
PyTorch學(xué)習(xí)系列教程:循環(huán)神經(jīng)網(wǎng)絡(luò)【RNN】
導(dǎo)讀
前兩篇推文分別介紹了DNN和CNN,今天本文來介紹深度學(xué)習(xí)的另一大基石:循環(huán)神經(jīng)網(wǎng)絡(luò),即RNN。RNN應(yīng)該算是與CNN齊名的一類神經(jīng)網(wǎng)絡(luò),在深度學(xué)習(xí)發(fā)展史上具有奠基性地位。
注:RNN既用于表達循環(huán)神經(jīng)網(wǎng)絡(luò)這一類網(wǎng)絡(luò),也用于表達標準RNN模塊。正常情況下不存在理解歧義,因此本文不加以明確區(qū)分。
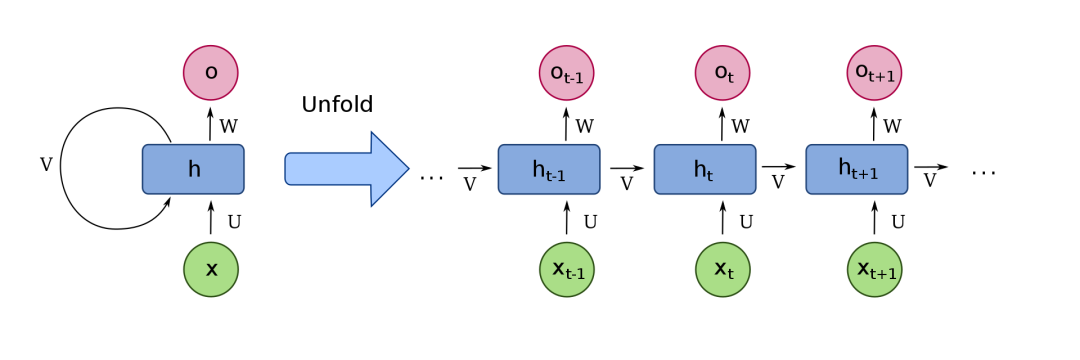
標準的RNN模塊結(jié)構(gòu)
如果說從DNN到CNN的技術(shù)演進是為了面向圖像數(shù)據(jù)解決提取空間依賴特征的問題,那么RNN的出現(xiàn)則是為了應(yīng)對序列數(shù)據(jù)建模,提取時間依賴特征(這里的"時間"不一定要求具有確切的時間信息,僅用于強調(diào)數(shù)據(jù)的先后性)。
延續(xù)前文的行文思路,本文仍然從以下四個方面加以介紹:
什么是RNN
RNN為何有效
RNN的適用場景
在PyTorch中的使用
循環(huán)神經(jīng)網(wǎng)絡(luò),英文Recurrent Neural Network,簡寫RNN。顯然,這里的"循環(huán)"是最具特色的關(guān)鍵詞。那么,如何理解"循環(huán)"二字呢?這首先要從RNN適用的任務(wù)——序列數(shù)據(jù)建模說起。
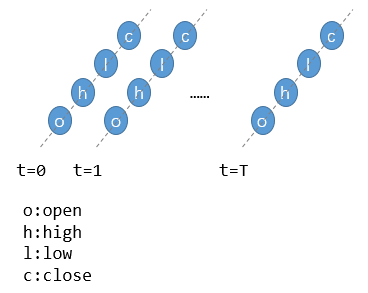
實際上,這就是一個二維的數(shù)據(jù)矩陣[T, 4],其中T為時序長度,4為特征個數(shù)。在機器學(xué)習(xí)中,單支股票數(shù)據(jù)只能算作一個樣本,進一步考慮多支股票則可構(gòu)成標準的序列數(shù)據(jù)集[N, T, 4],其中N為股票數(shù)量。
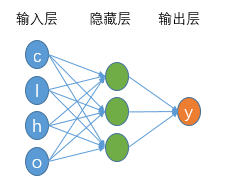
一個具有4個輸入特征、單隱藏層的DNN架構(gòu)
如果我們不考慮股票的時間特性(消除前述數(shù)據(jù)集的時間維度),則每支股票特征僅有4個,便可以直接利用上述的3層DNN架構(gòu)完成特征處理,并得到最終的預(yù)測結(jié)果。上述這一過程可以抽象為:
這其實恰好就是前文提到的內(nèi)容:神經(jīng)網(wǎng)絡(luò)本質(zhì)上是在擬合一個復(fù)雜的復(fù)合函數(shù),其中這個復(fù)合函數(shù)的輸入是X,網(wǎng)絡(luò)參數(shù)是W和b。
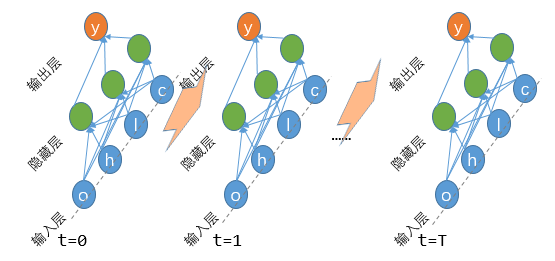
RNN處理序列數(shù)據(jù)示意圖
如上述示意圖所示,縱向上仍然是一個單純的DNN網(wǎng)絡(luò)進行數(shù)據(jù)處理的流程,而橫向上則代表了新增的時間維度。也正因為這個時間維度的出現(xiàn),所以時刻t對應(yīng)DNN輸入數(shù)據(jù)將來源于兩部分:當(dāng)前時刻t對應(yīng)的4個輸入特征,以及t-1時刻的輸出信息,即圖中粉色橫向?qū)捈^表示的部分。
是否好奇:為啥要將t-1時刻的的輸出作為t時刻的輸入呢?當(dāng)然是因為要序列建模!如果不把相鄰時刻的輸入輸出聯(lián)系起來,那序列先后順序又該如何體現(xiàn)?
用數(shù)學(xué)公式加以抽象表示,就是:
上式中,Wi表達當(dāng)前輸入信息的權(quán)重矩陣,Wh表達對前一時刻輸入的權(quán)重矩陣,且二者在各個時刻是相同的,可理解為面向時間維度的權(quán)值共享。
對比該公式和前面DNN中的公式,主要有兩點區(qū)別:
映射函數(shù)的輸入數(shù)據(jù)部分不止是X,還有前一時刻提供的信息ht-1;
模型的直接輸出變?yōu)橹虚g狀態(tài)ht,而ht與最終輸出y的區(qū)別在于:y可以是直接給出最終需要的信息,例如股票預(yù)測中的收盤價,但ht為了兼顧相鄰時刻之間的信息交互,往往不一定符合最終的輸出結(jié)果,所以可能需要對ht進一步使用一個DNN網(wǎng)絡(luò)進行映射得到想要的輸出
上圖中的右側(cè)(unfold部分),橫向代表了沿時間維度傳播的流程,縱向代表了單個時刻的信息處理流程(各時刻都是一個DNN),其中X代表各時刻的輸入特征,ht代表各時刻對應(yīng)的狀態(tài)信息,U和V分別為當(dāng)前輸入和前一時刻狀態(tài)的網(wǎng)絡(luò)權(quán)重,W為由當(dāng)前狀態(tài)ht擬合最終需要結(jié)果的網(wǎng)絡(luò)權(quán)重。而左側(cè)呢,其實就是把這個循環(huán)處理的流程抽象為一個循環(huán)結(jié)構(gòu),也就是那個指向自己的箭頭。
這個用指向自己的箭頭來表示神經(jīng)網(wǎng)絡(luò)的循環(huán),乍一看還挺唬人的!
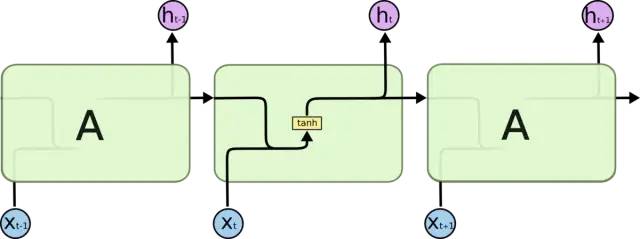
標準RNN模塊的內(nèi)部結(jié)構(gòu)
標準RNN結(jié)構(gòu)非常簡單,通常來說,在神經(jīng)網(wǎng)絡(luò)中過于簡單的結(jié)構(gòu)也意味著其表達能力有限。比如說,由于每經(jīng)過一個時間節(jié)點的信息傳遞,都會將之前的歷史信息和當(dāng)前信息進行線性組合,并通過一個tanh激活函數(shù)。tanh激活函數(shù)的輸出值在(-1,1)之間,這也就意味著,如果時間鏈路較長時歷史信息很可能會被淹沒!這也是標準RNN結(jié)構(gòu)最大的問題——不容易表達長期記憶——換句話說,就是時間鏈路較長的歷史信息會變得很小。
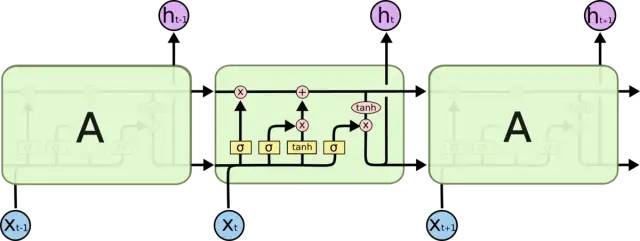
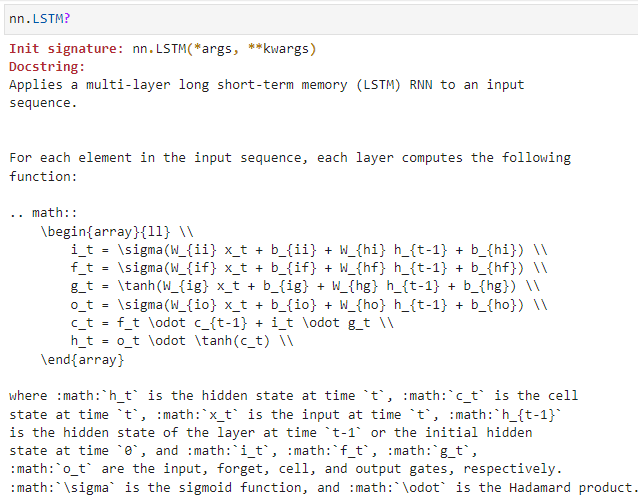
當(dāng)然,除了上述這一單元結(jié)構(gòu)示意圖,LSTM還往往需要這樣一組標準計算公式(這個等到后續(xù)擇機再講吧。。):
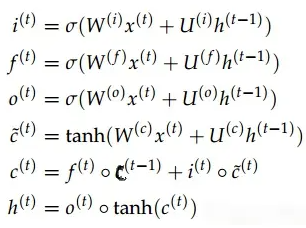
宏觀對照標準RNN和LSTM單元結(jié)構(gòu),可以概括二者間的主要異同點如下:
相同點:各單元結(jié)構(gòu)的輸入信息均包含兩部分,即當(dāng)前時刻的輸入和前一時刻的輸入;輸出均為ht
不同點:
RNN中接收前一時刻的輸入信息只有一種(這部分叫做ht),體現(xiàn)為相鄰單元間的單箭頭;而在LSTM中接收前一時刻的輸入則包含兩部分(兩部分分別是ht和ct,ct是新引入的部分),體現(xiàn)為相鄰單元間的雙箭頭
RNN中的內(nèi)部結(jié)構(gòu)非常簡單,就是兩部分向量相加的結(jié)果;而LSTM的內(nèi)部結(jié)構(gòu)相對非常復(fù)雜
與標準RNN中簡單地將前一狀態(tài)信息與當(dāng)前信息線性相加不同,LSTM中設(shè)計了三個門結(jié)構(gòu)(所謂的門結(jié)構(gòu)就是經(jīng)過sigmoid處理后的權(quán)重矩陣,這個矩陣的取值在(0, 1)之間,越接近于1表示通過的信息越大,越接近于0表示對信息的消減越嚴重),即遺忘門、輸入門和輸出門,其中:
遺忘門作用于歷史數(shù)據(jù)輸入上,用于控制歷史信息對當(dāng)前輸出影響的大小;
輸入門作用于當(dāng)前輸入上,用于控制當(dāng)前輸入信息對當(dāng)前輸出影響的大小;
輸出門則進一步控制當(dāng)前輸出的大小;
LSTM中之所以相較于標準RNN能提供更為長期的記憶,根本原因在于引入了從歷史信息直接到達輸出的通路(LSTM結(jié)構(gòu)中的上側(cè)貫通線),由于該通路可以不與當(dāng)前時刻輸入同步接受相同的門控作用,所以允許網(wǎng)絡(luò)學(xué)習(xí)更為久遠的記憶(只需將遺忘門的結(jié)果學(xué)習(xí)得大一些); LSTM除了可以提供長期記憶,還可以提供短期記憶,原因在于專門提供了對當(dāng)前輸入信息的通路(LSTM結(jié)構(gòu)中的下側(cè)通路),但同時該信息又與部分歷史信息會和,一并經(jīng)過輸入門的控制,這一部分子結(jié)構(gòu)大體定位相當(dāng)于標準RNN中的簡單處理流程
進一步復(fù)盤由RNN到LSTM的改進:雖然LSTM設(shè)計的非常精妙,通過三個門結(jié)構(gòu)很好的權(quán)衡了歷史信息和當(dāng)前信息對輸出結(jié)果的影響,但也有一個細節(jié)問題——為了控制兩部分信息的相對大小,我們是不是只需要1個參數(shù)就可以了呢?比如,計算x和y的加權(quán)平均時,我們無需為其分別提供兩個系數(shù)α和β,計算z=αx+βy,而只需z=αx+y就可以,或者寫成其歸一化形式z=αx+(1-α)y。正是基于這一樸素思想,LSTM的精簡版——GRU單元結(jié)構(gòu)順利誕生!
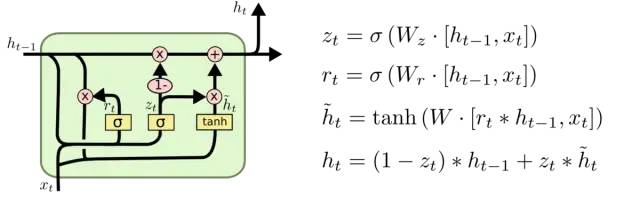
對比下LSTM與GRU的異同點
所以概括一下:從RNN到LSTM的改進是為了增加網(wǎng)絡(luò)容量,權(quán)衡長短期記憶;而從LSTM到GRU的演進則是為了精簡模型,去除冗余結(jié)構(gòu)。
上述大體介紹了循環(huán)神經(jīng)網(wǎng)絡(luò)的起源,并簡要介紹了三種最常用的循環(huán)神經(jīng)網(wǎng)絡(luò)單元結(jié)構(gòu):RNN、LSTM和GRU。如果說卷積和池化是卷積神經(jīng)網(wǎng)絡(luò)中的標志性模塊,那么這三個模塊無疑就是循環(huán)神經(jīng)網(wǎng)絡(luò)中的典型代表。
DNN可以用通用近似定理論證其有效性(更準確地說,通用近似定理適用于所有神經(jīng)網(wǎng)絡(luò),而不止是DNN),CNN也可以抽取若干個特征圖直觀的表達其卷積的操作結(jié)果,但RNN似乎并不容易直接說明其為何會有效。
循環(huán)神經(jīng)網(wǎng)絡(luò)適用于序列數(shù)據(jù)建模場景,而相較于普通的DNN(包括CNN,其實也是不帶有時間依賴信息的單時刻輸入特征)而言,其最大的特點在于如何按順序提取各時刻的新增信息,所以形式上必然是要將當(dāng)前信息與歷史信息做融合 為了保持對所有時刻信息處理流程的一致性,RNN中也有權(quán)值共享機制,即網(wǎng)絡(luò)參數(shù)在隨時間維度的傳播過程中使用同一套網(wǎng)絡(luò)權(quán)重(Wi和Wh),這保證了處理時序信息的公平性 適當(dāng)?shù)拈T機制。實際上,標準的RNN單元其記憶能力是有限的,所以談不上有效;但為何LSTM卻非常有效?其核心就在于門的設(shè)計上,即允許神經(jīng)網(wǎng)絡(luò)通過反向傳播算法去自主學(xué)習(xí):什么情況下應(yīng)給歷史信息較大的權(quán)重——記憶歷史;什么情況下又該給當(dāng)前輸入信息較大的權(quán)重——更新現(xiàn)在,而這一切都交由網(wǎng)絡(luò)通過訓(xùn)練集自己去訓(xùn)練
循環(huán)神經(jīng)網(wǎng)絡(luò)是一個精妙的設(shè)計,對于序列建模而言是非常有效的,其歷史地位不亞于卷積神經(jīng)網(wǎng)絡(luò)。但也值得指出,目前循環(huán)神經(jīng)網(wǎng)絡(luò)似乎已經(jīng)有了替代結(jié)構(gòu)——注意力機制——這也是對序列建模非常有效的網(wǎng)絡(luò)結(jié)構(gòu),而且無需按時間順序執(zhí)行,可以方便的實現(xiàn)并行化,從而提高執(zhí)行效率——當(dāng)然,這是后來的故事!
論及循環(huán)神經(jīng)網(wǎng)絡(luò)適用的場景,其實答案是相對明確的,即序列數(shù)據(jù)建模。進一步地,這里的序列數(shù)據(jù)既可以是帶有時間屬性的時序數(shù)據(jù),也可以是僅含有先后順序關(guān)系的其他序列數(shù)據(jù),例如文本序列等。
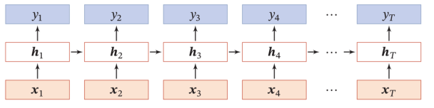
N to 1:前述的例子都是N個時刻的輸入對應(yīng)1個時刻的輸出,例如股票預(yù)測,天氣預(yù)報、文本情感分類等
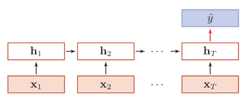
1 to N:典型應(yīng)用是NLP中的作詩、寫文章等,即僅提供標題或起始單詞,交由模型輸出一篇文章
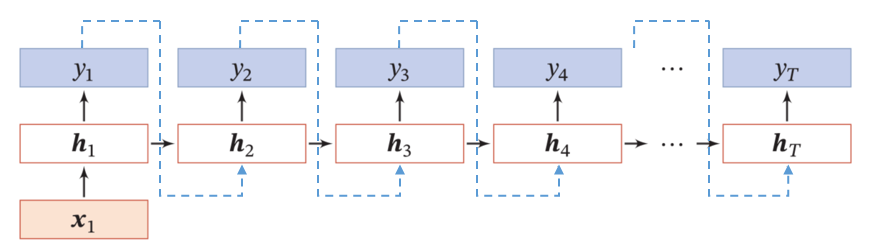
N to N:即給定N個歷史時刻的輸入數(shù)據(jù),同步給出相應(yīng)的N個輸出(注意,這里的輸入和輸出是同步的),典型的應(yīng)用場景是詞性分析,即逐一輸入一段文本中的各個單詞,要求輸出各單詞的詞性判斷結(jié)果
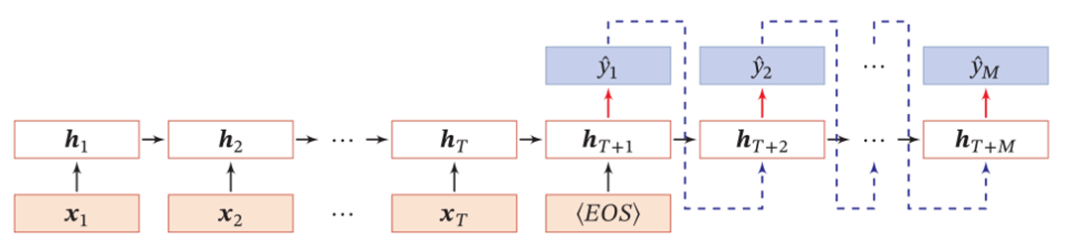
N to M:也就是給定N個歷史的輸入數(shù)據(jù),完全處理后得到M個輸出,其中M個輸出與N個輸入具有先后順序,輸入和輸出是異步的(也叫Seq2Seq)。典型的場景是機器翻譯:給定N個英文單詞,翻譯結(jié)果是M個中文詞語,多步的股票預(yù)測也符合這種場景
對于標準RNN、LSTM和GRU三種典型的循環(huán)神經(jīng)網(wǎng)絡(luò)單元,PyTorch中均有相應(yīng)的實現(xiàn)。對使用者來說,無需過度關(guān)心各單元內(nèi)在的結(jié)構(gòu),因為三者幾乎是具有相近的封裝形式,無論是類的初始化參數(shù),還是對輸入和輸出數(shù)據(jù)的形式上。

具體來說:
input_size:輸入數(shù)據(jù)的特征維度,例如在前面舉的股票例子中包括open、high、low和close共4個特征,即input_size=4
hidden_size:前面提到,在每個時間截面循環(huán)神經(jīng)單元其實都是一個DNN結(jié)構(gòu),默認情況下該DNN只有單個隱藏層,hidden_size即為該隱藏層神經(jīng)元的個數(shù),在前述的股票例子中隱藏層神經(jīng)元數(shù)量為3,即hidden_size=3
num_layers:雖然RNN、LSTM和GRU這些循環(huán)單元的的重點是構(gòu)建時間維度的序列依賴信息,但在單個事件截面的特征處理也可以支持含有更多隱藏層的DNN結(jié)構(gòu),默認狀態(tài)下為1
bias:類似于nn.Linear中的bias參數(shù),用于控制是否擬合偏置項,默認為bias=True,即擬合偏置項
batch_first:用于控制輸入數(shù)據(jù)各維度所對應(yīng)的含義,前面舉例中一直用的示例維度是(N, T, 4),即分別對應(yīng)樣本數(shù)量、時序長度和特征數(shù)量,這種可能比較符合部分人的思維習(xí)慣(包括我自己也是如此),但實際上LSTM更喜歡的方式是將序列維度放于第一個維度,此時即為(T, N, 4)。batch_first默認為False,即樣本數(shù)量為第二個維度,序列長度為第一個維度,(seq_len, batch, input_size)
dropout:用于控制全連接層后面是否設(shè)置dropout單元,增加dropout有時是為了增強模型的泛化能力
bidirectional:上述所介紹LSTM等都是沿著序列的正向進行處理和傳播,正向傳播更容易記住靠后的序列信息,而忘記前面的信息;所以LSTM的一種改進就是雙向循環(huán)單元結(jié)構(gòu),即首先沿正向處理一遍,再逆向處理一遍。bidirectional參數(shù)即用于控制是單向還是雙向,默認為bidirectional=False,即僅正向處理


大體來看,輸入和輸出具有相近的形式(這也是為啥可以循環(huán)處理的原因),對于LSTM來說包含三部分,即:
input/output:(L, N, H_in/H_out),其中L為序列長度,N為樣本數(shù)量,H_in和H_out分別為輸入數(shù)據(jù)和輸出結(jié)果的特征維度,即前面初始化中用到的input_size和hidden_size
h_n和c_n,分別對應(yīng)最后時刻循環(huán)單元對應(yīng)的隱藏狀態(tài)和細胞狀態(tài)(LSTM的相鄰單元之間有兩條連接線,上面的代表細胞狀態(tài)c_n,下面代表隱藏狀態(tài)h_n),如果是RNN或者GRU則只有隱藏狀態(tài)h_n
進一步地,output與h_n的聯(lián)系和區(qū)別是什么呢?output是區(qū)分時間維度的輸出序列,記錄了各時刻所對應(yīng)DNN的最終輸出結(jié)果,L個序列長度對應(yīng)了L個時刻的輸出;而h_n則只記錄最后一個序列所對應(yīng)的隱藏層輸出,所以只有一個時刻的結(jié)果,但如果num_layers>1或者bidirectional設(shè)置為True時,則也會有多個輸出結(jié)果。當(dāng)在默認情況下,即num_layers=1,bidirectional=False時,output[-1]=h_n
關(guān)于循環(huán)神經(jīng)網(wǎng)絡(luò)的介紹就到這里,后續(xù)將基于股票數(shù)據(jù)集提供一個實際案例。
相關(guān)閱讀: