
面試官:看你簡歷上寫了精通 JVM,我不信
大家好,我是二哥呀!前面分享了 Java 基礎(chǔ)篇、Java 并發(fā)篇的硬核面試題,今天我們來搞定 Java 虛擬機(jī),也就是 JVM。
講真,一個(gè)程序員在其整個(gè)職業(yè)生涯中都可能碰不到 JVM 調(diào)優(yōu),可一旦工作中遇到了,那就是凸顯能力的時(shí)候,可能一舉就奠定了自己在整個(gè)團(tuán)隊(duì)中的核心地位,從此華麗轉(zhuǎn)身,完成逆襲。
就面試而言,JVM 絕對是衡量一名 Java 后端開發(fā)的核心關(guān)鍵點(diǎn),能應(yīng)答如流,那自然就會(huì)令面試官刮目相看。
一句話:吃透 JVM,前程似錦。
一、引言
1.什么是 JVM?
JVM——Java 虛擬機(jī),它是 Java 實(shí)現(xiàn)平臺無關(guān)性的基石。
Java 程序運(yùn)行的時(shí)候,編譯器將 Java 文件編譯成平臺無關(guān)的 Java 字節(jié)碼文件(.class),接下來對應(yīng)平臺 JVM 對字節(jié)碼文件進(jìn)行解釋,翻譯成對應(yīng)平臺匹配的機(jī)器指令并運(yùn)行。

同時(shí) JVM 也是一個(gè)跨語言的平臺,和語言無關(guān),只和 class 的文件格式關(guān)聯(lián),任何語言,只要能翻譯成符合規(guī)范的字節(jié)碼文件,都能被 JVM 運(yùn)行。

二、內(nèi)存管理
2.能說一下 JVM 的內(nèi)存區(qū)域嗎?
JVM 內(nèi)存區(qū)域最粗略的劃分可以分為堆和棧,當(dāng)然,按照虛擬機(jī)規(guī)范,可以劃分為以下幾個(gè)區(qū)域:
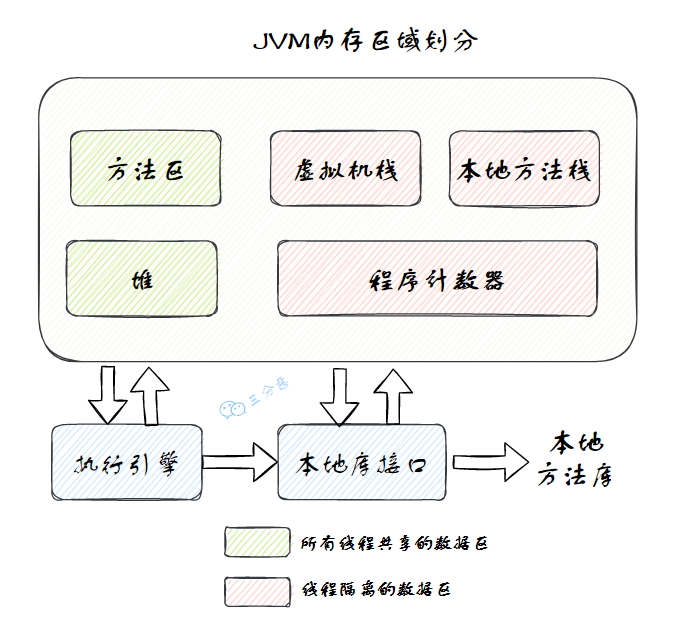
JVM 內(nèi)存分為線程私有區(qū)和線程共享區(qū),其中方法區(qū)和堆是線程共享區(qū),虛擬機(jī)棧、本地方法棧和程序計(jì)數(shù)器是線程隔離的數(shù)據(jù)區(qū)。
1)程序計(jì)數(shù)器
程序計(jì)數(shù)器(Program Counter Register)也被稱為 PC 寄存器,是一塊較小的內(nèi)存空間。
它可以看作是當(dāng)前線程所執(zhí)行的字節(jié)碼的行號指示器。
2)Java 虛擬機(jī)棧
Java 虛擬機(jī)棧(Java Virtual Machine Stack)也是線程私有的,它的生命周期與線程相同。
Java 虛擬機(jī)棧描述的是 Java 方法執(zhí)行的線程內(nèi)存模型:方法執(zhí)行時(shí),JVM 會(huì)同步創(chuàng)建一個(gè)棧幀,用來存儲(chǔ)局部變量表、操作數(shù)棧、動(dòng)態(tài)連接等。
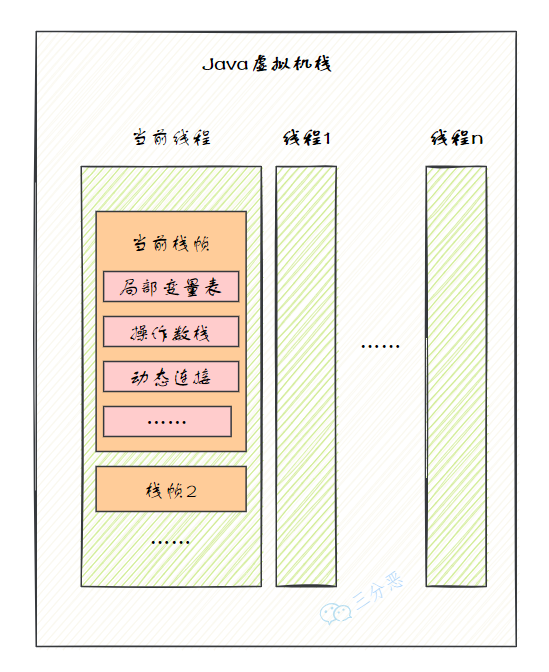
3)本地方法棧
本地方法棧(Native Method Stacks)與虛擬機(jī)棧所發(fā)揮的作用是非常相似的,其區(qū)別只是虛擬機(jī)棧為虛擬機(jī)執(zhí)行 Java 方法(也就是字節(jié)碼)服務(wù),而本地方法棧則是為虛擬機(jī)使用到的本地(Native)方法服務(wù)。
Java 虛擬機(jī)規(guī)范允許本地方法棧被實(shí)現(xiàn)成固定大小的或者是根據(jù)計(jì)算動(dòng)態(tài)擴(kuò)展和收縮的。
4)Java 堆
對于 Java 應(yīng)用程序來說,Java 堆(Java Heap)是虛擬機(jī)所管理的內(nèi)存中最大的一塊。Java 堆是被所有線程共享的一塊內(nèi)存區(qū)域,在虛擬機(jī)啟動(dòng)時(shí)創(chuàng)建。此內(nèi)存區(qū)域的唯一目的就是存放對象實(shí)例,Java 里“幾乎”所有的對象實(shí)例都在這里分配內(nèi)存。
Java 堆是垃圾收集器管理的內(nèi)存區(qū)域,因此一些資料中它也被稱作“GC 堆”(Garbage Collected Heap,)。從回收內(nèi)存的角度看,由于現(xiàn)代垃圾收集器大部分都是基于分代收集理論設(shè)計(jì)的,所以 Java 堆中經(jīng)常會(huì)出現(xiàn)新生代、老年代、Eden空間、From Survivor空間、To Survivor空間等名詞,需要注意的是這種劃分只是根據(jù)垃圾回收機(jī)制來進(jìn)行的劃分,不是 Java 虛擬機(jī)規(guī)范本身制定的。

5)方法區(qū)
方法區(qū)是比較特別的一塊區(qū)域,和堆類似,它也是各個(gè)線程共享的內(nèi)存區(qū)域,用于存儲(chǔ)已被虛擬機(jī)加載的類型信息、常量、靜態(tài)變量、即時(shí)編譯器編譯后的代碼緩存等數(shù)據(jù)。
它特別在 Java 虛擬機(jī)規(guī)范對它的約束非常寬松,所以方法區(qū)的具體實(shí)現(xiàn)歷經(jīng)了許多變遷,例如 jdk1.7 之前使用永久代作為方法區(qū)的實(shí)現(xiàn)。
3.說一下 JDK1.6、1.7、1.8 內(nèi)存區(qū)域的變化?
JDK1.6、1.7/1.8 內(nèi)存區(qū)域發(fā)生了變化,主要體現(xiàn)在方法區(qū)的實(shí)現(xiàn):
JDK1.6 使用永久代實(shí)現(xiàn)方法區(qū):
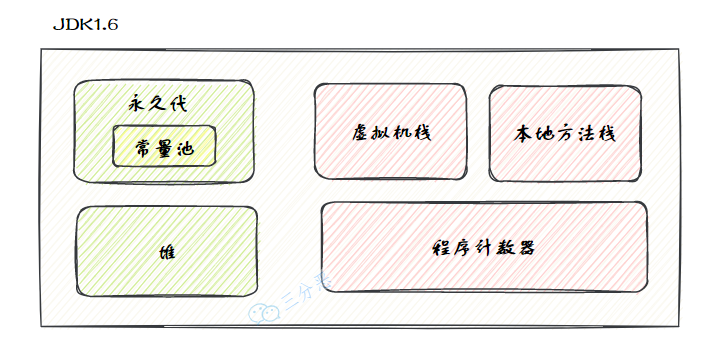
JDK1.7 時(shí)發(fā)生了一些變化,將字符串常量池、靜態(tài)變量,存放在堆上

在 JDK1.8 時(shí)徹底干掉了永久代,而在直接內(nèi)存中劃出一塊區(qū)域作為元空間,運(yùn)行時(shí)常量池、類常量池都移動(dòng)到元空間。
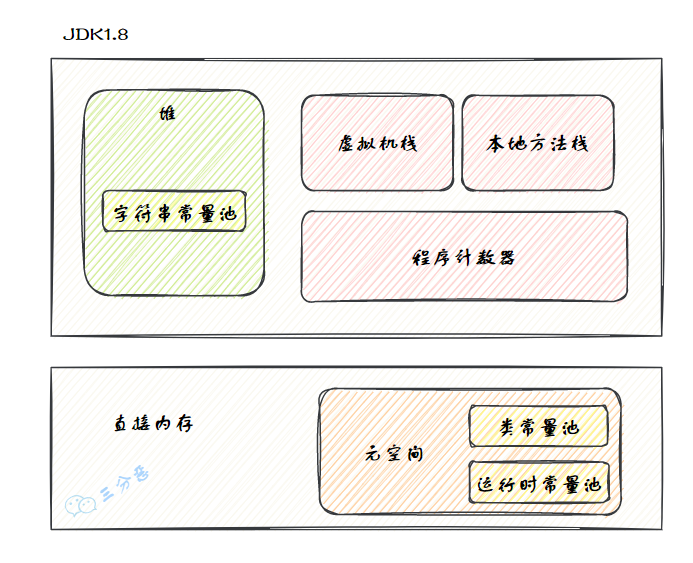
JDK 1.8內(nèi)存區(qū)域
4.為什么使用元空間替代永久代作為方法區(qū)的實(shí)現(xiàn)?
Java 虛擬機(jī)規(guī)范規(guī)定的方法區(qū)只是換種方式實(shí)現(xiàn)。有客觀和主觀兩個(gè)原因。
客觀上使用永久代來實(shí)現(xiàn)方法區(qū)的決定的設(shè)計(jì)導(dǎo)致了 Java 應(yīng)用更容易遇到內(nèi)存溢出的問題(永久代有-XX:MaxPermSize 的上限,即使不設(shè)置也有默認(rèn)大小,而 J9 和 JRockit 只要沒有觸碰到進(jìn)程可用內(nèi)存的上限,例如 32 位系統(tǒng)中的 4GB 限制,就不會(huì)出問題),而且有極少數(shù)方法 (例如 String::intern())會(huì)因永久代的原因而導(dǎo)致不同虛擬機(jī)下有不同的表現(xiàn)。
主觀上當(dāng) Oracle 收購 BEA 獲得了 JRockit 的所有權(quán)后,準(zhǔn)備把 JRockit 中的優(yōu)秀功能,譬如 Java Mission Control 管理工具,移植到 HotSpot 虛擬機(jī)時(shí),但因?yàn)閮烧邔Ψ椒▍^(qū)實(shí)現(xiàn)的差異而面臨諸多困難。考慮到 HotSpot 未來的發(fā)展,在 JDK 6 的 時(shí)候 HotSpot 開發(fā)團(tuán)隊(duì)就有放棄永久代,逐步改為采用本地內(nèi)存(Native Memory)來實(shí)現(xiàn)方法區(qū)的計(jì)劃了,到了 JDK 7 的 HotSpot,已經(jīng)把原本放在永久代的字符串常量池、靜態(tài)變量等移出,而到了 JDK 8,終于完全廢棄了永久代的概念,改用與 JRockit、J9 一樣在本地內(nèi)存中實(shí)現(xiàn)的元空間(Meta-space)來代替,把 JDK 7 中永久代還剩余的內(nèi)容(主要是類型信息)全部移到元空間中。
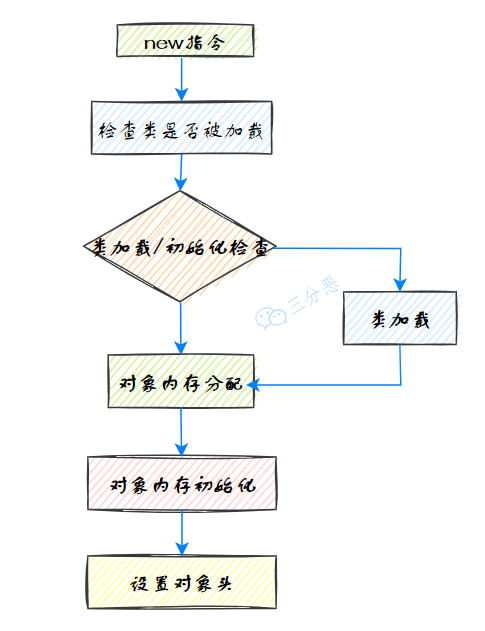
5.對象創(chuàng)建的過程了解嗎?
在 JVM 中對象的創(chuàng)建,我們從一個(gè) new 指令開始:
首先檢查這個(gè)指令的參數(shù)是否能在常量池中定位到一個(gè)類的符號引用
檢查這個(gè)符號引用代表的類是否已被加載、解析和初始化過。如果沒有,就先執(zhí)行相應(yīng)的類加載過程
類加載檢查通過后,接下來虛擬機(jī)將為新生對象分配內(nèi)存。
內(nèi)存分配完成之后,虛擬機(jī)將分配到的內(nèi)存空間(但不包括對象頭)都初始化為零值。
接下來設(shè)置對象頭,請求頭里包含了對象是哪個(gè)類的實(shí)例、如何才能找到類的元數(shù)據(jù)信息、對象的哈希碼、對象的 GC 分代年齡等信息。
這個(gè)過程大概圖示如下:
6.什么是指針碰撞?什么是空閑列表?
內(nèi)存分配有兩種方式,指針碰撞(Bump The Pointer)、空閑列表(Free List)。
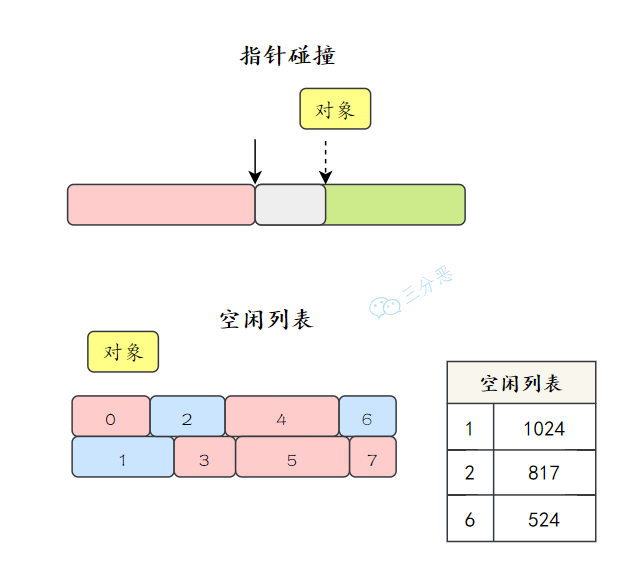
指針碰撞:假設(shè) Java 堆中內(nèi)存是絕對規(guī)整的,所有被使用過的內(nèi)存都被放在一邊,空閑的內(nèi)存被放在另一邊,中間放著一個(gè)指針作為分界點(diǎn)的指示器,那所分配內(nèi)存就僅僅是把那個(gè)指針向空閑空間方向挪動(dòng)一段與對象大小相等的距離,這種分配方式稱為“指針碰撞”。 空閑列表:如果 Java 堆中的內(nèi)存并不是規(guī)整的,已被使用的內(nèi)存和空閑的內(nèi)存相互交錯(cuò)在一起,那就沒有辦法簡單地進(jìn)行指針碰撞了,虛擬機(jī)就必須維護(hù)一個(gè)列表,記錄上哪些內(nèi)存塊是可用的,在分配的時(shí)候從列表中找到一塊足夠大的空間劃分給對象實(shí)例,并更新列表上的記錄,這種分配方式稱為“空閑列表”。 兩種方式的選擇由 Java 堆是否規(guī)整決定,Java 堆是否規(guī)整是由選擇的垃圾收集器是否具有壓縮整理能力決定的。
7.JVM 里 new 對象時(shí),堆會(huì)發(fā)生搶占嗎?JVM 是怎么設(shè)計(jì)來保證線程安全的?
會(huì),假設(shè) JVM 虛擬機(jī)上,每一次 new 對象時(shí),指針就會(huì)向右移動(dòng)一個(gè)對象 size 的距離,一個(gè)線程正在給 A 對象分配內(nèi)存,指針還沒有來的及修改,另一個(gè)為 B 對象分配內(nèi)存的線程,又引用了這個(gè)指針來分配內(nèi)存,這就發(fā)生了搶占。
有兩種可選方案來解決這個(gè)問題:
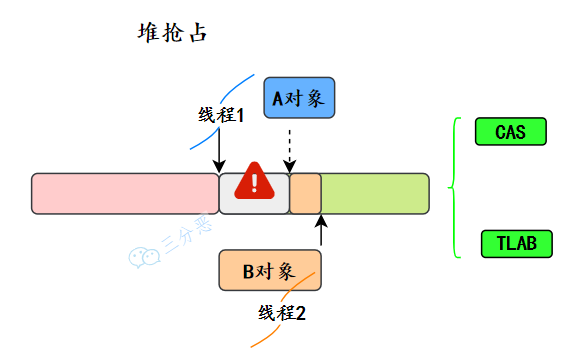
采用 CAS 分配重試的方式來保證更新操作的原子性
每個(gè)線程在 Java 堆中預(yù)先分配一小塊內(nèi)存,也就是本地線程分配緩沖(Thread Local Allocation
Buffer,TLAB),要分配內(nèi)存的線程,先在本地緩沖區(qū)中分配,只有本地緩沖區(qū)用完了,分配新的緩存區(qū)時(shí)才需要同步鎖定。
8.能說一下對象的內(nèi)存布局嗎?
在 HotSpot 虛擬機(jī)里,對象在堆內(nèi)存中的存儲(chǔ)布局可以劃分為三個(gè)部分:對象頭(Header)、實(shí)例數(shù)據(jù)(Instance Data)和對齊填充(Padding)。

對象頭主要由兩部分組成:
第一部分存儲(chǔ)對象自身的運(yùn)行時(shí)數(shù)據(jù):哈希碼、GC 分代年齡、鎖狀態(tài)標(biāo)志、線程持有的鎖、偏向線程 ID、偏向時(shí)間戳等,官方稱它為 Mark Word,它是個(gè)動(dòng)態(tài)的結(jié)構(gòu),隨著對象狀態(tài)變化。 第二部分是類型指針,指向?qū)ο蟮念愒獢?shù)據(jù)類型(即對象代表哪個(gè)類)。 此外,如果對象是一個(gè) Java 數(shù)組,那還應(yīng)該有一塊用于記錄數(shù)組長度的數(shù)據(jù)
實(shí)例數(shù)據(jù)用來存儲(chǔ)對象真正的有效信息,也就是我們在程序代碼里所定義的各種類型的字段內(nèi)容,無論是從父類繼承的,還是自己定義的。
對齊填充不是必須的,沒有特別含義,僅僅起著占位符的作用。
9.對象怎么訪問定位?
Java 程序會(huì)通過棧上的 reference 數(shù)據(jù)來操作堆上的具體對象。由于 reference 類型在《Java 虛擬機(jī)規(guī)范》里面只規(guī)定了它是一個(gè)指向?qū)ο蟮囊茫]有定義這個(gè)引用應(yīng)該通過什么方式去定位、訪問到堆中對象的具體位置,所以對象訪問方式也是由虛擬機(jī)實(shí)現(xiàn)而定的,主流的訪問方式主要有使用句柄和直接指針兩種:
如果使用句柄訪問的話,Java 堆中將可能會(huì)劃分出一塊內(nèi)存來作為句柄池,reference 中存儲(chǔ)的就是對象的句柄地址,而句柄中包含了對象實(shí)例數(shù)據(jù)與類型數(shù)據(jù)各自具體的地址信息,其結(jié)構(gòu)如圖所示:
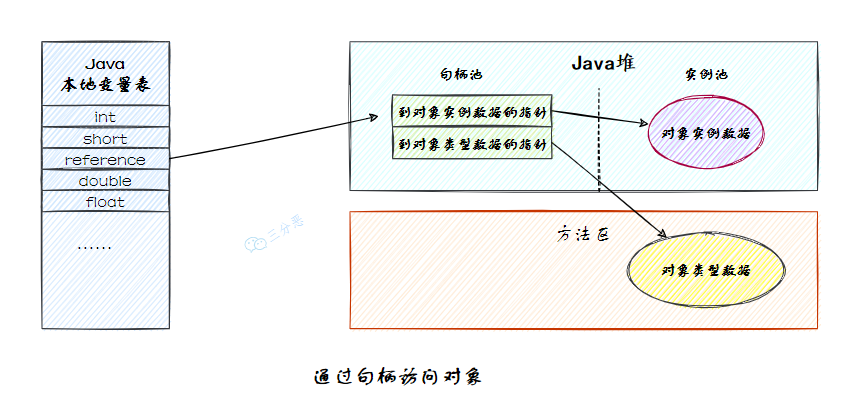
如果使用直接指針訪問的話,Java 堆中對象的內(nèi)存布局就必須考慮如何放置訪問類型數(shù)據(jù)的相關(guān)信息,reference 中存儲(chǔ)的直接就是對象地址,如果只是訪問對象本身的話,就不需要多一次間接訪問的開銷,如圖所示:

這兩種對象訪問方式各有優(yōu)勢,使用句柄來訪問的最大好處就是 reference 中存儲(chǔ)的是穩(wěn)定句柄地址,在對象被移動(dòng)(垃圾收集時(shí)移動(dòng)對象是非常普遍的行為)時(shí)只會(huì)改變句柄中的實(shí)例數(shù)據(jù)指針,而 reference 本身不需要被修改。
使用直接指針來訪問最大的好處就是速度更快,它節(jié)省了一次指針定位的時(shí)間開銷,由于對象訪問在 Java 中非常頻繁,因此這類開銷積少成多也是一項(xiàng)極為可觀的執(zhí)行成本。
HotSpot 虛擬機(jī)主要使用直接指針來進(jìn)行對象訪問。
10.內(nèi)存溢出和內(nèi)存泄漏是什么意思?
內(nèi)存泄露就是申請的內(nèi)存空間沒有被正確釋放,導(dǎo)致內(nèi)存被白白占用。
內(nèi)存溢出就是申請的內(nèi)存超過了可用內(nèi)存,內(nèi)存不夠了。
兩者關(guān)系:內(nèi)存泄露可能會(huì)導(dǎo)致內(nèi)存溢出。
用一個(gè)有味道的比喻,內(nèi)存溢出就是排隊(duì)去蹲坑,發(fā)現(xiàn)沒坑位了,內(nèi)存泄漏,就是有人占著茅坑不拉屎,占著茅坑不拉屎的多了可能會(huì)導(dǎo)致坑位不夠用。

11.能手寫內(nèi)存溢出的例子嗎?
在 JVM 的幾個(gè)內(nèi)存區(qū)域中,除了程序計(jì)數(shù)器外,其他幾個(gè)運(yùn)行時(shí)區(qū)域都有發(fā)生內(nèi)存溢出(OOM)異常的可能,重點(diǎn)關(guān)注堆和棧。
Java 堆溢出
Java 堆用于儲(chǔ)存對象實(shí)例,只要不斷創(chuàng)建不可被回收的對象,比如靜態(tài)對象,那么隨著對象數(shù)量的增加,總?cè)萘坑|及最大堆的容量限制后就會(huì)產(chǎn)生內(nèi)存溢出異常(OutOfMemoryError)。
這就相當(dāng)于一個(gè)房子里,不斷堆積不能被收走的雜物,那么房子很快就會(huì)被堆滿了。
/**
?* VM參數(shù):?-Xms20m -Xmx20m -XX:+HeapDumpOnOutOfMemoryError
?*/
public?class?HeapOOM?{
????static?class?OOMObject?{
????}
????public?static?void?main(String[]?args)?{
????????List?list?=?new?ArrayList();
????????while?(true)?{
????????????list.add(new?OOMObject());
????????}
????}
}
虛擬機(jī)棧.OutOfMemoryError
JDK 使用的 HotSpot 虛擬機(jī)的棧內(nèi)存大小是固定的,我們可以把棧的內(nèi)存設(shè)大一點(diǎn),然后不斷地去創(chuàng)建線程,因?yàn)椴僮飨到y(tǒng)給每個(gè)進(jìn)程分配的內(nèi)存是有限的,所以到最后,也會(huì)發(fā)生 OutOfMemoryError 異常。
/**
?* vm參數(shù):-Xss2M
?*/
public?class?JavaVMStackOOM?{
????private?void?dontStop()?{
????????while?(true)?{
????????}
????}
????public?void?stackLeakByThread()?{
????????while?(true)?{
????????????Thread?thread?=?new?Thread(new?Runnable()?{
????????????????public?void?run()?{
????????????????????dontStop();
????????????????}
????????????});
????????????thread.start();
????????}
????}
????public?static?void?main(String[]?args)?throws?Throwable?{
????????JavaVMStackOOM?oom?=?new?JavaVMStackOOM();
????????oom.stackLeakByThread();
????}
}
12.內(nèi)存泄漏可能由哪些原因?qū)е履兀?span style="display: none;">
內(nèi)存泄漏可能的原因有很多種:

靜態(tài)集合類引起內(nèi)存泄漏
靜態(tài)集合的生命周期和 JVM 一致,所以靜態(tài)集合引用的對象不能被釋放。
public?class?OOM?{
?static?List?list?=?new?ArrayList();
?public?void?oomTests(){
???Object?obj?=?new?Object();
???list.add(obj);
??}
}
單例模式
和上面的例子原理類似,單例對象在初始化后會(huì)以靜態(tài)變量的方式在 JVM 的整個(gè)生命周期中存在。如果單例對象持有外部的引用,那么這個(gè)外部對象將不能被 GC 回收,導(dǎo)致內(nèi)存泄漏。
數(shù)據(jù)連接、IO、Socket 等連接
創(chuàng)建的連接不再使用時(shí),需要調(diào)用 close 方法關(guān)閉連接,只有連接被關(guān)閉后,GC 才會(huì)回收對應(yīng)的對象(Connection,Statement,ResultSet,Session)。忘記關(guān)閉這些資源會(huì)導(dǎo)致持續(xù)占有內(nèi)存,無法被 GC 回收。
????????try?{
????????????Connection?conn?=?null;
????????????Class.forName("com.mysql.jdbc.Driver");
????????????conn?=?DriverManager.getConnection("url",?"",?"");
????????????Statement?stmt?=?conn.createStatement();
????????????ResultSet?rs?=?stmt.executeQuery("....");
??????????}?catch?(Exception?e)?{
??????????}finally?{
????????????//不關(guān)閉連接
??????????}
????????}
變量不合理的作用域
一個(gè)變量的定義作用域大于其使用范圍,很可能存在內(nèi)存泄漏;或不再使用對象沒有及時(shí)將對象設(shè)置為 null,很可能導(dǎo)致內(nèi)存泄漏的發(fā)生。
public?class?Simple?{
????Object?object;
????public?void?method1(){
????????object?=?new?Object();
????????//...其他代碼
????????//由于作用域原因,method1執(zhí)行完成之后,object?對象所分配的內(nèi)存不會(huì)馬上釋放
????????object?=?null;
????}
}
hash 值發(fā)生變化
對象 Hash 值改變,使用 HashMap、HashSet 等容器中時(shí)候,由于對象修改之后的 Hah 值和存儲(chǔ)進(jìn)容器時(shí)的 Hash 值不同,所以無法找到存入的對象,自然也無法單獨(dú)刪除了,這也會(huì)造成內(nèi)存泄漏。說句題外話,這也是為什么 String 類型被設(shè)置成了不可變類型。
ThreadLocal 使用不當(dāng)
ThreadLocal 的弱引用導(dǎo)致內(nèi)存泄漏也是個(gè)老生常談的話題了,使用完 ThreadLocal 一定要記得使用 remove 方法來進(jìn)行清除。
13.如何判斷對象仍然存活?
有兩種方式,引用計(jì)數(shù)算法(reference counting)和可達(dá)性分析算法。
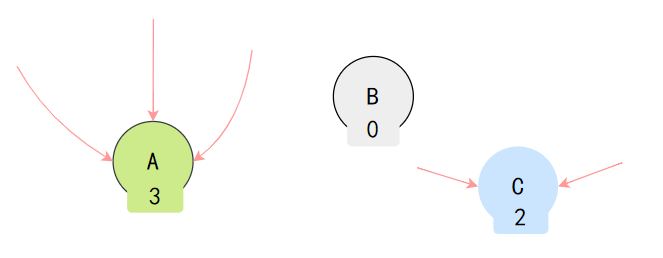
引用計(jì)數(shù)算法
引用計(jì)數(shù)器的算法是這樣的:在對象中添加一個(gè)引用計(jì)數(shù)器,每當(dāng)有一個(gè)地方引用它時(shí),計(jì)數(shù)器值就加一;當(dāng)引用失效時(shí),計(jì)數(shù)器值就減一;任何時(shí)刻計(jì)數(shù)器為零的對象就是不可能再被使用的。
可達(dá)性分析算法
目前 Java 虛擬機(jī)的主流垃圾回收器采取的是可達(dá)性分析算法。這個(gè)算法的實(shí)質(zhì)在于將一系列 GC Roots 作為初始的存活對象合集(Gc Root Set),然后從該合集出發(fā),探索所有能夠被該集合引用到的對象,并將其加入到該集合中,這個(gè)過程我們也稱之為標(biāo)記(mark)。最終,未被探索到的對象便是死亡的,是可以回收的。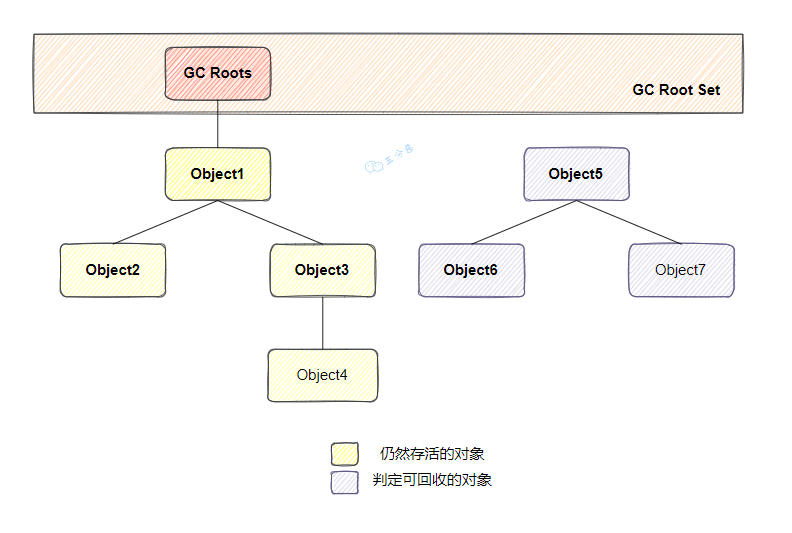
14.Java 中可作為 GC Roots 的對象有哪幾種?
可以作為 GC Roots 的主要有四種對象:
虛擬機(jī)棧(棧幀中的本地變量表)中引用的對象 方法區(qū)中類靜態(tài)屬性引用的對象 方法區(qū)中常量引用的對象 本地方法棧中 JNI 引用的對象
15.說一下對象有哪幾種引用?
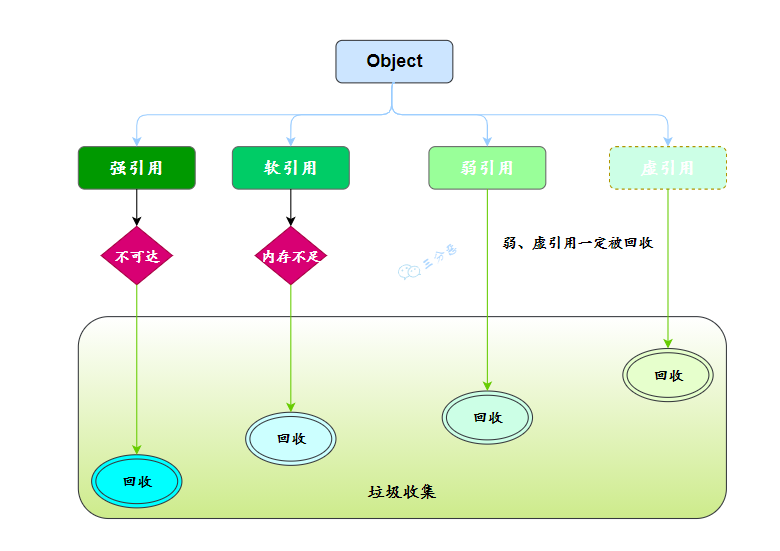
Java 中的引用有四種,分為強(qiáng)引用(Strongly Reference)、軟引用(Soft Reference)、弱引用(Weak Reference)和虛引用(Phantom Reference)4 種,這 4 種引用強(qiáng)度依次逐漸減弱。
強(qiáng)引用是最傳統(tǒng)的 引用的定義,是指在程序代碼之中普遍存在的引用賦值,無論任何情況下,只要強(qiáng)引用關(guān)系還存在,垃圾收集器就永遠(yuǎn)不會(huì)回收掉被引用的對象。
Object?obj?=new?Object();
軟引用是用來描述一些還有用,但非必須的對象。只被軟引用關(guān)聯(lián)著的對象,在系統(tǒng)將要發(fā)生內(nèi)存溢出異常前,會(huì)把這些對象列進(jìn)回收范圍之中進(jìn)行第二次回收,如果這次回收還沒有足夠的內(nèi)存, 才會(huì)拋出內(nèi)存溢出異常。在 JDK 1.2 版之后提供了 SoftReference 類來實(shí)現(xiàn)軟引用。
????????Object?obj?=?new?Object();
????????ReferenceQueue?queue?=?new?ReferenceQueue();
????????SoftReference?reference?=?new?SoftReference(obj,?queue);
????????//強(qiáng)引用對象滯空,保留軟引用
????????obj?=?null;
弱引用也是用來描述那些非必須對象,但是它的強(qiáng)度比軟引用更弱一些,被弱引用關(guān)聯(lián)的對象只能生存到下一次垃圾收集發(fā)生為止。當(dāng)垃圾收集器開始工作,無論當(dāng)前內(nèi)存是否足夠,都會(huì)回收掉只被弱引用關(guān)聯(lián)的對象。在 JDK 1.2 版之后提供了 WeakReference 類來實(shí)現(xiàn)弱引用。
????????Object?obj?=?new?Object();
????????ReferenceQueue?queue?=?new?ReferenceQueue();
????????WeakReference?reference?=?new?WeakReference(obj,?queue);
????????//強(qiáng)引用對象滯空,保留軟引用
????????obj?=?null;
虛引用也稱為“幽靈引用”或者“幻影引用”,它是最弱的一種引用關(guān)系。一個(gè)對象是否有虛引用的存在,完全不會(huì)對其生存時(shí)間構(gòu)成影響,也無法通過虛引用來取得一個(gè)對象實(shí)例。為一個(gè)對象設(shè)置虛引用關(guān)聯(lián)的唯一目的只是為了能在這個(gè)對象被收集器回收時(shí)收到一個(gè)系統(tǒng)通知。在 JDK 1.2 版之后提供了 PhantomReference 類來實(shí)現(xiàn)虛引用。
????????Object?obj?=?new?Object();
????????ReferenceQueue?queue?=?new?ReferenceQueue();
????????PhantomReference?reference?=?new?PhantomReference(obj,?queue);
????????//強(qiáng)引用對象滯空,保留軟引用
????????obj?=?null;
16.finalize()方法了解嗎?有什么作用?
用一個(gè)不太貼切的比喻,垃圾回收就是古代的秋后問斬,finalize()就是刀下留人,在人犯被處決之前,還要做最后一次審計(jì),青天大老爺看看有沒有什么冤情,需不需要刀下留人。

如果對象在進(jìn)行可達(dá)性分析后發(fā)現(xiàn)沒有與 GC Roots 相連接的引用鏈,那它將會(huì)被第一次標(biāo)記,隨后進(jìn)行一次篩選,篩選的條件是此對象是否有必要執(zhí)行 finalize()方法。如果對象在在 finalize()中成功拯救自己——只要重新與引用鏈上的任何一個(gè)對象建立關(guān)聯(lián)即可,譬如把自己 (this 關(guān)鍵字)賦值給某個(gè)類變量或者對象的成員變量,那在第二次標(biāo)記時(shí)它就”逃過一劫“;但是如果沒有抓住這個(gè)機(jī)會(huì),那么對象就真的要被回收了。
17.Java 堆的內(nèi)存分區(qū)了解嗎?
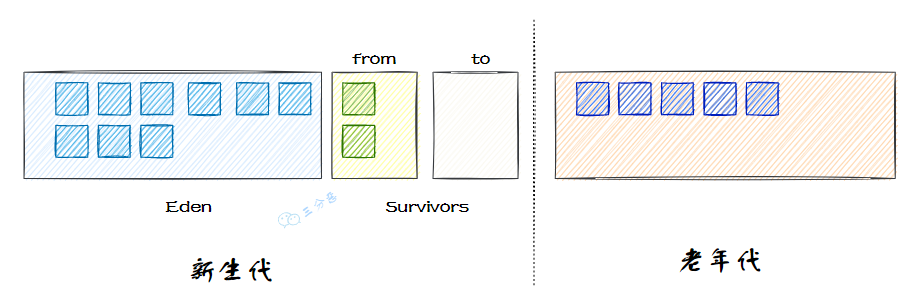
按照垃圾收集,將 Java 堆劃分為新生代 (Young Generation)和老年代(Old Generation)兩個(gè)區(qū)域,新生代存放存活時(shí)間短的對象,而每次回收后存活的少量對象,將會(huì)逐步晉升到老年代中存放。
而新生代又可以分為三個(gè)區(qū)域,eden、from、to,比例是 8:1:1,而新生代的內(nèi)存分區(qū)同樣是從垃圾收集的角度來分配的。
18.垃圾收集算法了解嗎?
垃圾收集算法主要有三種:
標(biāo)記-清除算法
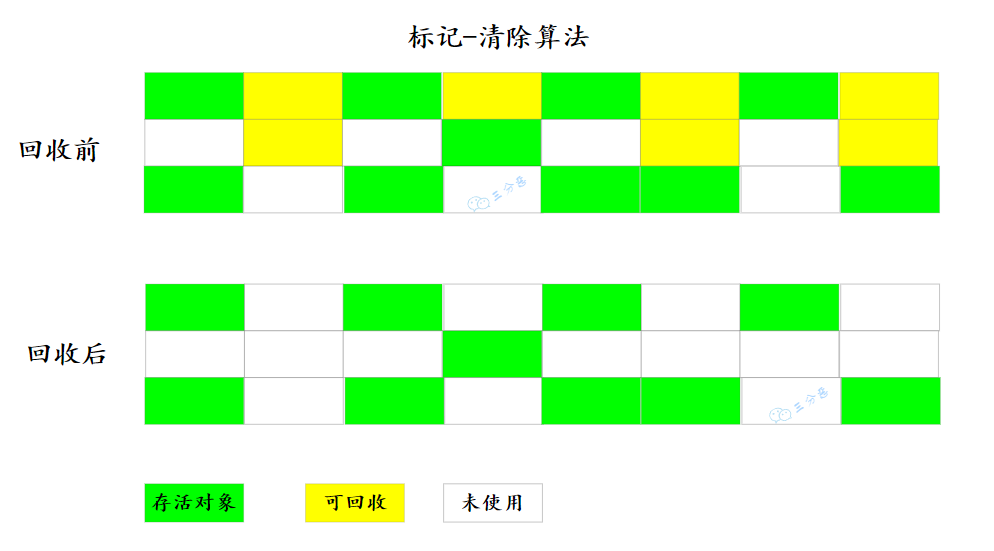
見名知義,標(biāo)記-清除(Mark-Sweep)算法分為兩個(gè)階段:
標(biāo)記 : 標(biāo)記出所有需要回收的對象 清除:回收所有被標(biāo)記的對象
標(biāo)記-清除算法比較基礎(chǔ),但是主要存在兩個(gè)缺點(diǎn):
執(zhí)行效率不穩(wěn)定,如果 Java 堆中包含大量對象,而且其中大部分是需要被回收的,這時(shí)必須進(jìn)行大量標(biāo)記和清除的動(dòng)作,導(dǎo)致標(biāo)記和清除兩個(gè)過程的執(zhí)行效率都隨對象數(shù)量增長而降低。 內(nèi)存空間的碎片化問題,標(biāo)記、清除之后會(huì)產(chǎn)生大量不連續(xù)的內(nèi)存碎片,空間碎片太多可能會(huì)導(dǎo)致當(dāng)以后在程序運(yùn)行過程中需要分配較大對象時(shí)無法找到足夠的連續(xù)內(nèi)存而不得不提前觸發(fā)另一次垃圾收集動(dòng)作。
標(biāo)記-復(fù)制算法
標(biāo)記-復(fù)制算法解決了標(biāo)記-清除算法面對大量可回收對象時(shí)執(zhí)行效率低的問題。
過程也比較簡單:將可用內(nèi)存按容量劃分為大小相等的兩塊,每次只使用其中的一塊。當(dāng)這一塊的內(nèi)存用完了,就將還存活著的對象復(fù)制到另外一塊上面,然后再把已使用過的內(nèi)存空間一次清理掉。

這種算法存在一個(gè)明顯的缺點(diǎn):一部分空間沒有使用,存在空間的浪費(fèi)。
新生代垃圾收集主要采用這種算法,因?yàn)樾律拇婊顚ο蟊容^少,每次復(fù)制的只是少量的存活對象。當(dāng)然,實(shí)際新生代的收集不是按照這個(gè)比例。
標(biāo)記-整理算法
為了降低內(nèi)存的消耗,引入一種針對性的算法:標(biāo)記-整理(Mark-Compact)算法。
其中的標(biāo)記過程仍然與“標(biāo)記-清除”算法一樣,但后續(xù)步驟不是直接對可回收對象進(jìn)行清理,而是讓所有存活的對象都向內(nèi)存空間一端移動(dòng),然后直接清理掉邊界以外的內(nèi)存。
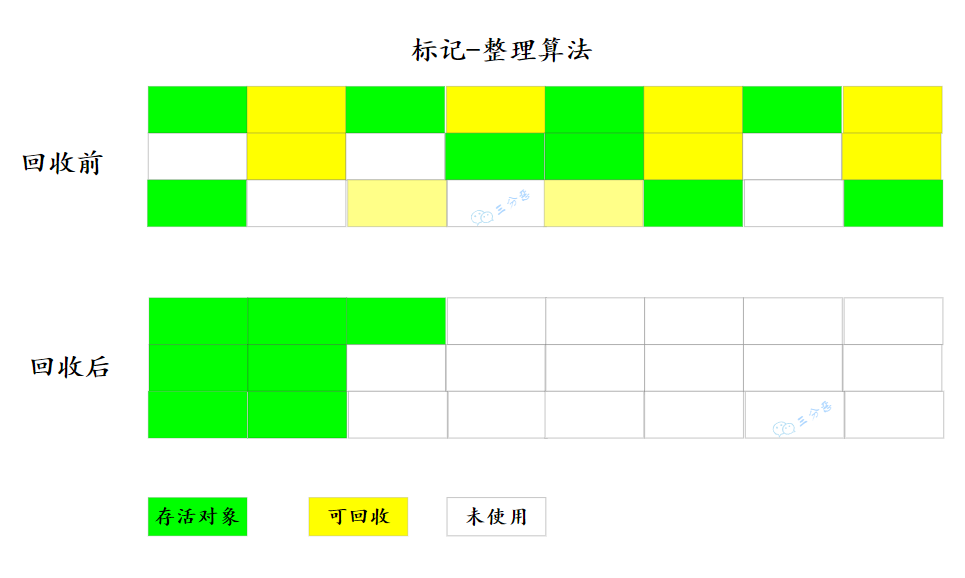
標(biāo)記-整理算法主要用于老年代,移動(dòng)存活對象是個(gè)極為負(fù)重的操作,而且這種操作需要 Stop The World 才能進(jìn)行,只是從整體的吞吐量來考量,老年代使用標(biāo)記-整理算法更加合適。
19.說一下新生代的區(qū)域劃分?
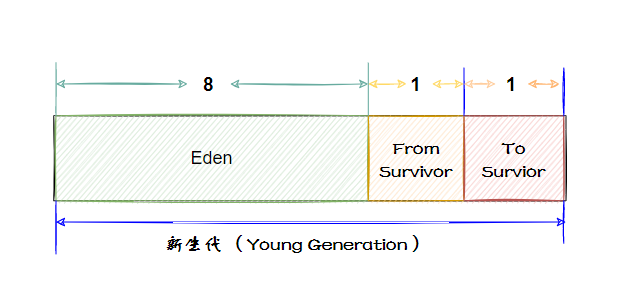
新生代的垃圾收集主要采用標(biāo)記-復(fù)制算法,因?yàn)樾律拇婊顚ο蟊容^少,每次復(fù)制少量的存活對象效率比較高。
基于這種算法,虛擬機(jī)將內(nèi)存分為一塊較大的 Eden 空間和兩塊較小的 Survivor 空間,每次分配內(nèi)存只使用 Eden 和其中一塊 Survivor。發(fā)生垃圾收集時(shí),將 Eden 和 Survivor 中仍然存活的對象一次性復(fù)制到另外一塊 Survivor 空間上,然后直接清理掉 Eden 和已用過的那塊 Survivor 空間。默認(rèn) Eden 和 Survivor 的大小比例是 8∶1。
20.Minor GC/Young GC、Major GC/Old GC、Mixed GC、Full GC 都是什么意思?
部分收集(Partial GC):指目標(biāo)不是完整收集整個(gè) Java 堆的垃圾收集,其中又分為:
新生代收集(Minor GC/Young GC):指目標(biāo)只是新生代的垃圾收集。 老年代收集(Major GC/Old GC):指目標(biāo)只是老年代的垃圾收集。目前只有CMS 收集器會(huì)有單獨(dú)收集老年代的行為。 混合收集(Mixed GC):指目標(biāo)是收集整個(gè)新生代以及部分老年代的垃圾收集。目前只有 G1 收集器會(huì)有這種行為。
整堆收集(Full GC):收集整個(gè) Java 堆和方法區(qū)的垃圾收集。
21.Minor GC/Young GC 什么時(shí)候觸發(fā)?
新創(chuàng)建的對象優(yōu)先在新生代 Eden 區(qū)進(jìn)行分配,如果 Eden 區(qū)沒有足夠的空間時(shí),就會(huì)觸發(fā) Young GC 來清理新生代。
22.什么時(shí)候會(huì)觸發(fā) Full GC?
這個(gè)觸發(fā)條件稍微有點(diǎn)多,往下看:
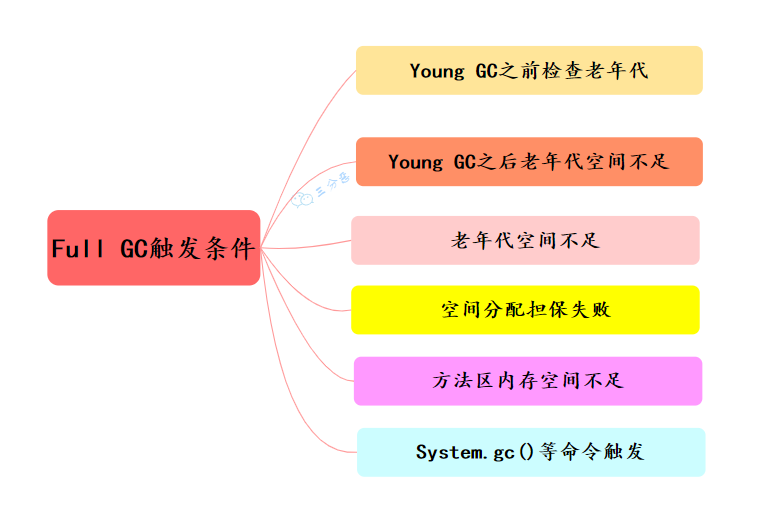
Young GC 之前檢查老年代:在要進(jìn)行 Young GC 的時(shí)候,發(fā)現(xiàn) 老年代可用的連續(xù)內(nèi)存空間<新生代歷次Young GC后升入老年代的對象總和的平均大小,說明本次 Young GC 后可能升入老年代的對象大小,可能超過了老年代當(dāng)前可用內(nèi)存空間,那就會(huì)觸發(fā) Full GC。Young GC 之后老年代空間不足:執(zhí)行 Young GC 之后有一批對象需要放入老年代,此時(shí)老年代就是沒有足夠的內(nèi)存空間存放這些對象了,此時(shí)必須立即觸發(fā)一次 Full GC 老年代空間不足,老年代內(nèi)存使用率過高,達(dá)到一定比例,也會(huì)觸發(fā) Full GC。 空間分配擔(dān)保失敗( Promotion Failure),新生代的 To 區(qū)放不下從 Eden 和 From 拷貝過來對象,或者新生代對象 GC 年齡到達(dá)閾值需要晉升這兩種情況,老年代如果放不下的話都會(huì)觸發(fā) Full GC。 方法區(qū)內(nèi)存空間不足:如果方法區(qū)由永久代實(shí)現(xiàn),永久代空間不足 Full GC。 System.gc()等命令觸發(fā):System.gc()、jmap -dump 等命令會(huì)觸發(fā) full gc。
23.對象什么時(shí)候會(huì)進(jìn)入老年代?

長期存活的對象將進(jìn)入老年代
在對象的對象頭信息中存儲(chǔ)著對象的迭代年齡,迭代年齡會(huì)在每次 YoungGC 之后對象的移區(qū)操作中增加,每一次移區(qū)年齡加一.當(dāng)這個(gè)年齡達(dá)到 15(默認(rèn))之后,這個(gè)對象將會(huì)被移入老年代。
可以通過這個(gè)參數(shù)設(shè)置這個(gè)年齡值。
-?XX:MaxTenuringThreshold
大對象直接進(jìn)入老年代
有一些占用大量連續(xù)內(nèi)存空間的對象在被加載就會(huì)直接進(jìn)入老年代.這樣的大對象一般是一些數(shù)組,長字符串之類的對。
HotSpot 虛擬機(jī)提供了這個(gè)參數(shù)來設(shè)置。
-XX:PretenureSizeThreshold
動(dòng)態(tài)對象年齡判定
為了能更好地適應(yīng)不同程序的內(nèi)存狀況,HotSpot 虛擬機(jī)并不是永遠(yuǎn)要求對象的年齡必須達(dá)到- XX:MaxTenuringThreshold 才能晉升老年代,如果在 Survivor 空間中相同年齡所有對象大小的總和大于 Survivor 空間的一半,年齡大于或等于該年齡的對象就可以直接進(jìn)入老年代。
空間分配擔(dān)保
假如在 Young GC 之后,新生代仍然有大量對象存活,就需要老年代進(jìn)行分配擔(dān)保,把 Survivor 無法容納的對象直接送入老年代。
24.知道有哪些垃圾收集器嗎?
主要垃圾收集器如下,圖中標(biāo)出了它們的工作區(qū)域、垃圾收集算法,以及配合關(guān)系。

這些收集器里,面試的重點(diǎn)是兩個(gè)——CMS和G1。
Serial 收集器
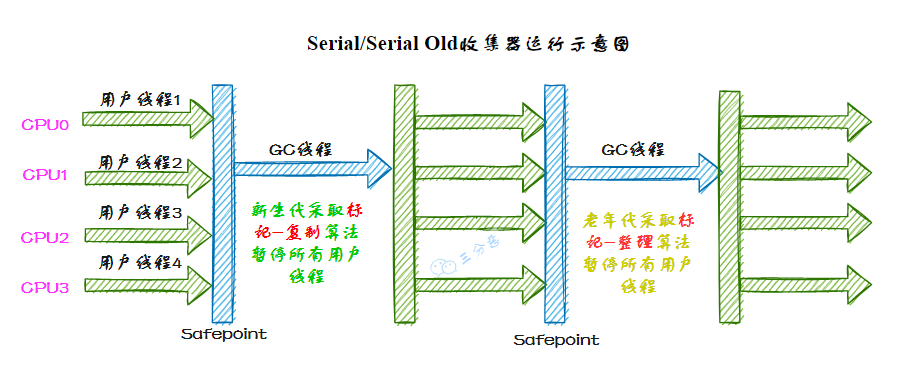
Serial 收集器是最基礎(chǔ)、歷史最悠久的收集器。
如同它的名字(串行),它是一個(gè)單線程工作的收集器,使用一個(gè)處理器或一條收集線程去完成垃圾收集工作。并且進(jìn)行垃圾收集時(shí),必須暫停其他所有工作線程,直到垃圾收集結(jié)束——這就是所謂的“Stop The World”。
Serial/Serial Old 收集器的運(yùn)行過程如圖:
ParNew
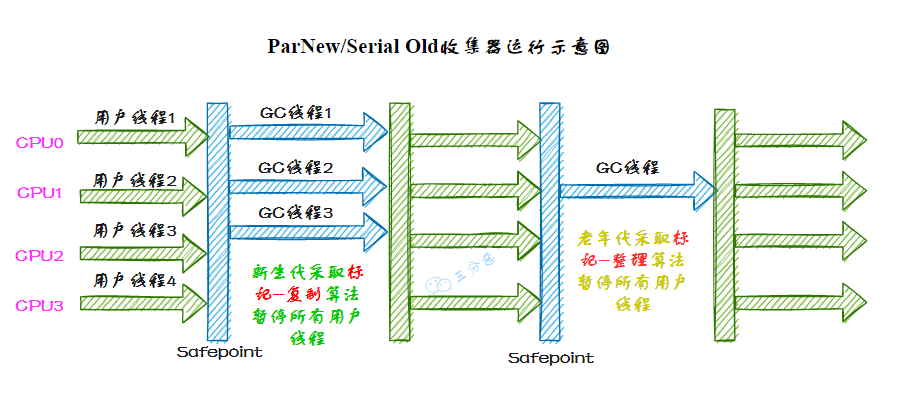
ParNew 收集器實(shí)質(zhì)上是 Serial 收集器的多線程并行版本,使用多條線程進(jìn)行垃圾收集。
ParNew/Serial Old 收集器運(yùn)行示意圖如下:
Parallel Scavenge
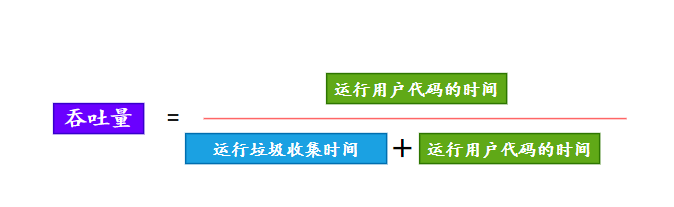
Parallel Scavenge 收集器是一款新生代收集器,基于標(biāo)記-復(fù)制算法實(shí)現(xiàn),也能夠并行收集。和 ParNew 有些類似,但 Parallel Scavenge 主要關(guān)注的是垃圾收集的吞吐量——所謂吞吐量,就是 CPU 用于運(yùn)行用戶代碼的時(shí)間和總消耗時(shí)間的比值,比值越大,說明垃圾收集的占比越小。
Serial Old
Serial Old 是 Serial 收集器的老年代版本,它同樣是一個(gè)單線程收集器,使用標(biāo)記-整理算法。
Parallel Old
Parallel Old 是 Parallel Scavenge 收集器的老年代版本,支持多線程并發(fā)收集,基于標(biāo)記-整理算法實(shí)現(xiàn)。
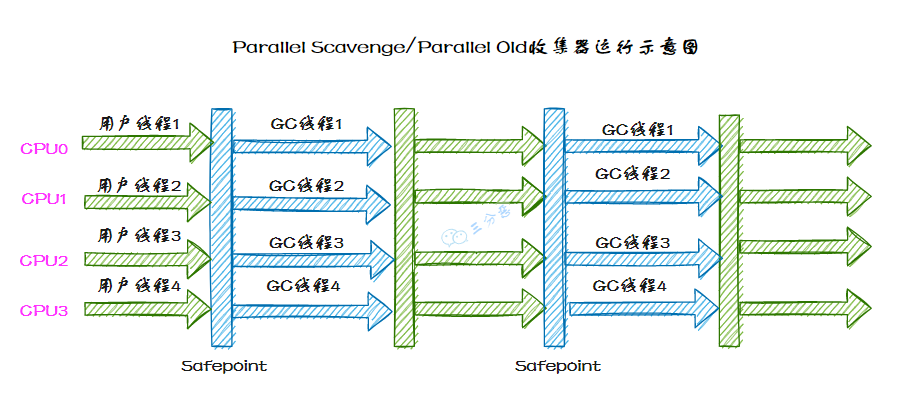
CMS 收集器
CMS(Concurrent Mark Sweep)收集器是一種以獲取最短回收停頓時(shí)間為目標(biāo)的收集器,同樣是老年代的收集器,采用標(biāo)記-清除算法。
Garbage First 收集器
Garbage First(簡稱 G1)收集器是垃圾收集器的一個(gè)顛覆性的產(chǎn)物,它開創(chuàng)了局部收集的設(shè)計(jì)思路和基于 Region 的內(nèi)存布局形式。
25.什么是 Stop The World ? 什么是 OopMap ?什么是安全點(diǎn)?
進(jìn)行垃圾回收的過程中,會(huì)涉及對象的移動(dòng)。為了保證對象引用更新的正確性,必須暫停所有的用戶線程,像這樣的停頓,虛擬機(jī)設(shè)計(jì)者形象描述為Stop The World。也簡稱為 STW。
在 HotSpot 中,有個(gè)數(shù)據(jù)結(jié)構(gòu)(映射表)稱為OopMap。一旦類加載動(dòng)作完成的時(shí)候,HotSpot 就會(huì)把對象內(nèi)什么偏移量上是什么類型的數(shù)據(jù)計(jì)算出來,記錄到 OopMap。在即時(shí)編譯過程中,也會(huì)在特定的位置生成 OopMap,記錄下棧上和寄存器里哪些位置是引用。
這些特定的位置主要在:
1.循環(huán)的末尾(非 counted 循環(huán))
2.方法臨返回前 / 調(diào)用方法的 call 指令后
3.可能拋異常的位置
這些位置就叫作安全點(diǎn)(safepoint)。 用戶程序執(zhí)行時(shí)并非在代碼指令流的任意位置都能夠在停頓下來開始垃圾收集,而是必須是執(zhí)行到安全點(diǎn)才能夠暫停。
用通俗的比喻,假如老王去拉車,車上東西很重,老王累的汗流浹背,但是老王不能在上坡或者下坡休息,只能在平地上停下來擦擦汗,喝口水。

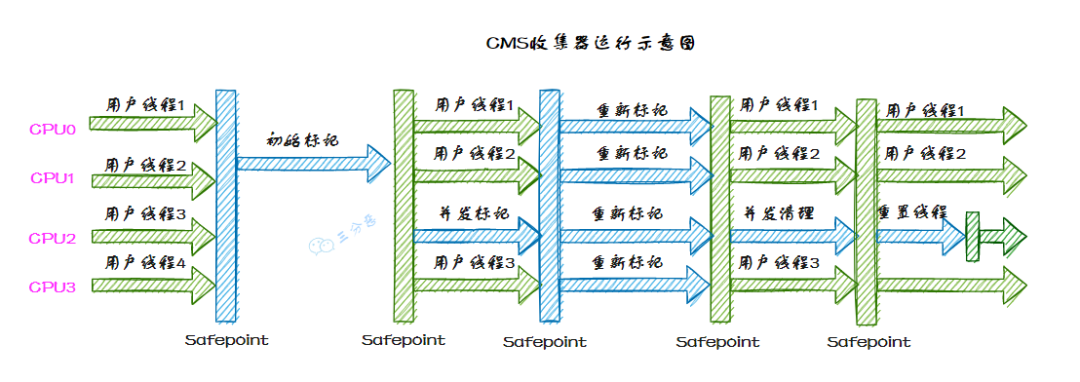
26.能詳細(xì)說一下 CMS 收集器的垃圾收集過程嗎?
CMS 收集齊的垃圾收集分為四步:
初始標(biāo)記(CMS initial mark):單線程運(yùn)行,需要 Stop The World,標(biāo)記 GC Roots 能直達(dá)的對象。 并發(fā)標(biāo)記((CMS concurrent mark):無停頓,和用戶線程同時(shí)運(yùn)行,從 GC Roots 直達(dá)對象開始遍歷整個(gè)對象圖。 重新標(biāo)記(CMS remark):多線程運(yùn)行,需要 Stop The World,標(biāo)記并發(fā)標(biāo)記階段產(chǎn)生對象。 并發(fā)清除(CMS concurrent sweep):無停頓,和用戶線程同時(shí)運(yùn)行,清理掉標(biāo)記階段標(biāo)記的死亡的對象。
Concurrent Mark Sweep 收集器運(yùn)行示意圖如下:
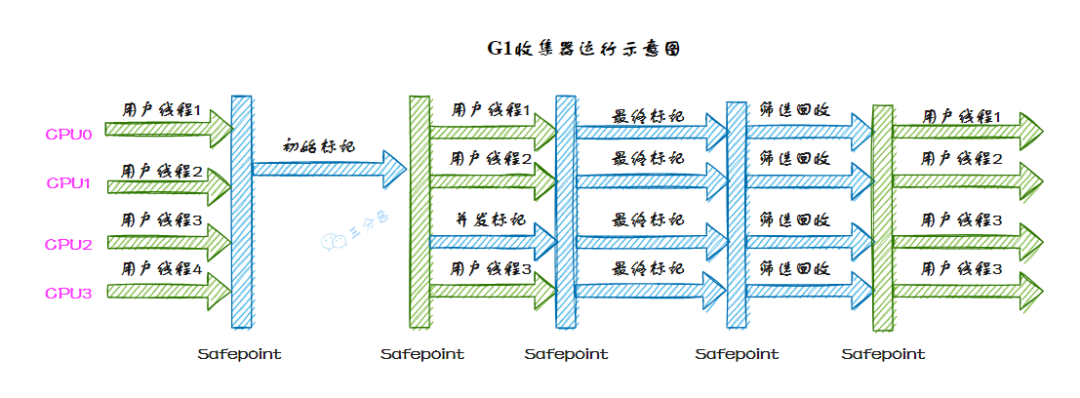
27.G1 垃圾收集器了解嗎?
Garbage First(簡稱 G1)收集器是垃圾收集器的一個(gè)顛覆性的產(chǎn)物,它開創(chuàng)了局部收集的設(shè)計(jì)思路和基于 Region 的內(nèi)存布局形式。
雖然 G1 也仍是遵循分代收集理論設(shè)計(jì)的,但其堆內(nèi)存的布局與其他收集器有非常明顯的差異。以前的收集器分代是劃分新生代、老年代、持久代等。
G1 把連續(xù)的 Java 堆劃分為多個(gè)大小相等的獨(dú)立區(qū)域(Region),每一個(gè) Region 都可以根據(jù)需要,扮演新生代的 Eden 空間、Survivor 空間,或者老年代空間。收集器能夠?qū)Π缪莶煌巧?Region 采用不同的策略去處理。

這樣就避免了收集整個(gè)堆,而是按照若干個(gè) Region 集進(jìn)行收集,同時(shí)維護(hù)一個(gè)優(yōu)先級列表,跟蹤各個(gè) Region 回收的“價(jià)值,優(yōu)先收集價(jià)值高的 Region。
G1 收集器的運(yùn)行過程大致可劃分為以下四個(gè)步驟:
初始標(biāo)記(initial mark),標(biāo)記了從 GC Root 開始直接關(guān)聯(lián)可達(dá)的對象。STW(Stop the World)執(zhí)行。 并發(fā)標(biāo)記(concurrent marking),和用戶線程并發(fā)執(zhí)行,從 GC Root 開始對堆中對象進(jìn)行可達(dá)性分析,遞歸掃描整個(gè)堆里的對象圖,找出要回收的對象、 最終標(biāo)記(Remark),STW,標(biāo)記再并發(fā)標(biāo)記過程中產(chǎn)生的垃圾。 篩選回收(Live Data Counting And Evacuation),制定回收計(jì)劃,選擇多個(gè) Region 構(gòu)成回收集,把回收集中 Region 的存活對象復(fù)制到空的 Region 中,再清理掉整個(gè)舊 Region 的全部空間。需要 STW。
28.有了 CMS,為什么還要引入 G1?
優(yōu)點(diǎn):CMS 最主要的優(yōu)點(diǎn)在名字上已經(jīng)體現(xiàn)出來——并發(fā)收集、低停頓。
缺點(diǎn):CMS 同樣有三個(gè)明顯的缺點(diǎn)。
Mark Sweep 算法會(huì)導(dǎo)致內(nèi)存碎片比較多 CMS 的并發(fā)能力比較依賴于 CPU 資源,并發(fā)回收時(shí)垃圾收集線程可能會(huì)搶占用戶線程的資源,導(dǎo)致用戶程序性能下降。 并發(fā)清除階段,用戶線程依然在運(yùn)行,會(huì)產(chǎn)生所謂的理“浮動(dòng)垃圾”(Floating Garbage),本次垃圾收集無法處理浮動(dòng)垃圾,必須到下一次垃圾收集才能處理。如果浮動(dòng)垃圾太多,會(huì)觸發(fā)新的垃圾回收,導(dǎo)致性能降低。
G1 主要解決了內(nèi)存碎片過多的問題。
29.你們線上用的什么垃圾收集器?為什么要用它?
怎么說呢,雖然調(diào)優(yōu)說的震天響,但是我們一般都是用默認(rèn)。管你 Java 怎么升,我用 8,那么 JDK1.8 默認(rèn)用的是什么呢?
可以使用命令:
java?-XX:+PrintCommandLineFlags?-version
可以看到有這么一行:
-XX:+UseParallelGC
UseParallelGC = Parallel Scavenge + Parallel Old,表示的是新生代用的Parallel Scavenge收集器,老年代用的是Parallel Old 收集器。
那為什么要用這個(gè)呢?默認(rèn)的唄。
當(dāng)然面試肯定不能這么答。
Parallel Scavenge 的特點(diǎn)是什么?
高吞吐,我們可以回答:因?yàn)槲覀兿到y(tǒng)是業(yè)務(wù)相對復(fù)雜,但并發(fā)并不是非常高,所以希望盡可能的利用處理器資源,出于提高吞吐量的考慮采用Parallel Scavenge + Parallel Old的組合。
當(dāng)然,這個(gè)默認(rèn)雖然也有說法,但不太討喜。
還可以說:
采用Parallel New+CMS的組合,我們比較關(guān)注服務(wù)的響應(yīng)速度,所以采用了 CMS 來降低停頓時(shí)間。
或者一步到位:
我們線上采用了設(shè)計(jì)比較優(yōu)秀的 G1 垃圾收集器,因?yàn)樗粌H滿足我們低停頓的要求,而且解決了 CMS 的浮動(dòng)垃圾問題、內(nèi)存碎片問題。
30.垃圾收集器應(yīng)該如何選擇?
垃圾收集器的選擇需要權(quán)衡的點(diǎn)還是比較多的——例如運(yùn)行應(yīng)用的基礎(chǔ)設(shè)施如何?使用 JDK 的發(fā)行商是什么?等等……
這里簡單地列一下上面提到的一些收集器的適用場景:
Serial :如果應(yīng)用程序有一個(gè)很小的內(nèi)存空間(大約 100 MB)亦或它在沒有停頓時(shí)間要求的單線程處理器上運(yùn)行。 Parallel:如果優(yōu)先考慮應(yīng)用程序的峰值性能,并且沒有時(shí)間要求要求,或者可以接受 1 秒或更長的停頓時(shí)間。 CMS/G1:如果響應(yīng)時(shí)間比吞吐量優(yōu)先級高,或者垃圾收集暫停必須保持在大約 1 秒以內(nèi)。 ZGC:如果響應(yīng)時(shí)間是高優(yōu)先級的,或者堆空間比較大。
31.對象一定分配在堆中嗎?有沒有了解逃逸分析技術(shù)?
對象一定分配在堆中嗎? 不一定的。
隨著 JIT 編譯期的發(fā)展與逃逸分析技術(shù)逐漸成熟,所有的對象都分配到堆上也漸漸變得不那么“絕對”了。其實(shí),在編譯期間,JIT 會(huì)對代碼做很多優(yōu)化。其中有一部分優(yōu)化的目的就是減少內(nèi)存堆分配壓力,其中一種重要的技術(shù)叫做逃逸分析。
什么是逃逸分析?
逃逸分析是指分析指針動(dòng)態(tài)范圍的方法,它同編譯器優(yōu)化原理的指針分析和外形分析相關(guān)聯(lián)。當(dāng)變量(或者對象)在方法中分配后,其指針有可能被返回或者被全局引用,這樣就會(huì)被其他方法或者線程所引用,這種現(xiàn)象稱作指針(或者引用)的逃逸(Escape)。
通俗點(diǎn)講,當(dāng)一個(gè)對象被 new 出來之后,它可能被外部所調(diào)用,如果是作為參數(shù)傳遞到外部了,就稱之為方法逃逸。

除此之外,如果對象還有可能被外部線程訪問到,例如賦值給可以在其它線程中訪問的實(shí)例變量,這種就被稱為線程逃逸。

逃逸分析的好處
棧上分配
如果確定一個(gè)對象不會(huì)逃逸到線程之外,那么久可以考慮將這個(gè)對象在棧上分配,對象占用的內(nèi)存隨著棧幀出棧而銷毀,這樣一來,垃圾收集的壓力就降低很多。
同步消除
線程同步本身是一個(gè)相對耗時(shí)的過程,如果逃逸分析能夠確定一個(gè)變量不會(huì)逃逸出線程,無法被其他線程訪問,那么這個(gè)變量的讀寫肯定就不會(huì)有競爭, 對這個(gè)變量實(shí)施的同步措施也就可以安全地消除掉。
標(biāo)量替換
如果一個(gè)數(shù)據(jù)是基本數(shù)據(jù)類型,不可拆分,它就被稱之為標(biāo)量。把一個(gè) Java 對象拆散,將其用到的成員變量恢復(fù)為原始類型來訪問,這個(gè)過程就稱為標(biāo)量替換。假如逃逸分析能夠證明一個(gè)對象不會(huì)被方法外部訪問,并且這個(gè)對象可以被拆散,那么可以不創(chuàng)建對象,直接用創(chuàng)建若干個(gè)成員變量代替,可以讓對象的成員變量在棧上分配和讀寫。
JVM 調(diào)優(yōu)
32.有哪些常用的命令行性能監(jiān)控和故障處理工具?
操作系統(tǒng)工具
top:顯示系統(tǒng)整體資源使用情況 vmstat:監(jiān)控內(nèi)存和 CPU iostat:監(jiān)控 IO 使用 netstat:監(jiān)控網(wǎng)絡(luò)使用 JDK 性能監(jiān)控工具
jps:虛擬機(jī)進(jìn)程查看 jstat:虛擬機(jī)運(yùn)行時(shí)信息查看 jinfo:虛擬機(jī)配置查看 jmap:內(nèi)存映像(導(dǎo)出) jhat:堆轉(zhuǎn)儲(chǔ)快照分析 jstack:Java 堆棧跟蹤 jcmd:實(shí)現(xiàn)上面除了 jstat 外所有命令的功能
33.了解哪些可視化的性能監(jiān)控和故障處理工具?
以下是一些 JDK 自帶的可視化性能監(jiān)控和故障處理工具:
JConsole
VisualVM

Java Mission Control

除此之外,還有一些第三方的工具:
MAT
Java 堆內(nèi)存分析工具。
GChisto
GC 日志分析工具。
GCViewer
GC 日志分析工具。
JProfiler
商用的性能分析利器。
arthas
阿里開源診斷工具。
async-profiler
Java 應(yīng)用性能分析工具,開源、火焰圖、跨平臺。
34.JVM 的常見參數(shù)配置知道哪些?
一些常見的參數(shù)配置:
堆配置:
-Xms:初始堆大小 -Xms:最大堆大小 -XX:NewSize=n:設(shè)置年輕代大小 -XX:NewRatio=n:設(shè)置年輕代和年老代的比值。如:為 3 表示年輕代和年老代比值為 1:3,年輕代占整個(gè)年輕代年老代和的 1/4 -XX:SurvivorRatio=n:年輕代中 Eden 區(qū)與兩個(gè) Survivor 區(qū)的比值。注意 Survivor 區(qū)有兩個(gè)。如 3 表示 Eden:3 Survivor:2,一個(gè) Survivor 區(qū)占整個(gè)年輕代的 1/5 -XX:MaxPermSize=n:設(shè)置持久代大小
收集器設(shè)置:
-XX:+UseSerialGC:設(shè)置串行收集器 -XX:+UseParallelGC:設(shè)置并行收集器 -XX:+UseParalledlOldGC:設(shè)置并行年老代收集器 -XX:+UseConcMarkSweepGC:設(shè)置并發(fā)收集器
并行收集器設(shè)置
-XX:ParallelGCThreads=n:設(shè)置并行收集器收集時(shí)使用的 CPU 數(shù)。并行收集線程數(shù) -XX:MaxGCPauseMillis=n:設(shè)置并行收集最大的暫停時(shí)間(如果到這個(gè)時(shí)間了,垃圾回收器依然沒有回收完,也會(huì)停止回收) -XX:GCTimeRatio=n:設(shè)置垃圾回收時(shí)間占程序運(yùn)行時(shí)間的百分比。公式為:1/(1+n) -XX:+CMSIncrementalMode:設(shè)置為增量模式。適用于單 CPU 情況 -XX:ParallelGCThreads=n:設(shè)置并發(fā)收集器年輕代手機(jī)方式為并行收集時(shí),使用的 CPU 數(shù)。并行收集線程數(shù)
打印 GC 回收的過程日志信息
-XX:+PrintGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:filename
35.有做過 JVM 調(diào)優(yōu)嗎?
JVM 調(diào)優(yōu)是一件很嚴(yán)肅的事情,不是拍腦門就開始調(diào)優(yōu)的,需要有嚴(yán)密的分析和監(jiān)控機(jī)制,大概的一個(gè) JVM 調(diào)優(yōu)流程圖:

實(shí)際上,JVM 調(diào)優(yōu)是不得已而為之,有那功夫,好好把爛代碼重構(gòu)一下不比瞎調(diào) JVM 強(qiáng)。
但是,面試官非要問怎么辦?可以從處理問題的角度來回答(對應(yīng)圖中事后),這是一個(gè)中規(guī)中矩的案例:電商公司的運(yùn)營后臺系統(tǒng),偶發(fā)性的引發(fā) OOM 異常,堆內(nèi)存溢出。
1)因?yàn)槭桥及l(fā)性的,所以第一次簡單的認(rèn)為就是堆內(nèi)存不足導(dǎo)致,單方面的加大了堆內(nèi)存從 4G 調(diào)整到 8G -Xms8g。
2)但是問題依然沒有解決,只能從堆內(nèi)存信息下手,通過開啟了-XX:+HeapDumpOnOutOfMemoryError 參數(shù) 獲得堆內(nèi)存的 dump 文件。
3)用 JProfiler 對 堆 dump 文件進(jìn)行分析,通過 JProfiler 查看到占用內(nèi)存最大的對象是 String 對象,本來想跟蹤著 String 對象找到其引用的地方,但 dump 文件太大,跟蹤進(jìn)去的時(shí)候總是卡死,而 String 對象占用比較多也比較正常,最開始也沒有認(rèn)定就是這里的問題,于是就從線程信息里面找突破點(diǎn)。
4)通過線程進(jìn)行分析,先找到了幾個(gè)正在運(yùn)行的業(yè)務(wù)線程,然后逐一跟進(jìn)業(yè)務(wù)線程看了下代碼,有個(gè)方法引起了我的注意,導(dǎo)出訂單信息。
5)因?yàn)橛唵涡畔?dǎo)出這個(gè)方法可能會(huì)有幾萬的數(shù)據(jù)量,首先要從數(shù)據(jù)庫里面查詢出來訂單信息,然后把訂單信息生成 excel,這個(gè)過程會(huì)產(chǎn)生大量的 String 對象。
6)為了驗(yàn)證自己的猜想,于是準(zhǔn)備登錄后臺去測試下,結(jié)果在測試的過程中發(fā)現(xiàn)導(dǎo)出訂單的按鈕前端居然沒有做點(diǎn)擊后按鈕置灰交互事件,后端也沒有做防止重復(fù)提交,因?yàn)閷?dǎo)出訂單數(shù)據(jù)本來就非常慢,使用的人員可能發(fā)現(xiàn)點(diǎn)擊后很久后頁面都沒反應(yīng),然后就一直點(diǎn),結(jié)果就大量的請求進(jìn)入到后臺,堆內(nèi)存產(chǎn)生了大量的訂單對象和 EXCEL 對象,而且方法執(zhí)行非常慢,導(dǎo)致這一段時(shí)間內(nèi)這些對象都無法被回收,所以最終導(dǎo)致內(nèi)存溢出。
7)知道了問題就容易解決了,最終沒有調(diào)整任何 JVM 參數(shù),只是做了兩個(gè)處理:
在前端的導(dǎo)出訂單按鈕上加上了置灰狀態(tài),等后端響應(yīng)之后按鈕才可以進(jìn)行點(diǎn)擊 后端代碼加分布式鎖,做防重處理
這樣雙管齊下,保證導(dǎo)出的請求不會(huì)一直打到服務(wù)端,問題解決!
36.線上服務(wù) CPU 占用過高怎么排查?
問題分析:CPU 高一定是某個(gè)程序長期占用了 CPU 資源。

1)所以先需要找出那個(gè)進(jìn)程占用 CPU 高。
top 列出系統(tǒng)各個(gè)進(jìn)程的資源占用情況。
2)然后根據(jù)找到對應(yīng)進(jìn)行里哪個(gè)線程占用 CPU 高。
top -Hp 進(jìn)程 ID 列出對應(yīng)進(jìn)程里面的線程占用資源情況
3)找到對應(yīng)線程 ID 后,再打印出對應(yīng)線程的堆棧信息
printf "%x\n" PID 把線程 ID 轉(zhuǎn)換為 16 進(jìn)制。 jstack PID 打印出進(jìn)程的所有線程信息,從打印出來的線程信息中找到上一步轉(zhuǎn)換為 16 進(jìn)制的線程 ID 對應(yīng)的線程信息。
4)最后根據(jù)線程的堆棧信息定位到具體業(yè)務(wù)方法,從代碼邏輯中找到問題所在。
查看是否有線程長時(shí)間的 watting 或 blocked,如果線程長期處于 watting 狀態(tài)下, 關(guān)注 watting on xxxxxx,說明線程在等待這把鎖,然后根據(jù)鎖的地址找到持有鎖的線程。
37.內(nèi)存飆高問題怎么排查?
分析:內(nèi)存飚高如果是發(fā)生在 java 進(jìn)程上,一般是因?yàn)閯?chuàng)建了大量對象所導(dǎo)致,持續(xù)飚高說明垃圾回收跟不上對象創(chuàng)建的速度,或者內(nèi)存泄露導(dǎo)致對象無法回收。
1)先觀察垃圾回收的情況
jstat -gc PID 1000 查看 GC 次數(shù),時(shí)間等信息,每隔一秒打印一次。 jmap -histo PID | head -20 查看堆內(nèi)存占用空間最大的前 20 個(gè)對象類型,可初步查看是哪個(gè)對象占用了內(nèi)存。
如果每次 GC 次數(shù)頻繁,而且每次回收的內(nèi)存空間也正常,那說明是因?yàn)閷ο髣?chuàng)建速度快導(dǎo)致內(nèi)存一直占用很高;如果每次回收的內(nèi)存非常少,那么很可能是因?yàn)閮?nèi)存泄露導(dǎo)致內(nèi)存一直無法被回收。
2)導(dǎo)出堆內(nèi)存文件快照
jmap -dump:live,format=b,file=/home/myheapdump.hprof PID dump 堆內(nèi)存信息到文件。
3)使用 visualVM 對 dump 文件進(jìn)行離線分析,找到占用內(nèi)存高的對象,再找到創(chuàng)建該對象的業(yè)務(wù)代碼位置,從代碼和業(yè)務(wù)場景中定位具體問題。
38.頻繁 minor gc 怎么辦?
優(yōu)化 Minor GC 頻繁問題:通常情況下,由于新生代空間較小,Eden 區(qū)很快被填滿,就會(huì)導(dǎo)致頻繁 Minor GC,因此可以通過增大新生代空間-Xmn來降低 Minor GC 的頻率。
39.頻繁 Full GC 怎么辦?
Full GC 的排查思路大概如下:
1)清楚從程序角度,有哪些原因?qū)е?FGC?
大對象:系統(tǒng)一次性加載了過多數(shù)據(jù)到內(nèi)存中(比如 SQL 查詢未做分頁),導(dǎo)致大對象進(jìn)入了老年代。 內(nèi)存泄漏:頻繁創(chuàng)建了大量對象,但是無法被回收(比如 IO 對象使用完后未調(diào)用 close 方法釋放資源),先引發(fā) FGC,最后導(dǎo)致 OOM. 程序頻繁生成一些長生命周期的對象,當(dāng)這些對象的存活年齡超過分代年齡時(shí)便會(huì)進(jìn)入老年代,最后引發(fā) FGC. (即本文中的案例) 程序 BUG 代碼中顯式調(diào)用了 gc方法,包括自己的代碼甚至框架中的代碼。 JVM 參數(shù)設(shè)置問題:包括總內(nèi)存大小、新生代和老年代的大小、Eden 區(qū)和 S 區(qū)的大小、元空間大小、垃圾回收算法等等。
2)清楚排查問題時(shí)能使用哪些工具
公司的監(jiān)控系統(tǒng):大部分公司都會(huì)有,可全方位監(jiān)控 JVM 的各項(xiàng)指標(biāo)。 JDK 的自帶工具,包括 jmap、jstat 等常用命令:
#?查看堆內(nèi)存各區(qū)域的使用率以及GC情況
jstat?-gcutil?-h20?pid?1000
#?查看堆內(nèi)存中的存活對象,并按空間排序
jmap?-histo?pid?|?head?-n20
#?dump堆內(nèi)存文件
jmap?-dump:format=b,file=heap?pid
可視化的堆內(nèi)存分析工具:JVisualVM、MAT 等
3)排查指南
查看監(jiān)控,以了解出現(xiàn)問題的時(shí)間點(diǎn)以及當(dāng)前 FGC 的頻率(可對比正常情況看頻率是否正常) 了解該時(shí)間點(diǎn)之前有沒有程序上線、基礎(chǔ)組件升級等情況。 了解 JVM 的參數(shù)設(shè)置,包括:堆空間各個(gè)區(qū)域的大小設(shè)置,新生代和老年代分別采用了哪些垃圾收集器,然后分析 JVM 參數(shù)設(shè)置是否合理。 再對步驟 1 中列出的可能原因做排除法,其中元空間被打滿、內(nèi)存泄漏、代碼顯式調(diào)用 gc 方法比較容易排查。 針對大對象或者長生命周期對象導(dǎo)致的 FGC,可通過 jmap -histo 命令并結(jié)合 dump 堆內(nèi)存文件作進(jìn)一步分析,需要先定位到可疑對象。 通過可疑對象定位到具體代碼再次分析,這時(shí)候要結(jié)合 GC 原理和 JVM 參數(shù)設(shè)置,弄清楚可疑對象是否滿足了進(jìn)入到老年代的條件才能下結(jié)論。
40.有沒有處理過內(nèi)存泄漏問題?是如何定位的?
內(nèi)存泄漏是內(nèi)在病源,外在病癥表現(xiàn)可能有:
應(yīng)用程序長時(shí)間連續(xù)運(yùn)行時(shí)性能嚴(yán)重下降 CPU 使用率飆升,甚至到 100% 頻繁 Full GC,各種報(bào)警,例如接口超時(shí)報(bào)警等 應(yīng)用程序拋出 OutOfMemoryError錯(cuò)誤應(yīng)用程序偶爾會(huì)耗盡連接對象
嚴(yán)重內(nèi)存泄漏往往伴隨頻繁的 Full GC,所以分析排查內(nèi)存泄漏問題首先還得從查看 Full GC 入手。主要有以下操作步驟:
1)使用 jps 查看運(yùn)行的 Java 進(jìn)程 ID
2)使用top -p [pid] 查看進(jìn)程使用 CPU 和 MEM 的情況
3)使用 top -Hp [pid] 查看進(jìn)程下的所有線程占 CPU 和 MEM 的情況
4)將線程 ID 轉(zhuǎn)換為 16 進(jìn)制:printf "%x\n" [pid],輸出的值就是線程棧信息中的 nid。
例如:printf "%x\n" 29471,換行輸出 731f。
5)抓取線程棧:jstack 29452 > 29452.txt,可以多抓幾次做個(gè)對比。
在線程棧信息中找到對應(yīng)線程號的 16 進(jìn)制值,如下是 731f 線程的信息。線程棧分析可使用 Visualvm 插件 TDA。
"Service?Thread"?#7?daemon?prio=9?os_prio=0?tid=0x00007fbe2c164000?nid=0x731f?runnable?[0x0000000000000000]
???java.lang.Thread.State:?RUNNABLE
6)使用jstat -gcutil [pid] 5000 10 每隔 5 秒輸出 GC 信息,輸出 10 次,查看 YGC 和 Full GC 次數(shù)。通常會(huì)出現(xiàn) YGC 不增加或增加緩慢,而 Full GC 增加很快。
或使用 jstat -gccause [pid] 5000 ,同樣是輸出 GC 摘要信息。
或使用 jmap -heap [pid] 查看堆的摘要信息,關(guān)注老年代內(nèi)存使用是否達(dá)到閥值,若達(dá)到閥值就會(huì)執(zhí)行 Full GC。
7)如果發(fā)現(xiàn) Full GC 次數(shù)太多,就很大概率存在內(nèi)存泄漏了
8)使用 jmap -histo:live [pid] 輸出每個(gè)類的對象數(shù)量,內(nèi)存大小(字節(jié)單位)及全限定類名。
9)生成 dump 文件,借助工具分析哪 個(gè)對象非常多,基本就能定位到問題在那了
使用 jmap 生成 dump 文件:
#?jmap?-dump:live,format=b,file=29471.dump?29471
Dumping?heap?to?/root/dump?...
Heap?dump?file?created
10)dump 文件分析
可以使用 jhat 命令分析:jhat -port 8000 29471.dump,瀏覽器訪問 jhat 服務(wù),端口是 8000。
通常使用圖形化工具分析,如 JDK 自帶的 jvisualvm,從菜單 > 文件 > 裝入 dump 文件。
或使用第三方式具分析的,如 JProfiler 也是個(gè)圖形化工具,GCViewer 工具。Eclipse 或以使用 MAT 工具查看。或使用在線分析平臺 GCEasy。
注意:如果 dump 文件較大的話,分析會(huì)占比較大的內(nèi)存。
11)在 dump 文析結(jié)果中查找存在大量的對象,再查對其的引用。
基本上就可以定位到代碼層的邏輯了。
41.有沒有處理過內(nèi)存溢出問題?
內(nèi)存泄漏和內(nèi)存溢出二者關(guān)系非常密切,內(nèi)存溢出可能會(huì)有很多原因?qū)е拢瑑?nèi)存泄漏最可能的罪魁禍?zhǔn)字弧?/p>
排查過程和排查內(nèi)存泄漏過程類似。
虛擬機(jī)執(zhí)行
42.能說一下類的生命周期嗎?
一個(gè)類從被加載到虛擬機(jī)內(nèi)存中開始,到從內(nèi)存中卸載,整個(gè)生命周期需要經(jīng)過七個(gè)階段:加載 (Loading)、驗(yàn)證(Verification)、準(zhǔn)備(Preparation)、解析(Resolution)、初始化 (Initialization)、使用(Using)和卸載(Unloading),其中驗(yàn)證、準(zhǔn)備、解析三個(gè)部分統(tǒng)稱為連接(Linking)。

43.類加載的過程知道嗎?
加載是 JVM 加載的起點(diǎn),具體什么時(shí)候開始加載,《Java 虛擬機(jī)規(guī)范》中并沒有進(jìn)行強(qiáng)制約束,可以交給虛擬機(jī)的具體實(shí)現(xiàn)來自由把握。
在加載過程,JVM 要做三件事情:
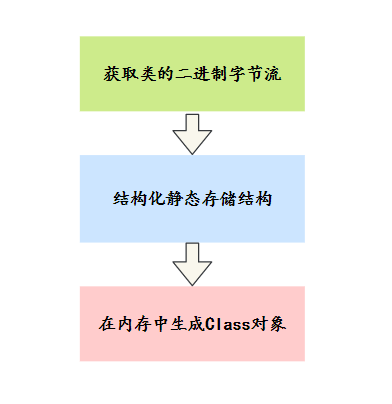
1)通過一個(gè)類的全限定名來獲取定義此類的二進(jìn)制字節(jié)流。
2)將這個(gè)字節(jié)流所代表的靜態(tài)存儲(chǔ)結(jié)構(gòu)轉(zhuǎn)化為方法區(qū)的運(yùn)行時(shí)數(shù)據(jù)結(jié)構(gòu)。
3)在內(nèi)存中生成一個(gè)代表這個(gè)類的 java.lang.Class 對象,作為方法區(qū)這個(gè)類的各種數(shù)據(jù)的訪問入口。
加載階段結(jié)束后,Java 虛擬機(jī)外部的二進(jìn)制字節(jié)流就按照虛擬機(jī)所設(shè)定的格式存儲(chǔ)在方法區(qū)之中了,方法區(qū)中的數(shù)據(jù)存儲(chǔ)格式完全由虛擬機(jī)實(shí)現(xiàn)自行定義,《Java 虛擬機(jī)規(guī)范》未規(guī)定此區(qū)域的具體數(shù)據(jù)結(jié)構(gòu)。
類型數(shù)據(jù)妥善安置在方法區(qū)之后,會(huì)在 Java 堆內(nèi)存中實(shí)例化一個(gè) java.lang.Class 類的對象, 這個(gè)對象將作為程序訪問方法區(qū)中的類型數(shù)據(jù)的外部接口。
44.類加載器有哪些?
主要有四種類加載器:
啟動(dòng)類加載器(Bootstrap ClassLoader)用來加載 java 核心類庫,無法被 java 程序直接引用。
擴(kuò)展類加載器(extensions class loader):它用來加載 Java 的擴(kuò)展庫。Java 虛擬機(jī)的實(shí)現(xiàn)會(huì)提供一個(gè)擴(kuò)展庫目錄。該類加載器在此目錄里面查找并加載 Java 類。
系統(tǒng)類加載器(system class loader):它根據(jù) Java 應(yīng)用的類路徑(CLASSPATH)來加載 Java 類。一般來說,Java 應(yīng)用的類都是由它來完成加載的。可以通過 ClassLoader.getSystemClassLoader()來獲取它。
用戶自定義類加載器 (user class loader),用戶通過繼承 java.lang.ClassLoader 類的方式自行實(shí)現(xiàn)的類加載器。
45.什么是雙親委派機(jī)制?

雙親委派模型的工作過程:如果一個(gè)類加載器收到了類加載的請求,它首先不會(huì)自己去嘗試加載這個(gè)類,而是把這個(gè)請求委派給父類加載器去完成,每一個(gè)層次的類加載器都是如此,因此所有的加載請求最終都應(yīng)該傳送到最頂層的啟動(dòng)類加載器中,只有當(dāng)父加載器反饋?zhàn)约簾o法完成這個(gè)加載請求時(shí),子加載器才會(huì)嘗試自己去完成加載。
46.為什么要用雙親委派機(jī)制?
答案是為了保證應(yīng)用程序的穩(wěn)定有序。
例如類 java.lang.Object,它存放在 rt.jar 之中,通過雙親委派機(jī)制,保證最終都是委派給處于模型最頂端的啟動(dòng)類加載器進(jìn)行加載,保證 Object 的一致。反之,都由各個(gè)類加載器自行去加載的話,如果用戶自己也編寫了一個(gè)名為 java.lang.Object 的類,并放在程序的 ClassPath 中,那系統(tǒng)中就會(huì)出現(xiàn)多個(gè)不同的 Object 類。
47.如何破壞雙親委派機(jī)制?
如果不想打破雙親委派模型,就重寫 ClassLoader 類中的 fifindClass()方法即可,無法被父類加載器加載的類最終會(huì)通過這個(gè)方法被加載。而如果想打破雙親委派模型則需要重寫 loadClass()方法。
48.歷史上有哪幾次雙親委派機(jī)制的破壞?
雙親委派機(jī)制在歷史上主要有三次破壞:
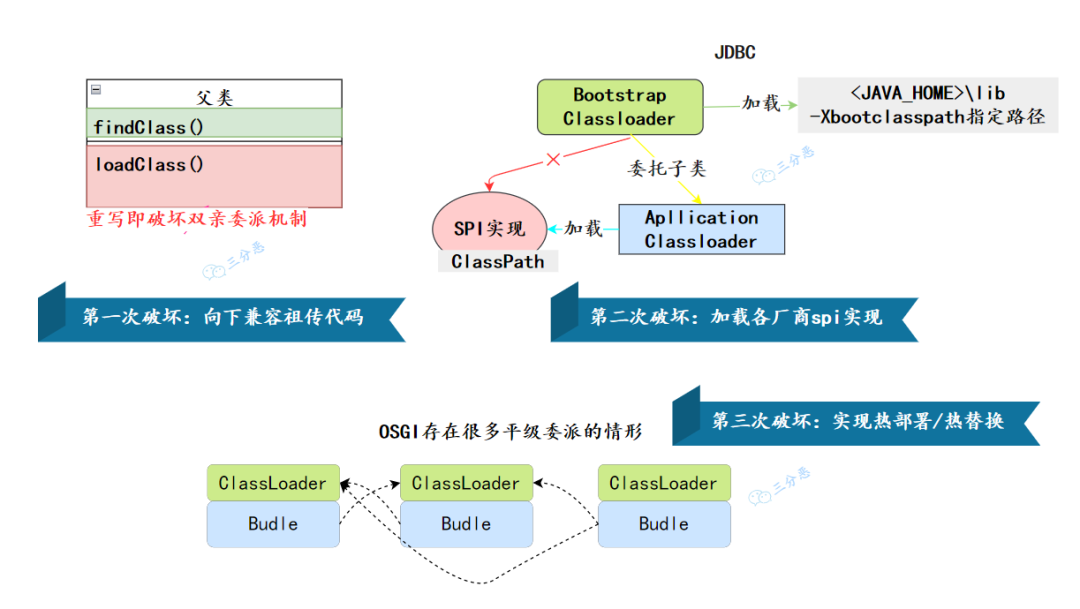
第一次破壞
雙親委派模型的第一次“被破壞”其實(shí)發(fā)生在雙親委派模型出現(xiàn)之前——即 JDK 1.2 面世以前的“遠(yuǎn)古”時(shí)代。
由于雙親委派模型在 JDK 1.2 之后才被引入,但是類加載器的概念和抽象類 java.lang.ClassLoader 則在 Java 的第一個(gè)版本中就已經(jīng)存在,為了向下兼容舊代碼,所以無法以技術(shù)手段避免 loadClass()被子類覆蓋的可能性,只能在 JDK 1.2 之后的 java.lang.ClassLoader 中添加一個(gè)新的 protected 方法 findClass(),并引導(dǎo)用戶編寫的類加載邏輯時(shí)盡可能去重寫這個(gè)方法,而不是在 loadClass()中編寫代碼。
第二次破壞
雙親委派模型的第二次“被破壞”是由這個(gè)模型自身的缺陷導(dǎo)致的,如果有基礎(chǔ)類型又要調(diào)用回用戶的代碼,那該怎么辦呢?
例如我們比較熟悉的 JDBC:
各個(gè)廠商各有不同的 JDBC 的實(shí)現(xiàn),Java 在核心包\lib里定義了對應(yīng)的 SPI,那么這個(gè)就毫無疑問由啟動(dòng)類加載器加載器加載。
但是各個(gè)廠商的實(shí)現(xiàn),是沒辦法放在核心包里的,只能放在classpath里,只能被應(yīng)用類加載器加載。那么,問題來了,啟動(dòng)類加載器它就加載不到廠商提供的 SPI 服務(wù)代碼。
為了解決這個(gè)問題,引入了一個(gè)不太優(yōu)雅的設(shè)計(jì):線程上下文類加載器 (Thread Context ClassLoader)。這個(gè)類加載器可以通過 java.lang.Thread 類的 setContext-ClassLoader()方法進(jìn)行設(shè)置,如果創(chuàng)建線程時(shí)還未設(shè)置,它將會(huì)從父線程中繼承一個(gè),如果在應(yīng)用程序的全局范圍內(nèi)都沒有設(shè)置過的話,那這個(gè)類加載器默認(rèn)就是應(yīng)用程序類加載器。
JNDI 服務(wù)使用這個(gè)線程上下文類加載器去加載所需的 SPI 服務(wù)代碼,這是一種父類加載器去請求子類加載器完成類加載的行為。
第三次破壞
雙親委派模型的第三次“被破壞”是由于用戶對程序動(dòng)態(tài)性的追求而導(dǎo)致的,例如代碼熱替換(Hot Swap)、模塊熱部署(Hot Deployment)等。
OSGi 實(shí)現(xiàn)模塊化熱部署的關(guān)鍵是它自定義的類加載器機(jī)制的實(shí)現(xiàn),每一個(gè)程序模塊(OSGi 中稱為 Bundle)都有一個(gè)自己的類加載器,當(dāng)需要更換一個(gè) Bundle 時(shí),就把 Bundle 連同類加載器一起換掉以實(shí)現(xiàn)代碼的熱替換。在 OSGi 環(huán)境下,類加載器不再雙親委派模型推薦的樹狀結(jié)構(gòu),而是進(jìn)一步發(fā)展為更加復(fù)雜的網(wǎng)狀結(jié)構(gòu)。
49.你覺得應(yīng)該怎么實(shí)現(xiàn)一個(gè)熱部署功能?
我們已經(jīng)知道了 Java 類的加載過程。一個(gè) Java 類文件到虛擬機(jī)里的對象,要經(jīng)過如下過程:首先通過 Java 編譯器,將 Java 文件編譯成 class 字節(jié)碼,類加載器讀取 class 字節(jié)碼,再將類轉(zhuǎn)化為實(shí)例,對實(shí)例 newInstance 就可以生成對象。
類加載器 ClassLoader 功能,也就是將 class 字節(jié)碼轉(zhuǎn)換到類的實(shí)例。在 Java 應(yīng)用中,所有的實(shí)例都是由類加載器,加載而來。
一般在系統(tǒng)中,類的加載都是由系統(tǒng)自帶的類加載器完成,而且對于同一個(gè)全限定名的 java 類(如 com.csiar.soc.HelloWorld),只能被加載一次,而且無法被卸載。
這個(gè)時(shí)候問題就來了,如果我們希望將 java 類卸載,并且替換更新版本的 java 類,該怎么做呢?
既然在類加載器中,Java 類只能被加載一次,并且無法卸載。那么我們是不是可以直接把 Java 類加載器干掉呢?答案是可以的,我們可以自定義類加載器,并重寫 ClassLoader 的 findClass 方法。
想要實(shí)現(xiàn)熱部署可以分以下三個(gè)步驟:
1)銷毀原來的自定義 ClassLoader 2)更新 class 類文件 3)創(chuàng)建新的 ClassLoader 去加載更新后的 class 類文件。
到此,一個(gè)熱部署的功能就這樣實(shí)現(xiàn)了。
50.Tomcat 的類加載機(jī)制了解嗎?
Tomcat 是主流的 Java Web 服務(wù)器之一,為了實(shí)現(xiàn)一些特殊的功能需求,自定義了一些類加載器。
Tomcat 類加載器如下:

Tomcat 實(shí)際上也是破壞了雙親委派模型的。
Tomact 是 web 容器,可能需要部署多個(gè)應(yīng)用程序。不同的應(yīng)用程序可能會(huì)依賴同一個(gè)第三方類庫的不同版本,但是不同版本的類庫中某一個(gè)類的全路徑名可能是一樣的。如多個(gè)應(yīng)用都要依賴 hollis.jar,但是 A 應(yīng)用需要依賴 1.0.0 版本,但是 B 應(yīng)用需要依賴 1.0.1 版本。這兩個(gè)版本中都有一個(gè)類是 com.hollis.Test.class。如果采用默認(rèn)的雙親委派類加載機(jī)制,那么無法加載多個(gè)相同的類。
所以,Tomcat 破壞了雙親委派原則,提供隔離的機(jī)制,為每個(gè) web 容器單獨(dú)提供一個(gè) WebAppClassLoader 加載器。每一個(gè) WebAppClassLoader 負(fù)責(zé)加載本身的目錄下的 class 文件,加載不到時(shí)再交 CommonClassLoader 加載,這和雙親委派剛好相反。

沒有什么使我停留——除了目的,縱然岸旁有玫瑰、有綠蔭、有寧靜的港灣,我是不系之舟。
推薦閱讀: