
萬字長文:重溫機器學習經(jīng)典算法
點擊上方“機器學習算法工程師”
選擇“星標”公眾號,重磅干貨,第一時間送達
一、強化學習的概念和主要用途
1.什么是強化學習?
強化學習(Reinforcement Learning)是機器學習的一個非常重要的分支,其核心思想是實驗者構(gòu)建一個完整的實驗環(huán)境,在該環(huán)境中通過給予被實驗者一定的觀測值和回報等方法來強化或鼓勵被實驗者的一些行動,從而以更高的可能性產(chǎn)生實驗者所期望的結(jié)果或目標。從以上對強化學習的描述中,我們可以看出強化學習一定會涉及到被實驗者(也稱為智能體,Agent)、實驗者構(gòu)建的環(huán)境(也就是系統(tǒng)環(huán)境,System Environment)、被實驗者的觀測值(也稱為環(huán)境狀態(tài),State)、被實驗者的行動(Action)和回報(也稱為獎勵或反饋,Reward)這五個關鍵要素。
舉一個經(jīng)典的心理學實驗來進一步解釋強化學習所涉及到的這幾個關鍵要素。這個實驗就是巴浦洛夫的狗,在實驗中每次實驗者都對著狗搖鈴鐺,并給它一點食物。久而久之,鈴鐺和食物的組合就潛移默化地影響了狗的行動,此后每次對著狗搖鈴鐺,狗就會不由自主的流口水,并期待實驗者能給它食物,通過這樣的方法,實驗者就讓狗學會了鈴鐺和食物之間的關系,這算作是強化學習的一個簡單的例子。
從這個例子中我們不光能看出強化學習所涉及到的以上描述的五個關鍵要素,并且還能得到一個包含這五個關鍵要素的高度抽象的強化學習的框架,那就是: 在經(jīng)典的強化學習中,智能體是要和實驗者構(gòu)建的系統(tǒng)環(huán)境完成一系列的交互,主要包含以下三項內(nèi)容:
1. 在每一時刻,環(huán)境都處于一種狀態(tài),智能體能得到環(huán)境當前狀態(tài)的觀測值; 2. 智能體根據(jù)當前環(huán)境狀態(tài)的觀測值,并結(jié)合自己歷史的行為準則(一般稱為策略,Policy)做出行動; 3. 智能體做出的這個行動又繼而會使環(huán)境狀態(tài)發(fā)生一定的改變,同時智能體又會獲取到新的環(huán)境狀態(tài)的觀測值和這個行動所帶來的回報,當然這個回報既可以是正向的也可以是負向的,這樣智能體就會根據(jù)新的狀態(tài)觀測值和回報來繼續(xù)做出新的行動,直至達到實驗者所期望的目標為止。 因此,高度抽象的強化學習的框架所包含的整個過程如圖1所示:
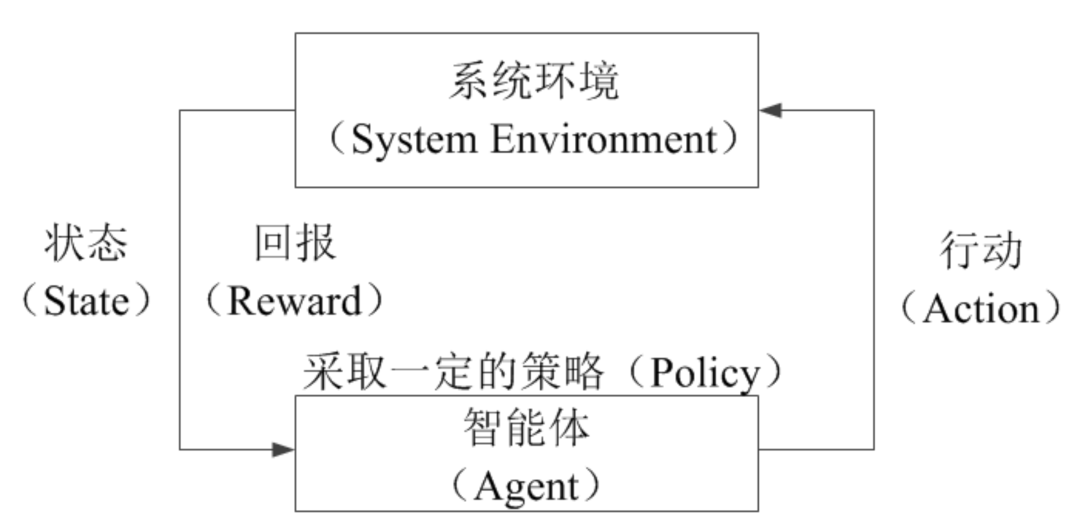
圖1 強化學習的過程表示
所以,站在智能體的角度,強化學習的目標就是最大化所獲得的回報。但是這個目標有些抽象,因此我們需要把這個目標變得更容易量化。這時不得不講強化學習的兩個顯著的特點,一是不斷試錯,根據(jù)環(huán)境狀態(tài)做出行動的智能體有時得到較多回報,有時回報又比較少,甚至還有可能得到負值的回報,因此智能體需要根據(jù)回報的多少不斷調(diào)整自己的策略以獲得盡可能多的回報,這個過程中就需要智能體不斷嘗試應對環(huán)境狀態(tài)的各種可能的行動,并收集對應的回報,只有借助這些反饋信息智能體才能更好地完成學習任務;二是看重長期回報,而不追逐短期的得分(例如,圍棋游戲中為了最終戰(zhàn)勝對方,游戲中可能會做出一些被對方吃掉棋子的看似不好的行動),這通常就需要智能體和系統(tǒng)環(huán)境進行長時間的交互,所以追求長期回報就需要多探索和不斷嘗試,也有可能遇到更多的失敗。
基于強化學習這兩個特點,我們在評價強化學習算法的優(yōu)劣時,除了常規(guī)的衡量指標(比如,算法效果、穩(wěn)定性和泛化性)以外,還需重點關注另一個指標,就是學習時間。由于強化學習與不斷試錯和看重長期回報相關,所以學習時間一般也可由強化學習算法嘗試和探索的次數(shù)代替。 因此,根據(jù)以上一系列的描述,強化學習可以簡潔地歸結(jié)為:根據(jù)環(huán)境狀態(tài)、行動和回報,不斷試錯學習出最佳的策略來讓智能體做出行動,并以最終結(jié)果為目標,不只看某個行動當下帶來的回報,而更要看到這個行動未來所能帶來的潛在回報。
2.強化學習能用來干什么?
強化學習主要是用來解決一系列決策問題的,因為它可以在復雜、不確定的環(huán)境中學習如何實現(xiàn)我們所設定的目標。強化學習的應用場景非常廣,幾乎包含了所有需要做決策的問題,比如控制機器人的電機來執(zhí)行特定的任務、無人駕駛中在當前道路狀態(tài)上做出最該執(zhí)行的行動(如加減速和轉(zhuǎn)換方向等)、商品定價和庫存管理以及玩視頻游戲或棋牌游戲。其中,掀起強化學習研究熱潮的當屬大名鼎鼎的AlphaGo,它是由谷歌公司的DeepMind團隊結(jié)合了策略網(wǎng)絡(Policy Network)、估值網(wǎng)絡(Value Network)與蒙特卡洛搜索樹(Monte Carlo Tree Search),實現(xiàn)的具有超高水平的進行圍棋對戰(zhàn)的深度強化學習程序,自打問世就一舉戰(zhàn)勝人類世界圍棋冠軍李世石,并一戰(zhàn)成名。
其中,強化學習中兩類重要的方法分別是策略迭代法(Policy-Based 或 Policy Gradients)和價值迭代法(Value-Based 或 Q-Learning)。這兩種方法的主要區(qū)別在Policy-Based方法直接預測在某個環(huán)境狀態(tài)下應該采取的行動,而Value-Based方法預測在某個環(huán)境狀態(tài)下所有行動的期望價值(也就是Q值),之后選擇Q值最高的行動來執(zhí)行。一般來說,Value-Based方法適合僅有少量離散取值的行動的問題,而Policy-Based方法則更加通用,適合可采取行動的種類非常多或有連續(xù)取值的行動的問題。
二、機器學習幾類常見算法的辨析
有監(jiān)督學習是一種經(jīng)典的機器學習方法,其核心思想是通過一定數(shù)量的訓練樣本學習出一個能根據(jù)給定的輸入得到對應輸出的模型,值得一提的是,這些訓練樣本包含了一對對輸入和已知輸出的數(shù)據(jù),有監(jiān)督學習就是使用這樣一對對輸入和輸出數(shù)據(jù)來計算出模型的參數(shù)(比如,連接權(quán)重和學習率等參數(shù)),從而完成模型的學習。因此,從學習的目標來看,有監(jiān)督學習是希望學習得到的模型能根據(jù)給定的輸入得到相應的輸出,而強化學習是希望智能體根據(jù)給定的環(huán)境狀態(tài)得到能使回報最大化的行動。
以上描述中我們知道,有監(jiān)督學習的效果除了依賴訓練樣本數(shù)據(jù),更依賴于從數(shù)據(jù)中提取的特征,因為這類算法是需要從訓練數(shù)據(jù)中計算出每個特征和預測結(jié)果之間的相關度。可以毫不夸張地說,同樣的訓練樣本數(shù)據(jù)使用不同的表達方式會極大地影響有監(jiān)督學習的效果,一旦有效解決了數(shù)據(jù)表達和特征提取的問題,很多有監(jiān)督學習問題也就解決了90%。但是對于許多有監(jiān)督學習問題來說,特征提取并不是一件簡單的事情。在一些復雜的問題中,需要通過人工的方式來設計有效的特征集合,這樣不光要花費很多的時間和精力,而且有時依賴人工的方式不能很好地提取出本質(zhì)特征。那么是否能依賴計算機來進行自動提取特征呢?深度學習就應運而生,深度學習基本上是深層人工神經(jīng)網(wǎng)絡的一個代名詞,其在圖像識別、語音識別、自然語言處理以及人機博弈等領域的工業(yè)界和學術界均有非常出色的應用和研究,因此深度學習是有監(jiān)督學習的一個重要分支。深度學習解決的核心問題有二個,一是可以像其他有監(jiān)督學習一樣學習特征和預測結(jié)果之間的關聯(lián),二是能自動將簡單特征組合成更加復雜的特征。也就是說,深度學習能從數(shù)據(jù)中學習出更加復雜的特征表達,使得神經(jīng)網(wǎng)絡模型訓練中的連接權(quán)重學習變得更加簡單有效,如圖2所示。
在圖3中,深度學習展示了解決圖像識別問題的樣例,可以看出深度學習是從圖像像素的基礎特征中逐漸組合出線條、邊、角、簡單形狀和復雜形狀等復雜特征的。因此,深度學習是能一層一層地將簡單特征逐步轉(zhuǎn)化成更加復雜的特征,從而使得不同類別的圖像更加可分。
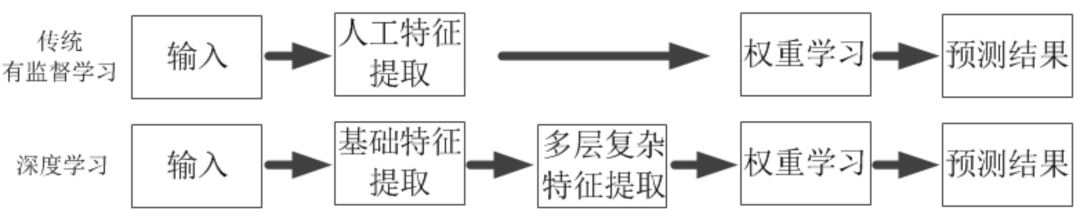
圖2 深度學習和傳統(tǒng)有監(jiān)督學習流程比較
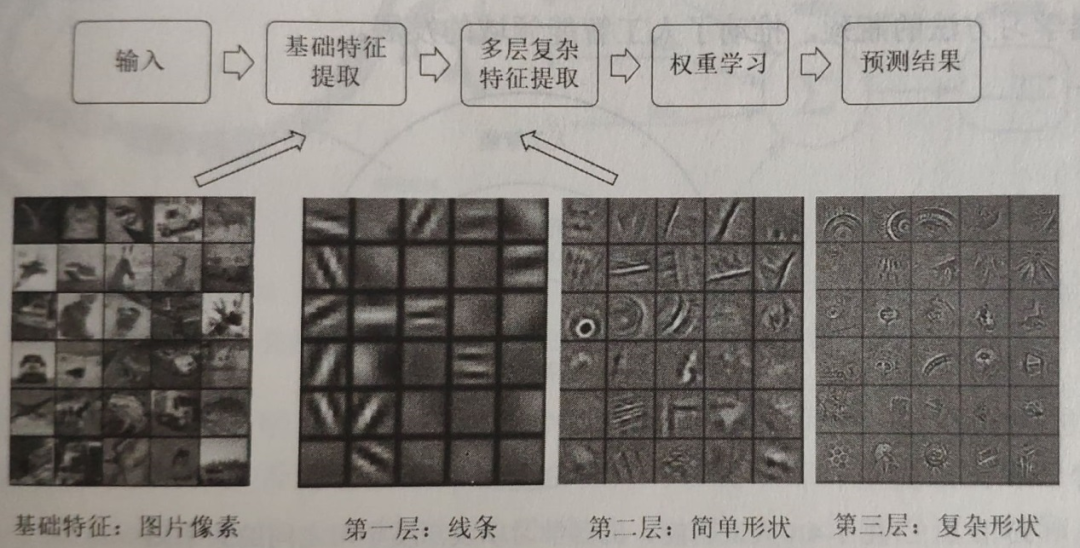
圖3 深度學習在圖像識別問題上的算法流程樣例
此外,將深度學習和強化學習結(jié)合起來的深度強化學習更是近年來的研究熱點,比如無人駕駛、機器人自主任務執(zhí)行和人工智能打游戲等。深度強化學習本質(zhì)上也是神經(jīng)網(wǎng)絡,只不過是在前幾層中使用了卷積神經(jīng)網(wǎng)絡等深度學習算法來對攝像頭捕獲的圖像進行識別、處理和分析,相當于能讓智能體看得見環(huán)境并正確識別周圍物體,之后再通過強化學習算法來預測出最該執(zhí)行的一系列動作來使得回報最大化,從而完成既定的任務。
在人工智能領域還有一種機器學習算法同樣很重要,那就是無監(jiān)督學習,這類算法是在沒有訓練樣本數(shù)據(jù)的情況下,對沒有標定輸出標簽的數(shù)據(jù)進行分析并建立合適的模型以給出問題解決方案的,常見的無監(jiān)督學習算法包括將樣本特征變量降維的數(shù)據(jù)轉(zhuǎn)換和把樣本劃歸到不同分組的聚類分析。
因此,從以上對各類算法的描述中可以看出,強化學習跟有監(jiān)督學習和無監(jiān)督學習均有所不同。強化學習既不像有監(jiān)督學習那樣有非常明確的學習目標(一個輸入對應的就是一個確定的輸出),也不像無監(jiān)督學習那樣完全沒有學習目標,而強化學習的目標一般是不明確的,因為在一定的環(huán)境狀態(tài)下能獲得最大回報的行動可能有很多。所以,這幾類機器學習算法在學習目標的明確性上有本質(zhì)的區(qū)別。此外,從時間維度上看,強化學習和有監(jiān)督學習輸出的意義不同。有監(jiān)督學習主要看重的是輸入和輸出的匹配程度,如果輸入和輸出匹配,那么學習的效果就是比較好的,即便存在輸入序列到輸出序列的映射,有監(jiān)督學習也希望每一時刻的輸出都能和其輸入對應上,比如,以俄羅斯方塊游戲為例,如果采用有監(jiān)督學習進行訓練,那么有監(jiān)督學習模型就會以每一幀游戲畫面或狀態(tài)作為輸入,對應的輸出當然也是確定的,要么移動方塊,要么翻轉(zhuǎn)方塊;但是這種學習方式實際上有些死板,因為要想最終獲得更多分數(shù),其操作序列當然不止一種。
然而,強化學習主要看重的卻是回報最大化,在智能體與環(huán)境交互過程中,并不是每一個行動都會獲得回報,當智能體與環(huán)境完成了一次完整的交互后,會得到一個行動序列,但在序列中哪些行動為最終的回報產(chǎn)生了正向的貢獻,哪些行動產(chǎn)生了負向的貢獻,有時確實很難界定,比如,以圍棋游戲為例,為了最終戰(zhàn)勝對方,智能體在游戲中的某些行動可能會走一些不好的招法,讓對方吃掉棋子,這是為達成最終目標而做出的犧牲,很難判定行動序列中的這些行動是優(yōu)是劣。因此,強化學習的優(yōu)勢就在于學習過程中被強制施加的約束更少,影響行動的反饋雖然不如有監(jiān)督學習直接了當,但是卻能降低問題抽象的難度,而且還更看重行動序列所帶來的的整體回報,而不是單步行動的即時收益。
實際上,有一種學習方法的目標和強化學習一致,都是最大化長期回報值,但其學習過程和有監(jiān)督學習類似,收集大量的單步?jīng)Q策的樣本數(shù)據(jù),并讓模型學習這些單步?jīng)Q策的邏輯,這類機器學習算法被稱為“模仿學習”。如圖4所示,模仿學習的執(zhí)行流程為: (1)尋找一些“專家系統(tǒng)”代替智能體和環(huán)境的交互過程,得到一系列的交互序列; (2)假設這些交互序列為對應環(huán)境狀態(tài)下的“標準答案”,就可以使用有監(jiān)督學習讓模型去學習這些數(shù)據(jù),從而完成將環(huán)境狀態(tài)和專家采取的行動相對應的工作。
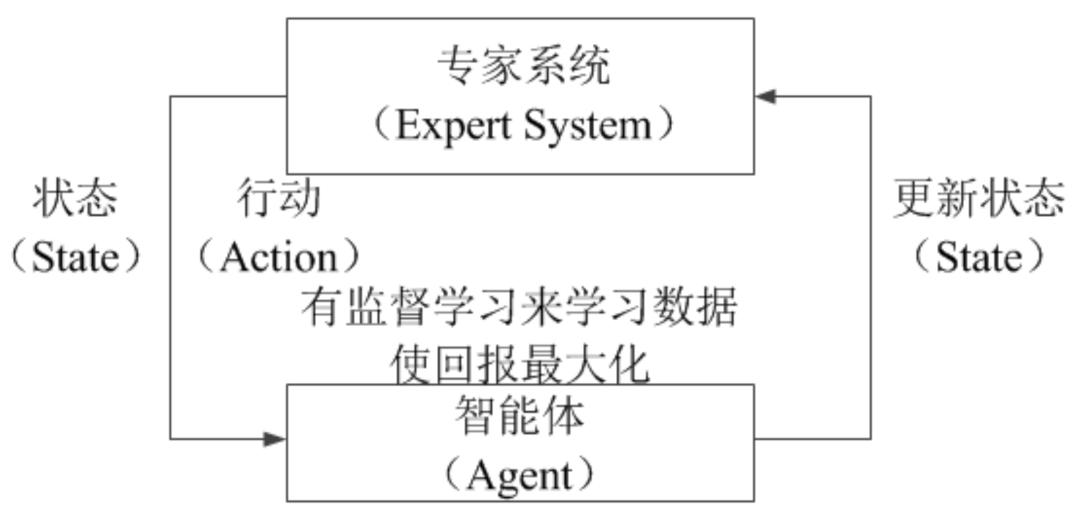
圖4 模仿學習的執(zhí)行流程圖
模仿學習在一些問題上可以獲得比較好的效果,但也有其弊端,那就是: (1)必須要在問題領域中存在一個專家,所有的訓練樣本數(shù)據(jù)都通過專家系統(tǒng)和環(huán)境交互產(chǎn)生; (2)必須要有足夠多數(shù)量的訓練樣本數(shù)據(jù),否則很難學習出一個效果好的行動策略模型; (3)必須確保學習得到的模型擁有足夠的泛化性,否則在實際使用中遇到一些訓練樣本中沒有出現(xiàn)的觀測值,導致泛化能力不夠的智能體出現(xiàn)重大決策失誤; 為了解決以上存在的問題,模仿學習需要從訓練樣本和模型兩方面入手。但實際上這三個問題在現(xiàn)實中都不太容易解決,因此模仿學習的難度并不小,這才使得研究潮流大部分都集中在強化學習上,就是希望強化學習能夠解決模仿學習無法解決的問題。綜上所述,人工智能領域中幾類常見算法之間的關系如下圖5所示:
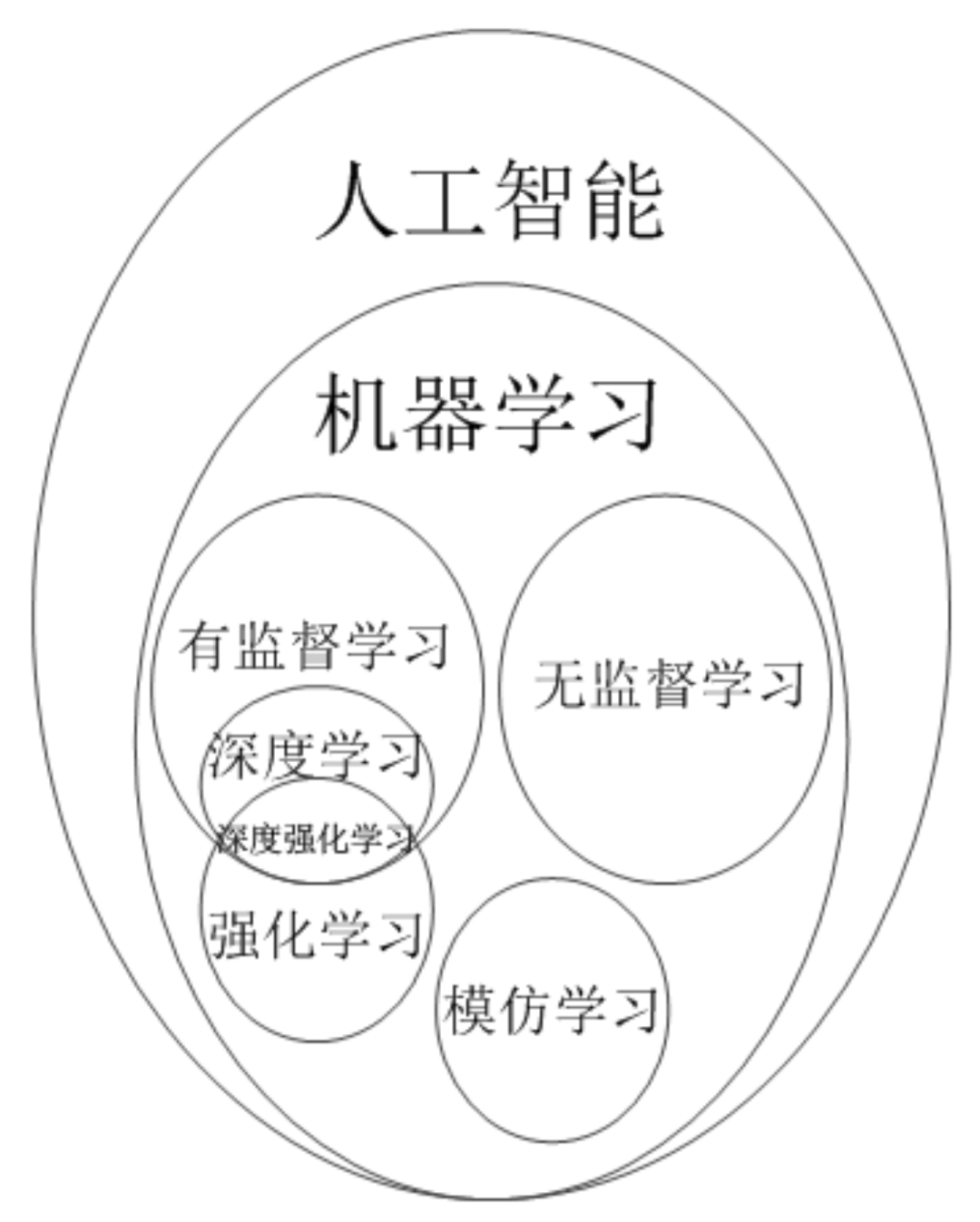
圖5 人工智能中幾類算法之間的關系圖
現(xiàn)如今在工業(yè)界和學術界,受到人們廣泛關注的機器學習計算框架就是谷歌公司在2015年11月9日正式開源的TensorFlow。相比其他的機器學習開源計算工具而言,TensorFlow計算框架能夠很好地支持深度學習和強化學習等多種機器學習算法的實現(xiàn)。TensorFlow既是實現(xiàn)機器學習算法的接口,也是執(zhí)行機器學習算法的框架,其在很多方面都有優(yōu)異的表現(xiàn),比如開發(fā)人員設計神經(jīng)網(wǎng)絡結(jié)構(gòu)的代碼簡潔性和分布式機器學習算法的執(zhí)行效率以及將訓練好的模型部署的便利性。
此外,在強化學習中還要用到的另一個重要框架就是Gym以及在此框架上實現(xiàn)的算法集合Baselines。Gym是一個集成了眾多強化學習實驗環(huán)境的平臺,在該平臺上研究人員可以很方便地搭建起強化學習所需要的仿真環(huán)境,從而集中精力完成行動策略學習的主要工作。Baselines則基于TensorFlow和Gym實現(xiàn)了一些經(jīng)典的強化學習算法。總而言之,Gym實現(xiàn)了強化學習中和系統(tǒng)環(huán)境這個關鍵要素相關的功能,而Baselines實現(xiàn)了與智能體這個關鍵要素相關的功能。 以上內(nèi)容就是對強化學習的定義、高度抽象的框架、特點、主要用途、強化學習與其他幾類主要機器學習算法的本質(zhì)區(qū)別以及機器學習常用的搭建環(huán)境等內(nèi)容的精要概述。
覺得不錯,多多「留言」,點擊「在看」吧↓↓↓
