
介紹一種更方便的代理池實現(xiàn)方案
“
閱讀本文大概需要 8 分鐘。
現(xiàn)在搞爬蟲,代理是不可或缺的資源。
代理池
為了保證代理的有效性,我們往往可能需要維護一個代理池。這個代理池里面存著非常多的代理,同時代理池還會定時爬取代理來補充到代理池中,同時還會不斷檢測其中代理的有效性。當(dāng)然還有一個很重要的功能就是提供一個接口,這個接口可以隨機返回代理池中的一個有效代理。
比如之前我實現(xiàn)過的一個代理池:https://github.com/Python3WebSpider/ProxyPool,就包含了上面所說的功能,它把現(xiàn)在很多免費代理、付費代理集成起來,做到定時獲取,定時檢測,同時還提供了代理提取的 API。
用的時候怎么用呢?直接請求某個接口,獲取一個隨機代理即可。比如代理池的取用地址為 http://127.0.0.1:5555/random,那么我們直接請求這個接口就能獲取一個有效代理,像這樣:
import requestsproxypool_url ='http://127.0.0.1:5555/random'def get_random_proxy():return requests.get(proxypool_url).text.strip()
在這里我們直接調(diào)用 get_random_proxy 方法我們就能獲取到一個可用代理。
返回結(jié)果類似如下:
116.196.115.209:8080然后我們再拿著這個代理去請求某些站點就行了。
情景切入
其實這樣做起來問題不大,用起來也不麻煩。但是我們必須要請求這個 API 來獲取一個代理,然后接著再去拿著這個代理去爬取站點。有沒有更優(yōu)化的方案呢?能不能我把代理都封裝成一個 endpoint,我直接拿著這個 endpoint 來爬呢?
有的同學(xué)一聽,說:哦,這種代理我用過啊,那個 xx 云不就這么干的嗎?它會給我一個代理地址,比如 xxproxy:7777,我就設(shè)置這個代理地址,然后只拿著這個代理去爬就行了,每次請求的時候 IP 都會換,具體用的那個 IP 我也不需要關(guān)心,還挺方便的。
是的就是這種,有些代理服務(wù)商就會賣這種服務(wù)的代理,叫做隧道代理(動態(tài)轉(zhuǎn)發(fā)),在這里把某代理網(wǎng)的介紹復(fù)制過來。
?隧道代理無須切換 IP,將 IP 切換的事情交給隧道來做,程序只需要對接一個隧道代理的固定地址即可。?隧道代理(動態(tài)轉(zhuǎn)發(fā))每一個請求一個隨機 IP。隨機 IP 來自全局 IP 池,每天 IP 流水 50 萬以上。?HTTP 隧道有并發(fā)請求限制,默認每秒只允許 5 個請求。如果需要更多請求數(shù),請額外購買。
原理基本上就是這樣子,調(diào)用的時候就直接設(shè)置上這個代理就好了,比如 Scrapy 的話就是這樣調(diào)用:
import scrapyimport osclassMyIPSpider(scrapy.Spider):name ='my_ip'start_urls =['https://api.ip.sb/ip?v=1','https://api.ip.sb/ip?v=2',]def start_requests(self):proxyUser ="app_id(后臺-產(chǎn)品管理-隧道代理頁面可查)"proxyPass ="密碼(用戶中心-隧道代理訂單頁面可查)"proxyHost ="http.xxxxxproxy.com"proxyPort ="1000"proxyMeta ="http://%(user)s:%(pass)s@%(host)s:%(port)s"%{"host": proxyHost,"port": proxyPort,"user": proxyUser,"pass": proxyPass,}for url inself.start_urls:req = scrapy.Request(url, meta={'proxy': proxyMeta})yield reqdef parse(self, response):yield{'body': response.text,}
那么它具體原理是什么樣子的呢?在這里再貼一段官方的介紹。
產(chǎn)品特性
?隧道代理(短效版)每個 IP 的使用時長為 1 分鐘,到期后隧道將自動切換到另一個 IP。同時也允許手動切換 IP,切換間隔時間不得少于 10 秒。?隧道代理有并發(fā)請求限制,默認每秒只允許 5 個請求。如果需要更多請求數(shù),請額外購買。
產(chǎn)品說明
?隧道代理 基于 HTTP 協(xié)議,支持 HTTP/HTTPS 協(xié)議的數(shù)據(jù)接入。???平臺在云端維護一個全局 IP 池 供短效代理 IP 產(chǎn)品使用,池中的 IP 會不間斷更新,以保證 IP 池 中有足夠多的 IP 供用戶使用。?需要注意的是 IP池 中有部分 IP 可能會在當(dāng)天重復(fù)出現(xiàn)。?隧道代理(短效版) 同一時刻只能使用一個 IP,如果需要同時使用多個 IP,同一賬號需要購買多條 HTTP 隧道。
資源優(yōu)勢
?自有數(shù)據(jù)節(jié)點,網(wǎng)絡(luò)穩(wěn)定,速度快。?百萬級別 IP 池,海量 IP 可用。?毫秒級別更換 IP,響應(yīng)迅速。?無須頻繁更換代理服務(wù)器地址和端口號,方便快捷。
基本上看完介紹就是這樣子,用的話就是設(shè)置一個固定代理,然后它背后有一個代理池,幫你去做轉(zhuǎn)發(fā)。也就是說它把代理池的篩選、挑選、轉(zhuǎn)發(fā)的功能都做了,這樣用戶用起來會更加方便。
但這種隧道代理也不是沒有缺點,比如:
???不好針對性地控制針對某一站點的有效代理。比如這個隧道代理它只管給你分配一個有效能用的代理,但是它不管這個代理是不是已經(jīng)被某個網(wǎng)站封掉了。這個問題使用代理池就能很好地解決。???這種代理一般他們會設(shè)置并發(fā)限制,比如限制每秒最多五個,多了繼續(xù)加錢。
這種代理大家可能比較好奇是怎么實現(xiàn)的,其實很簡單,本節(jié)我們就來介紹下它的實現(xiàn)方式。
Squid
首先我們來介紹下 Squid,如果你自己搭建過代理的話,想必對 Squid 不陌生。它就是一個用來搭建 HTTP 代理的軟件。
官方介紹如下:
Squid is a caching proxy for the Web supporting HTTP, HTTPS, FTP, and more. It reduces bandwidth and improves response times by caching and reusing frequently-requested web pages. Squid has extensive access controls and makes a great server accelerator. It runs on most available operating systems, including Windows and is licensed under the GNU GPL.
官方介紹說是一個代理緩存軟件,為什么又說是緩存呢?這里先引用一張圖,其工作機制是這樣的:
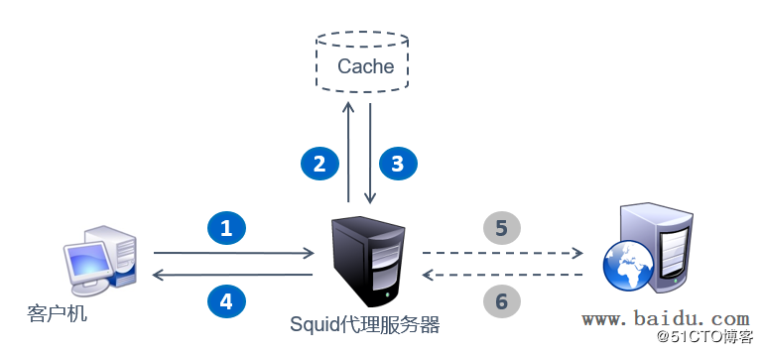 Squid工作機制
Squid工作機制當(dāng)我們客戶機通過 Squid 代理去訪問 Web頁面時,指定的代理服務(wù)器會先檢查自己的緩存,若是緩存中有我們客戶機需要的頁面,那么 Squid 服務(wù)器將直接把緩存中的頁面內(nèi)容返回給客戶機,如果緩存中沒有客戶端請求的頁面,那么 Squid 代理服務(wù)器就會向 Internet 發(fā)送訪問請求,獲得返回的 Web 頁面后,將網(wǎng)頁的數(shù)據(jù)保存到緩存中并發(fā)送給客戶機。
由于客戶機的 Web 訪問請求實際上是 Squid 代理服務(wù)器來代替完成的,所以隱藏了用戶的真實 IP 地址,從而起到一定的保護作用。另一方面,Squid 也可以針對要訪問的目標(biāo)、客戶機的地址、訪問的時間段進行過濾控制。
這就明白了吧,為什么說是代理緩存軟件,以及它為什么能搭建一個代理服務(wù)器。
當(dāng)然 Squid 里面可以設(shè)置透明代理、匿名代理、高匿代理等方式,都是可以配置的。當(dāng)然對于爬蟲來說,選擇匿名或高匿代理是最好的。
代理設(shè)置
好了,明白了 Squid 的工作機制之后,我們其實就可以借助于 Squid 來搭建一個代理服務(wù)器了。比如你的公網(wǎng) IP 為 x.x.x.x,然后安裝了一個 Squid,運行在 3128 端口,運行起來。
然后你就可以使用 x.x.x.x:3128 作為你的爬蟲代理了,你就擁有了一個像之前代理池中取到的某個代理一樣工作原理的代理。
當(dāng)你用這個代理來爬取網(wǎng)站的時候,如果你設(shè)置的是高匿模式,那么被爬取的網(wǎng)站識別到的 IP 就是這個服務(wù)器的 IP,即 x.x.x.x,就偽裝成功了。
嗯,這就是 Squid 的基本使用。
但是,仿佛扯遠了,我們要說的不是這個,說的是怎樣來實現(xiàn)一個前文所介紹的隧道代理。
隧道代理
隧道代理的介紹前文介紹過了,那么我們要怎么實現(xiàn)呢?其實用 Squid 就可以了。
Squid 里面有一個配置叫做 cache_peer,翻譯過來叫「緩存同胞」?很奇怪的名字是吧?其實你了解了 Squid 的原理之后就不覺得奇怪了,前文說了,Squid 本身就是一個代理緩存,即 cache,而 peer 又是同類、同胞的意思。怎么理解呢,其實就是和自己類似的 Squid 服務(wù)器嘛。
那么 cache_peer 能配置什么呢?其實就是在這里面再配置一些類似 Squid 的代理,即 Squid 代理的代理。
其基本語法配置如下:
cache_peer hostname type http-port icp-port [options]例如:
# proxy icp# hostname type port port options# -------------------- -------- ----- ----- -----------cache_peer parent.foo.net parent 31283130defaultcache_peer sib1.foo.net sibling 31283130 proxy-onlycache_peer sib2.foo.net sibling 31283130 proxy-onlycache_peer example.com parent 800defaultcache_peer cdn.example.com sibling 31280
比如這里就配置了 5 個 cache_peer,指定了 hostname,type,port 等等。
這樣代理就會根據(jù)對應(yīng)的配置選擇特定的代理進行轉(zhuǎn)發(fā)了。
比如這里配置了一個 default 的 cache_peer 為 parent.foo.net 的代理,那么一旦有請求本 Squid 代理服務(wù)器的,本 Squid 服務(wù)器就會把請求再轉(zhuǎn)發(fā)給 parent.foo.net 這個代理服務(wù)器,parent.foo.net 這個代理服務(wù)器再去請求對應(yīng)的網(wǎng)站就行了,得到響應(yīng)之后再按照順序轉(zhuǎn)發(fā)回去就行了。
這就是代理的轉(zhuǎn)發(fā),也可以理解為其中包含了兩級代理,第一級代理就是這個 Squid,第二級代理就是隨機選取的 cache_peer。
好,那么回到原來的問題,隧道代理就有思路了吧。
我們可以把獲取下來的好多好多代理都設(shè)置成 cache_peer,Squid 會根據(jù)規(guī)則自動或隨機選擇某一代理進行請求,同時 Squid 還能同時檢測每個 cache_peer 的有效性。比如我們有一萬個代理 IP,我們寫入到 cache_peer 里面,Squid 就會自動檢測每個代理的有效性,我們也不用再去實現(xiàn)檢測邏輯了。
然后如有請求來了,Squid 就會隨機選一個 cache_peer 來轉(zhuǎn)發(fā),這樣被爬取的網(wǎng)站獲取的 IP 就是二級代理的 IP。
同時我們這個 Squid 的代理也不會變,就是 Squid 代理所在的服務(wù)器地址和端口。
這樣我們就能實現(xiàn)一個恒定的隧道代理,同時做到請求的時候代理地址隨機動態(tài)更換了。
嗯,美滋滋。
配置實現(xiàn)
那么具體配置是怎樣的呢?
這里介紹幾個比較有用的參數(shù):
?hostname:就是二級代理服務(wù)器的 host,不帶端口。?type:類型,可以是 pareent、sibling、multicast,我們設(shè)置為 parent 就好了。?port:二級代理服務(wù)器的端口。?icp port:用于查詢有關(guān)對象的鄰居緩存,如果對等方不支持 ICP 或 HTCP,則設(shè)置為 0,我們設(shè)置為 0 就好。?options:其他選項。在這里其他選項也有很多配置,比較重要的有:?login=user:password:如果二級代理有用戶名密碼,可以用 login 設(shè)置。?weight=N:cache_peer 選取權(quán)重,根據(jù) weight 來有權(quán)重地選取 cache_peer。?no-query:不做查詢操作,直接獲取數(shù)據(jù)。?proxy-only:指明從 peer 得到的數(shù)據(jù)不在本地緩存。?default:缺省路由,該 peer 將被用作最后的嘗試手段。當(dāng)你只有一個父代理服務(wù)器并且其不支持 ICP 協(xié)議時,可以使用 default 和 no-query 選項讓所有請求都發(fā)送到該父代理服務(wù)器。?round-robin:負載均衡,設(shè)置了之后會在配置的二級代理之間進行切換選取。?weighted-round-robin:有權(quán)重的負載均衡,同時會根據(jù)二級代理的往返時間來改變選取權(quán)重,越快的選取概率越高。
這些是我從官方文檔翻譯的,更詳細的配置大家可以去看官方文檔:http://www.squid-cache.org/Doc/config/cache_peer/,里面還介紹了其他更多參數(shù)。
好了,了解了上面的配置,我們的 cache_peer 應(yīng)該怎么配置呢?
這里給一個示例:
cache_peer 58.22.22.124 parent 20530no-query proxy-only weighted-round-robin login=germey:Yuy3z92hwRmJe2X6fs3BH6aWnt7xePoL這就是一行 cache_peer 的配置。
如果有非常多的代理池,那么可以根據(jù)這個格式來寫入一個 conf 文件里面,一個代理一個,Squid 引用這個文件即可。
這個 conf 文件可以保存為 peers.conf,然后在 Squid 的配置文件 squid.conf 里面引入即可,例如:
include /etc/squid/peers.conf這樣,Squid 的 cache peers 會被設(shè)置為有權(quán)重的負載均衡模式,當(dāng)有請求來的時候,Squid 會隨機選一個 cache peer 轉(zhuǎn)發(fā),同時 Squid 還會檢測每一個 cache peer 的有效性,我們也不用再單獨實現(xiàn)檢測邏輯了,省去了一大麻煩。
嗯,利用上面的方法,我就能維護一個隧道代理了,這樣一來,我就可以完成:
?爬蟲的代理直接設(shè)置為該 Squid 的 host 和 port 即可。?獲取到的代理直接寫入 peers.conf 配置文件里面,不用再去額外檢測代理有效性,Squid 會自動檢測。?代理池的維護和取用和轉(zhuǎn)發(fā)由 Squid 的 cache_peer 機制自動實現(xiàn),我們不用再去關(guān)心隨機選取的問題了。
OK,是不是很方便呢?這樣我們就實現(xiàn)了一種更方便的代理池。
高匿代理
最后再介紹下 Squid 高匿代理的關(guān)鍵配置:
request_header_access Via deny allrequest_header_access X-Forwarded-For deny all
這里就僅做記錄了,加到 squid.conf 配置文件即可。
優(yōu)化方案
另外,有人說了,難道我有幾萬個 IP,每次更新都要寫入 Squid 文件嗎?寫入之后要重啟吧,Squid 重啟的時候這個代理不就沒法用了嗎?
這個問題,一個更好的解決方案是二級代理使用 ADSL 撥號代理服務(wù)器,peers.conf 里面配置這些 ADSL 撥號代理,這樣 IP 的切換由 ADSL 撥號代理控制,本機 Squid 不用再動 peers.conf 配置文件,也不用重啟了,同時還能檢測撥號代理的有效性,實現(xiàn)永久可用。
代碼
在這里提供我實現(xiàn)的隧道代理的源碼,里面還支持了代理認證的配置,打包了 Docker,感興趣可以研究一下:https://github.com/Python3WebSpider/ProxyTunnel,謝謝!
參考來源
?http://www.squid-cache.org/?http://www.squid-cache.org/Doc/config/cache_peer/?https://blog.51cto.com/riverxyz/1843194?https://blog.51cto.com/14154700/2406060?source=dra?https://xiaoxiangdaili.com/plan/tunnel/dynamic
推薦閱讀
1
2
別再造假數(shù)據(jù)了,來試試 Faker 這個庫吧!
3
4??
如何用一條命令將網(wǎng)頁轉(zhuǎn)成電腦 App
崔慶才
微軟工程師,《Python3網(wǎng)絡(luò)爬蟲開發(fā)實戰(zhàn)》作者
隱形字
個人公眾號:進擊的Coder


長按識別二維碼關(guān)注
好文和朋友一起看~