文章來(lái)源于磐創(chuàng)AI,作者VK
? 磐創(chuàng)AI分享??
作者 | Renu Khandelwal?編譯 | VK?來(lái)源 | Medium我們從以下問(wèn)題開(kāi)始
- 循環(huán)神經(jīng)網(wǎng)絡(luò)能解決人工神經(jīng)網(wǎng)絡(luò)和卷積神經(jīng)網(wǎng)絡(luò)存在的問(wèn)題。
- 在哪里可以使用RNN?
- RNN是什么以及它是如何工作的?
- 挑戰(zhàn)RNN的消梯度失和梯度爆炸
- LSTM和GRU如何解決這些挑戰(zhàn)
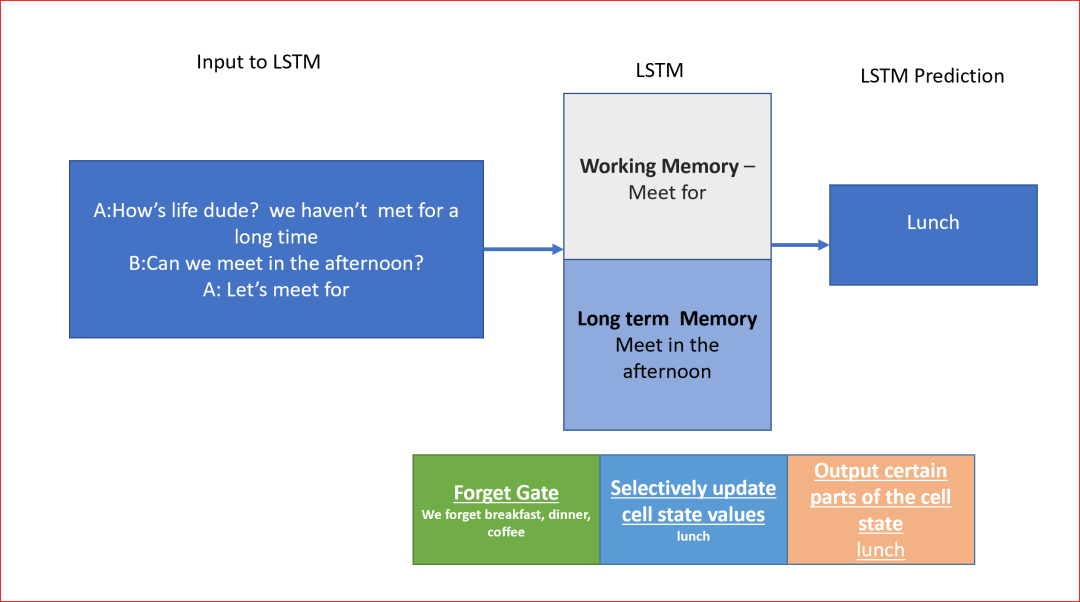
假設(shè)我們正在寫(xiě)一條信息“Let’s meet for___”,我們需要預(yù)測(cè)下一個(gè)單詞是什么。下一個(gè)詞可以是午餐、晚餐、早餐或咖啡。我們更容易根據(jù)上下文作出推論。假設(shè)我們知道我們是在下午開(kāi)會(huì),并且這些信息一直存在于我們的記憶中,那么我們就可以很容易地預(yù)測(cè)我們可能會(huì)在午餐時(shí)見(jiàn)面。
當(dāng)我們需要處理需要在多個(gè)時(shí)間步上的序列數(shù)據(jù)時(shí),我們使用循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)
傳統(tǒng)的神經(jīng)網(wǎng)絡(luò)和CNN需要一個(gè)固定的輸入向量,在固定的層集上應(yīng)用激活函數(shù)產(chǎn)生固定大小的輸出。
例如,我們使用128×128大小的向量的輸入圖像來(lái)預(yù)測(cè)狗、貓或汽車(chē)的圖像。我們不能用可變大小的圖像來(lái)做預(yù)測(cè)
現(xiàn)在,如果我們需要對(duì)依賴(lài)于先前輸入狀態(tài)(如消息)的序列數(shù)據(jù)進(jìn)行操作,或者序列數(shù)據(jù)可以在輸入或輸出中,或者同時(shí)在輸入和輸出中,而這正是我們使用RNNs的地方,該怎么辦。
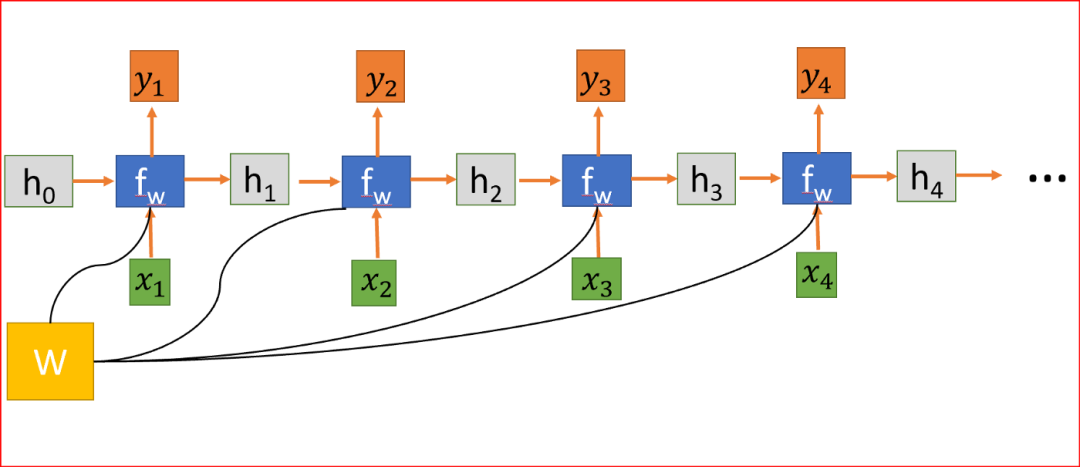
在RNN中,我們共享權(quán)重并將輸出反饋給循環(huán)輸入,這種循環(huán)公式有助于處理序列數(shù)據(jù)。
RNN利用連續(xù)的數(shù)據(jù)來(lái)推斷誰(shuí)在說(shuō)話(huà),說(shuō)什么,下一個(gè)單詞可能是什么等等。
RNN是一種神經(jīng)網(wǎng)絡(luò),具有循環(huán)來(lái)保存信息。RNN被稱(chēng)為循環(huán),因?yàn)樗鼈儗?duì)序列中的每個(gè)元素執(zhí)行相同的任務(wù),并且輸出元素依賴(lài)于以前的元素或狀態(tài)。這就是RNN如何持久化信息以使用上下文來(lái)推斷。
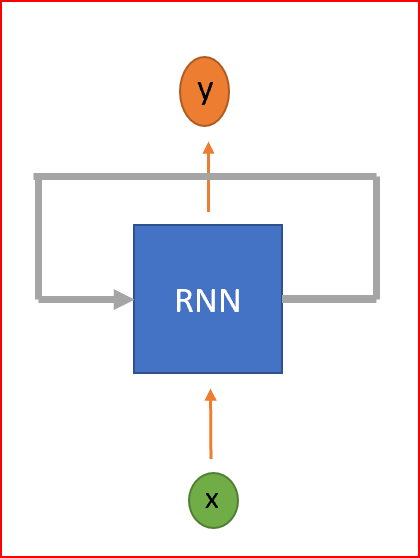
RNN是一種具有循環(huán)的神經(jīng)網(wǎng)絡(luò)
RNN在哪里使用?
前面所述的RNN可以有一個(gè)或多個(gè)輸入和一個(gè)或多個(gè)輸出,即可變輸入和可變輸出。
RNN可用于
- 分類(lèi)圖像
- 圖像采集
- 機(jī)器翻譯
- 視頻分類(lèi)
- 情緒分析
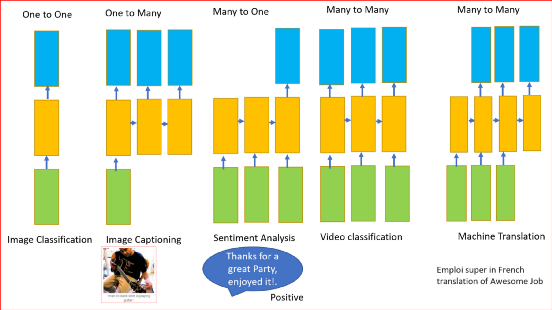
RNN是如何工作的?
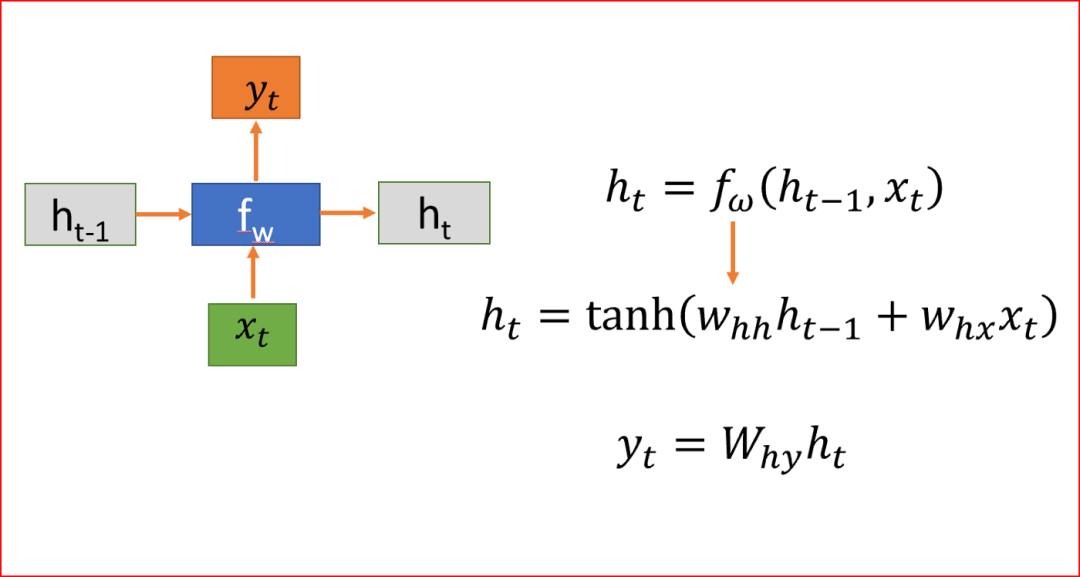
先解釋符號(hào)。
- h是隱藏狀態(tài)
- x為輸入
- y為輸出
- W是權(quán)重
- t是時(shí)間步長(zhǎng)
當(dāng)我們?cè)谔幚硇蛄袛?shù)據(jù)時(shí),RNN在時(shí)間步t上取一個(gè)輸入x。RNN在時(shí)間步t-1上取隱藏狀態(tài)值來(lái)計(jì)算時(shí)間步t上的隱藏狀態(tài)h并應(yīng)用tanh激活函數(shù)。我們使用tanh或ReLU來(lái)表示輸出和時(shí)間t的非線(xiàn)性關(guān)系。
將RNN展開(kāi)為四層神經(jīng)網(wǎng)絡(luò),每一步共享權(quán)值矩陣W。
隱藏狀態(tài)連接來(lái)自前一個(gè)狀態(tài)的信息,因此充當(dāng)RNN的記憶。任何時(shí)間步的輸出都取決于當(dāng)前輸入以及以前的狀態(tài)。
與其他對(duì)每個(gè)隱藏層使用不同參數(shù)的深層神經(jīng)網(wǎng)絡(luò)不同,RNN在每個(gè)步驟共享相同的權(quán)重參數(shù)。
我們隨機(jī)初始化權(quán)重矩陣,在訓(xùn)練過(guò)程中,我們需要找到矩陣的值,使我們有理想的行為,所以我們計(jì)算損失函數(shù)L。損失函數(shù)L是通過(guò)測(cè)量實(shí)際輸出和預(yù)測(cè)輸出之間的差異來(lái)計(jì)算的。用交叉熵函數(shù)計(jì)算L。
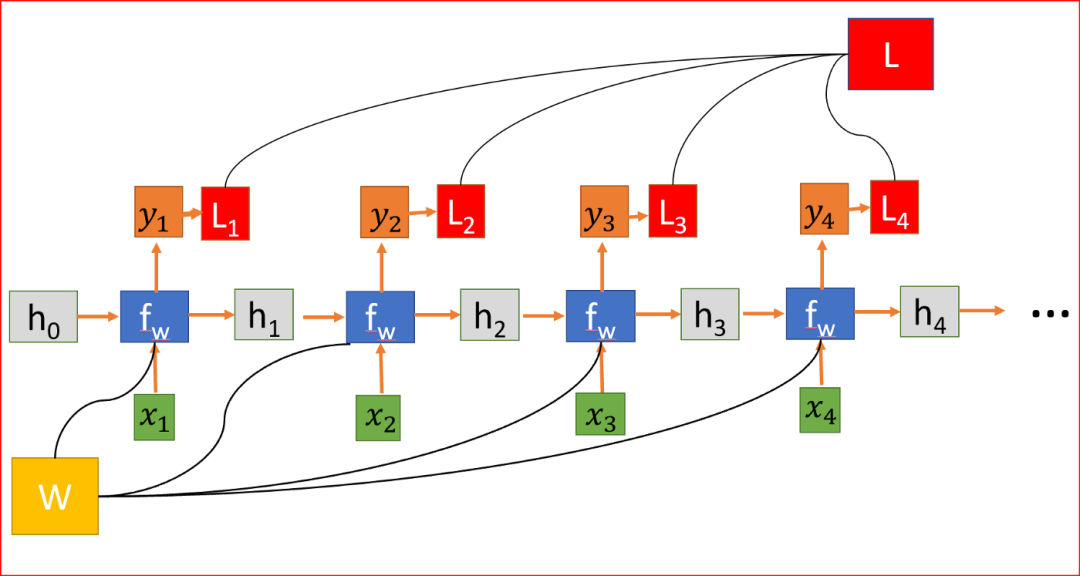
RNN,其中損失函數(shù)L是各層所有損失的總和
為了減少損失,我們使用反向傳播,但與傳統(tǒng)的神經(jīng)網(wǎng)絡(luò)不同,RNN在多個(gè)層次上共享權(quán)重,換句話(huà)說(shuō),它在所有時(shí)間步驟上共享權(quán)重。這樣,每一步的誤差梯度也取決于前一步的損失。
在上面的例子中,為了計(jì)算第4步的梯度,我們需要將前3步的損失和第4步的損失相加。這稱(chēng)為通過(guò)Time-BPPT的反向傳播。
我們計(jì)算誤差相對(duì)于權(quán)重的梯度,來(lái)為我們學(xué)習(xí)正確的權(quán)重,為我們獲得理想的輸出。
因?yàn)閃在每一步中都被用到,直到最后的輸出,我們從t=4反向傳播到t=0。在傳統(tǒng)的神經(jīng)網(wǎng)絡(luò)中,我們不共享權(quán)重,因此不需要對(duì)梯度進(jìn)行求和,而在RNN中,我們共享權(quán)重,并且我們需要在每個(gè)時(shí)間步上對(duì)W的梯度進(jìn)行求和。
在時(shí)間步t=0計(jì)算h的梯度涉及W的許多因素,因?yàn)槲覀冃枰ㄟ^(guò)每個(gè)RNN單元反向傳播。即使我們不要權(quán)重矩陣,并且一次又一次地乘以相同的標(biāo)量值,但是時(shí)間步如果特別大,比如說(shuō)100個(gè)時(shí)間步,這將是一個(gè)挑戰(zhàn)。
如果最大奇異值大于1,則梯度將爆炸,稱(chēng)為爆炸梯度。
如果最大奇異值小于1,則梯度將消失,稱(chēng)為消失梯度。
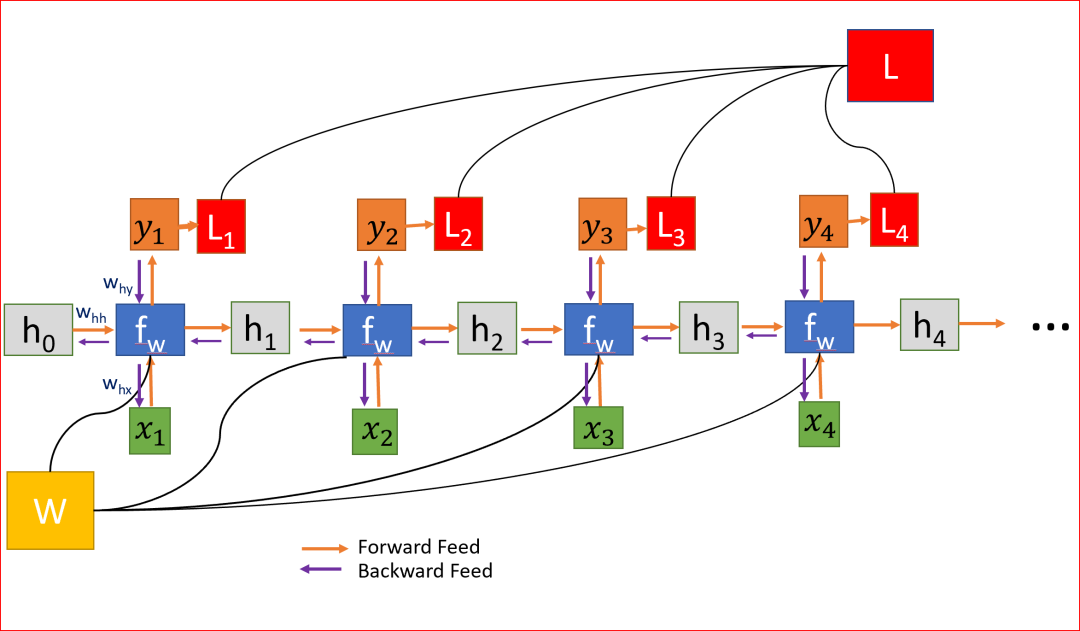
權(quán)重在所有層中共享,導(dǎo)致梯度爆炸或消失
對(duì)于梯度爆炸問(wèn)題,我們可以使用梯度剪裁,其中我們可以預(yù)先設(shè)置一個(gè)閾值,如果梯度值大于閾值,我們可以剪裁它。
為了解決消失梯度問(wèn)題,常用的方法是使用長(zhǎng)短期記憶(LSTM)或門(mén)控循環(huán)單元(GRU)。
在我們的消息示例中,為了預(yù)測(cè)下一個(gè)單詞,我們需要返回幾個(gè)時(shí)間步驟來(lái)了解前面的單詞。我們有可能在兩個(gè)相關(guān)信息之間有足夠的差距。隨著差距的擴(kuò)大,RNN很難學(xué)習(xí)和連接信息。但這反而是LSTM的強(qiáng)大功能。

長(zhǎng)短時(shí)記憶網(wǎng)絡(luò)(LSTM)
LSTMs能夠更快地學(xué)習(xí)長(zhǎng)期依賴(lài)關(guān)系。LSTMs可以學(xué)習(xí)跨1000步的時(shí)間間隔。這是通過(guò)一種高效的基于梯度的算法實(shí)現(xiàn)的。
為了預(yù)測(cè)消息中的下一個(gè)單詞,我們可以將上下文存儲(chǔ)到消息的開(kāi)頭,這樣我們就有了正確的上下文。這正是我們記憶的工作方式。
讓我們深入了解一下LSTM架構(gòu),了解它是如何工作的

LSTMs的行為是在很長(zhǎng)一段時(shí)間內(nèi)記住信息,因此它需要知道要記住什么和忘記什么。
LSTM使用4個(gè)門(mén),你可以將它們認(rèn)為是否需要記住以前的狀態(tài)。單元狀態(tài)在LSTMs中起著關(guān)鍵作用。LSTM可以使用4個(gè)調(diào)節(jié)門(mén)來(lái)決定是否要從單元狀態(tài)添加或刪除信息。
這些門(mén)的作用就像水龍頭,決定了應(yīng)該通過(guò)多少信息。

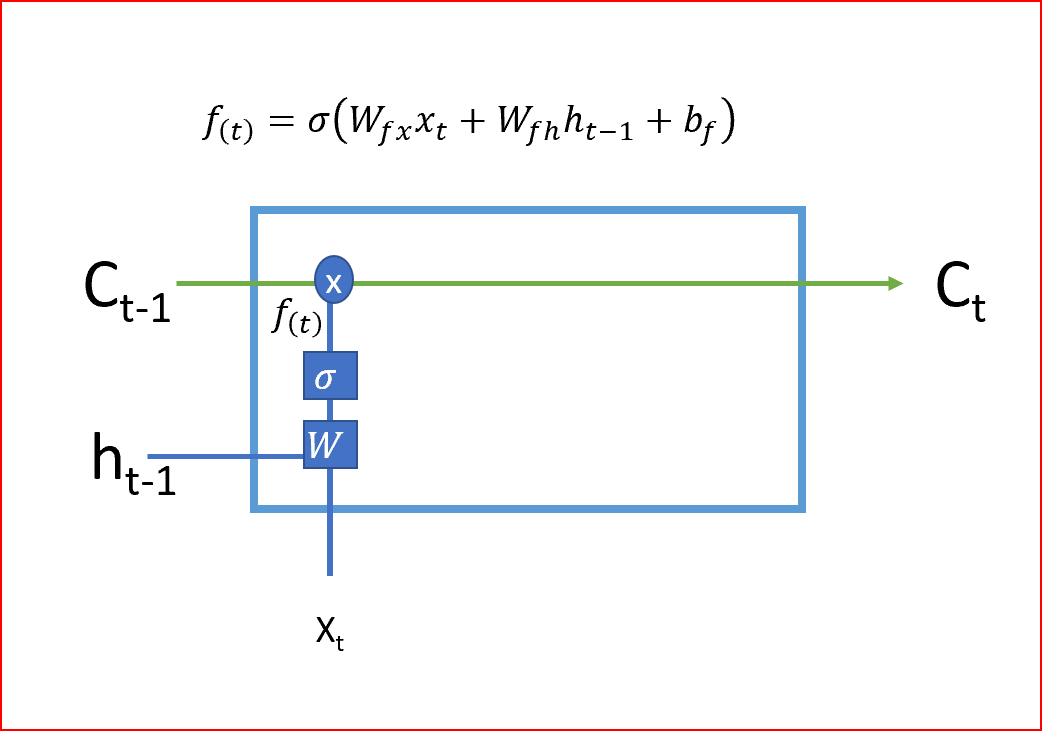
- LSTM的第一步是決定我們是需要記住還是忘記單元的狀態(tài)。遺忘門(mén)使用Sigmoid激活函數(shù),輸出值為0或1。遺忘門(mén)的輸出1告訴我們要保留該值,值0告訴我們要忘記該值。
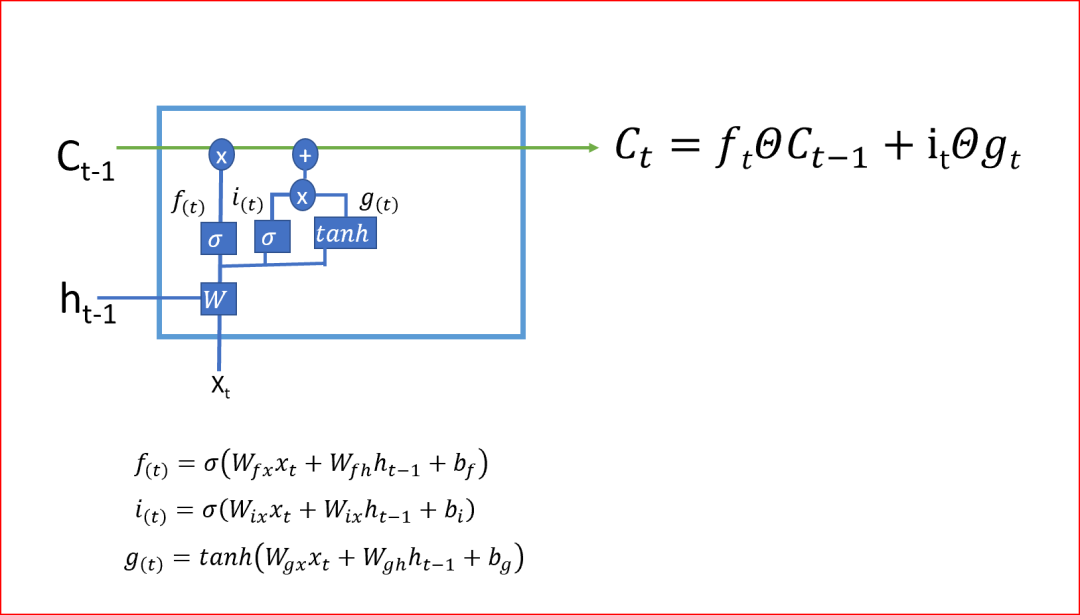
- 第二步?jīng)Q定我們將在單元狀態(tài)中存儲(chǔ)哪些新信息。這有兩部分:一部分是輸入門(mén),它通過(guò)使用sigmoid函數(shù)決定是否寫(xiě)入單元狀態(tài);另一部分是使用tanh激活函數(shù)決定有哪些新信息被加入。

在最后一步中,我們通過(guò)組合步驟1和步驟2的輸出來(lái)創(chuàng)建單元狀態(tài),步驟1和步驟2的輸出是將當(dāng)前時(shí)間步的tanh激活函數(shù)應(yīng)用于輸出門(mén)的輸出后乘以單元狀態(tài)。Tanh激活函數(shù)給出-1和+1之間的輸出范圍
單元狀態(tài)是單元的內(nèi)部存儲(chǔ)器,它將先前的單元狀態(tài)乘以遺忘門(mén),然后將新計(jì)算的隱藏狀態(tài)(g)乘以輸入門(mén)i的輸出。
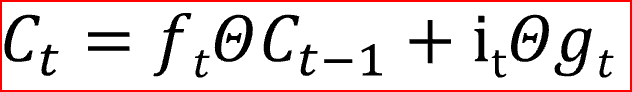
最后,輸出將基于單元狀態(tài)
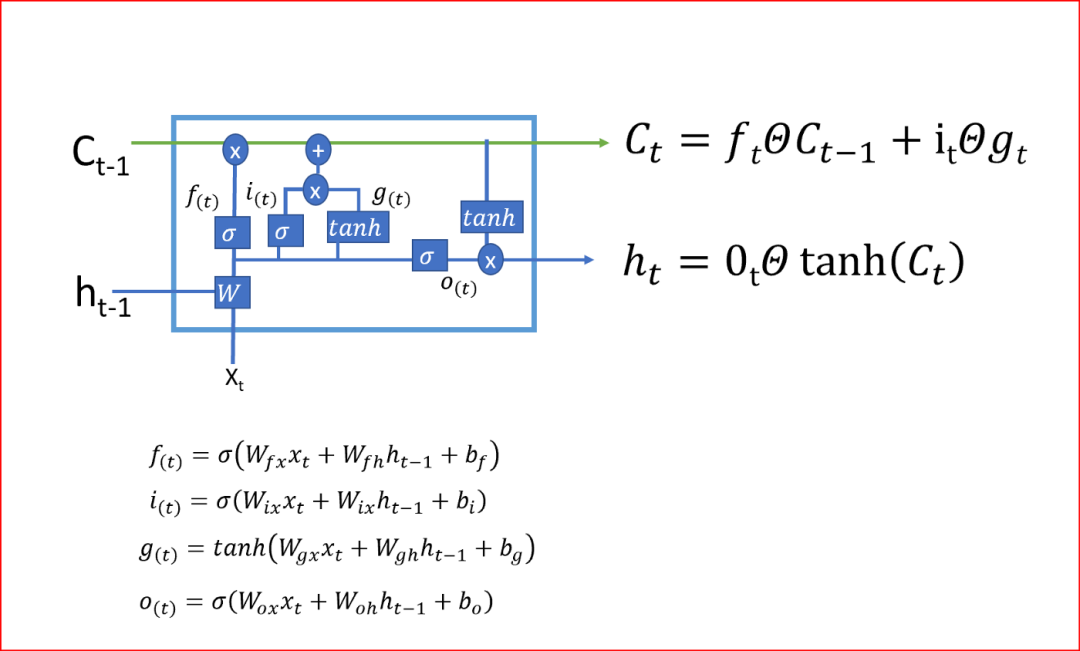
從當(dāng)前單元狀態(tài)到前一單元狀態(tài)的反向傳播只有遺忘門(mén)的單元相乘,沒(méi)有W的矩陣相乘,這就利用單元狀態(tài)消除了消失和爆炸梯度問(wèn)題
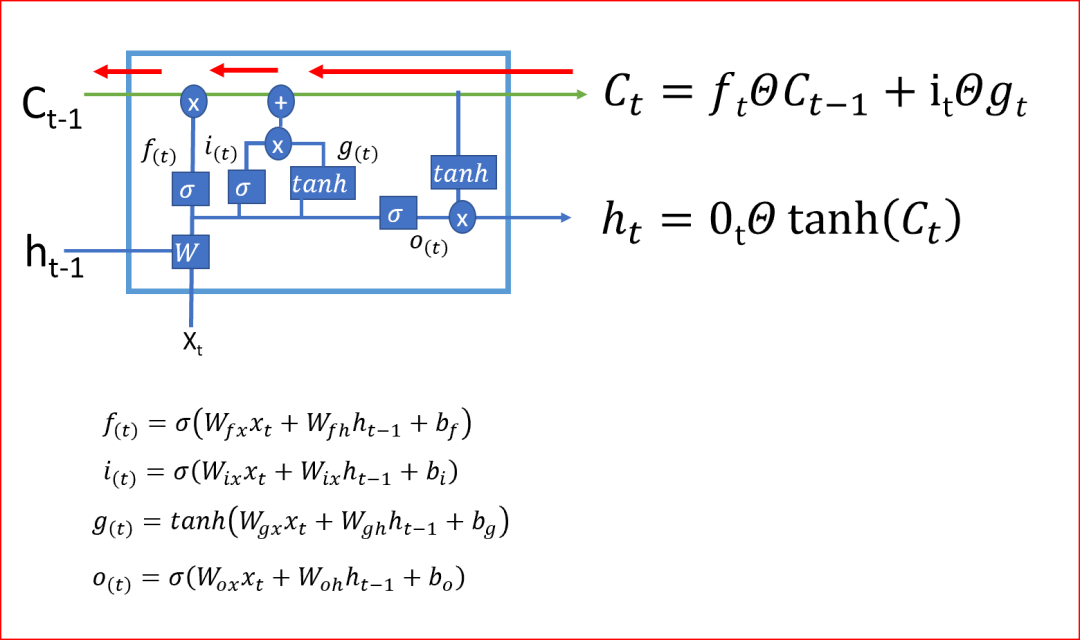
LSTM通過(guò)決定忘記什么、記住什么、更新哪些信息來(lái)決定何時(shí)以及如何在每個(gè)時(shí)間步驟轉(zhuǎn)換記憶。這就是LSTMs如何幫助存儲(chǔ)長(zhǎng)期記憶。
以下LSTM如何對(duì)我們的消息進(jìn)行預(yù)測(cè)的示例
GRU,LSTM的變體
GRU使用兩個(gè)門(mén),重置門(mén)和一個(gè)更新門(mén),這與LSTM中的三個(gè)步驟不同。GRU沒(méi)有內(nèi)部記憶
重置門(mén)決定如何將新輸入與前一個(gè)時(shí)間步的記憶相結(jié)合。
更新門(mén)決定了應(yīng)該保留多少以前的記憶。更新門(mén)是我們?cè)贚STM中理解的輸入門(mén)和遺忘門(mén)的組合。
GRU是求解消失梯度問(wèn)題的LSTM的一個(gè)簡(jiǎn)單變種
原文鏈接:https://medium.com/datadriveninvestor/recurrent-neural-network-rnn-52dd4f01b7e8
?------------------------------------------------看到這里,說(shuō)明你喜歡這篇文章,請(qǐng)點(diǎn)擊「在看」或順手「轉(zhuǎn)發(fā)」「點(diǎn)贊」。
往期精彩回顧
獲取一折本站知識(shí)星球優(yōu)惠券,復(fù)制鏈接直接打開(kāi):
https://t.zsxq.com/yFQV7am
本站qq群1003271085。
加入微信群請(qǐng)掃碼進(jìn)群: